Python爬虫新手入门之初学lxml库
1.爬虫是什么
所谓爬虫,就是按照一定的规则,自动的从网络中抓取信息的程序或者脚本。万维网就像一个巨大的蜘蛛网,我们的爬虫就是上面的一个蜘蛛,不断的去抓取我们需要的信息。
2.爬虫三要素
- 抓取
- 分析
- 存储
3.爬虫的过程分析
当人类去访问一个网页时,是如何进行的?
①打开浏览器,输入要访问的网址,发起请求。
②等待服务器返回数据,通过浏览器加载网页。
③从网页中找到自己需要的数据(文本、图片、文件等等)。
④保存自己需要的数据。
对于爬虫,也是类似的。它模仿人类请求网页的过程,但是又稍有不同。
首先,对应于上面的①和②步骤,我们要利用python实现请求一个网页的功能。
其次,对应于上面的③步骤,我们要利用python实现解析请求到的网页的功能。
最后,对于上面的④步骤,我们要利用python实现保存数据的功能。
因为是讲一个简单的爬虫嘛,所以一些其他的复杂操作这里就不说了。下面,针对上面几个功能,逐一进行分析。
4.如何用python请求一个网页
作为一门拥有丰富类库的编程语言,利用python请求网页完全不在话下。这里推荐一个非常好用的类库urllib.request。
4.1.抓取网页
urllib库使用
import urllib.request
response = urllib.request.urlopen('https://laoniu.blog.csdn.net/')
print(response.read().decode('utf-8'))
这样就可以抓取csdn我的主页的html文档
我们使用爬虫就是需要在网页中提取我们需要的数据,接下来我们来学习抓取一下百度搜索页的热榜数据

4.2.如何解析网页呢
使用lxml库
lxml 是一种使用 Python 编写的库,可以迅速、灵活地处理 XML 和 HTML。
它支持 XML Path Language (XPath) 和 Extensible Stylesheet Language Transformation (XSLT),并且实现了常见的 ElementTree API。
安装
windows下安装
#pip方式安装 pip3 install lxml #wheel方式安装 #下载对应系统版本的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml pip3 install lxml-4.2.1-cp36-cp36m-win_amd64.whl
linux下安装
yum install -y epel-release libxslt-devel libxml2-devel openssl-devel pip3 install lxml
环境/版本一览:
- 开发工具:PyCharm 2020.2.3
- python:3.8.5
4.3.编写代码
import urllib.request
from lxml import etree
# 获取百度热榜
url = "https://www.baidu.com/s?ie=UTF-8&wd=1"
# 我们在请求头加入User-Agent参数,这样可以让服务端认为此次请求是用户通过浏览器发起的正常请求,防止被识别为爬虫程序请求导致直接拒绝访问
req = urllib.request.Request(url=url, headers={
'User-Agent': 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
})
# 发起请求
html_resp = urllib.request.urlopen(req).read().decode("utf-8")
到这里我们可以顺利获取百度的搜索页面html文档
我门需要看一下热搜排行榜的标签元素在哪里
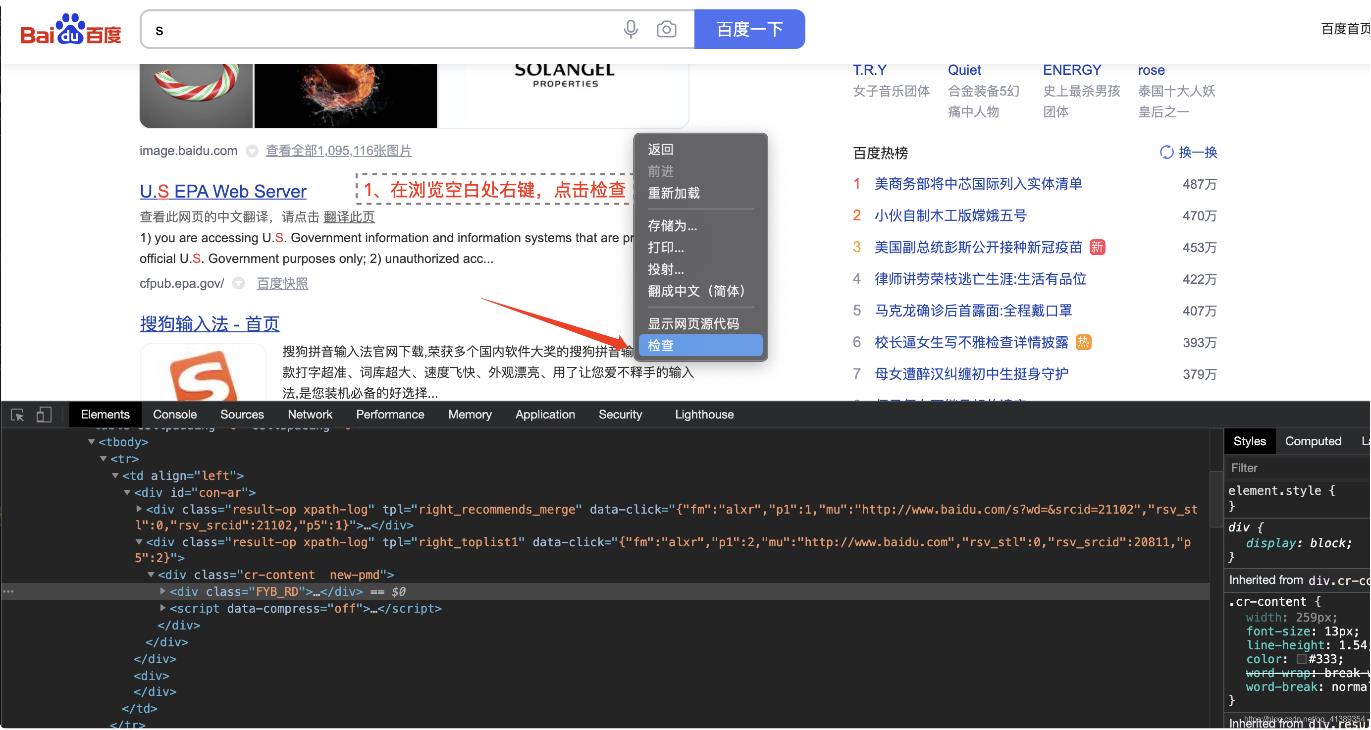
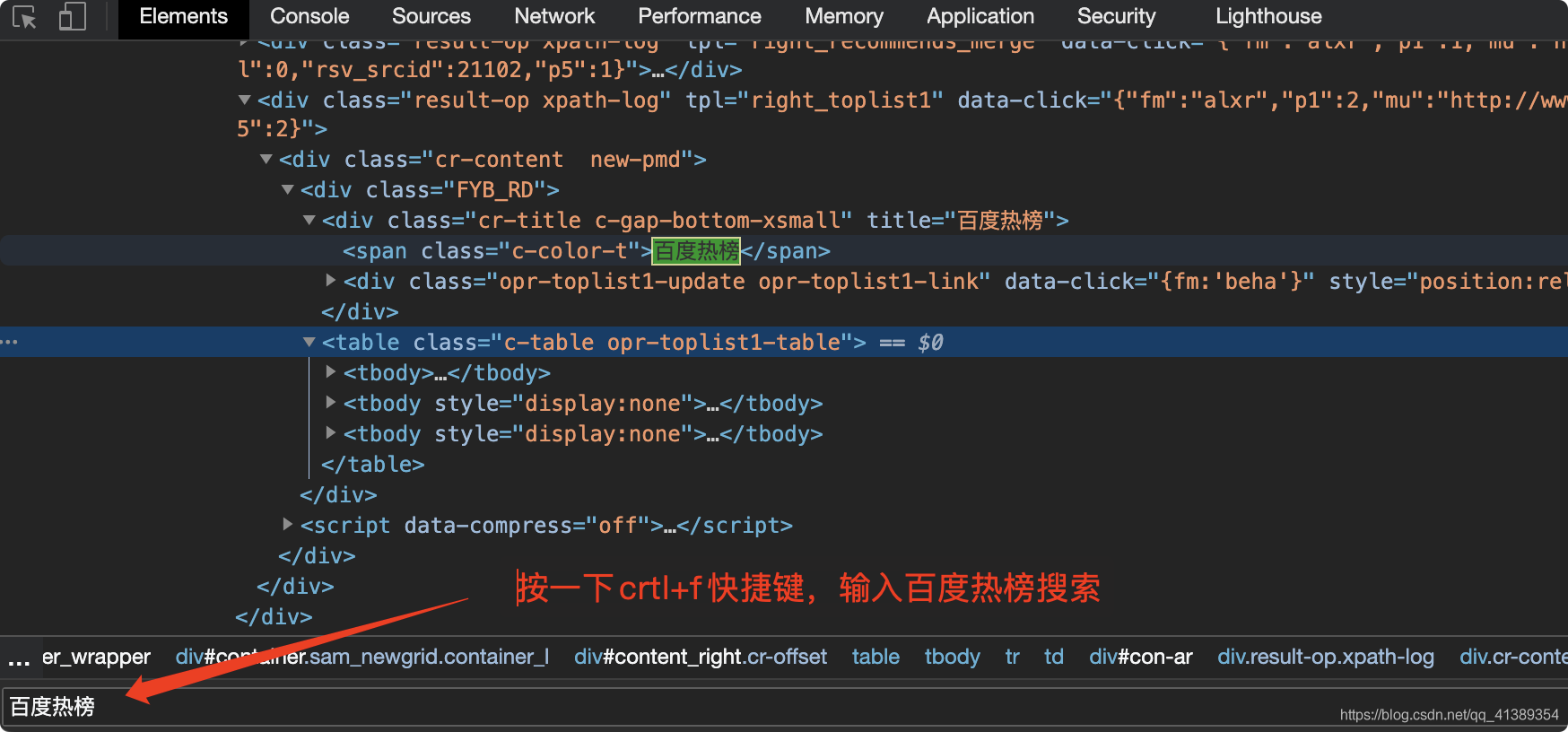
找到第一条 右键复制 XPath (后边说XPath是什么)
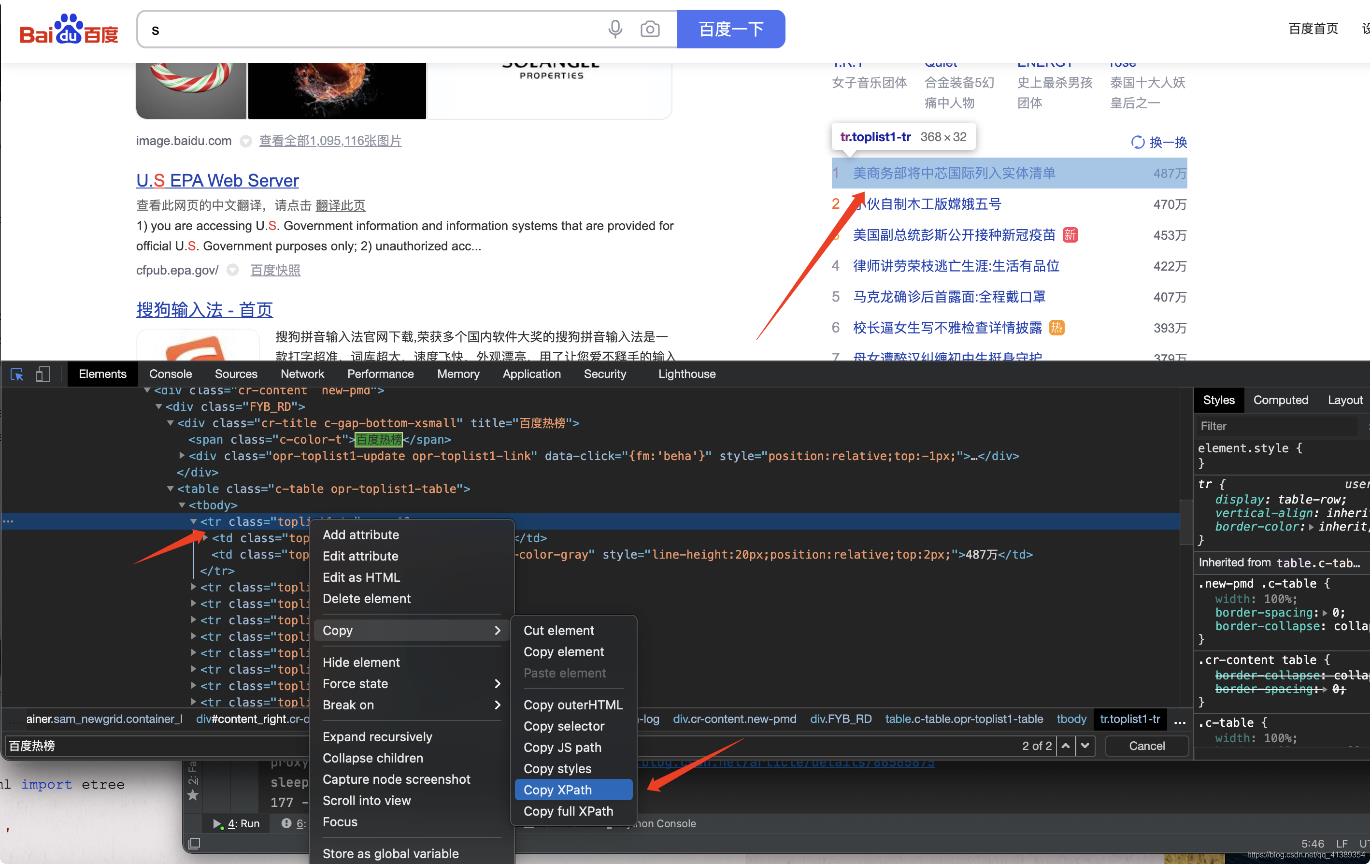
我们需要了解并使用XPath,XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
复制的内容结果是: //*[@id="con-ar"]/div[2]/div/div/table/tbody[1]/tr[1]
这xPath字符串 表示现在在html定位的位置就是热点新闻第一行内容
5.XPath常用规则
| 表达式 | 描述 |
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符,选择所有元素节点与元素名 |
| @* | 选取所有属性 |
| [@attrib] | 选取具有给定属性的所有元素 |
| [@attrib='value'] | 选取给定属性具有给定值的所有元素 |
| [tag] | 选取所有具有指定元素的直接子节点 |
| [tag='text'] | 选取所有具有指定元素并且文本内容是text节点 |
6.继续分析
那么我们要获取所有的热点新闻该怎么写呢
继续看网页
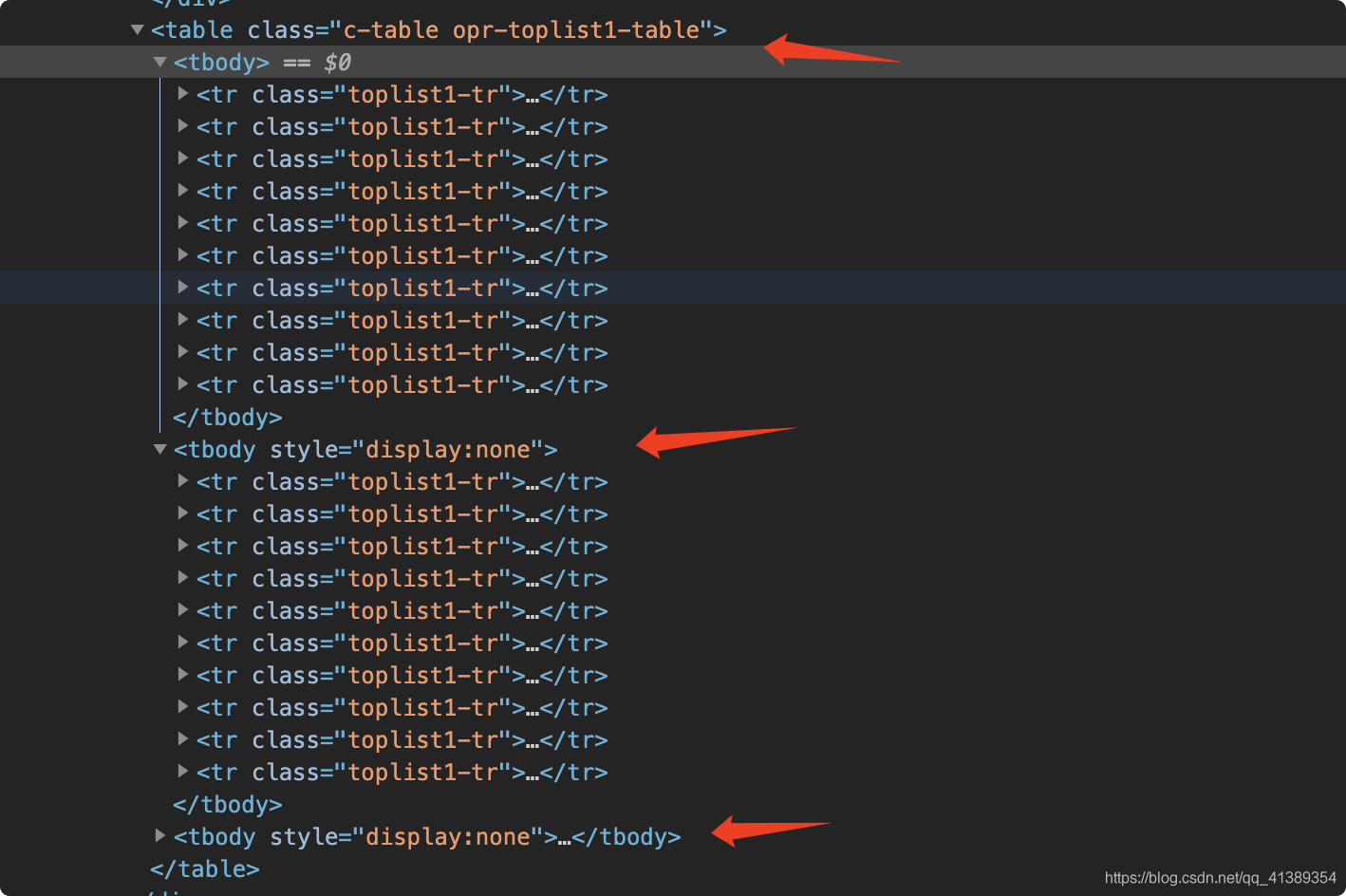
可以看到所有的热榜分别在三个<tbody>之下
修改一下刚才复制的XPath
//*[@id="con-ar"]/div[2]/div/div/table/tbody[1]/tr[1] 改为 //*[@id="con-ar"]/div[2]/div/div/table/tbody/tr
这样XPath就会定位到这三个tbody下的所有tr元素内容
我们继续看一下tr是不是我们想要的内容,展开一个tr看看
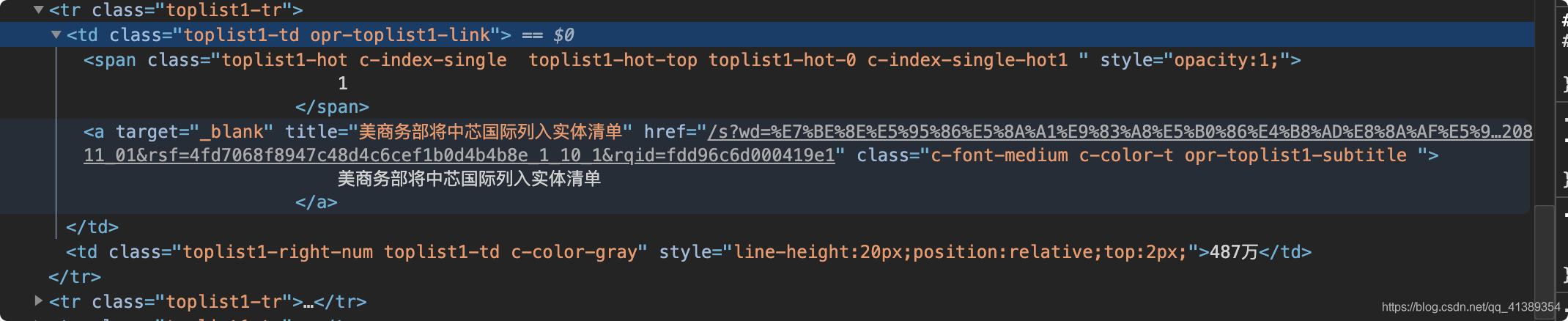
淦~还有一堆,,
这该怎么办。我们需要拿到数据是 【标题】 【访问链接】 【热度】,现在手里已经拿到的是所有的tr元素
紧接着从tr下手 直接 拿到下面所有<a>标签的标题与超链接
标题的XPath: */a/@title 超链接的XPath: */a/@href
*表示匹配tr下的所有元素 /a是在*找到第一个a标签 @是属性选择器 title和href就是要选择的素属性了
还剩下个热度,let‘s me 继续操作,直接选择tr下的第二个td XPath: td[2]
分析完毕,把完整的代码贴出来
import urllib.request
from lxml import etree
# 获取百度热榜
url = "https://www.baidu.com/s?ie=UTF-8&wd=1"
# 我们在请求头加入User-Agent参数,这样可以让服务端认为此次请求是用户通过浏览器发起的正常请求,防止被识别为爬虫程序请求导致直接拒绝访问
req = urllib.request.Request(url=url, headers={
'User-Agent': 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
})
html_resp = urllib.request.urlopen(req).read().decode("utf-8")
html = etree.HTML(html_resp)#初始化生成一个XPath解析对象
_list = html.xpath("//*[@id='con-ar']/div[2]/div/div/table/tbody/tr")
print(f"article count : {len(_list)}")
for tr in _list:
title = tr.xpath("*/a/@title")[0]
href = tr.xpath("*/a/@href")[0]
hot = tr.xpath("string(td[2])").strip()
print(f"{hot}\t{title}\thttps://www.baidu.com{href}")
点击运行,程序啪就跑起来了,很快啊,数据全都过来了,我全都接住了,我笑了一下。
到此就完成了lxml xpath的基本使用,更详细的xpath教程请看 :https://www.w3school.com.cn/xpath/index.asp
爬虫三要素,抓取数据完成了,剩余的分析与存储就先不说了
总结
到此这篇关于Python爬虫新手入门之初学lxml库的文章就介绍到这了,更多相关Python爬虫入门之lxml库内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python3爬虫爬取百姓网列表并保存为json功能示例【基于request、lxml和json模块】
本文实例讲述了Python3爬虫爬取百姓网列表并保存为json功能.分享给大家供大家参考,具体如下: python3爬虫之爬取百姓网列表并保存为json文件.这几天一直在学习使用python3爬取数据,今天记录一下,代码很简单很容易上手. 首先需要安装python3.如果还没有安装,可参考本站python3安装与配置相关文章. 首先需要安装requests和lxml和json三个模块 需要手动创建d.json文件 代码 import requests from lxml import etree
-
Python爬虫基于lxml解决数据编码乱码问题
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高 XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言,它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索 XPath的选择功能十分强大,它提供了非常简明的路径选择表达式,另外,它还提供了超过100个内建函数,用于字符串.数值.时间的匹配以及节点.序列的处理等,几乎所有我们想要定位的节点,都可以用XPath来选择 XPath
-
Python爬虫基础之XPath语法与lxml库的用法详解
前言 本来打算写的标题是XPath语法,但是想了一下Python中的解析库lxml,使用的是Xpath语法,同样也是效率比较高的解析方法,所以就写成了XPath语法和lxml库的用法 XPath 即为 XML 路径语言,它是一种用来确定 XML(标准通用标记语言的子集)文档中某部分位置的语言. XPath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力. XPath 同样也支持HTML. XPath 是一门小型的查询语言. python 中 lxml库 使用的是 Xpath 语法,是
-
Python爬虫新手入门之初学lxml库
1.爬虫是什么 所谓爬虫,就是按照一定的规则,自动的从网络中抓取信息的程序或者脚本.万维网就像一个巨大的蜘蛛网,我们的爬虫就是上面的一个蜘蛛,不断的去抓取我们需要的信息. 2.爬虫三要素 抓取 分析 存储 3.爬虫的过程分析 当人类去访问一个网页时,是如何进行的? ①打开浏览器,输入要访问的网址,发起请求. ②等待服务器返回数据,通过浏览器加载网页. ③从网页中找到自己需要的数据(文本.图片.文件等等). ④保存自己需要的数据. 对于爬虫,也是类似的.它模仿人类请求网页的过程,但是又稍有不同.
-
python爬虫beautifulsoup库使用操作教程全解(python爬虫基础入门)
[python爬虫基础入门]系列是对python爬虫的一个入门练习实践,旨在用最浅显易懂的语言,总结最明了,最适合自己的方法,本人一直坚信,总结才会使人提高 1. BeautifulSoup库简介 BeautifulSoup库在python中被美其名为"靓汤",它和和 lxml 一样也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据.BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,若在没用安装此库的情况下
-
Python pygame新手入门基础教程
目录 pygame简介 pygame实现窗口 设置屏幕背景色 添加文字 绘制多边形 绘制直线 绘制圆形 绘制椭圆 绘制矩形 总结 pygame简介 pygame可以实现python游戏的一个基础包. pygame实现窗口 初始化pygame,init()类似于java类的初始化方法,用于pygame初始化. pygame.init() 设置屏幕,(500,400)设置屏幕初始大小为500 * 400的大小, 0和32 是比较高级的用法.这样我们便设置了一个500*400的屏幕. surface
-
python爬虫(入门教程、视频教程) 原创
python的版本经过了python2.x和python3.x等版本,无论哪种版本,关于python爬虫相关的知识是融会贯通的,我们关于爬虫这个方便整理过很多有价值的教程,小编通过本文章给大家做一个关于python爬虫相关知识的总结,以下就是全部内容: python爬虫的基础概述 1.什么是爬虫 网络爬虫,即Web Spider,是一个很形象的名字.把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛.网络蜘蛛是通过网页的链接地址来寻找网页的.从网站某一个页面(通常是首页)开始,读
-
Java 网络爬虫新手入门详解
这是 Java 网络爬虫系列文章的第一篇,如果你还不知道 Java 网络爬虫系列文章,请参看Java 网络爬虫基础知识入门解析.第一篇是关于 Java 网络爬虫入门内容,在该篇中我们以采集虎扑列表新闻的新闻标题和详情页为例,需要提取的内容如下图所示: 我们需要提取图中圈出来的文字及其对应的链接,在提取的过程中,我们会使用两种方式来提取,一种是 Jsoup 的方式,另一种是 httpclient + 正则表达式的方式,这也是 Java 网络爬虫常用的两种方式,你不了解这两种方式没关系,后面会有相应
-
Python爬虫天气预报实例详解(小白入门)
本文研究的主要是Python爬虫天气预报的相关内容,具体介绍如下. 这次要爬的站点是这个:http://www.weather.com.cn/forecast/ 要求是把你所在城市过去一年的历史数据爬出来. 分析网站 首先来到目标数据的网页 http://www.weather.com.cn/weather40d/101280701.shtml 我们可以看到,我们需要的天气数据都是放在图表上的,在切换月份的时候,发现只有部分页面刷新了,就是天气数据的那块,而URL没有变化. 这是因为网页前端使用
-
python爬虫请求库httpx和parsel解析库的使用测评
Python网络爬虫领域两个最新的比较火的工具莫过于httpx和parsel了.httpx号称下一代的新一代的网络请求库,不仅支持requests库的所有操作,还能发送异步请求,为编写异步爬虫提供了便利.parsel最初集成在著名Python爬虫框架Scrapy中,后独立出来成立一个单独的模块,支持XPath选择器, CSS选择器和正则表达式等多种解析提取方式, 据说相比于BeautifulSoup,parsel的解析效率更高. 今天我们就以爬取链家网上的二手房在售房产信息为例,来测评下http
-
关于python爬虫应用urllib库作用分析
目录 一.urllib库是什么? 二.urllib库的使用 urllib.request模块 urllib.parse模块 利用try-except,进行超时处理 status状态码 && getheaders() 突破反爬 一.urllib库是什么? urllib库用于操作网页 URL,并对网页的内容进行抓取处理 urllib包 包含以下几个模块: urllib.request - 打开和读取 URL. urllib.error - 包含 urllib.request 抛出的异常. ur
-
python爬虫入门教程--HTML文本的解析库BeautifulSoup(四)
前言 python爬虫系列文章的第3篇介绍了网络请求库神器 Requests ,请求把数据返回来之后就要提取目标数据,不同的网站返回的内容通常有多种不同的格式,一种是 json 格式,这类数据对开发者来说最友好.另一种 XML 格式的,还有一种最常见格式的是 HTML 文档,今天就来讲讲如何从 HTML 中提取出感兴趣的数据 自己写个 HTML 解析器来解析吗?还是用正则表达式?这些都不是最好的办法,好在,Python 社区在这方便早就有了很成熟的方案,BeautifulSoup 就是这一类问题
-
python爬虫入门教程--优雅的HTTP库requests(二)
前言 urllib.urllib2.urllib3.httplib.httplib2 都是和 HTTP 相关的 Python 模块,看名字就觉得很反人类,更糟糕的是这些模块在 Python2 与 Python3 中有很大的差异,如果业务代码要同时兼容 2 和 3,写起来会让人崩溃. 好在,还有一个非常惊艳的 HTTP 库叫 requests,它是 GitHUb 关注数最多的 Python 项目之一,requests 的作者是 Kenneth Reitz 大神. requests 实现了 HTTP