基于C中一个行压缩图的简单实现代码
首先简单说一下什么是行压缩图,其实严格意义上应该是行压缩矩阵。正常情况下,矩阵是用二维数组简单存储的,但是如果是稀疏矩阵,也就是零很多的时候,这样比较浪费空间。所以就有各种节省空间的存储方式,三元组存储就是其中一种。
什么是三元组呢?一个三元组就是(row,col,value),这样把所有不为零的值组成一个向量。这种存储方式比二维数组节省了不少空间,当然还可以进一步节省,因为三元组里面row或者col重复存储了,一行或者一列存一次就行了,按这种思路走下去就是行压缩存储了。
那具体什么是行压缩存储呢?行压缩存储的思想就是,把所有不为零的值按行访问的顺序组成一个向量,然后再把每一行值不为0的列的下标存下来,这个两个向量的大小和稀疏矩阵中不为0的值得个数相同,当然要实现对行压缩矩阵的访问,还要把每一行的不为0的列的下标在第二个向量中开始的位置存下来,有人把这个叫做指针。有了这三个向量就可以实现对矩阵实现高效的按行访问了。行压缩存储比三元组优秀的不仅是空间的压缩,还有就是行访问时的高效。三元组如果是有序的,可以二分查找来访问一行,但是行压缩存储按行访问时的时间复杂度是常数级的。 大家可以参考下面这个行压缩矩阵示意图:
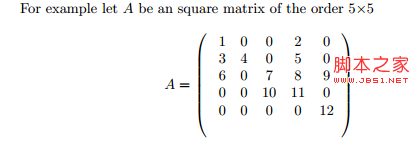

可能你会有疑问,你明明实现的行压缩图,怎么扯了这么多行压缩矩阵呢?其实图和矩阵是等价的,矩阵的一行可以看做是图一个节点的出边,矩阵的一列可以看做图一个节点的入边。当然这里需要满足两个条件:第一个就是图节点编号必须是从0或者1开始的连续数值(这个可以通过对图的节点做一次映射解决),第二个就是图必须至少是弱连通的(非连通图可以拆成连图片)。实现了稀疏矩阵的高效存储访问,也就实现了图的高效存储访问。
下面来说一下,我的实现。我的实现跟经典的行压缩矩阵有两个不同:第一个就是经典的行压缩矩阵没有考虑一行全为0的情况,我对这种情况做了处理(之所以处理当然不是因为我无聊,而是因为有这个需求)。第二个就是经典的行压缩图对按列访问比较慢(当然是相对于按行访问的速度而言),对行压缩图按列访问时,时间复杂度是线性的。我也对这种情况做了处理。
这里简单说一下我的思路:
第一个问题,我是通过将所有指针默认设为-1,即表示该行可能全为0,只有当有非零值时才设置为其正确的指针。当然访问时也要做相应的处理。
第二个问题,我是这样解决的。我按列压缩存储的方式,存了一份每一列不为0的行下标,以及每一列不为0的行下标开始的位置。这样我的实现中就多了两个向量,浪费了存储空间,但是提高了按列访问时的效率。
好了,talk is cheap,show me the code。下面是我的代码(可能有错,我只做了简单的测试)
/*
* buildGraph 利用边向量 构造压缩图
* 对边分别按第一个顶点、第二个顶点排序
* 然后分别按行压缩图和列压缩图构造行、列索引和指针
* 全零行和全零列,指针置为-1
*/
private void buildGraph(Vector<Edge> edges) {
int edgeSize = edges.size();
weight = new Vector<Float>(edgeSize);
rowIndex = new Vector<Integer>(edgeSize);
rowPtr = new Vector<Integer>(nodeCount + 1);
colIndex = new Vector<Integer>(edgeSize);
colPtr = new Vector<Integer>(nodeCount + 1);
// set default value as -1
for (int i = 0; i < nodeCount; ++i) {
rowPtr.add(-1);
colPtr.add(-1);
}
rowPtr.add(edges.size());
colPtr.add(edges.size());
// sort the edge based on first node
EdgeBasedOnFirstNodeComparator cmp = new EdgeBasedOnFirstNodeComparator();
Collections.sort(edges, cmp);
// build row index and pointer
int curNode = edges.elementAt(0).getFirstNode();
int curPtr = 0;
for (int i = 0; i < edgeSize; ++i) {
Edge e = edges.elementAt(i);
// System.out.println("curNode" + curNode + "firstNode: "
// + e.getFirstNode());
weight.add(e.getWeight());
rowIndex.add(e.getSecondNode());
if (curNode != e.getFirstNode()) {
rowPtr.set(curNode, curPtr);
curNode = e.getFirstNode();
curPtr = i;
}
}
rowPtr.set(curNode, curPtr);
// sort the edge based on second node
EdgeBasedOnSecondNodeComparator cmp2 = new EdgeBasedOnSecondNodeComparator();
Collections.sort(edges, cmp2);
// build column index and pointer
curNode = edges.elementAt(0).getSecondNode();
curPtr = 0;
for (int i = 0; i < edgeSize; ++i) {
Edge e = edges.elementAt(i);
colIndex.add(e.getFirstNode());
if (curNode != e.getSecondNode()) {
colPtr.set(curNode, curPtr);
curNode = e.getSecondNode();
curPtr = i;
}
}
colPtr.set(curNode, curPtr);
}
获得一个节点的出边
/*
* getOutEdges 返回结点所有的出边(即所有由结点指出的边)
*
* @param node 要查找的结点
*
* @return 返回结点所有的出边组成的向量
*/
@Override
public Vector<Edge> getOutEdges(int node) {
Vector<Edge> res = new Vector<Edge>();
int startIndex = getStartIndex(node, true);
if (startIndex == -1) {
// 没有出边的点
return null;
}
int endIndex = getEndIndex(node, true);
float value;
Edge e;
int outNode;
for (int index = startIndex; index < endIndex; ++index) {
value = weight.elementAt(index);
outNode = rowIndex.elementAt(index);
e = new Edge(node, outNode, value);
res.add(e);
}
return res;
}
获得一个节点的入边
?
/*
* getInEdges 获取结点所有的入边(即所有指向结点的边)
*
* @param node 要查找的结点
*
* @return 返回所有由结点入边组成的向量
*/
@Override
public Vector<Edge> getInEdges(int node) {
Vector<Edge> res = new Vector<Edge>();
int startIndex = getStartIndex(node, false);
// 没有入边的点
if (startIndex == -1) {
return null;
}
int endIndex = getEndIndex(node, false);
float value;
Edge e;
int inNode;
for (int index = startIndex; index < endIndex; ++index) {
inNode = colIndex.elementAt(index);
value = getWeight(inNode, node);
e = new Edge(inNode, node, value);
res.add(e);
}
return res;
}
这里访问方式就跟按行访问不一样了,行访问时,直接读weight向量里面对应的值就行了,这里不行,应该weight向量是按行访问顺序存的。我的解决方法,获取入节点,然后对整个节点对按行访问获得对应值。这样虽然绕了一下,但是对于稀疏图来说,基本上也是常数级的。下面是getWeight的代码
代码如下:
/*
* getWeight 获得特定边的weight
*/
private float getWeight(int row, int col) {
int startIndex = getStartIndex(row, true);
if(startIndex==-1)
return 0;
int endIndex = getEndIndex(row, true);
for (int i = startIndex; i < endIndex; ++i) {
if (rowIndex.elementAt(i) == col)
return weight.elementAt(i);
}
return 0;
}
最后是对行或者列全0时的特殊处理,这里处理,体现在从指针向量获取开始和结束位置的函数上
代码如下:
/*
* getStartIndex 获取特定顶点的开始索引
*/
private int getStartIndex(int node, boolean direction) {
// true : out edge
if (direction)
return rowPtr.elementAt(node);
else
return colPtr.elementAt(node);
}
?
/*
* getEndIndex 获取特定顶点的结束索引
*/
private int getEndIndex(int node, boolean direction) {
// true:out edge
if (direction) {
int i = 1;
while ((node + i) < nodeCount) {
if (rowPtr.elementAt(node + i) != -1)
return rowPtr.elementAt(node + i);
else
++i;
}
return rowPtr.elementAt(nodeCount);
} else {
int i = 1;
while ((node + i) < nodeCount) {
if (colPtr.elementAt(node + i) != -1)
return colPtr.elementAt(node + i);
else
++i;
}
return colPtr.elementAt(nodeCount);
}
}
这里我只实现了两个最简单的功能,获取入边和出边。一方面是因为,对于我做的东西,这两个函数就够了,另一方面,对于一个图来说,有这两个函数,其他函数都可以相应实现。
相关推荐
-

基于C中一个行压缩图的简单实现代码
首先简单说一下什么是行压缩图,其实严格意义上应该是行压缩矩阵.正常情况下,矩阵是用二维数组简单存储的,但是如果是稀疏矩阵,也就是零很多的时候,这样比较浪费空间.所以就有各种节省空间的存储方式,三元组存储就是其中一种. 什么是三元组呢?一个三元组就是(row,col,value),这样把所有不为零的值组成一个向量.这种存储方式比二维数组节省了不少空间,当然还可以进一步节省,因为三元组里面row或者col重复存储了,一行或者一列存一次就行了,按这种思路走下去就是行压缩存储了. 那具体什么是行压缩存储
-
详解基于electron制作一个node压缩图片的桌面应用
基于electron制作一个node压缩图片的桌面应用 下载地址:https://github.com/zenoslin/imagemin-electron/releases 项目源码Github:https://github.com/zenoslin/imagemin-electron 准备工作 我们来整理一下我们需要做什么: 压缩图片模块 获取文件路径 桌面应用生成 压缩图片 我们需要使用imagemin这个库来压缩图片,这里我们把这个库封装成压缩模块. const imagemin = r
-
基于ElementUI中Table嵌套实现多选的示例代码
前言: 写这个是因为帮朋友修改项目中的bug 我也是第一次写这个功能,有不对的希望大家指正,如果看完有帮助点个赞! 代码中关键是js中Tree的路径查找这个核心,有不懂的自行百度 多了不说了,有需要的可以私信找我要代码,来看下我怎么实现的 思路: 从头开始看这个需求,我们需要知道用到哪写东西 1.表格Table 2.多选&全选 3.嵌套数据(下拉操作) 正好我们可以找下ElementUI官方文档 找到了我们需要用到的API 在嵌套数据的时候需要使用tree-props 选中数据的时候使用togg
-
基于Python编写一个计算器程序,实现简单的加减乘除和取余二元运算
方法一: 结合lambda表达式.函数调用运算符.标准库函数对象.C++11标准新增的标准库function类型,编写一个简单的计算器,可实现简单的加.减.乘.除.取余二元运算.代码如下: #include "pch.h" #include <iostream> #include <functional> #include <map> #include <string> using namespace std; int add(int i
-
基于Python编写一个计算器程序,实现简单的加减乘除和取余二元运算
方法一: 结合lambda表达式.函数调用运算符.标准库函数对象.C++11标准新增的标准库function类型,编写一个简单的计算器,可实现简单的加.减.乘.除.取余二元运算.代码如下: #include "pch.h" #include <iostream> #include <functional> #include <map> #include <string> using namespace std; int add(int i
-
基于TensorBoard中graph模块图结构分析
在上一篇文章中,我们介绍了如何使用源码对TensorBoard进行编译教程,没有定制需求的可以直接使用pip进行安装. TensorBoard中的graph是一种计算图,里面的点用于表示Tensor本身或者运算符,图中的边则代表Tensor的流动或者控制关系. 本文主要从代码的层面,分析graph的数据来源与结构. 一般来说,我们在启动TensorBoard的时候会使用--logdir参数配置文件路径(或者设置数据库位置),这些日志文件为TensorBoard提供了数据.于是我们打开一个日志文件
-
基于python使用Pillow做动态图在图中生成二维码以及图像处理
目录 1.什么是Pillow 2.pillow图像处理的简单使用 图片信息显示 修改图片尺寸 裁剪旋转图片 为图片添加水印 生成gif图片 1.什么是Pillow 首先我们需要了解一下PIL(Python Imaging Library),它是Python2中非常强大的图像处理标准库,但只支持到Python2.7.Pillow是在PIL的基础上创建了兼容的版本,支持最新Python 3.x,又加入了许多新特性. 安装: pip install pillow 其中Image是pillow库的一个常
-
python统计一个文本中重复行数的方法
本文实例讲述了python统计一个文本中重复行数的方法.分享给大家供大家参考.具体实现方法如下: 比如有下面一个文件 2 3 1 2 我们期望得到 2,2 3,1 1,1 解决问题的思路: 出现的文本作为key, 出现的数目作为value,然后按照value排除后输出 最好按照value从大到小输出出来,可以参照: 复制代码 代码如下: in recent Python 2.7, we have new OrderedDict type, which remembers the order in
-
PHP基于反射获取一个类中所有的方法
本文实例讲述了PHP基于反射获取一个类中所有的方法.分享给大家供大家参考,具体如下: 当我们使用一个类时既没有源码也没有文档时(尤其是php扩展提供的类,比如mysqli,Redis类),我们该怎么知道这个类中提供了哪些方法,以及每个方法该怎么使用呢,此时就该PHP中强大的反射登场了,下面以Redis扩展为例用代码演示: <?php $ref = new ReflectionClass('Redis'); $consts = $ref->getConstants(); //返回所有常量名和值
-
Vue项目中使用better-scroll实现一个轮播图自动播放功能
前言 better-scroll是一个非常非常强大的第三方库 在移动端利用这个库 不仅可以实现一个非常类似原生ScrollView的效果 也可以实现一个轮播图的效果 这里就先记录一下自己实现这个效果的一些过程吧 思路 1.首先要确定自己的HTML结构 基本结构就是一个wrapper包含一个content 2.其次需要明白的一个页面可以滚动的原理在于 当内容的高度超出了容器的高度才可以实现滚动 如果没有超出 那么就没有滚动的必要 因此第一点需要实现的就是 获取到所有内容的高度 由于实现的是一个轮播