hadoop 全面解读自定义分区
分区概念
分区这个词对很多同学来说并不陌生,比如Java很多中间件中,像kafka的分区,mysql的分区表等,分区存在的意义在于将数据按照业务规则进行合理的划分,方便后续对各个分区数据高效处理
Hadoop分区
hadoop中的分区,是把不同数据输出到不同reduceTask ,最终到输出不同文件中
hadoop 默认分区规则
- hash分区
- 按照key的hashCode % reduceTask 数量 = 分区号
- 默认reduceTask 数量为1,当然也可以在driver 端设置
以下是Partition 类中摘取出来的源码,还是很容易懂的

hash分区代码演示
下面是wordcount案例中的driver部分的代码,默认情况下我们不做任何设置,最终输出一个统计单词个数的txt文件,如果我们在这段代码中添加这样一行

再次运行下面的程序后,会出现什么结果呢?
public class DemoJobDriver {
public static void main(String[] args) throws Exception {
//1、获取job
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
//2、设置jar路径
job.setJarByClass(DemoJobDriver.class);
//3、关联mapper 和 Reducer
job.setMapperClass(DemoMapper.class);
job.setReducerClass(DemoReducer.class);
//4、设置 map输出的 key/val 的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5、设置最终输出的key / val 类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6、设置最终的输出路径
String inputPath = "F:\\网盘\\csv\\hello.txt";
String outPath = "F:\\网盘\\csv\\wordcount\\hello_result.txt";
//设置输出文件为2个
job.setNumReduceTasks(2);
FileInputFormat.setInputPaths(job,new Path(inputPath));
FileOutputFormat.setOutputPath(job,new Path(outPath));
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
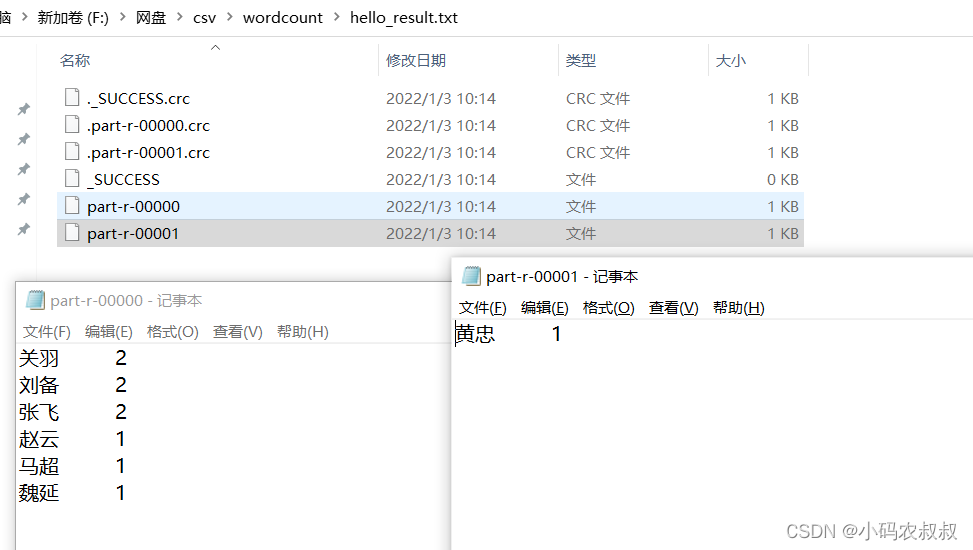
可以看到,最终输出了2个统计结果文件,每个文件中的内容有所不同,这就是默认情况下,当reducer个数设置为多个时,会按照hash分区算法计算结果并输出到不同分区对应的文件中去
自定义分区步骤
- 自定义类继承Partitioner
- 重写getPartition方法,并在此方法中根据业务规则控制不同的数据进入到不同分区
- 在Job的驱动类中,设置自定义的Partitioner类
- 自定义Partition后,要根据自定义的Partition逻辑设置相应数量的ReduceTask
业务需求
将下面文件中 的人物名称按照姓氏,“马”姓的放入第一个分区,“李”姓的放入第二个分区,其他的放到其他第三个分区中

自定义分区
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.io.Text;
public class MyPartioner extends Partitioner<Text, IntWritable> {
@Override
public int getPartition(Text text, IntWritable intWritable, int partion) {
String key = text.toString();
if(StringUtils.isNotEmpty(key.trim())){
if(key.startsWith("马")){
partion = 0;
}else if(key.startsWith("李")){
partion = 1;
}else {
partion = 2;
}
}
return partion;
}
}
将自定义分区关联到Driver类中,注意这里的ReduceTasks个数和自定义的分区数量保持一致
job.setNumReduceTasks(3); job.setPartitionerClass(MyPartioner.class);
下面运行Driver类,观察最终的输出结果,也是按照预期,将不同的姓氏数据输出到了不同的文件中
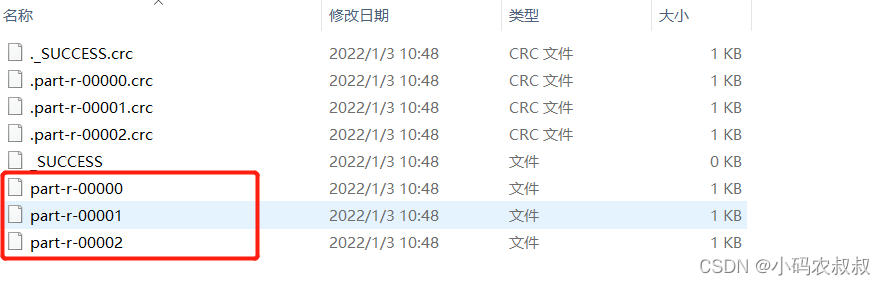
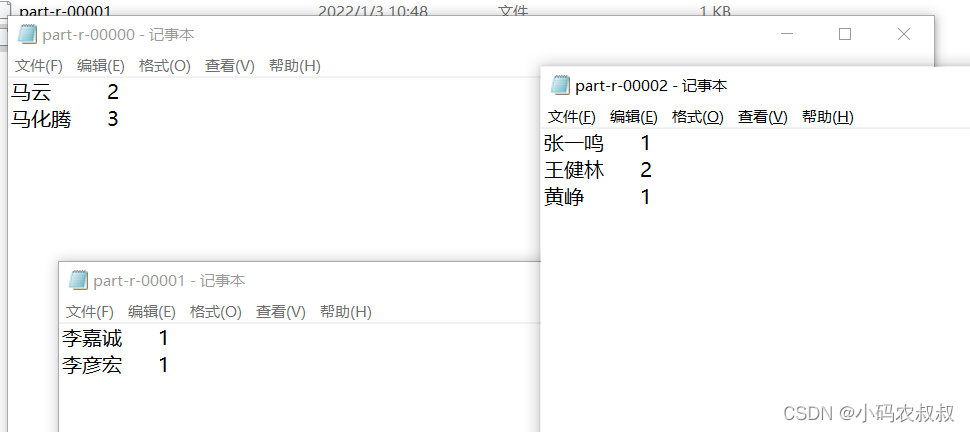
关于自定义分区的总结
- 如果ReduceTask的数量 > 自定义partion中的分区数量,则会多产生几个空的输出文件
- 如果 1 < ReduceTask < 自定义partion中的分区数量,有一部分的数据处理过程中无法找到相应的分区文件存储,会抛异常
- 如果ReduceTask = 1 ,则不管自定义的partion中分区数量为多少个,最终结果都只会交给这一个ReduceTask 处理,最终只会产生一个结果文件
- 分区号必须从0开始,逐一累加
到此这篇关于hadoop 全面解读自定义分区的文章就介绍到这了,更多相关hadoop 自定义分区内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

hadoop 切片机制分析与应用
前言 上面是一张MapReduce读取一个文本数据的逻辑顺序处理图.我们知道,不管是本地运行还是集群模式下,最终以job的任务调度形式运行,主要分为两个阶段 Map阶段,开启MapTask处理数据的读取 Reduce阶段,开启ReduceTask对数据做聚合 比如在wordcount案例中,一段文本数据,在map阶段首先被解析,拆分成一个个的单词,其实对hadoop来说,这项工作的完成,是由背后开启的一个MapTask进行处理的,等job处理完成,看到在目标文件夹下,生成了对应的单词统计结果 如
-
Hadoop环境配置之hive环境配置详解
1.将下载的hive压缩包拉到/opt/software/文件夹下 安装包版本:apache-hive-3.1.2-bin.tar.gz 2.将安装包解压到/opt/module/文件夹中,命令: cd /opt/software/ tar -zxvf 压缩包名 -C /opt/module/ 3.修改系统环境变量,命令: vi /etc/profile 在编辑面板中添加如下代码: export HIVE_HOME=/opt/module/apache-hive-3.1.2-bin expor
-
hadoop 详解如何实现数据排序
目录 前言 MapReduce排序 MapReduce排序分类 1.部分排序 2.全排序 3.辅助排序 4.二次排序 自定义排序案例 1.自定义一个Bean对象,实现WritableComparable接口 2.自定义Mapper 3.自定义Reducer 4.自定义Driver类 分区内排序案例 1.添加自定义分区 2.改造Driver类 前言 在hadoop的MapReduce中,提供了对于客户端的自定义排序的功能相关API MapReduce排序 默认情况下,MapTask 和Reduce
-
深入了解Hadoop如何实现序列化
目录 前言 为什么要序列化 为什么不使用Java序列化 Hadoop序列化特点 Hadoop序列化业务场景 案例业务描述 编码实现 前言 序列化想必大家都很熟悉了,对象在进行网络传输过程中,需要序列化之后才能传输到客户端,或者客户端的数据序列化之后送达到服务端 序列化的标准解释如下: 序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输 对应的反序列化为序列化的逆向过程 反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内
-
hadoop 全面解读自定义分区
分区概念 分区这个词对很多同学来说并不陌生,比如Java很多中间件中,像kafka的分区,mysql的分区表等,分区存在的意义在于将数据按照业务规则进行合理的划分,方便后续对各个分区数据高效处理 Hadoop分区 hadoop中的分区,是把不同数据输出到不同reduceTask ,最终到输出不同文件中 hadoop 默认分区规则 hash分区 按照key的hashCode % reduceTask 数量 = 分区号 默认reduceTask 数量为1,当然也可以在driver 端设置 以下是Pa
-
Java kafka如何实现自定义分区类和拦截器
生产者发送到对应的分区有以下几种方式: (1)指定了patition,则直接使用:(可以查阅对应的java api, 有多种参数) (2)未指定patition但指定key,通过对key的value进行hash出一个patition: (3)patition和key都未指定,使用轮询选出一个patition. 但是kafka提供了,自定义分区算法的功能,由业务手动实现分布: 1.实现一个自定义分区类,CustomPartitioner实现Partitioner import org.apache
-
hadoop二次排序的原理和实现方法
默认情况下,Map输出的结果会对Key进行默认的排序,但是有时候需要对Key排序的同时还需要对Value进行排序,这时候就要用到二次排序了.下面我们来说说二次排序 1.二次排序原理 我们把二次排序分为以下几个阶段 Map起始阶段 在Map阶段,使用job.setInputFormatClass()定义的InputFormat,将输入的数据集分割成小数据块split,同时InputFormat提供一个RecordReader的实现.在这里我们使用的是TextInputFormat,它提供的Reco
-
详解c# PLINQ中的分区
最近因为比较忙,好久没有写博客了,这篇主要给大家分享一下PLINQ中的分区.上一篇介绍了并行编程,这边详细介绍一下并行编程中的分区和自定义分区. 先做个假设,假设我们有一个200Mb的文本文件需要读取,怎么样才能做到最优的速度呢?对,很显然就是拆分,把文本文件拆分成很多个小文件,充分利用我们计算机中的多核cpu的优势,让每个cpu都充分的利用,达到效率的最大化.然而在PLINQ中也是,我们有一个数据源,如果想进行最大的并行化操作,那么就需要把其拆分为可以多个线程同时访问的多个部分,这就是PLIN
-
怎样给Kafka新增分区
目录 给Kafka新增分区 1.修改 topic 的分区 2.迁移数据 3.迁移 4.验证 Kafka分区原理机制 分区结构 分区优点 分区策略 根据分区策略实现消息的顺序消费 默认分区策略源码 总结 给Kafka新增分区 数据量猛增的时候,需要给 kafka 的 topic 新增分区,增大处理的数据量,可以通过以下步骤 1.修改 topic 的分区 kafka-topics --zookeeper hadoop004:2181 --alter --topic flink-test-04 --p
-
深入解析kafka 架构原理
kafka 架构原理 大数据时代来临,如果你还不知道Kafka那就真的out了!据统计,有三分之一的世界财富500强企业正在使用Kafka,包括所有TOP10旅游公司,7家TOP10银行,8家TOP10保险公司,9家TOP10电信公司等等.LinkedIn.Microsoft和Netflix每天都用Kafka处理万亿级的信息.本文就让我们一起来大白话kafka的架构原理. kafka官网:http://kafka.apache.org/ 01 kafka简介 Kafka最初由Linkedin公
-
VMWare安装Centos 6.9教程
VMWare下Centos 6.9安装教程,记录如下 1.新建虚拟机 (1)点击文件-->新建虚拟机 (2)选择 自定义(高级)-->下一步 (3)选择Workstation 12.0-->下一步 (4)选择 稍后安装操作系统-->下一步 (5)选择 Linux à Red Hat Enterprise Linux 6 64位-->下一步 (6)修改虚拟机名称-->下一步 这个虚拟机名称就是以后在左边栏看到的名称 (7)点击 下一步 (8)直接使用推荐内存,点击 下一步
-
MySQL分区表的局限和限制详解
禁止构建 分区表达式不支持以下几种构建: 存储过程,存储函数,UDFS或者插件 声明变量或者用户变量 可以参考分区不支持的SQL函数 算术和逻辑运算符 分区表达式支持+,-,*算术运算,但是不支持DIV和/运算(还存在,可以查看Bug #30188, Bug #33182).但是,结果必须是整形或者NULL(线性分区键除外,想了解更多信息,可以查看分区类型). 分区表达式不支持位运算:|,&,^,<<,>>,~ . HANDLER语句 在MySQL 5.7.1之前的分区表不
-
Vmware虚拟机中centOS7安装图文教程
本教程为大家分享了Vmware虚拟机中centOS7安装步骤,供大家参考,具体内容如下 1.安装VMware 下载一个软件安装: 2.新建一个虚拟机 3.引用安装包 4.启动新建的虚拟机 5.安装CentOS7的步骤 配置系统语言: 配置系统时间: 配置系统键盘: 配置键盘切换的快捷键: 配置键盘的多种: 语言支持: 默认自动使用安装源: 配置软件环境,需要及时添加的软件,这里我开启图形界面GUI:这里勾上,就默认启动图形界面. 配置安装目标位置: 选择配置分区点击完成就会进入手动分区页面: 配