java 中模式匹配算法-KMP算法实例详解
java 中模式匹配算法-KMP算法实例详解
朴素模式匹配算法的最大问题就是太低效了。于是三位前辈发表了一种KMP算法,其中三个字母分别是这三个人名的首字母大写。
简单的说,KMP算法的对于主串的当前位置不回溯。也就是说,如果主串某次比较时,当前下标为i,i之前的字符和子串对应的字符匹配,那么不要再像朴素算法那样将主串的下标回溯,比如主串为“abcababcabcabcabcabc”,子串为“abcabx”.第一次匹配的时候,主串1,2,3,4,5字符都和子串相应的匹配,第6为‘c'与子串中的‘x'不匹配,说明此时i=6,下次匹配的时候,就不用再像朴素那样,将i置为2,再循环置为3,4,5去和子串匹配了。而是直接从i=6(以i=6为开头)开始和子串去进行匹配。
那么子串的下标的变化呢,是不是每次要从第一位开始去和主串匹配,实际上也不需要。还是上面的例子,第一次匹配后,子串的当前位置(下标)为j=6,因为前两位a,b和主串的4,5位的a,b已经比较完成,是匹配的,所以这两位也无需比较,也就是从j=3开始和主串匹配。现在的问题是,如何找到子串的下标j的变化。
我们把子串各个位置的j值得变化定义为1个数组next,那么next的长度就是T串的长度。于是可以得到下面的函数定义:
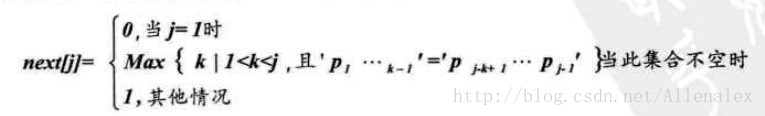
上图引用自《大话数据结构》,关于更多的KMP算法的说明,尤其是next[j]的推导,读者可以参考该书,讲解的非常的详细。下面给出该算法的java实现。
在《大话数据结构》,保存串的数组的首位,也就是0下标位置保存的是字符串的长度。但是上面的next[j]却可取值为0,这点我没有弄明白,如有哪位牛人能帮忙解释,万分感谢。下面编写的代码略有不同,在0下标位置不再是保存字符串的长度,而是保存字符串的首字符,也就是是与字符串对应的。所以next[j]的计算函数也不太一样,如下:

实现的代码:
public class Pattern_KMP {
public static void main(String args[])
{
int times;
String source="abcabaabcabcabxxzhabaabcabcabxad";
String subStr="abcabx";
times=pattren_KMP(source, subStr);
System.out.println("匹配次数:"+times);
}
static int pattren_KMP(String source,String subStr)
{
int len1,len2;
len1=source.length();
len2=subStr.length();
int i,j;
i=j=0;
int times=0;
while(i<len1)
{
if(source.charAt(i)==subStr.charAt(j))
{
i++;
j++;
}else
{
if(j==0)/*这一步很重要,如果没有会进入死循环,也就是,如果主串某位与子串*/
i++;/*第一位不等的话,必须往后移位。*/
j=next(subStr,j);
}
if(j==len2)
{
times++;
j=0;
}
}
return times;
}
static int next(String subStr,int j)
{
if(j==0)
return 0;
else {
int next=0;
int k=1;
int m1;
int m2;
int i,n;
/*这一循环对应实现上面函数的第二项*/
while(k<j)
{
String sub1="",sub2="";
for(m1=0,m2=j-k;m1<k&&m2<j;m1++,m2++)
{
sub1+=subStr.charAt(m1);
sub2+=subStr.charAt(m2);
}
for(i=0,n=0;i<sub1.length()&&n<sub2.length();i++,n++)
{
if(sub1.charAt(i)!=sub2.charAt(n))
break;
}
if(i==sub1.length()&&n==sub2.length())
next=k;
k++;
}
return next;
}
}
}
下面附上《大话数据结构》中的KMP算法(c代码)供对照参考(不是完整可执行程序)
/* 通过计算返回子串T的next数组。 */
void get_next(String T, int *next)
{
int i,j;
i=1;
j=0;
next[1]=0;
while (i<T[0]) /* 此处T[0]表示串T的长度 */
{
if(j==0 || T[i]== T[j]) /* T[i]表示后缀的单个字符,T[j]表示前缀的单个字符 */
{
++i;
++j;
next[i] = j;
}
else
j= next[j]; /* 若字符不相同,则j值回溯 */
}
}
/* 返回子串T在主串S中第pos个字符之后的位置。若不存在,则函数返回值为0。 */
/* T非空,1≤pos≤StrLength(S)。 */
int Index_KMP(String S, String T, int pos)
{
int i = pos; /* i用于主串S中当前位置下标值,若pos不为1,则从pos位置开始匹配 */
int j = 1; /* j用于子串T中当前位置下标值 */
int next[255]; /* 定义一next数组 */
get_next(T, next); /* 对串T作分析,得到next数组 */
while (i <= S[0] && j <= T[0]) /* 若i小于S的长度并且j小于T的长度时,循环继续 */
{
if (j==0 || S[i] == T[j]) /* 两字母相等则继续,与朴素算法增加了j=0判断 */
{
++i;
++j;
}
else /* 指针后退重新开始匹配 */
j = next[j];/* j退回合适的位置,i值不变 */
}
if (j > T[0])
return i-T[0];
else
return 0;
}
感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
相关推荐
-

Android Java实现余弦匹配算法示例代码
Java实现余弦匹配算法 最近在做一个通讯交友的项目,项目中有一个这样的需求,通过用户的兴趣爱好,为用户寻找推荐兴趣相近的好友.其实思路好简单,把用户的兴趣爱好和其他用户的兴趣爱好进行一个匹配,当他们的爱好相似度比较高的时候就给双方进行推荐.那么如何进行比较是一个问题,其实我们可以通过余弦匹配算法来对用户的兴趣爱好进行比较,根据计算出来的值来得到一个兴趣爱好相近好友列表,并进行排序. 因为我做的项目是Android端的,所以算法是通过Java实现的,废话不过多说了,下面是算法的实现: pack
-
java 合并排序算法、冒泡排序算法、选择排序算法、插入排序算法、快速排序算法的描述
算法是在有限步骤内求解某一问题所使用的一组定义明确的规则.通俗点说,就是计算机解题的过程.在这个过程中,无论是形成解题思路还是编写程序,都是在实施某种算法.前者是推理实现的算法,后者是操作实现的算法. 一个算法应该具有以下五个重要的特征: 1.有穷性: 一个算法必须保证执行有限步之后结束: 2.确切性: 算法的每一步骤必须有确切的定义: 3.输入:一个算法有0个或多个输入,以刻画运算对象的初始情况: 4.输出:一个算法有一个或多个输出,以反映对输入数据加工后的结果.没有输出的算法是毫无意义的:
-
基于Java实现的图的广度优先遍历算法
本文以实例形式讲述了基于Java的图的广度优先遍历算法实现方法,具体方法如下: 用邻接矩阵存储图方法: 1.确定图的顶点个数和边的个数 2.输入顶点信息存储在一维数组vertex中 3.初始化邻接矩阵: 4.依次输入每条边存储在邻接矩阵arc中 输入边依附的两个顶点的序号i,j: 将邻接矩阵的第i行第j列的元素值置为1: 将邻接矩阵的第j行第i列的元素值置为1: 广度优先遍历实现: 1.初始化队列Q 2.访问顶点v:visited[v]=1;顶点v入队Q; 3.while(队列Q非空) v=队列
-
Java实现的最大匹配分词算法详解
本文实例讲述了Java实现的最大匹配分词算法.分享给大家供大家参考,具体如下: 全文检索有两个重要的过程: 1分词 2倒排索引 我们先看分词算法 目前对中文分词有两个方向,其中一个是利用概率的思想对文章分词. 也就是如果两个字,一起出现的频率很高的话,我们可以假设这两个字是一个词.这里可以用一个公式衡量:M(A,B)=P(AB)/P(A)P(B),其中 A表示一个字,B表示一个字,P(AB)表示AB相邻出现的概率,P(A)表示A在这篇文章中的频度,P(B)表示B在这篇文章中的频度.用概率分词的好
-
关于各种排列组合java算法实现方法
一.利用二进制状态法求排列组合,此种方法比较容易懂,但是运行效率不高,小数据排列组合可以使用 复制代码 代码如下: import java.util.Arrays; //利用二进制算法进行全排列//count1:170187//count2:291656 public class test { public static void main(String[] args) { long start=System.currentTimeMillis(); count
-
Java实现的权重算法(按权重展现广告)
基本算法描述如下: 1.每个广告增加权重 2.将所有匹配广告的权重相加sum, 3.以相加结果为随机数的种子,生成1~sum之间的随机数rd 4..接着遍历所有广告,访问顺序可以随意.将当前节点的权重值加上前面访问的各节点权重值得curWt,判断curWt >= rd,如果条件成立则返回当前节点,如果不是则继续累加下一节点. 直到符合上面的条件,由于rd<=sum 因此一定存在curWt>=rd. 特别说明: 此算法和广告的顺序无关 import java.util.ArrayList
-
java字符串相似度算法
本文实例讲述了java字符串相似度算法.分享给大家供大家参考.具体实现方法如下: 复制代码 代码如下: public class Levenshtein { private int compare(String str, String target) { int d[][]; // 矩阵 int n = str.length(); int m = target.length(); int i; // 遍历str的
-
JAVA实现caesar凯撒加密算法
复制代码 代码如下: public class Caesar { public static final String SOURCE = "abcdefghijklmnopqrstuvwxyz"; public static final int LEN = SOURCE.length(); /** * @param args */ public static void main(String[] args) { String result = caesarEncryptio
-
关于JAVA经典算法40题(超实用版)
[程序1]题目:古典问题:有一对兔子,从出生后第3个月起每个月都生一对兔子,小兔子长到第四个月后每个月又生一对兔子,假如兔子都不死,问每个月的兔子总数为多少?1.程序分析: 兔子的规律为数列1,1,2,3,5,8,13,21....public class exp2{ public static void main(String args[]){ int i=0; for(i=1;i<=20;i++)System.out.println(f(i));}public static int f(in
-
java异或加密算法
简单异或密码(simple XOR cipher)是密码学中中一种简单的加密算法. 异或运算:m^n^n = m; 利用异或运算的特点,可以对数据进行简单的加密和解密. 复制代码 代码如下: /** * 简单异或加密解密算法 * @param str 要加密的字符串 * @return */private static String encode2(String str) { int code = 112; // 密钥 char[] charArray = str.toCharArray();
-
Java数据结构及算法实例:朴素字符匹配 Brute Force
/** * 朴素字符串算法通过两层循环来寻找子串, * 好像是一个包含模式的"模板"沿待查文本滑动. * 算法的思想是:从主串S的第pos个字符起与模式串进行比较, * 匹配不成功时,从主串S的第pos+1个字符重新与模式串进行比较. * 如果主串S的长度是n,模式串长度是 m,那么Brute-Force的时间复杂度是o(m*n). * 最坏情况出现在模式串的子串频繁出现在主串S中. * 虽然它的时间复杂度为o(m*n),但在一般情况下匹配时间为o(m+n), * 因此在实际中它被大量