Python 爬取携程所有机票的实例代码
打开携程网,查询机票,如广州到成都。
这时网址为:http://flights.ctrip.com/booking/CAN-CTU-day-1.html?DDate1=2018-06-15
其中,CAN 表示广州,CTU 表示成都,日期 “2018-06-15”就比较明显了。一般的爬虫,只有替换这几个值,就可以遍历了。但观察发现,有个链接可以看到当前网页的所有json格式的数据。如下
同样可以看到城市和日期,该连接打开的是 json 文件,里面存储的就是当前页面的数据。显示如下,其中 "fis" 则是航班信息。
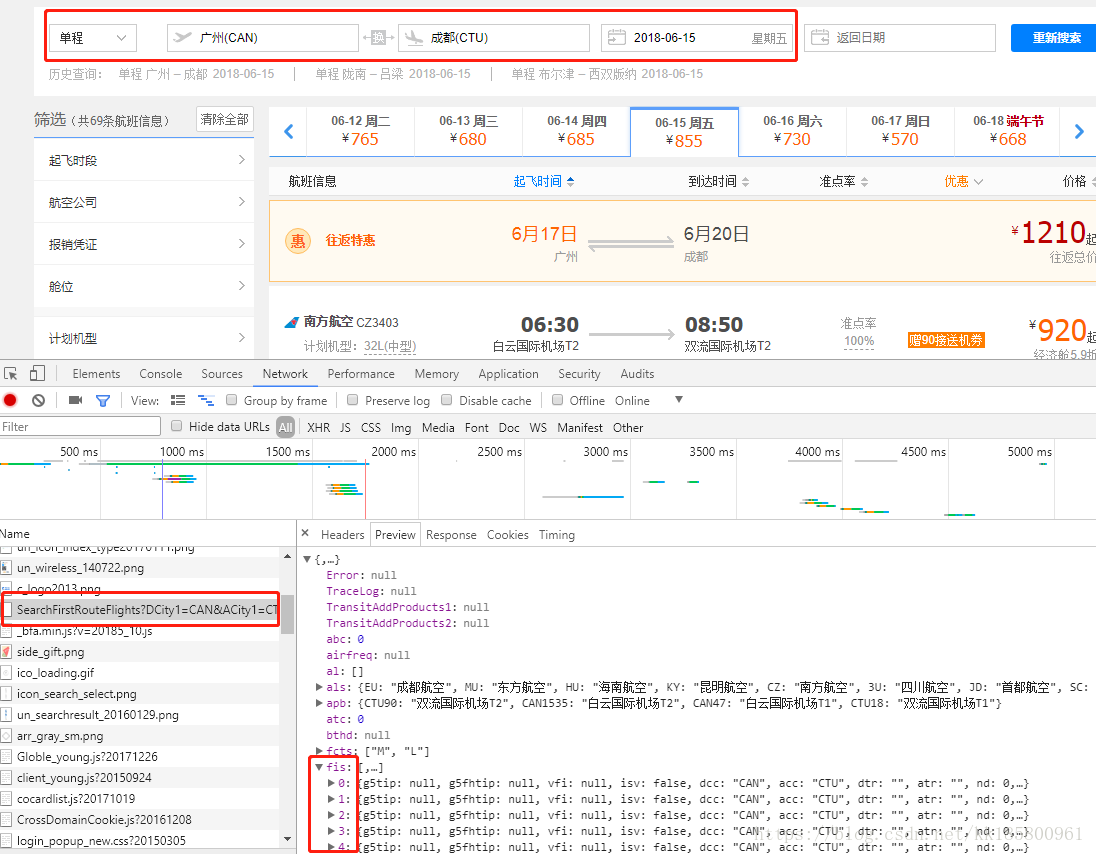
每一次爬取只要替换城市代码和日期即可,城市代码自己手动整理了一份:
city={"YIE":"阿尔山","AKU":"阿克苏","RHT":"阿拉善右旗","AXF":"阿拉善左旗","AAT":"阿勒泰","NGQ":"阿里","MFM":"澳门"
,"AQG":"安庆","AVA":"安顺","AOG":"鞍山","RLK":"巴彦淖尔","AEB":"百色","BAV":"包头","BSD":"保山","BHY":"北海","BJS":"北京"
,"DBC":"白城","NBS":"白山","BFJ":"毕节","BPL":"博乐","CKG":"重庆","BPX":"昌都","CGD":"常德","CZX":"常州"
,"CHG":"朝阳","CTU":"成都","JUH":"池州","CIF":"赤峰","SWA":"潮州","CGQ":"长春","CSX":"长沙","CIH":"长治","CDE":"承德"
,"CWJ":"沧源","DAX":"达州","DLU":"大理","DLC":"大连","DQA":"大庆","DAT":"大同","DDG":"丹东","DCY":"稻城","DOY":"东营"
,"DNH":"敦煌","DAX":"达县","LUM":"德宏","EJN":"额济纳旗","DSN":"鄂尔多斯","ENH":"恩施","ERL":"二连浩特","FUO":"佛山"
,"FOC":"福州","FYJ":"抚远","FUG":"阜阳","KOW":"赣州","GOQ":"格尔木","GYU":"固原","GYS":"广元","CAN":"广州","KWE":"贵阳"
,"KWL":"桂林","HRB":"哈尔滨","HMI":"哈密","HAK":"海口","HLD":"海拉尔","HDG":"邯郸","HZG":"汉中","HGH":"杭州","HFE":"合肥"
,"HTN":"和田","HEK":"黑河","HET":"呼和浩特","HIA":"淮安","HJJ":"怀化","TXN":"黄山","HUZ":"惠州","JXA":"鸡西","TNA":"济南"
,"JNG":"济宁","JGD":"加格达奇","JMU":"佳木斯","JGN":"嘉峪关","SWA":"揭阳","JIC":"金昌","KNH":"金门","JNZ":"锦州"
,"CYI":"嘉义","JHG":"景洪","JSJ":"建三江","JJN":"晋江","JGS":"井冈山","JDZ":"景德镇","JIU":"九江","JZH":"九寨沟","KHG":"喀什"
,"KJH":"凯里","KGT":"康定","KRY":"克拉玛依","KCA":"库车","KRL":"库尔勒","KMG":"昆明","LXA":"拉萨","LHW":"兰州","HZH":"黎平"
,"LJG":"丽江","LLB":"荔波","LYG":"连云港","LPF":"六盘水","LFQ":"临汾","LZY":"林芝","LNJ":"临沧","LYI":"临沂","LZH":"柳州"
,"LZO":"泸州","LYA":"洛阳","LLV":"吕梁","JMJ":"澜沧","LCX":"龙岩","NZH":"满洲里","LUM":"芒市","MXZ":"梅州","MIG":"绵阳"
,"OHE":"漠河","MDG":"牡丹江","MFK":"马祖" ,"KHN":"南昌","NAO":"南充","NKG":"南京","NNG":"南宁","NTG":"南通","NNY":"南阳"
,"NGB":"宁波","NLH":"宁蒗","PZI":"攀枝花","SYM":"普洱","NDG":"齐齐哈尔","JIQ":"黔江","IQM":"且末","BPE":"秦皇岛","TAO":"青岛"
,"IQN":"庆阳","JUZ":"衢州","RKZ":"日喀则","RIZ":"日照","SYX":"三亚","XMN":"厦门","SHA":"上海","SZX":"深圳","HPG":"神农架"
,"SHE":"沈阳","SJW":"石家庄","TCG":"塔城","HYN":"台州","TYN":"太原","YTY":"泰州","TVS":"唐山","TCZ":"腾冲","TSN":"天津"
,"THQ":"天水","TGO":"通辽","TEN":"铜仁","TLQ":"吐鲁番","WXN":"万州","WEH":"威海","WEF":"潍坊","WNZ":"温州","WNH":"文山"
,"WUA":"乌海","HLH":"乌兰浩特","URC":"乌鲁木齐","WUX":"无锡","WUZ":"梧州","WUH":"武汉","WUS":"武夷山","SIA":"西安","XIC":"西昌"
,"XNN":"西宁","JHG":"西双版纳","XIL":"锡林浩特","DIG":"香格里拉(迪庆)","XFN":"襄阳","ACX":"兴义","XUZ":"徐州","HKG":"香港"
,"YNT":"烟台","ENY":"延安","YNJ":"延吉","YNZ":"盐城","YTY":"扬州","LDS":"伊春","YIN":"伊宁","YBP":"宜宾","YIH":"宜昌"
,"YIC":"宜春","YIW":"义乌","INC":"银川","LLF":"永州","UYN":"榆林","YUS":"玉树","YCU":"运城","ZHA":"湛江","DYG":"张家界"
,"ZQZ":"张家口","YZY":"张掖","ZAT":"昭通","CGO":"郑州","ZHY":"中卫","HSN":"舟山","ZUH":"珠海","WMT":"遵义(茅台)","ZYI":"遵义(新舟)"}
为了防止频繁请求出现 429,UserAgent 也找多一些让其随机取值。但是有时候太频繁则需要输入验证码,所以还是每爬取一个出发城市,暂停10秒钟吧。
先创建表用于存储数据,此处用的是 SQL Server:
CREATE TABLE KKFlight( ID int IDENTITY(1,1), --自增ID ItinerarDate date, --行程日期 Airline varchar(100), --航空公司 AirlineCode varchar(100), --航空公司代码 FlightNumber varchar(20), --航班号 FlightNumberS varchar(20), --航班号-共享(实际航班) Aircraft varchar(50), --飞机型号 AircraftSize char(2), --型号大小(L大;M中;S小) AirportTax decimal(10,2), --机场建设费 FuelOilTax decimal(10,2), --燃油税 FromCity varchar(50), --出发城市 FromCityCode varchar(10), --出发城市代码 FromAirport varchar(50), --出发机场 FromTerminal varchar(20), --出发航站楼 FromDateTime datetime, --出发时间 ToCity varchar(50), --到达城市 ToCityCode varchar(10), --到达城市代码 ToAirport varchar(50), --到达机场 ToTerminal varchar(20), --到达航站楼 ToDateTime datetime, --到达时间 DurationHour int, --时长(小时h) DurationMinute int, --时长(分钟m) Duration varchar(20), --时长(字符串) Currency varchar(10), --币种 TicketPrices decimal(10,2), --票价 Discount decimal(4,2), --已打折扣 PunctualityRate decimal(4,2), --准点率 AircraftCabin char(1), --仓位(F头等舱;C公务舱;Y经济舱) InsertDate datetime default(getdate()), --添加时间 )
因为是爬取所有城市,所以城市不限制,只限制日期,即爬取哪天至哪天的数据。全部脚本如下:
#-*- coding: utf-8 -*-
# python 3.5.0
import json
import time
import random
import datetime
import sqlalchemy
import urllib.request
import pandas as pd
from operator import itemgetter
from dateutil.parser import parse
class FLIGHT(object):
def __init__(self):
self.Airline = {} #航空公司代码
self.engine = sqlalchemy.create_engine("mssql+pymssql://kk:kk@HZC/Myspider")
self.url = ''
self.headers = {}
self.city={"AAT":"阿勒泰","ACX":"兴义","AEB":"百色","AKU":"阿克苏","AOG":"鞍山","AQG":"安庆","AVA":"安顺","AXF":"阿拉善左旗","BAV":"包头","BFJ":"毕节","BHY":"北海"
,"BJS":"北京","BPE":"秦皇岛","BPL":"博乐","BPX":"昌都","BSD":"保山","CAN":"广州","CDE":"承德","CGD":"常德","CGO":"郑州","CGQ":"长春","CHG":"朝阳","CIF":"赤峰"
,"CIH":"长治","CKG":"重庆","CSX":"长沙","CTU":"成都","CWJ":"沧源","CYI":"嘉义","CZX":"常州","DAT":"大同","DAX":"达县","DBC":"白城","DCY":"稻城","DDG":"丹东"
,"DIG":"香格里拉(迪庆)","DLC":"大连","DLU":"大理","DNH":"敦煌","DOY":"东营","DQA":"大庆","DSN":"鄂尔多斯","DYG":"张家界","EJN":"额济纳旗","ENH":"恩施"
,"ENY":"延安","ERL":"二连浩特","FOC":"福州","FUG":"阜阳","FUO":"佛山","FYJ":"抚远","GOQ":"格尔木","GYS":"广元","GYU":"固原","HAK":"海口","HDG":"邯郸"
,"HEK":"黑河","HET":"呼和浩特","HFE":"合肥","HGH":"杭州","HIA":"淮安","HJJ":"怀化","HKG":"香港","HLD":"海拉尔","HLH":"乌兰浩特","HMI":"哈密","HPG":"神农架"
,"HRB":"哈尔滨","HSN":"舟山","HTN":"和田","HUZ":"惠州","HYN":"台州","HZG":"汉中","HZH":"黎平","INC":"银川","IQM":"且末","IQN":"庆阳","JDZ":"景德镇"
,"JGD":"加格达奇","JGN":"嘉峪关","JGS":"井冈山","JHG":"西双版纳","JIC":"金昌","JIQ":"黔江","JIU":"九江","JJN":"晋江","JMJ":"澜沧","JMU":"佳木斯","JNG":"济宁"
,"JNZ":"锦州","JSJ":"建三江","JUH":"池州","JUZ":"衢州","JXA":"鸡西","JZH":"九寨沟","KCA":"库车","KGT":"康定","KHG":"喀什","KHN":"南昌","KJH":"凯里","KMG":"昆明"
,"KNH":"金门","KOW":"赣州","KRL":"库尔勒","KRY":"克拉玛依","KWE":"贵阳","KWL":"桂林","LCX":"龙岩","LDS":"伊春","LFQ":"临汾","LHW":"兰州","LJG":"丽江","LLB":"荔波"
,"LLF":"永州","LLV":"吕梁","LNJ":"临沧","LPF":"六盘水","LUM":"芒市","LXA":"拉萨","LYA":"洛阳","LYG":"连云港","LYI":"临沂","LZH":"柳州","LZO":"泸州"
,"LZY":"林芝","MDG":"牡丹江","MFK":"马祖","MFM":"澳门","MIG":"绵阳","MXZ":"梅州","NAO":"南充","NBS":"白山","NDG":"齐齐哈尔","NGB":"宁波","NGQ":"阿里"
,"NKG":"南京","NLH":"宁蒗","NNG":"南宁","NNY":"南阳","NTG":"南通","NZH":"满洲里","OHE":"漠河","PZI":"攀枝花","RHT":"阿拉善右旗","RIZ":"日照","RKZ":"日喀则"
,"RLK":"巴彦淖尔","SHA":"上海","SHE":"沈阳","SIA":"西安","SJW":"石家庄","SWA":"揭阳","SYM":"普洱","SYX":"三亚","SZX":"深圳","TAO":"青岛","TCG":"塔城","TCZ":"腾冲"
,"TEN":"铜仁","TGO":"通辽","THQ":"天水","TLQ":"吐鲁番","TNA":"济南","TSN":"天津","TVS":"唐山","TXN":"黄山","TYN":"太原","URC":"乌鲁木齐","UYN":"榆林","WEF":"潍坊"
,"WEH":"威海","WMT":"遵义(茅台)","WNH":"文山","WNZ":"温州","WUA":"乌海","WUH":"武汉","WUS":"武夷山","WUX":"无锡","WUZ":"梧州","WXN":"万州","XFN":"襄阳","XIC":"西昌"
,"XIL":"锡林浩特","XMN":"厦门","XNN":"西宁","XUZ":"徐州","YBP":"宜宾","YCU":"运城","YIC":"宜春","YIE":"阿尔山","YIH":"宜昌","YIN":"伊宁","YIW":"义乌","YNJ":"延吉"
,"YNT":"烟台","YNZ":"盐城","YTY":"扬州","YUS":"玉树","YZY":"张掖","ZAT":"昭通","ZHA":"湛江","ZHY":"中卫","ZQZ":"张家口","ZUH":"珠海","ZYI":"遵义(新舟)"}
"""{"KJI":"布尔津"}"""
self.UserAgent = [
"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.36 Safari/535.7",
"Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:16.0) Gecko/16.0 Firefox/16.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/534.55.3 (KHTML, like Gecko) Version/5.1.3 Safari/534.53.10",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1500.55 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_2) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1309.0 Safari/537.17"
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11"
]
#遍历两个日期间的所有日期
def set_url_headers(self,startdate,enddate):
startDate=datetime.datetime.strptime(startdate,'%Y-%m-%d')
endDate=datetime.datetime.strptime(enddate,'%Y-%m-%d')
while startDate<=endDate:
today = startDate.strftime('%Y-%m-%d')
for fromcode, fromcity in sorted(self.city.items(), key=itemgetter(0)):
for tocode, tocity in sorted(self.city.items(), key=itemgetter(0)):
if fromcode != tocode:
self.url = 'http://flights.ctrip.com/domesticsearch/search/SearchFirstRouteFlights?DCity1=%s&ACity1=%s&SearchType=S&DDate1=%s&IsNearAirportRecommond=0&LogToken=027e478a47494975ad74857b18283e12&rk=4.381066884522498182534&CK=9FC7881E8F373585C0E5F89152BC143D&r=0.24149333708195565406316' % (fromcode,tocode,today)
self.headers = {
"Host": "flights.ctrip.com",
"User-Agent": random.choice(self.UserAgent),
"Referer": "https://flights.ctrip.com/booking/%s-%s-day-1.html?DDate1=%s" % (fromcode,tocode,today),
"Connection": "keep-alive",
}
print("%s : %s(%s) ==> %s(%s) " % (today,fromcity,fromcode,tocity,tocode))
self.get_parse_json_data(today)
time.sleep(10)
startDate+=datetime.timedelta(days=1)
#获取一个页面中的数据
def get_one_page_json_data(self):
req = urllib.request.Request(self.url,headers=self.headers)
body = urllib.request.urlopen(req,timeout=30).read().decode('gbk')
jsonData = json.loads(body.strip("'<>() ").replace('\'', '\"'))
return jsonData
#获取一个页面中的数据,解析保存到数据库
def get_parse_json_data(self,today):
jsonData = self.get_one_page_json_data()
df = pd.DataFrame(columns=['ItinerarDate','Airline','AirlineCode','FlightNumber','FlightNumberS','Aircraft','AircraftSize'
,'AirportTax','FuelOilTax','FromCity','FromCityCode','FromAirport','FromTerminal','FromDateTime','ToCity','ToCityCode','ToAirport'
,'ToTerminal','ToDateTime','DurationHour','DurationMinute','Duration','Currency','TicketPrices','Discount','PunctualityRate','AircraftCabin'])
if bool(jsonData["fis"]):
#获取航空公司代码及公司名称
company = jsonData["als"]
for k in company.keys():
if k not in self.Airline:
self.Airline[k]=company[k]
index = 0
for data in jsonData["fis"]:
df.loc[index,'ItinerarDate'] = today #行程日期
#df.loc[index,'Airline'] = self.Airline[data["alc"].strip()] #航空公司
df.loc[index,'Airline'] = self.Airline[data["alc"].strip()] if (data["alc"].strip() in self.Airline) else None #航空公司
df.loc[index,'AirlineCode'] = data["alc"].strip() #航空公司代码
df.loc[index,'FlightNumber'] = data["fn"] #航班号
df.loc[index,'FlightNumberS'] = data["sdft"] #共享航班号(实际航班)
df.loc[index,'Aircraft'] = data["cf"]["c"] #飞机型号
df.loc[index,'AircraftSize'] = data["cf"]["s"] #型号大小(L大;M中;S小)
df.loc[index,'AirportTax'] = data["tax"] #机场建设费
df.loc[index,'FuelOilTax'] = data["of"] #燃油税
df.loc[index,'FromCity'] = data["acn"] #出发城市
df.loc[index,'FromCityCode'] = data["acc"] #出发城市代码
df.loc[index,'FromAirport'] = data["apbn"] #出发机场
df.loc[index,'FromTerminal'] = data["asmsn"] #出发航站楼
df.loc[index,'FromDateTime'] = data["dt"] #出发时间
df.loc[index,'ToCity'] = data["dcn"] #到达城市
df.loc[index,'ToCityCode'] = data["dcc"] #到达城市代码
df.loc[index,'ToAirport'] = data["dpbn"] #到达机场
df.loc[index,'ToTerminal'] = data["dsmsn"] #到达航站楼
df.loc[index,'ToDateTime'] = data["at"] #到达时间
df.loc[index,'DurationHour'] = int((parse(data["at"])-parse(data["dt"])).seconds/3600) #时长(小时h)
df.loc[index,'DurationMinute'] = int((parse(data["at"])-parse(data["dt"])).seconds%3600/60) #时长(分钟m)
df.loc[index,'Duration'] = str(df.loc[index,'DurationHour']) + 'h' + str(df.loc[index,'DurationMinute']) + 'm' #时长(字符串)
df.loc[index,'Currency'] = None #币种
df.loc[index,'TicketPrices'] = data["lp"] #票价
df.loc[index,'Discount'] = None #已打折扣
df.loc[index,'PunctualityRate'] = None #准点率
df.loc[index,'AircraftCabin'] = None #仓位(F头等舱;C公务舱;Y经济舱)
index = index + 1
df.to_sql("KKFlight", self.engine, index=False, if_exists='append')
print("done!~")
if __name__ == "__main__":
fly = FLIGHT()
fly.set_url_headers('2018-06-16','2018-06-16')
总结
以上所述是小编给大家介绍的Python 爬取携程所有机票,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
python用线性回归预测股票价格的实现代码
线性回归在整个财务中广泛应用于众多应用程序中.在之前的教程中,我们使用普通最小二乘法(OLS)计算了公司的beta与相对索引的比较.现在,我们将使用线性回归来估计股票价格. 线性回归是一种用于模拟因变量(y)和自变量(x)之间关系的方法.通过简单的线性回归,只有一个自变量x.可能有许多独立变量属于多元线性回归的范畴.在这种情况下,我们只有一个自变量即日期.对于第一个日期上升到日期向量长度的整数,该日期将由1开始的整数表示,该日期可以根据时间序列数据而变化.当然,我们的因变量将是股票的价格.为了理
-

用Python抢过年的火车票附源码
前言:大家跟我一起念,Python大法好,跟着本宝宝用Python抢火车票 首先我们需要splinter 安装: pip install splinter -i http://pypi.douban.com/simple --trusted-host pypi.douban.com 然后还需要一个浏览器的驱动,当然用chrome啦 下载地址: http://chromedriver.storage.googleapis.com/index.html?path=2.20/ 根据下载的自己的电脑系统
-
python自动12306抢票软件实现代码
昨天我发的是抓取的12306数据包,然后分析了一下,今天按照昨天的分析 用代码实现了,如果有需要的同学们可以看一下,实现的功能有,登录,验证码识别,自动查票,有余票点击预定, 差了最后一步提交订单.同学们可以自己研究一下. import requests import time import dmpt import re import random from copyheaders import headers_raw_to_dict DEFAULT_HEADERS={ 'Host':'kyfw
-
Python实现12306火车票抢票系统
Python实现12306火车票抢票系统效果图如下所示: 具体代码如下所示: import urllib.request as request import http.cookiejar as cookiejar import re import os import smtplib from email.mime.text import MIMEText import time user = '' #登陆邮箱 pwd = ''#邮箱密码 to = [''] #发送的邮箱 with open('D
-
通过python3实现投票功能代码实例
这篇文章主要介绍了通过python3实现投票功能代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 import urllib.request # cd C:\Python36-32\Scripts # pip install BeautifulSoup from bs4 import BeautifulSoup def vote(get_url, post_url, option): # 访问投票页面,拿到cookie resp = ur
-
python3使用pandas获取股票数据的方法
如下所示: from pandas_datareader import data, wb from datetime import datetime import matplotlib.pyplot as plt end = datetime.now() start = datetime(end.year - 1, end.month, end.day) alibaba = data.DataReader('BABA', 'yahoo', start, end) alibaba['Adj Clo
-
Python 爬取携程所有机票的实例代码
打开携程网,查询机票,如广州到成都. 这时网址为:http://flights.ctrip.com/booking/CAN-CTU-day-1.html?DDate1=2018-06-15 其中,CAN 表示广州,CTU 表示成都,日期 "2018-06-15"就比较明显了.一般的爬虫,只有替换这几个值,就可以遍历了.但观察发现,有个链接可以看到当前网页的所有json格式的数据.如下 http://flights.ctrip.com/domesticsearch/search/Sear
-
python 爬取B站原视频的实例代码
B站原视频爬取,我就不多说直接上代码.直接运行就好. B站是把视频和音频分开.要把2个合并起来使用.这个需要分析才能看出来.然后就是登陆这块是比较难的. import os import re import argparse import subprocess import prettytable from DecryptLogin import login '''B站类''' class Bilibili(): def __init__(self, username, password, **
-
使用python爬取抖音app视频的实例代码
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例. 编程工具:pycharm app抓包工具:mitmproxy app自动化工具:appium 运行环境:windows10 思路: 假设已经配置好我们所需要的工具 1.使用mitmproxy对手机app抓包获取我们想要的内容 2.利用appium自动化测试工具,驱动app模拟人的动作(滑动.点击等) 3.将1和2相结合达到自动化爬虫的效果 一.mitmproxy/mitmdump抓包 确保已经安装好了mitmproxy,并
-
Python爬虫实战之爬取携程评论
一.分析数据源 这里的数据源是指html网页?还是Aajx异步.对于爬虫初学者来说,可能不知道怎么判断,这里辰哥也手把手过一遍. 提示:以下操作均不需要登录(当然登录也可以) 咱们先在浏览器里面搜索携程,然后在携程里面任意搜索一个景点:长隆野生动物世界,这里就以长隆野生动物世界为例,讲解如何去爬取携程评论数据. 页面下方则是评论数据 从上面两张图可以看出,点击评论下一页,浏览器的链接没有变化,说明数据是Ajax异步请求.因此我们就找到了数据是异步加载过来的,这时候需要去network里面是查
-
python爬取安居客二手房网站数据(实例讲解)
是小打小闹 哈哈,现在开始正式进行爬虫书写首先,需要分析一下要爬取的网站的结构:作为一名河南的学生,那就看看郑州的二手房信息吧! 在上面这个页面中,我们可以看到一条条的房源信息,从中我们发现了什么,发现了连郑州的二手房都是这么的贵,作为即将毕业的学生狗惹不起啊惹不起 还是正文吧!!!由上可以看到网页一条条的房源信息,点击进去后就会发现: 房源的详细信息.OK!那么我们要干嘛呢,就是把郑州这个地区的二手房房源信息都能拿到手,可以保存到数据库中,用来干嘛呢,作为一个地理人,还是有点用处的,这次就不说
-
Python爬虫实现爬取京东手机页面的图片(实例代码)
实例如下所示: __author__ = 'Fred Zhao' import requests from bs4 import BeautifulSoup import os from urllib.request import urlretrieve class Picture(): def __init__(self): self.headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleW
-
python爬取cnvd漏洞库信息的实例
今天一同事需要整理http://ics.cnvd.org.cn/工控漏洞库里面的信息,一看960多个要整理到什么时候才结束. 所以我决定写个爬虫帮他抓取数据. 看了一下各类信息还是很规则的,感觉应该很好写. but这个网站设置了各种反爬虫手段. 经过各种百度,还是解决问题了. 设计思路: 1.先抓取每一个漏洞信息对应的网页url 2.获取每个页面的漏洞信息 # -*- coding: utf-8 -*- import requests import re import xlwt import t
-
python爬取盘搜的有效链接实现代码
因为盘搜搜索出来的链接有很多已经失效了,影响找数据的效率,因此想到了用爬虫来过滤出有效的链接,顺便练练手~ 这是本次爬取的目标网址http://www.pansou.com,首先先搜索个python,之后打开开发者工具, 可以发现这个链接下的json数据就是我们要爬取的数据了,把多余的参数去掉, 剩下的链接格式为http://106.15.195.249:8011/search_new?q=python&p=1,q为搜索内容,p为页码 以下是代码实现: import requests impor
-
使用Python爬取弹出窗口信息的实例
此文仅当学习笔记用. 这个实例是在Python环境下如何爬取弹出窗口的内容,有些时候我们要在页面中通过点击,然后在弹出窗口中才有我们要的信息,所以平常用的方法也许不行. 这里我用到的是Selenium这个工具, 不知道的朋友可以去搜索一下. 但是安装也是很费事的. 而且我用的浏览器是firefox,不用IE是因为好像新版的IE在Selenium下有问题,我也是百思不得其解, 网上也暂时没找到好的办法. from selenium import webdriver from selenium.we
-
python爬取2021猫眼票房字体加密实例
春节假期刚过,大家有没有看春节档的电影呢?今年的春节档电影很是火爆,我们可以在猫眼票房app查看有关数据,因为数据一致在更新,所以他的字体是动态的,想要爬取有些困难,再加上猫眼app对字体进行加密,该如何爬取呢?本文介绍反爬2021猫眼票房字体加密的实例. 一.字体加密原理 简单来说就是程序员在设计网站的时候使用了自己设计的字体代码对关键字进行编码,在浏览器加载的时会根据这个字体文件对这些字体进行编码,从而显示出正确的字体. 二.爬取实例 1.得到字体斜率字典 import requestsim