对pandas处理json数据的方法详解
今天展示一个利用pandas将json数据导入excel例子,主要利用的是pandas里的read_json函数将json数据转化为dataframe。
先拿出我要处理的json字符串:
strtext='[{"ttery":"min","issue":"20130801-3391","code":"8,4,5,2,9","code1":"297734529","code2":null,"time":1013395466000},\
{"ttery":"min","issue":"20130801-3390","code":"7,8,2,1,2","code1":"298058212","code2":null,"time":1013395406000},\
{"ttery":"min","issue":"20130801-3389","code":"5,9,1,2,9","code1":"298329129","code2":null,"time":1013395346000},\
{"ttery":"min","issue":"20130801-3388","code":"3,8,7,3,3","code1":"298588733","code2":null,"time":1013395286000},\
{"ttery":"min","issue":"20130801-3387","code":"0,8,5,2,7","code1":"298818527","code2":null,"time":1013395226000}]'
pandas.read_json的语法如下:
pandas.read_json(path_or_buf=None, orient=None, typ='frame', dtype=True, convert_axes=True, convert_dates=True, keep_default_dates=True, numpy=False, precise_float=False, date_unit=None, encoding=None, lines=False, chunksize=None, compression='infer')
第一参数就是json文件路径或者json格式的字符串。
第二参数orient是表明预期的json字符串格式。orient的设置有以下几个值:
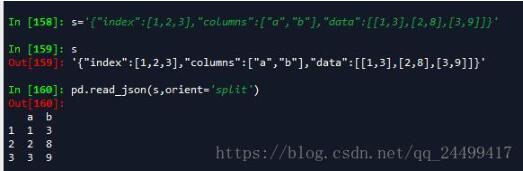
(1).'split' : dict like {index -> [index], columns -> [columns], data -> [values]}
这种就是有索引,有列字段,和数据矩阵构成的json格式。key名称只能是index,columns和data。
'records' : list like [{column -> value}, ... , {column -> value}]
这种就是成员为字典的列表。如我今天要处理的json数据示例所见。构成是列字段为键,值为键值,每一个字典成员就构成了dataframe的一行数据。
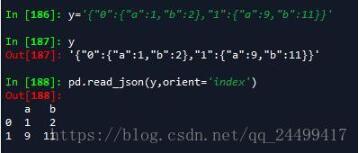
'index' : dict like {index -> {column -> value}}
以索引为key,以列字段构成的字典为键值。如:
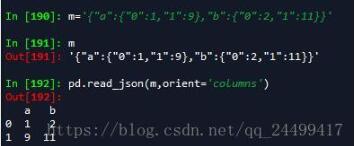
'columns' : dict like {column -> {index -> value}}
这种处理的就是以列为键,对应一个值字典的对象。这个字典对象以索引为键,以值为键值构成的json字符串。如下图所示:
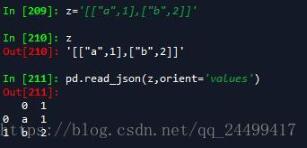
'values' : just the values array。
values这种我们就很常见了。就是一个嵌套的列表。里面的成员也是列表,2层的。
主要就说下这两个参数吧。下面我们回到示例中来。我们看前面可以发现示例是一个orient为records的json字符串。
这样就好处理了。看代码:
# -*- coding: utf-8 -*-
"""
Created on Sun Aug 5 09:01:38 2018
@author: FanXiaoLei
"""
import pandas as pd
strtext='[{"ttery":"min","issue":"20130801-3391","code":"8,4,5,2,9","code1":"297734529","code2":null,"time":1013395466000},\
{"ttery":"min","issue":"20130801-3390","code":"7,8,2,1,2","code1":"298058212","code2":null,"time":1013395406000},\
{"ttery":"min","issue":"20130801-3389","code":"5,9,1,2,9","code1":"298329129","code2":null,"time":1013395346000},\
{"ttery":"min","issue":"20130801-3388","code":"3,8,7,3,3","code1":"298588733","code2":null,"time":1013395286000},\
{"ttery":"min","issue":"20130801-3387","code":"0,8,5,2,7","code1":"298818527","code2":null,"time":1013395226000}]'
df=pd.read_json(strtext,orient='records')
df.to_excel('pandas处理json.xlsx',index=False,columns=["ttery","issue","code","code1","code2","time"])
最终写入excel如下图:
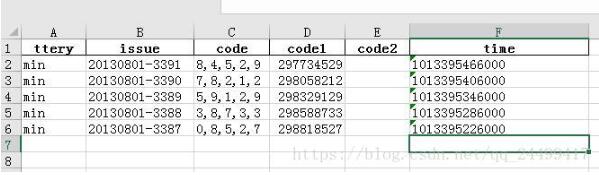
以上这篇pandas处理json数据就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

js中innerText/textContent和innerHTML与target和currentTarget的区别
一.获取/赋值文本值innerText/textContent.innerHTML <body> <div id="box_text"> <p style="color:hotpink;">muzidigbig</p> <p style="color:pink">lovely</p> </div> <input type="text" i
-
JSON的parse()方法介绍
parse()方法的介绍: 在接收服务器数据时一般是字符串. 我们可以使用 JSON.parse() 方法将数据转换为 JavaScript 对象. 语法 JSON.parse(text[, reviver]) 参数说明: text:必需, 一个有效的 JSON 字符串. reviver: 可选,一个转换结果的函数, 将为对象的每个成员调用此函数. 下面我们来看一个实例: <p id="demo"></p> <script> var obj = JS
-
JS实现的点击按钮图片上下滚动效果示例
本文实例讲述了JS实现的点击按钮图片上下滚动效果.分享给大家供大家参考,具体如下: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <style> *{ margin: 0; padding:0; list-style: none; } .big{ width: 2
-
JSON.stringify()方法讲解
JSON.stringify()方法是什么呢? 我们在向服务器发送数据时一般是字符串. 我们可以使用 JSON.stringify() 方法将 JavaScript 对象转换为字符串. 语法 JSON.stringify(value[, replacer[, space]]) 参数说明: value: 必需,一个有效的 JSON 对象. replacer: 可选.用于转换结果的函数或数组. 如果 replacer 为函数,则 JSON.stringify 将调用该函数,并传入每个成员的键和值.使
-
Javascript删除数组里的某个元素
删除数组中的某个元素,首先需要确定需要删除元素的索引值. var arr=[1,5,6,12,453,324]; function indexOf(val){ for(var i = 0; i < arr.length; i++){ if(arr[i] == val){return i;} } return -1; } 找到相对应的索引值后,根据索引值删除数组中该元素对应的值 function remove(val){ var index = indexOf(val); if(index >
-
jQuery.parseJSON()函数详解
jQuery.parseJSON()函数用于将格式完好的JSON字符串转为与之对应的JavaScript对象. 所谓"格式完好",就是要求指定的字符串必须符合严格的JSON格式,例如:属性名称必须加双引号.字符串值也必须用双引号. 如果传入一个格式不"完好"的JSON字符串将抛出一个JS异常,例如:以下字符串均符合JSON格式,但它们不是格式完好的JSON字符串(因此会抛出异常): // 以下均是字符串值,省略了两侧的引号,以便于展现内容 {id: 1} // id
-
Vue.js实现开发购物车功能的方法详解
本文实例讲述了Vue.js实现开发购物车功能的方法.分享给大家供大家参考,具体如下: 购物车一般包含商品名称.单价.数量等信息,数量可以任意新增或减少,商品项也可删除,还可以支持全选或多选: 我们把这个小项目分为三个文件: index.html (页面) index.js (Vue 脚本) style.css (样式) 1 index.js 首先在 js 中初始化 Vue 实例,整体模板如下: var app = new Vue({ el: '#app', data: { ... }, moun
-
JS异步执行结果获取的3种解决方式
前言 JS异步执行机制具有非常重要的地位,尤其体现在回调函数和事件等方面. 但异步有时候很方便,有时候却很让人恼火,下面来总结一下异步执行结果获取的方法 回调 这是最传统的方法了,也是最简单的,如下代码 function foo(cb) { setTimeout(function() { cb(1); // 通过参数把结果返回 }, 2000); } foo(function(result) { // 调用foo方法的时候,通过回调把方法返回的数据取出来 console.log(result);
-
JavaScript中.min.js和.js文件的区别讲解
Q&A Q: .js和.min.js文件分别是什么? A: .js是JavaScript 源码文件, .min.js是压缩版的js文件. Q:为什么要压缩为.min.js文件? 减小体积 .min.js文件经过压缩,相对编译前的js文件体积较小,传输效率快. 防止窥视和窃取源代码 经过编码将变量和函数原命名改为毫无意义的命名,以防止他人窥视和窃取 js 源代码 Q:.js 和.min.js文件的优缺点? .js文件: 优点: 可读性较好,易于debug和更改. 缺点:体积较大,传输时
-
Python常用的json标准库
当请求 headers 中,添加一个name为 Accept,值为 application/json 的 header(也即"我"(浏览器)接收的是 json 格式的数据),这样,向服务器请求返回的未必一定是 HTML 页面,也可能是 JSON 文档. 1. 数据交换格式 -- JSON(JavaScript Object Notation) http 1.1 规范 请求一个特殊编码的过程在 http1.1 规范中称为内容协商(content negotiation) JSON 特点