SQL Server中参数化SQL写法遇到parameter sniff ,导致不合理执行计划重用的快速解决方法
parameter sniff问题是重用其他参数生成的执行计划,导致当前参数采用该执行计划非最优化的现象。想必熟悉数据的同学都应该知道,产生parameter sniff最典型的问题就是使用了参数化的SQL(或者存储过程中使用了参数化)写法,如果存在数据分布不均匀的情况下,正常情况下生成的执行计划,在传入在分布数据较多的参数的情况下,重用了正常参数生成的执行计划,而这种缓存的执行计划并非适合当前参数的一种情况。
这种情况,在实际业务中,出现的频率还是比较高的,因为存储过程一般都是采用参数化的写法,这时,遇到分布不均匀的数据参数时,parameter sniff现象就出现了,这种问题还是比较让人头疼的。
具体parameter sniff产生的原因,我就不做过多的解释了,解释这个就显得太low了
我举个简单的例子,模拟一下这个现象,说明参数化的存存储过程是怎么写的,存在哪些问题,又如何解决parameter sniff问题,
先创建一个测试环境:
create table ParameterSniffProblem ( id int identity(1,1), CustomerId int, OrderId int, OrederStatus int, CreateDate Datetime, Remark varchar(200) ) declare @i int = 0 while @i<500000 begin INSERT INTO ParameterSniffProblem values (@i%10000,@i,RAND()*10,GETDATE()-RAND()*100,NEWID()) set @i=@i+1 end --假如某一个客户有非常多的订单,模拟数据分布不均匀的情况 INSERT INTO ParameterSniffProblem values (6666,RAND()*100000,1,GETDATE()-RAND()*100,NEWID()) GO 100000 --创建正常的索引 CREATE CLUSTERED INDEX IDX_CreateDate on ParameterSniffProblem(CreateDate )CREATE INDEX IDX_CustomerId ON ParameterSniffProblem(CustomerId)
参数化存储过程的写法:
在编写存储过程的时候,我们一般建议采用参数化的写法,目的是为了减少存储过程的编译和加强执行计划缓存的重用
大概是这样子的
CREATE PROCEDURE [dbo].ParameterSniffTest ( @p_CustomerId int, @p_Status int, @p_FromDate datetime, @p_ToDate datetime ) AS BEGIN SET NOCOUNT ON DECLARE @Parm NVARCHAR(MAX), @sqlcommand NVARCHAR(MAX) = N'' SET @sqlcommand = 'SELECT * FROM ParameterSniffProblem WHERE 1=1' IF(@p_CustomerId IS NOT NULL) SET @sqlcommand = CONCAT(@sqlcommand,'AND CustomerId=@p_CustomerId ') IF(@p_Status IS NOT NULL) SET @sqlcommand = CONCAT(@sqlcommand,'AND OrederStatus=@p_Status ') IF(@p_FromDate IS NOT NULL) SET @sqlcommand = CONCAT(@sqlcommand,'AND CreateDate>=@p_FromDate ') IF(@p_ToDate IS NOT NULL) SET @sqlcommand = CONCAT(@sqlcommand,'AND CreateDate<=@p_ToDate ') SET @Parm= '@p_CustomerId int, @p_Status int, @p_FromDate datetime, @p_ToDate datetime ' EXEC sp_executesql @sqlcommand,@Parm, @p_CustomerId = @p_CustomerId, @p_Status = @p_Status, @p_FromDate = @p_FromDate, @p_ToDate = @p_ToDate END GO
Parameter Sniff问题:
这就潜在一个parameter sniff问题,
比如我查询用户ID=100的订单信息,一个正常的分布的数据,存储过程第一次编译,这个执行计划完全没有问题,
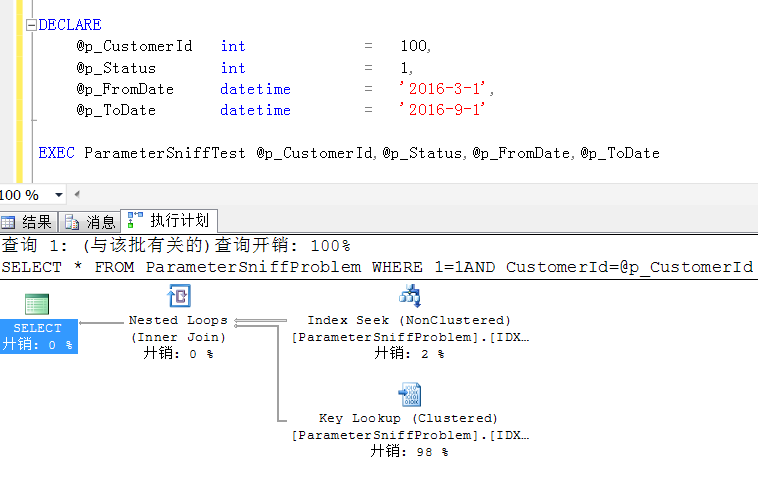
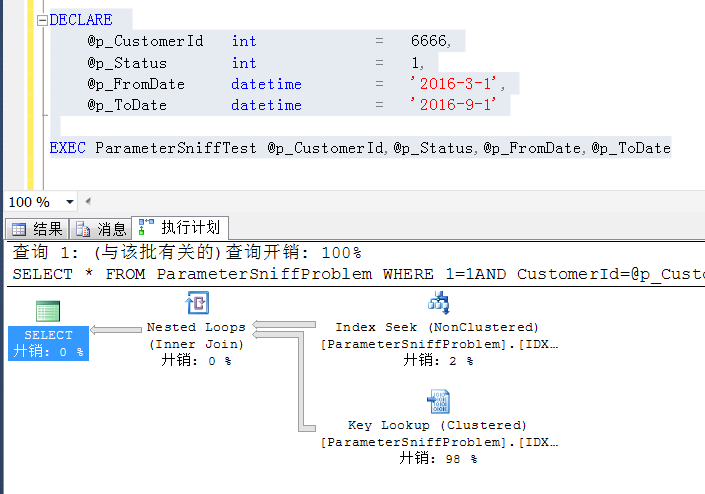
如果我接着改变参数执行查询用户6666的信息,一个分布及其不均匀的数据,但是因为重用上面缓存的执行计划,就出现parameter sniff问题了,这个执行计划显然是不合理的
IO就不看了,刻意造的例子
如果我清空执行计划缓存,重新执行上述查询,因为有了重编译,执行计划就是不这个样子,对于CustomerID=6666这个参数来说,显然走全表扫描代价要更小一点
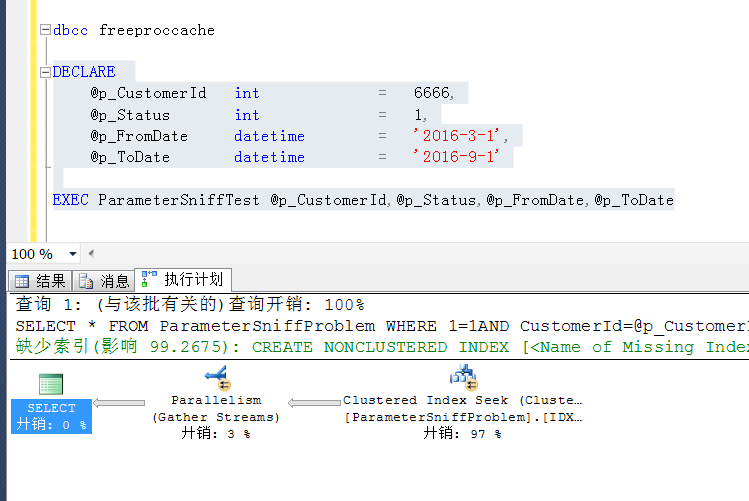
想必这是一个开发中常见的问题给,我们参数化SQL就是为了让不同参数的查询重用执行计划,但是很不幸,数据分布不均匀的时候,重用执行计划恰恰又给数据库造成了伤害,例中,如果是正常参数重用了分布较多数据的执行计划,比如命名可以用到索引,结果是表扫描,后果会更严重。
那么,既想要尽可能的重用执行计划,又要避免因为执行计划重用产生parameter sniff问题,怎么办?
我们知道问题在于@p_CustomerId身上,那么可不可以对有可能产生parameter sniff问题的@p_CustomerId不做参数化,直接拼凑在SQL中,如果@p_CustomerId变化了就重编译SQL,也就是对传入进来的@p_CustomerId重编译
如果是@p_CustomerId不变,其他参数有变化,比如这里时间字段的变化,还可以享受参数化带来的执行计划重用的好处 也就是这样处理 @p_CustomerId这个参数,直接把@p_CustomerId以字符串的方式平凑在SQL语句中,这样的话,就相当于即席查询了,不通过参数化的方式给CustomerId这个查询条件字段赋值
IF(@p_CustomerId IS NOT NULL) SET @sqlcommand = CONCAT(@sqlcommand,'AND CustomerId= ',@p_CustomerId)
这样再去执行存储过程的时候,
带入@p_CustomerId=1的时候,执行IDX_CustomerId的index seek
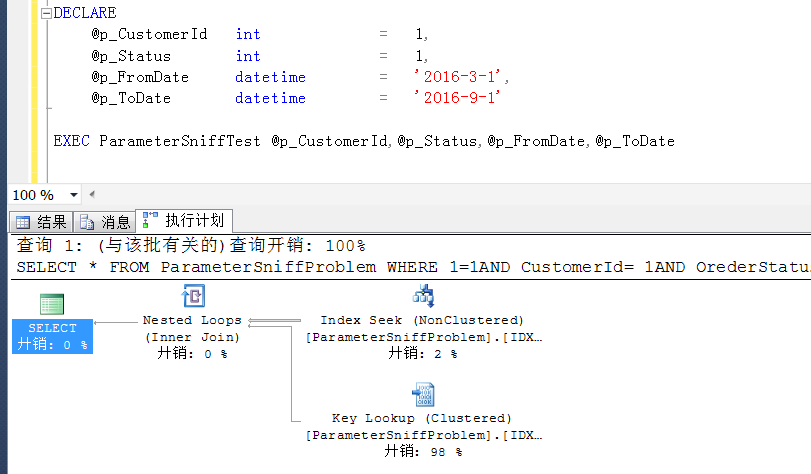
带入@p_CustomerId=6666的时候,重编译,执行计划是全表扫描,避免重用上面生成的执行计划,造成不合理的执行方式对效率以及数据库服务器资源的消耗
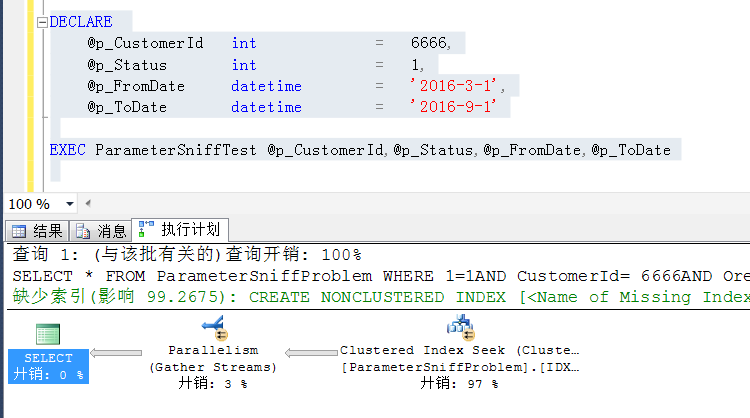
这样会尽可能的减少parameter sniff问题带来的影响,当缓存了@p_CustomerId=1的执行计划的时候,再次传入@p_CustomerId=1,其他条件有较小的变化,比如时间字段上有改动,依然可以重用缓存的执行计划,避免重编译带来的影响
结论:
这种方式于处理parameter sniff问题,当然不是完美的,肯定也有问题,我当然知道一旦@p_CustomerId不同就要重编译
肯定会因为@p_CustomerId参数值不同,这样的话,不可避免地增加了重编译的机会,
但是却不会因为不合理的执行计划重用,带来的parameter sniff问题
要知道一旦产生parameter sniff问题,大量的查询用到不合理的执行计划,会对整个服务器产生非常严重的影响,比如可能会产生大量的IO等
同时存在一个好处,比如第一次传入@p_CustomerId=1,
再次传入@p_CustomerId=1,其他条件有较小的变化,比如时间字段上有改动,依然可以重用缓存的执行计划,避免重编译带来的影响当然我这里只是一个简单的例子,实际应用中远远比这个复杂
比如分布的特别的多的数据有两个特点,第一分布的标示不仅仅只有一个,第二分布不均的数据是动态的,有可能第一季度是A这部分数据占据大多数,有可能是第二季度B数据占绝大多数
所以很难采用Plan Guide的方式解决parameter sniff问题
这种方式可以在一定程度上也能够重用缓存的执行计划,可以减少(但不可避免)重编译的次数
同时,这种方式与拼凑一个SQL字符串执行的即席查询方式相比,同时还可以利用参数化带来的其他好处,比如SQL注入等等
总结:
parameter sniff问题的解决方式有很多,不一一啰嗦了
最典型的就是强制重编译,
或者使用EXEC执行一个拼凑出来的字符串,这种方式属于Adhoc查询
或者查询提示,
或者是使用本地变量,
或者使用Plan Guide等等等等,
每种方式都有他的局限性,至少到目前为止,还没有一种十全十美的方式来解决parameter sniff问题
遇到问题,解决方法有很多种,以最小的代价解决问题才是王道。
相关推荐
-

MySQL中主键索引与聚焦索引之概念的学习教程
主键索引 主键索引,简称主键,原文是PRIMARY KEY,由一个或多个列组成,用于唯一性标识数据表中的某一条记录.一个表可以没有主键,但最多只能有一个主键,并且主键值不能包含NULL. 在MySQL中,InnoDB数据表的主键设计我们通常遵循几个原则: 采用一个没有业务用途的自增属性列作为主键: 主键字段值总是不更新,只有新增或者删除两种操作: 不选择会动态更新的类型,比如当前时间戳等. 这么做的好处有几点: 新增数据时,由于主键值是顺序增长的,innodb page发生分裂的概率降低了:可以
-
SqlServer 执行计划及Sql查询优化初探
网上的SQL优化的文章实在是很多,说实在的,我也曾经到处找这样的文章,什么不要使用IN了,什么OR了,什么AND了,很多很多,还有很多人拿出仅几S甚至几MS的时间差的例子来证明着什么(有点可笑),让许多人不知道其是对还是错.而SQL优化又是每个要与数据库打交道的程序员的必修课,所以写了此文,与朋友们共勉. 谈到优化就必然要涉及索引,就像要讲锁必然要说事务一样,所以你需要了解一下索引,仅仅是索引,就能讲半天了,所以索引我就不说了(打很多字是很累的,况且我也知之甚少),可以去参考相关的文章,这个网上
-
浅析SQL Server 聚焦索引对非聚集索引的影响
前言 在学习SQL 2012基础教程过程中会时不时穿插其他内容来进行讲解,相信看过SQL Server 2012 T-SQL基础教程的童鞋知道前面写的所有内容并非都是摘抄书上内容,如若是这样那将没有任何意义,学习的过程必须同时也是一个思考的过程,无论是独立思考也好还是查资料也罢都是思考而非走马观花,要不然过一段时间又会健忘.简短的内容,深入的理解. 话题 非聚集索引定义:非聚集索引也是一个B树结构,与聚集索引不同的是,B树的叶子节点存的是指向堆或聚集索引的指针.你真的理解了吗??你能举出例子吗?
-
浅析SQL Server中的执行计划缓存(下)
在上篇文章给大家介绍了SQL Server中的执行计划缓存(上),本文继续给大家介绍sqlserver执行计划缓存相关知识,小伙伴们一起学习吧. 简介 在上篇文章中我们谈到了查询优化器和执行计划缓存的关系,以及其二者之间的冲突.本篇文章中,我们会主要阐述执行计划缓存常见的问题以及一些解决办法. 将执行缓存考虑在内时的流程 上篇文章中提到了查询优化器解析语句的过程,当将计划缓存考虑在内时,首先需要查看计划缓存中是否已经有语句的缓存,如果没有,才会执行编译过程,如果存在则直接利用编译好的执行计划.因
-
浅析SQL Server中的执行计划缓存(上)
简介 我们平时所写的SQL语句本质只是获取数据的逻辑,而不是获取数据的物理路径.当我们写的SQL语句传到SQL Server的时候,查询分析器会将语句依次进行解析(Parse).绑定(Bind).查询优化(Optimization,有时候也被称为简化).执行(Execution).除去执行步骤外,前三个步骤之后就生成了执行计划,也就是SQL Server按照该计划获取物理数据方式,最后执行步骤按照执行计划执行查询从而获得结果.但查询优化器不是本篇的重点,本篇文章主要讲述查询优化器在生成执行计划之
-
强制SQL Server执行计划使用并行提升在复杂查询语句下的性能
通过观察执行计划,发现之前的执行计划在很多大表连接的部分使用了Hash Join,由于涉及的表中数据众多,因此查询优化器选择使用并行执行,速度较快.而我们优化完的执行计划由于索引的存在,且表内数据非常大,过滤条件的值在一个很宽的统计信息步长范围内,导致估计行数出现较大偏差(过滤条件实际为15000行,步长内估计的平均行数为800行左右),因此查询优化器选择了Loop Join,且没有选择并行执行,因此执行时间不降反升. 由于语句是在存储过程中实现,因此我们直接对该语句使用一个undocument
-
浅析SQL Server的聚焦使用索引和查询执行计划
前言 上一篇<浅析SQL Server 聚焦索引对非聚集索引的影响>我们讲了聚集索引对非聚集索引的影响,对数据库一直在强调的性能优化,所以这一节我们统筹讲讲利用索引来看看查询执行计划是怎样的,简短的内容,深入的理解. 透过索引来看查询执行计划 我们首先来看看第一个例子 1.默认使用索引 USE TSQL2012 GO SELECT orderid FROM Sales.Orders SELECT * FROM Sales.Orders 上述我们看到第2个查询的所需要的开销是第1个查询开销的3倍
-
SQLSERVER中得到执行计划的两种方式
得到执行计划的方式有两种: 1.一种是在指令的前面打开一些开关,让执行计划信息打在结果集里,这种方法比较适合在一个测试环境里对单个语句调优. 这些开关最常用的有 复制代码 代码如下: SET SHOWPLAN_ALL ON SET SHOWPLAN_ALL ON --(是不是reuse了一个执行计划,SQSERVERL有没有觉得缺少索引),只能在XML的输出里看到 SET STATISTICS PROFILE ON 还有如果使用SSMS的话,可以用快捷键:Ctrl+L 小写L 他会执行你的语句并
-
SQL Server中参数化SQL写法遇到parameter sniff ,导致不合理执行计划重用的快速解决方法
parameter sniff问题是重用其他参数生成的执行计划,导致当前参数采用该执行计划非最优化的现象.想必熟悉数据的同学都应该知道,产生parameter sniff最典型的问题就是使用了参数化的SQL(或者存储过程中使用了参数化)写法,如果存在数据分布不均匀的情况下,正常情况下生成的执行计划,在传入在分布数据较多的参数的情况下,重用了正常参数生成的执行计划,而这种缓存的执行计划并非适合当前参数的一种情况. 这种情况,在实际业务中,出现的频率还是比较高的,因为存储过程一般都是采用参数化的写法
-
Sql Server中通过sql命令获取cpu占用及产生锁的sql
获取SQLSERVER中产生锁的SQL语句 SELECT SUBSTRING(st.text, (qs.statement_start_offset/2) + 1,((CASE statement_end_offset WHEN -1 THEN DATALENGTH(st.text) ELSE qs.statement_end_offset END - qs.statement_start_offset)/2) + 1) as statement_text FROM sys.dm_exec_qu
-
SQL Server中的SQL语句优化与效率问题
很多人不知道SQL语句在SQL SERVER中是如何执行的,他们担心自己所写的SQL语句会被SQL SERVER误解.比如: select * from table1 where name='zhangsan' and tID > 10000 和执行: select * from table1 where tID > 10000 and name='zhangsan' 一些人不知道以上两条语句的执行效率是否一样,因为如果简单的从语句先后上看,这两个语句的确是不一样,如果tID是一个聚合索引,那
-
SQL Server中使用SQL语句实现把重复行数据合并为一行并用逗号分隔
一.定义表变量 复制代码 代码如下: DECLARE @T1 table ( UserID int , UserName nvarchar(50), CityName nvarchar(50) ); insert into @T1 (UserID,UserName,CityName) values (1,'a','上海') insert into @T1 (UserID,UserName,CityName) values (2,'b','北京') insert into @T1 (UserID,
-
使用sql server management studio 2008 无法查看数据库,提示 无法为该请求检索数据 错误916解决方法
今日使用时代互联的海外空间,sql 2008 无限空间大小,开通账户后,使用sql server management studio 2008 连接数据库,可以链接上,但是无法查看自己的数据库,点击数据库后,提示 无法为该请求检索数据 错误916 解决方法如下 1:点击左侧的数据库,然后到右侧的 "名称" 上面点击右键 出来如图所示的菜单,取消掉策略运行状态和排序规则,再次点击数据库的时候,就能显示所有的数据库以及你自己的数据库了.
-
在SQL Server中使用SQL语句查询一个存储过程被其它所有的存储过程引用的存储过程名
这个问题对于规模稍微大些的项目而言,显得尤其重要了,数据库中如果有几百个存储过程, 难道还一个个找不成,即使自己很了解业务和系统,时间长了,也难免能记得住. 如何使用SQL语句进行查询呢? 下面就和大家分享下SQL查询的方法: 复制代码 代码如下: select distinct name from syscomments a,sysobjects b where a.id=b.id and b.xtype='p' and text like '%pro_GetSN%' 上面的蓝色字体部分表示要
-
SQL Server 中查看SQL句子执行所用的时间
复制代码 代码如下: set statistics profile on set statistics io on set statistics time on go 你执行的SQL语句 复制代码 代码如下: go set statistics profile off set statistics io off set statistics time off 执行完后点消息即可.
-
安装SQL server 2005 出现警告 32位ASP.NET已经注册,需要注册64位的解决方法
可以运行以下两条命令: 1.将64位.net注册到iis上. cscript C:\inetpub\adminscripts\adsutil.vbs SET W3SVC/AppPools/Enable32bitAppOnWin64 0 和 C:\WINDOWS\Microsoft.NET\Framework64\v2.0.50727\aspnet_regiis.exe -i 2.注册32位.net: 不需要卸载32位,注册命令就是上面的命令.系统默认安装的是64位系统,但是由于客户程序大部分都是
-
在SQL Server中使用CLR调用.NET方法实现思路
介绍 我们一起来做个示例,在.NET中新建一个类,并在这个类里新建一个方法,然后在SQL Server中调用这个方法.按照微软所述,通过宿主 Microsoft .NET Framework 2.0 公共语言运行库 (CLR),SQL Server 2005显著地增强了数据库编程模型. 这使得开发人员可以用任何CLR语言(如C#.VB.NET或C++等)来写存储过程.触发器和用户自定义函数. 我们如何实现这些功能呢? 为了使用CLR,我们需要做如下几步: 1.在.NET中新建一个类,并在这个类里
-
在SQL Server中实现最短路径搜索的解决方法
开始这是去年的问题了,今天在整理邮件的时候才发现这个问题,感觉顶有意思的,特记录下来. 在表RelationGraph中,有三个字段(ID,Node,RelatedNode),其中Node和RelatedNode两个字段描述两个节点的连接关系:现在要求,找出从节点"p"至节点"j",最短路径(即经过的节点最少). 图1. 解析: 了能够更好的描述表RelationGraph中字段Node和 RelatedNode的关系,我在这里特意使用一个图形来描述,如图2. 图2