Python词频统计的两种方法详解
目录
- 统计文件里每个单词的个数
- 思路:
- 想法成立开始实践
- 方法一:
- 方法二:
- 总结
统计文件里每个单词的个数
思路:
分别统计文档中的单词,与出现的次数
用两个列表将其保存起来,最后再用zip()函数连接输出**
想法成立开始实践
方法一:
# 导入文件
with open("passage.txt", 'r') as file:
dates = file.readlines()
# 处理
words = []
for i in dates:
words += i.replace("\n", "").split(" ") # 用空字符来代替换行 words +是为了不被覆盖无+将只有最后一条数据
# print(i.replace("\n","").split(" "))
setWords = list(set(words)) # 集合自动去重
num = [] # 统计一个单词出现的次数
for k in setWords:
count = 0
for j in words:
if k == j:
count = count + 1
num.append(count)
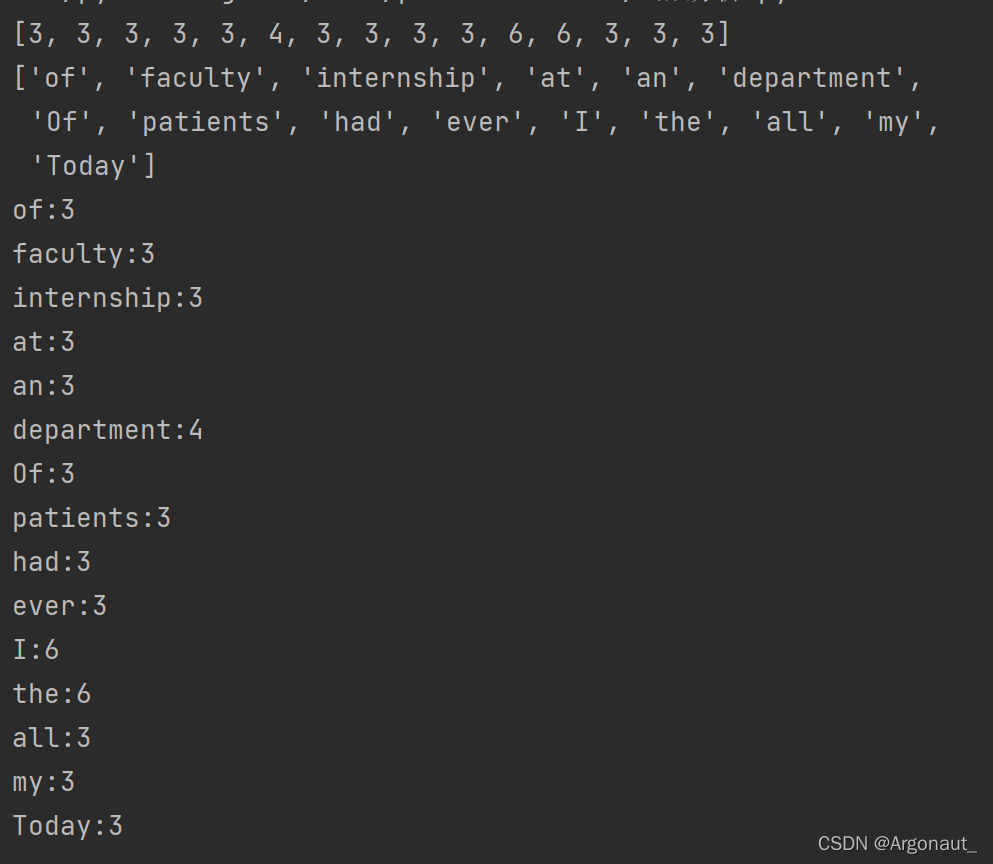
print(num)
print(setWords)
# 输出
for x, y in zip(setWords, num): # 将两个列表用zip结合
print(x + ":" + str(y))、
效果图:
方法二:
此方法用来字典,较前一个相对简洁一点
# 导入
with open("passage.txt", 'r') as file:
dates = file.readlines()
# 处理
words = []
for i in dates:
words += i.replace("\n", "").split(" ")
# print(i.replace("\n","").split(" "))
# setWords=list(set(words)) #可以不用这个
print(words)
print("-" * 40)
# print(setWords)
diccount = dict()
for i in words:
if (i not in diccount):
diccount[i] = 1 # 第一遍字典为空 赋值相当于 i=1,i为words里的单词
# print(diccount)
else:
diccount[i] = diccount[i] + 1 # 等不在里面的全部遍历一遍赋值就都在里面了,我们再来记数
print(diccount)
效果图:

统计的文档

总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
python写程序统计词频的方法
在李笑来所著<时间当作朋友>中有这么一段: 可问题在于,当年我在少年宫学习计算机程序语言的时候,怎么可能想象得到,在20多年后的某一天,我需要先用软件调取语料库中的数据,然后用统计方法为每个单词标注词频,再写一个批处理程序从相应的字典里复制出多达20MB的内容,重新整理-- 在新书<自学是门手艺>中,他再次提及: 又过了好几年,我去新东方教书.2003 年,在写词汇书的过程中,需要统计词频,C++ 倒是用不上,用之前学过它的经验,学了一点 Python,写程序统计词频 --<
-

Python jieba 中文分词与词频统计的操作
我就废话不多说了,大家还是直接看代码吧~ #! python3 # -*- coding: utf-8 -*- import os, codecs import jieba from collections import Counter def get_words(txt): seg_list = jieba.cut(txt) c = Counter() for x in seg_list: if len(x)>1 and x != '\r\n': c[x] += 1 print('常用词频度统
-
Python 合并多个TXT文件并统计词频的实现
需求是:针对三篇英文文章进行分析,计算出现次数最多的 10 个单词 逻辑很清晰简单,不算难, 使用 python 读取多个 txt 文件,将文件的内容写入新的 txt 中,然后对新 txt 文件进行词频统计,得到最终结果. 代码如下:(在Windows 10,Python 3.7.4环境下运行通过) # coding=utf-8 import re import os # 获取源文件夹的路径下的所有文件 sourceFileDir = 'D:\\Python\\txt\\' filenames
-
如何利用python实现词频统计功能
目录 功能要求 方法如下 运行结果 总结 功能要求 这是我们老师的作业 代码中都有注释 要求 词频统计软件: 1)从文本中读入数据:(文件的输入输出) 2)不区分大小写,去除特殊字符. 3) 统计单词 例如:about :10 并统计总共多少单词 4)对单词排序.出现次数 5)输出词频最高的10个单词和次数 6)把统计结果存入文本 方法如下 1.文件的读取,区分大小写,去除特殊字符 import re def getword(): # 读取文件 f=open('read.txt','r',enc
-
Python英文文章词频统计(14份剑桥真题词频统计)
Python剑桥真题词频统计 最好还是要学以致用,自主搜集了19年最近的14份剑桥真题之后,通过Python提供的jieba第三方库,对所有的文章信息进行了词频统计,并选择性地剔除了部分简易词汇,比如数字,普通冠词等,博主较懒,未清楚干净. Python代码如下: import jieba # 以只读方式打开text(即真题库) text = open('text.txt', 'r', encoding = 'utf-8').read() # len(text) #统一为小写 text = te
-
Python 详解爬取并统计CSDN全站热榜标题关键词词频流程
前言 最近在出差,发现住的宾馆居然有小强.所以出差无聊之际,写了点爬虫的代码玩玩,问就是应景.本篇文章主要是爬取CSDN全站综合热榜的100个标题,然后分词提取关键词,统计一下词频. 我想了下,对于其他博主还是有用的,可以看看什么标题可以上热榜,就分享一下吧.顺便把我解决各类问题的方法,说一说. 环境 使用的IDE为:spyder(有看着界面不习惯的,忍一下,不关键) 页面爬取使用chromedriver,至于原因我后面会说. 分词器:jieba 爬取页面地址:https://blog.csdn
-
详解Python用三种方式统计词频的方法
三种方法: ①直接使用dict ②使用defaultdict ③使用Counter ps:`int()`函数默认返回0 ①dict text = "I'm a hand some boy!" frequency = {} for word in text.split(): if word not in frequency: frequency[word] = 1 else: frequency[word] += 1 ②defaultdict import collections f
-
Python统计词频并绘制图片(附完整代码)
效果 1 实现代码 读取txt文件: def readText(text_file_path): with open(text_file_path, encoding='gbk') as f: # content = f.read() return content 得到文章的词频: def getRecommondArticleKeyword(text_content, key_word_need_num = 10, custom_words = [], stop_words =[], quer
-
Python词频统计的两种方法详解
目录 统计文件里每个单词的个数 思路: 想法成立开始实践 方法一: 方法二: 总结 统计文件里每个单词的个数 思路: 分别统计文档中的单词,与出现的次数 用两个列表将其保存起来,最后再用zip()函数连接输出** 想法成立开始实践 方法一: # 导入文件 with open("passage.txt", 'r') as file: dates = file.readlines() # 处理 words = [] for i in dates: words += i.replace(&q
-
对python捕获ctrl+c手工中断程序的两种方法详解
日常编写调试运行程序过程中,难免需要手动停止,以下两种方法可以捕获ctrl+c立即停止程序 1.使用python的异常KeyboardInterrupt try: while 1: pass except KeyboardInterrupt: pass 2.使用signal模块 def exit(signum, frame): print('You choose to stop me.') exit() signal.signal(signal.SIGINT, exit) signal.sign
-
Python获取网络时间戳的两种方法详解
目录 方法一 代码实现 调用方法 返回结果 方法二 代码实现 调用方法 返回结果 在我们进行注册码的有效期验证时,通常使用获取网络时间的方式来进行比对. 以下为获取网络时间的几种方式. 方法一 需要的时间会比较长,个别电脑上可能会出现不兼容现象 代码实现 def get_web_server_time(self, host_URL, year_str='-', time_str=':'): ''' 获取网络时间,需要的时间会比较长,个别电脑上可能会出现不兼容现象 :param host_URL:
-
Python比较两个日期的两种方法详解
目录 datetime strptime 之前我们曾经分享过:Python获取某一日期是“星期几”的6种方法!实际上,在我们使用Python处理日期/时间的时候,经常会遇到各种各样的问题.今天我们就来探讨另一个问题,如何用Python比较两个日期? datetime 如果需要用Python处理日期和时间,大家肯定会先想到datetime.time.calendar等模块.在这其中,datetime模块主要是用来表示日期时间的,就是我们常说的年月日/时分秒. datetime模块中常用的类: 类名
-
Python识别二维码的两种方法详解
目录 前言 pyzbar + PIL cv2 前言 最近在搜寻资料时,发现了一则10年前的新闻:二维码将成线上线下关键入口.从今天的移动互联网来看,支付收款码/健康码等等与我们息息相关,二维码确实成为了我们生活中不可或缺的一部分. 在学习Python处理二维码的过程中,我们看到的大多是“用python生成酷炫二维码”.“用Python制作动图二维码”之类的文章.而关于使用Python批量识别二维码的教程,并不多见.所以今天我会给大家分享两种批量识别二维码的Python技巧! pyzbar + P
-
基于ScheduledExecutorService的两种方法(详解)
开发中,往往遇到另起线程执行其他代码的情况,用java定时任务接口ScheduledExecutorService来实现. ScheduledExecutorService是基于线程池设计的定时任务类,每个调度任务都会分配到线程池中的一个线程去执行,也就是说,任务是并发执行,互不影响. 注意,只有当调度任务来的时候,ScheduledExecutorService才会真正启动一个线程,其余时间ScheduledExecutorService都是处于轮询任务的状态. 1.scheduleAtFix
-
使用Java构造和解析Json数据的两种方法(详解二)
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,采用完全独立于语言的文本格式,是理想的数据交换格式.同时,JSON是 JavaScript 原生格式,这意味着在 JavaScript 中处理 JSON数据不须要任何特殊的 API 或工具包. 在www.json.org上公布了很多JAVA下的json构造和解析工具,其中org.json和json-lib比较简单,两者使用上差不多但还是有些区别.下面接着介绍用org.json构造和解析Json数据的方法
-
使用Java构造和解析Json数据的两种方法(详解一)
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,采用完全独立于语言的文本格式,是理想的数据交换格式.同时,JSON是 JavaScript 原生格式,这意味着在 JavaScript 中处理 JSON数据不须要任何特殊的 API 或工具包. 在www.json.org上公布了很多JAVA下的json构造和解析工具,其中org.json和json-lib比较简单,两者使用上差不多但还是有些区别.下面首先介绍用json-lib构造和解析Json数据的方法
-
对Python获取屏幕截图的4种方法详解
Python获取电脑截图有多种方式,具体如下: PIL中的ImageGrab模块 windows API PyQt pyautogui PIL中的ImageGrab模块 import time import numpy as np from PIL import ImageGrab img = ImageGrab.grab(bbox=(100, 161, 1141, 610)) img = np.array(img.getdata(), np.uint8).reshape(img.size[1]
-
对Python使用mfcc的两种方式详解
1.Librosa import librosa filepath = "/Users/birenjianmo/Desktop/learn/librosa/mp3/in.wav" y,sr = librosa.load(filepath) mfcc = librosa.feature.mfcc( y,sr,n_mfcc=13 ) 返回结构为(13,None)的np.Array,None表示任意数量 2.python_speech_features from python_speech_