SQL Server简单查询示例汇总
前言
本节我们讲讲一些简单查询语句示例以及需要注意的地方,简短的内容,深入的理解。
EOMONTH
在SQL Server 2012的教程示例中,对于Sales.Orders表的查询,需要返回每月最后一天的订单。我们普遍的查询如下
USE TSQL2012 GO SELECT orderid, orderdate, custid, empid FROM Sales.Orders WHERE orderdate = DATEADD(MONTH, DATEDIFF(MONTH, '19991231', orderdate), '19991231')

但是在SQL Server 2012出现了新的函数直接返回每个月最后一天的订单,通过EOMONTH函数即可,将
WHERE orderdate = DATEADD(MONTH, DATEDIFF(MONTH, '19991231', orderdate), '19991231')
替换为
SELECT orderid, orderdate, custid, empid FROM Sales.Orders WHERE orderdate = EOMONTH(orderdate)
如上简单而粗暴。
HAVING AND WHERE
我们利用Sales.OrderDetails表来查询总价(qty*unitprice)大于10000的订单,且按照总价排序。
USE TSQL2012 GO SELECT orderid,SUM(unitprice *qty) AS TotalValue FROM Sales.OrderDetails GROUP BY orderid HAVING SUM(unitprice *qty) > 10000 ORDER BY TotalValue DESC

通过此例我们来说说WHERE和HAVING的区别,下面的示例是等同的
SELECT orderid FROM Sales.OrderDetails WHERE orderid >10357 GROUP BY orderid SELECT orderid FROM Sales.OrderDetails GROUP BY orderid HAVING orderid >10357
但是利用聚合函数时能等同吗?
SELECT orderid FROM Sales.OrderDetails WHERE COUNT(qty * unitprice) >10000 GROUP BY orderid SELECT orderid FROM Sales.OrderDetails GROUP BY orderid HAVING COUNT(qty * unitprice) >10000

二者的区别我们总结一下:
(1)WHERE能够用在UPDATE、DELETE、SELECT语句中,而HAVING只能用在SELECT语句中。
(2)WHERE过滤行在GROUP BY之前,而HAVING过滤行在GROUP BY之后。
(3)WHERE不能用在聚合函数中,除非该聚合函数位于HAVING子句或选择列表所包含的子查询中。
说了这么多,关于WHERE和HAVING的区别,其实WHERE的应用场景更多,我们归根结底一句话来概括的HAVING的用法即可。
HAVING仅仅在SELECT语句中对组(GROUP BY)或者聚合函数(AGGREGATE)进行过滤
INSERT TOP分析
当将查询出的数据插入到表中,我们其实有两种解决方案。
方案一
NSERT INTO TABLE … SELECT TOP (N) Cols… FROM Table
方案二
INSERT TOP(N) INTO TABLE … SELECT Cols… FROM Table
方案一是需要查询几条就插入几条,方案二则是查询所有我们需要插入几条数据,接下来我们来看看二者不同以及二者性能问题,创建查询表并插入数据。
CREATE TABLE TestValue(ID INT) INSERT INTO TestValue (ID) SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5
需要插入的两个表
USE TSQL2012 GO CREATE TABLE InsertTestValue (ID INT) CREATE TABLE InsertTestValue1 (ID INT)
方案一的插入
INSERT INTO InsertTestValue (ID) SELECT TOP (2) ID FROM TestValue ORDER BY ID DESC GO
方案二的插入
INSERT TOP (2) INTO InsertTestValue1 (ID) SELECT ID FROM TestValue ORDER BY ID DESC GO
接下来查询方案一和方案二的数据
SELECT * FROM InsertTestValue GO SELECT * FROM InsertTestValue1 GO

我们对方案一和方案二插入数据之前我们对查询的数据是进行了降序,此时我们能够很明显的看到方案一中的查询数据确确实实是降序,而方案二则忽略了降序,这是个很有意思的地方,至此我们看到了二者的不同。
二者性能比较
在插入数据时我们对其进行开销分析如下:
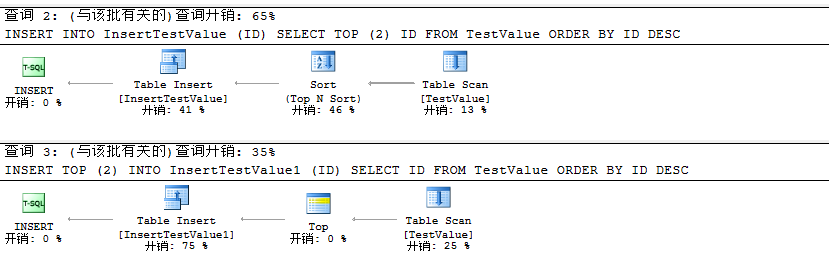
到这里我们能够知道利用INSET TOP (N)比INSERT … SELECT TOP (N)性能更好,同时SELECT TOP(N)会对查询出的数据排序进行忽略。至此我们可以得出如下结论
结论:INSERT TOP (N)比INSERT … SELECT TOP (N)插入数据性能更好。
COUNT(DISTINCT) AND COUNT(ALL)
关于DISTINCT就不用多讲,此关键字过滤重复针对的是所有列数据一致才过滤而不是针对于单列数据一致才过滤,我们看看COUNT(DISTINCT)和COUNT(ALL)查询出的数据是一致还是不一致呢?我们首先创建测试表
CREATE TABLE TestData ( Id INT NOT NULL IDENTITY PRIMARY KEY, NAME VARCHAR(max) NULL );
插入如下测试数据

接下来我们进行如下查询
USE TSQL2012 GO SELECT COUNT(NAME) AS COUNT_NAME FROM dbo.TestData SELECT COUNT(ALL NAME) AS COUNT_ALLNAME FROM dbo.TestData SELECT COUNT(DISTINCT NAME) AS COUNT_DISTINCTNAME FROM dbo.TestData

此时我们能够很清楚的看到COUNT(colName)和COUNT(ALL colName)的结果是一样的,其实COUNT(ALL colName)是默认的选项且包括所有非空值,换句话说ALL根本不需要我们去指定。
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流,同时也希望多多支持我们!
相关推荐
-

SQLSERVER分页查询关于使用Top方式和row_number()解析函数的不同
临近春节,心早已飞了不在工作上了,下面小编给大家整理些数据库的几种分页查询. Sql Sever 2005之前版本: select top 页大小 * from 表名 where id not in ( select top 页大小*(查询第几页-1) id from 表名 order by id ) order by id 例如: select top 10 * --10 为页大小 from [TCCLine].[dbo].[CLine_CommonImage] where id not in
-
在SQL SERVER中查询数据库中第几条至第几条之间的数据SQL语句写法
今天在写程序的时候,需要生成从开始id到结束id的sql语句.原来不需要这个功能现在就需要了. 在SQL SERVER中查询数据库中第几条至第几条之间的数据SQL语句如何写? 如:在SQL SERVER中查询数据库中第10条至30条之间的数据SQL语句如何写? ------解决方案-------------------- select top 20 * from 表 where id in (select top 30 id from 表 order by id)order by id desc
-
使用SqlServer CTE递归查询处理树、图和层次结构
CTE(Common Table Expressions)是从SQL Server 2005以后版本才有的.指定的临时命名结果集,这些结果集称为CTE. 与派生表类似,不存储为对象,并且只在查询期间有效.与派生表的不同之处在于,CTE 可自引用,还可在同一查询中引用多次.使用CTE能改善代码可读性,且不损害其性能. 递归CTE是SQL SERVER 2005中重要的增强之一.一般我们在处理树,图和层次结构的问题时需要用到递归查询. CTE的语法如下 WITH CTE AS ( SELECT Em
-
在sqlserver中如何使用CTE解决复杂查询问题
最近,同事需要从数个表中查询用户的业务和报告数据,写了一个SQL语句,查询比较慢: Select S.Name, S.AccountantCode, ( Select COUNT(*) from ( Select Distinct BusinessBackupId from Biz_BusinessBackupCustomer where Id in ( Select BusinessBackupCustomerId from Rpt_RegistForm where ( SignatureCP
-
SQL Server数据库按百分比查询出表中的记录数
SQL Server数据库查询时,能否按百分比查询出记录的条数呢?答案是肯定的.本文我们就介绍这一实现方法. 实现该功能的代码如下: create procedure pro_topPercent ( @ipercent [int] =0 --默认不返回 ) as begin select top (@ipercent ) percent * from books end 或 create procedure pro_topPercent ( @ipercent [int] =0 ) as be
-
SqlServer查询和Kill进程死锁的语句
查询死锁进程语句 select request_session_id spid, OBJECT_NAME(resource_associated_entity_id) tableName from sys.dm_tran_locks where resource_type='OBJECT' 杀死死锁进程语句 kill spid 下面再给大家分享一段关于sqlserver检测死锁;杀死锁和进程;查看锁信息 --检测死锁 --如果发生死锁了,我们怎么去检测具体发生死锁的是哪条SQL语句或存储过程?
-
SqlServer使用 case when 解决多条件模糊查询问题
我们在进行项目开发中,经常会遇到多条件模糊查询的需求.对此,我们常见的解决方案有两种:一是在程序端拼接SQL字符串,根据是否选择了某个条件,构造相应的SQL字符串:二是在数据库的存储过程中使用动态的SQL语句.其本质也是拼接SQL字符串,不过是从程序端转移到数据库端而已. 这两种方式的缺点是显而易见的:一是当多个条件每个都可为空时,要使用多个if语句进行判断:二是拼接的SQL语句容易产生SQL注入漏洞. 最近写数据库存储过程的时候经常使用case when 语句,正好可以用这个语句解决一下以上问
-
详解sqlserver查询表索引
SELECT 索引名称=a.name ,表名=c.name ,索引字段名=d.name ,索引字段位置=d.colid FROM sysindexes a JOIN sysindexkeys b ON a.id=b.id AND a.indid=b.indid JOIN sysobjects c ON b.id=c.id JOIN syscolumns d ON b.id=d.id AND b.colid=d.colid WHERE a.indid NOT IN(0,255) -- and
-
SQL Server查询前N条记录的常用方法小结
本文实例讲述了SQL Server查询前N条记录的常用方法.分享给大家供大家参考.具体如下: SQL Server查询前N条记录是我们经常要用到的操作,下面对SQL Server查询前N条记录的方法作了详细的介绍,如果您感兴趣的话,不妨一看. SQL Server查询前N条记录: 因为id可能不是连续的,所以不能用取得10<id<20的记录的方法. 有三种方法可以实现: 一.搜索前20条记录,指定不包括前10条 语句: 复制代码 代码如下: select top 20 * from tbl w
-
SQL Server 2016 查询存储性能优化小结
作为一个DBA,排除SQL Server问题是我们的职责之一,每个月都有很多人给我们带来各种不能解释却要解决的性能问题. 我就多次听到,以前的SQL Server的性能问题都还好且在正常范围内,但现在一切已经改变,SQL Server开始糟糕, 疯狂的事情不能解释.在这个情况下我介入,分析下整个SQL Server的安装,最后用一些神奇的调查方法找出性能问题的根源. 但很多时候问题的根源是一样的:所谓的计划回归(Plan Regression),即特定查询的执行计划已经改变.昨天SQL Serv
-
详解SQL Server的简单查询语句
前言 对于一些原理性文章园中已有大量的文章尤其是关于索引这一块,我也是花费大量时间去学习,对于了解索引原理对于后续理解查询计划和性能调优有很大的帮助,而我们只是一些内容进行概括和总结,这一节我们开始正式步入学习SQL中简单的查询语句,简短的内容,深入的理解. 简单查询语句 所有复杂的语句都是由简单的语句组成基本都是由SELECT.FROM.WHERE.GROUP BY.HAVING.ORDER BY等组成,当然还包括一些谓词等等.比如当我们要查询某表中所有数据时我们会像如下进行. SELECT