分布式系统下调用链追踪技术面试题
引言
一个复杂的分布式系统,用户发起一个请求,这个请求可能调用几十到几百个服务,经过很多业务层,而每个业务又是多个机器集群,一个请求具体被随机到哪台机器上又无法确定,如果最后用户的请求失败,只返回一个错误提示,作为开发人员,该如何定位解决问题?你需要定位以下问题:
- 问题出在哪个服务,是你负责的服务还是调用别人服务的某一个环节。
- 同一个服务集群有多台机器,到底要去哪个机房哪台机器定位某条报错信息。
- 同一个接口可能有多次请求,到底是哪一次报错了。
- 多个服务之间调用顺序是怎样的。
- 如果需要响应速度优化,到底是哪个环节哪个服务耗时了,如何定位。
1、面试官:
分布式微服务环境下那么多机器,调用链又很长,你们是如何定位问题的?
问题分析:这个问题,如果你使用过微服务框架,对于服务治理你一定知道这种技术,如果作为微服务架构的小白,你只是知道一些基础知识,突然被问到这个问题,确实比较懵逼。这么多机器集群,我怎么知道每次服务打到哪个机器上了,我怎么知道到底是哪个环节抛异常了?
我:分布式系统中针对上述问题,我们急需一套链路追踪(Trace)系统来解决这些痛点,这个系统主要的任务就是收集各服务的日志,上报日志,分析日志,保存展示。其关键核心在于调用链,为每个请求生成全局唯一的ID(Traceld),通过Traceld 将不同系统的“孤立地”调用信息关联在一起,还原出更多有价值的数据。
(如果你还不明白到底怎么搞直接看看成品图)
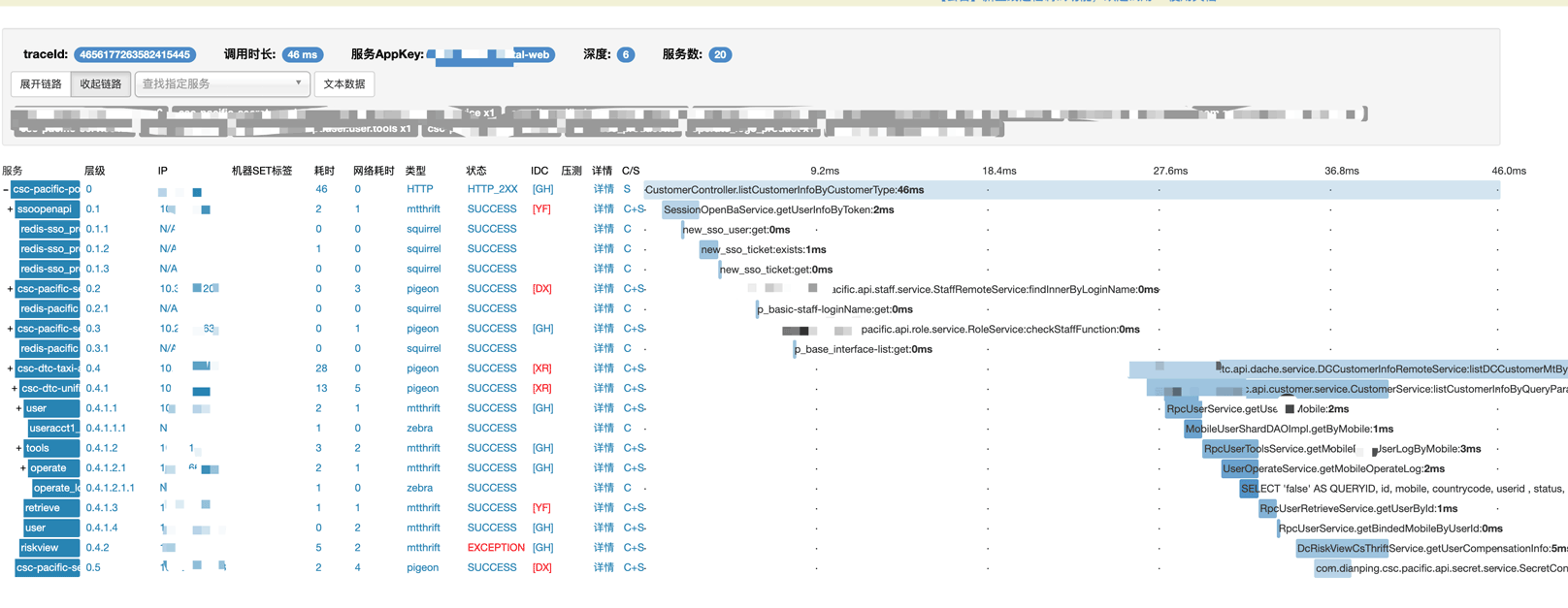
通过一个Trace查询某一次请求,这个Trace是全剧唯一,通过这个链路追踪系统,你可以清楚的知道服务调用深度,涉及服务个数,每个服务调用的时间及状态,到底是哪个服务出现异常,具体到方法名,查找耗时长的链路时,可以通过在查询结果页面点击“耗时”二字,让数据以耗时升序或降序排列,都一目了然,上面的问题都得到解决了。
2、面试官:
你知道哪些成熟的调用链开源工具?
Google Dapper
Dapper一开始是一个自包含的跟踪工具,但后来发展成为一个监控平台,具有高性能,代码侵入性低,支持集群扩展特性。
dapper 处理日志分为3个阶段:
- 各个服务将span数据写到本机日志上;
- dapper守护进程进行拉取日志文件,将文件读到dapper收集器里;
- dapper收集器将结果写到bigtable中,一次跟踪被记录为一行。
阿里巴巴的分布式调用跟踪系统 - 鹰眼(EagleEye)
EagleEye 是一个以调用链追踪技术为核心的监控系统,通过收集,存储,分析分布式系统中的调用事件参数,协同开发人员进行故障定位,容量预估,性能瓶颈定位,系统请求链路梳理等,EagleEye 的开发也是基于Google Dapper 的设计思想。
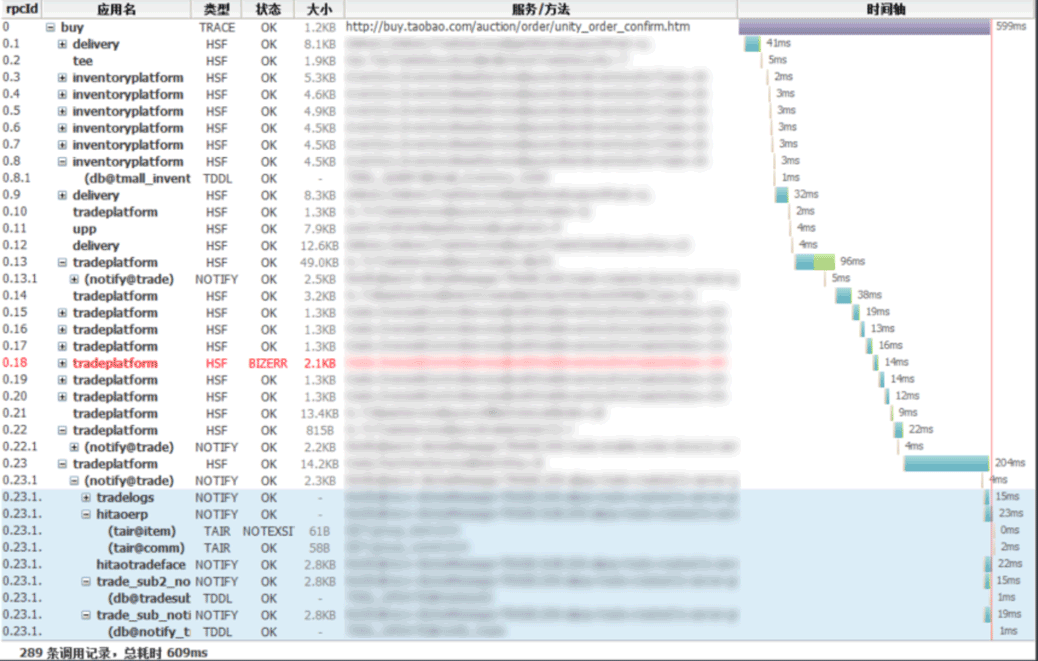
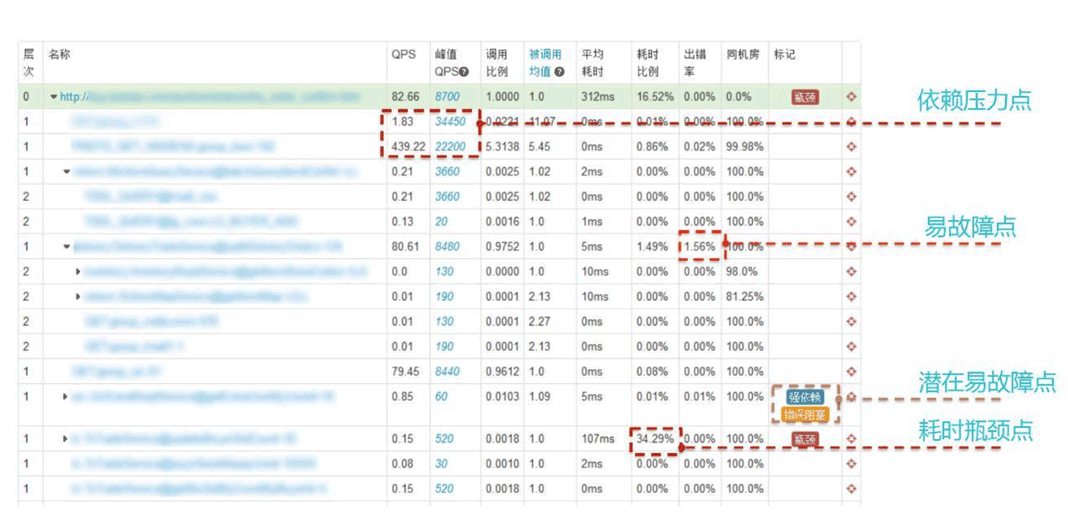
图片来源:github EagleEye 社区
美团分布式会话追踪系统 - MTrace
MTrace是美团点评内部的分布式会话跟踪系统,也借鉴了2010年Google的 dapper,通过一个全局的ID将分布在各个服务节点上的同一次请求串联起来,还原原有的调用关系、追踪系统问题、分析调用数据、统计系统指标,MTrace支持美团内部RPC中间件,HTTP中间件,MySQL,Tair,MQ等中间件的数据埋点。
总结
无论哪个公司使用哪个框架,我们发现 trace 系统最终要解决的问题都是相同的,大致归纳如下:
- 复杂网络环境中定位问题,通过异常log绑定记录,轻松定位。
- 发现热点,发现瓶颈问题。
- 预估系统容量,按照上下游调用比例,粗略计算哪些机器需要提前扩容。
- 优化链路,通过链路分析,从更高的全局角度分析可以优化的点。
以上就是分布式系统下调用链追踪技术面试题的详细内容,更多关于分布式系统下调用链追踪的资料请关注我们其它相关文章!
相关推荐
-

微服务分布式架构实现日志链路跟踪的方法
Logback 背景 Logback是由log4j创始人设计的另一个开源日志组件,官方网站:http://logback.qos.ch.它当前分为下面下个模块: logback-core:其它两个模块的基础模块 logback-classic:它是log4j的一个改良版本,同时它完整实现了slf4j API使你可以很方便地更换成其它日志系统如log4j或JDK14 Logging logback-access:访问模块与Servlet容器集成提供通过Http来访问日志的功能 普通debug日志
-
Java 实现分布式服务的调用链跟踪
目录 为什么要实现调用链跟踪? 如何实现? 第一步,看图.看场景,用户浏览器的一次请求行为所走的路径是什么样的 第二步,实现.不想看代码可直接拉最后看结果和原理 测试一下结果: 为什么要实现调用链跟踪? 随着业务的发展,所有的系统最终都会走向服务化体系,微服务的目的一是提高系统的稳定性,二是提高持续交付的效率,为什么能提高这两项不是今天讨论的内容. 当然这也不是绝对的,如果业务还在MVP验证,团队规模小个人觉得完全没必要微服务化.单体应用是比较好的选择.作者是有经历过从单体应用到1000+应用的
-
SpringCloud可视化链路追踪系统Zipkin部署过程
1.前提 已经配置Sleuth,可参考 https://www.jb51.net/article/182889.htm 2.什么是Zipkin? 官网:https://zipkin.io/ 大规模分布式系统的APM工具( Application Performance Management),基于 Google Dapper的基础实现,和 sleuth结合可以提供可视化web界面分析调用链路耗时情况 同类产品 鹰眼( Eag leYe) CAT twitter开源 zipkin,结合 sleut
-
SpringCloud分布式链路跟踪的方法
注:作者使用IDEA + Gradle 注:需要有一定的java SpringBoot and SSM+Springcloud基础 程序测试错误追责 我举个例子,我现在要做一个电商项目,项目里面有一个购买模块,那我这边可能要执行一个代码,比如减库存之类的东西,那我两个服务不就是要相互调用嘛,我自身是一个服务,我现在要调用减库存这个服务: 你调用它,你知道它一定能执行成功吗?肯定是不一定: 比如说,我现在要执行一个减库存的代码,我调用这个方法会进行库存的一个更改,这个库存减少成功还好,万一要是失败
-
分布式系统下调用链追踪技术面试题
引言 一个复杂的分布式系统,用户发起一个请求,这个请求可能调用几十到几百个服务,经过很多业务层,而每个业务又是多个机器集群,一个请求具体被随机到哪台机器上又无法确定,如果最后用户的请求失败,只返回一个错误提示,作为开发人员,该如何定位解决问题?你需要定位以下问题: 问题出在哪个服务,是你负责的服务还是调用别人服务的某一个环节. 同一个服务集群有多台机器,到底要去哪个机房哪台机器定位某条报错信息. 同一个接口可能有多次请求,到底是哪一次报错了. 多个服务之间调用顺序是怎样的. 如果需要响应速度优化
-
阿里、华为、腾讯Java技术面试题精选
阿里.华为.腾讯Java技术面试题精选,具体内容如下 JVM的类加载机制是什么?有哪些实现方式? 类加载机制: 类的加载指的是将类的.class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法去内,然后在堆区创建一个java.lang.Class对象,用来封装在方法区内的数据结构.类的加载最终是在堆区内的Class对象,Class对象封装了类在方法区内的数据结构,并且向Java程序员提供了访问方法区内的数据结构的接口. 类加载有三种方式: 1)命令行启动应用时候由JVM初始化加载 2)
-
OpenTelemetry初识及调用链Trace详解
目录 前言 初识OpenTelemetry 调用链Trace Span Span Context Attributes Span事件 Span Links Span状态 Span Kind Trace构建的原理 Metrics Logs Baggage 总结 前言 OpenTelemetry作为一个分布式追踪的项目,他支持非常多的语言,如Java,Golang,Python等,鉴于笔者的主力语言为Java,并且后续需要介绍OpenTelemetry的Java Agent实现,所以后续文章中的相关
-
skywalking分布式服务调用链路追踪APM应用监控
目录 前言 skywalking是什么,有什么用? skywalaking总体架构分为三部分 如何快速开始? 第一步:进入官方release地址 第二步:配置需要监控的应用的agent探针 系统使用图例 其他 前言 当企业应用进入分布式微服务时代,应用服务依赖会越来越多,skywalking可以很好的解决服务调用链路追踪的问题,而且基于java探针技术,基本对应用零侵入零耦合. skywalking是什么,有什么用? Skywalking 是一个APM系统,即应用性能监控系统,为微服务架构和云原
-
微信小程序本作用域下调用全局JS详解及实例
微信小程序本作用域下调用全局JS详解 本地wxml文件 <view> app版本:{{version}} </view> 本地js文件 var app; Page({ data:{ }, onLoad:function() { app = getApp(); this.setData({version:app.globalData.appName}); } }) 全局js文件 //app.js App({ globalData:{ appName:"hcoder"
-
python下调用pytesseract识别某网站验证码的实现方法
一.pytesseract介绍 1.pytesseract说明 pytesseract最新版本0.1.6,网址:https://pypi.python.org/pypi/pytesseract Python-tesseract is a wrapper for google's Tesseract-OCR ( http://code.google.com/p/tesseract-ocr/ ). It is also useful as a stand-alone invocation scrip
-
Python在Windows和在Linux下调用动态链接库的教程
Linux系统下调用动态库(.so) 1.linuxany.c代码如下: #include "stdio.h" void display(char* msg){ printf("%s\n",msg); } int add(int a,int b){ return a+b; } 2.编译c代码,最后生成Python可执行的.so文件 (1)gcc -c linuxany.c,将生成一个linuxany.o文件 (2)gcc -shared linuxany.c -o
-
python使用opencv在Windows下调用摄像头实现解析
这篇文章主要介绍了python使用opencv在Windows下调用摄像头实现解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 环境准备 1.我这里使用的是python3.7.4 2.使用pip安装numpy与opencv-python模块 安装成功后会提升succeed,这里我已安装所以提示已存在.需要注意的是opencv-python目前只有python3.7的支持版本不支持最新的python3.8. 可在阿里云的镜像仓库内查看openc
-
在Python IDLE 下调用anaconda中的库教程
大家都知道,Anaconda是一个开源的Python发行版本,其包含了conda.Python等180多个科学包及其依赖项.下载了anaconda我们可以很方便的随时调用这里面的库. 原先我自己在Python官网下载了python 3.7开发环境,anaconda的后面下载的,平时比较喜欢使用 IDLE 作简单的程序或学习的时候,发现调用不了anaconda中的库,就算是在cmd程序中使用pip 下载相应的库时,最终的库路径也是存于anaconda的库路径中. 当然,通过相关命令实现pip下载路