PostgreSQL LIST、RANGE 表分区的实现方案
简 介
PG分区:就是把逻辑上的一个大表分割成物理上的几块。
分区的优点
1. 某些类型的查询性能得到提升
2. 更新的性能也可以得到提升,因为某块的索引要比在整个数据集上的索引要小。
3. 批量删除可以通过简单的删除某个分区来实现。
4. 可以将很少用的数据移动到便宜的、转速慢的存储介质上。
分区实现原理
10.x版本之前PG表分区的实现原理:PG中是通过表的继承来实现的,建立一个主表,里面是空的,然后每个分区去继承它。无论何时,该主表里面都必须是空的
官网建议:只有当表本身大小超过了机器物理内存的实际大小时,才考虑分区。
原分区用法
以继承表的方式实现:
create table tbl( a int, b varchar(10) ); create table tbl_1 ( check ( a <= 1000 ) ) INHERITS (tbl); create table tbl_2 ( check ( a <= 10000 and a >1000 ) ) INHERITS (tbl); create table tbl_3 ( check ( a <= 100000 and a >10000 ) ) INHERITS (tbl);
再通过创建触发器或者规则,实现数据分发,只需要向子表插入数据则会自动分配到子表中
CREATE OR REPLACE FUNCTION tbl_part_tg() RETURNS TRIGGER AS $$ BEGIN IF ( NEW. a <= 1000 ) THEN INSERT INTO tbl_1 VALUES (NEW.*); ELSIF ( NEW. a > 1000 and NEW.a <= 10000 ) THEN INSERT INTO tbl_2 VALUES (NEW.*); ELSIF ( NEW. a > 10000 and NEW.a <= 100000 ) THEN INSERT INTO tbl_3 VALUES (NEW.*); ELSIF ( NEW. a > 100000 and NEW.a <= 1000000 ) THEN INSERT INTO tbl_4 VALUES (NEW.*); ELSE RAISE EXCEPTION 'data out of range!'; END IF; RETURN NULL; END; $$ LANGUAGE plpgsql; CREATE TRIGGER insert_tbl_part_tg BEFORE INSERT ON tbl FOR EACH ROW EXECUTE PROCEDURE tbl_part_tg();
分区创建成功
如何实现分区过滤?
对于分区表来说,如果有50个分区表,对于某个条件的值如果能确定,那么很可能直接过滤掉49个分区,大大提高扫描速度,当然分区表也能放在不同的物理盘上,提高IO速度。
对于查询是怎么实现分区表过滤呢?
约束排除 是否使用约束排除通过postgresql.conf中参数constraint_exclusion 来控制,
只有三个值
constraint_exclusion = on
on:所有情况都会进行约束排除检查
off:关闭,所有约束都不生效
partition:对分区表或者继承表进行约束排查,默认为partition
如:
select *from tbl where a = 12345;
首先找到主表tbl,然后通过tbl找到它的子表,找到后再对再拿着谓词条件a = 12345对一个个子表约束进行检查,不符合条件表就去掉不扫描,实现分区表过滤,下面简单介绍下约束排除源码逻辑。
如何实现数据分发?
基于规则的话,会在查询重写阶段按时替换规则生成新的插入语句,基于触发器会在insert主表前触发另外一个insert操作,这两个逻辑都比较简单,相关代码不再介绍。
错误描述:在新建分区主表时提示以下错误信息
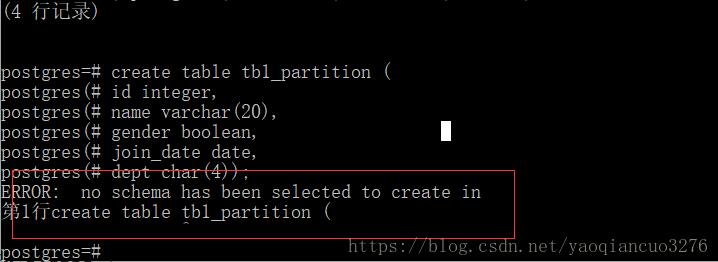
错误原因:在本地postgresql.conf 配置了 search_path = ‘$user' ,所以在使用的时候需要先创建当前用户对应的schema,如果不存在,则会提示错误
解决方法:在创建表时指定创建的schemal,即可成功。

PostgreSQL 10.x LIST分区方案
postgres=# CREATE TABLE list_parted (
postgres(# a int
postgres(# ) PARTITION BY LIST (a);
CREATE TABLE
postgres=# CREATE TABLE part_1 PARTITION OF list_parted FOR VALUES IN (1);
CREATE TABLE
postgres=# CREATE TABLE part_2 PARTITION OF list_parted FOR VALUES IN (2);
CREATE TABLE
postgres=# CREATE TABLE part_3 PARTITION OF list_parted FOR VALUES IN (3);
CREATE TABLE
postgres=# CREATE TABLE part_4 PARTITION OF list_parted FOR VALUES IN (4);
CREATE TABLE
postgres=# CREATE TABLE part_5 PARTITION OF list_parted FOR VALUES IN (5);
CREATE TABLE
postgres=#
postgres=# insert into list_parted values(32); --faled
ERROR: no partition of relation "list_parted" found for row
DETAIL: Failing row contains (32).
postgres=# insert into part_1 values(1);
INSERT 0 1
postgres=# insert into part_1 values(2);--faled
ERROR: new row for relation "part_1" violates partition constraint
DETAIL: Failing row contains (2).
postgres=# explain select *from list_parted where a =1;
QUERY PLAN
-----------------------------------------------------------------
Append (cost=0.00..41.88 rows=14 width=4)
-> Seq Scan on list_parted (cost=0.00..0.00 rows=1 width=4)
Filter: (a = 1)
-> Seq Scan on part_1 (cost=0.00..41.88 rows=13 width=4)
Filter: (a = 1)
(5 rows)
上面是LIST分区表,建表是先建主表,再建子表,子表以 PARTITION OF 方式说明和主表关系,约束条件应该就是后面的in里面。
Explain 执行sql解析计划
cost:数据库自定义的消耗单位,通过统计信息来估计SQL消耗。(查询分析是根据analyze的固执生成的,生成之后按照这个查询计划执行,执行过程中analyze是不会变的。所以如果估值和真是情况差别较大,就会影响查询计划的生成。)
rows:根据统计信息估计SQL返回结果集的行数。
width:返回结果集每一行的长度,这个长度值是根据pg_statistic表中的统计信息来计算的。

PostgreSQL 10.x RANGE分区
创建RANGE分区
postgres=# CREATE TABLE range_parted (
postgres(# a int
postgres(# ) PARTITION BY RANGE (a);
CREATE TABLE
postgres=# CREATE TABLE range_parted1 PARTITION OF range_parted FOR VALUES from (1) TO (1000);
CREATE TABLE
postgres=# CREATE TABLE range_parted2 PARTITION OF range_parted FOR VALUES FROM (1000) TO (10000);
CREATE TABLE
postgres=# CREATE TABLE range_parted3 PARTITION OF range_parted FOR VALUES FROM (10000) TO (100000);
CREATE TABLE
postgres=#
postgres=# insert into range_parted1 values(343);
INSERT 0 1
postgres=#
postgres=# explain select *from range_parted where a=32425;
QUERY PLAN
---------------------------------------------------------------------
Append (cost=0.00..41.88 rows=14 width=4)
-> Seq Scan on range_parted (cost=0.00..0.00 rows=1 width=4)
Filter: (a = 32425)
-> Seq Scan on range_parted3 (cost=0.00..41.88 rows=13 width=4)
Filter: (a = 32425)
(5 rows)
postgres=# set constraint_exclusion = off;
SET
postgres=# explain select *from range_parted where a=32425;
QUERY PLAN
---------------------------------------------------------------------
Append (cost=0.00..125.63 rows=40 width=4)
-> Seq Scan on range_parted (cost=0.00..0.00 rows=1 width=4)
Filter: (a = 32425)
-> Seq Scan on range_parted1 (cost=0.00..41.88 rows=13 width=4)
Filter: (a = 32425)
-> Seq Scan on range_parted2 (cost=0.00..41.88 rows=13 width=4)
Filter: (a = 32425)
-> Seq Scan on range_parted3 (cost=0.00..41.88 rows=13 width=4)
Filter: (a = 32425)
(9 rows)
上述操作中的 a的取值范围为【0,1000)即插入值若为1000边界值,则会保存在第二个分区表中和LIST差不多,就是语法略有不同,范围表值是一个连续的范围,LIST表是单点或多点的集合。
从上面例子可以看到,显然还是走的约束排除过滤子表的方式。
constraint_exclusion = “on ,off,partition ”; 该参数为postgresql.conf中的参数
on 表示所有的查询都会执行约束排除
off 关闭,所有的查询都不会执行约束排除
partition :表示只对分区的表进行约束排除
分区列的类型必须支持btree索引接口(几乎涵盖所有类型, 后面会说到检查方法)。
更新后的数据如果超出了所在分区的范围,则会报错

PostgreSQL 分区注意事项
语法
1、创建主表
[ PARTITION BY { RANGE | LIST } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ]
2、创建分区
PARTITION OF parent_table [ (
{ column_name [ column_constraint [ ... ] ]
| table_constraint }
[, ... ]
) ] FOR VALUES partition_bound_spec
and partition_bound_spec is:
{ IN ( expression [, ...] ) -- list分区
|
FROM ( { expression | UNBOUNDED } [, ...] ) TO ( { expression | UNBOUNDED } [, ...] ) } -- range分区, unbounded表示无限小或无限大
语法解释
partition by 指定分区表的类型range或list指定分区列,或表达式作为分区键。
range分区表键:支持指定多列、或多表达式,支持混合(键,非表达式中的列,会自动添加not null的约束)
list分区表键:支持单个列、或单个表达式
分区键必须有对应的btree索引方法的ops(可以查看系统表得到)
select typname from pg_type where oid in (select opcintype from pg_opclass);
主表不会有任何数据,数据会根据分区规则进入对应的分区表
如果插入数据时,分区键的值没有匹配的分区,会报错
不支持全局的unique, primary key, exclude, foreign key约束,只能在对应的分区建立这些约束
分区表和主表的 列数量,定义 必须完全一致,(包括OID也必须一致,要么都有,要么都没有)
可以为分区表的列单独增加Default值,或约束。
用户还可以对分区表增加表级约束
如果新增的分区表check约束,名字与主表的约束名一致,则约束内容必须与主表一致
当用户往主表插入数据库时,记录被自动路由到对应的分区,如果没有合适的分区,则报错
如果更新数据,并且更新后的KEY导致数据需要移动到另一分区,则会报错,(意思是分区键 可以更新,但是不支持更新后的数据移出到别的分区表)
修改主表的字段名,字段类型时,会自动同时修改所有的分区
TRUNCATE 主表时,会清除所有继承表分区的记录(如果有多级分区,则会一直清除到所有的直接和间接继承的分区)
如果要清除单个分区,请对分区进行操作
如果要删除分区表,可以使用DROP TABLE的DDL语句,注意这个操作会对主表也加access exclusive lock。
补充:对PostgreSQL语法分析中 targetlist 的理解
在 gram.y 中:
simple_select:
SELECT opt_distinct target_list
into_clause from_clause where_clause
group_clause having_clause window_clause
{
SelectStmt *n = makeNode(SelectStmt);
n->distinctClause = $2;
n->targetList = $3;
n->intoClause = $4;
n->fromClause = $5;
n->whereClause = $6;
n->groupClause = $7;
n->havingClause = $8;
n->windowClause = $9;
$$ = (Node *)n;
}
……
把它修改一下,增加:
simple_select:
SELECT opt_distinct target_list
into_clause from_clause where_clause
group_clause having_clause window_clause
{
SelectStmt *n = makeNode(SelectStmt);
n->distinctClause = $2;
n->targetList = $3;
n->intoClause = $4;
n->fromClause = $5;
n->whereClause = $6;
n->groupClause = $7;
n->havingClause = $8;
n->windowClause = $9;
$$ = (Node *)n;
fprintf(stderr,"length of list: %d\n", n->targetList->length);
}
……
psql 中执行:
select id, name from a8;
后台出现:
length of list: 2
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

浅谈PostgreSQL的客户端认证pg_hba.conf
大家都知道防火墙主要是用来过滤客户端并保护服务器不被恶意访问攻击,那在pg中同样存在一个类似于防火墙的工具用来控制客户端的访问,也就是pg_hba.conf这个东东. 在initdb初始化数据文件时,默认提供pg_hba.conf. 通过配置该文件,能够指定哪些ip可以访问,哪些ip不可以访问,以及访问的资源和认证方式,该文件类似于oracle中的监听中的白名单黑名单功能,且同样可以reload在线生效. 记录可以是下面七种格式之一: local database user auth-metho
-
基于PostgreSQL pg_hba.conf 配置参数的使用说明
pg_hba.conf 配置详解 该文件位于初始化安装的数据库目录下 编辑 pg_hba.conf 配置文件 postgres@clw-db1:/pgdata/9.6/poc/data> vi pg_hba.conf TYPE 参数设置 TYPE 表示主机类型,值可能为: 若为 `local` 表示是unix-domain的socket连接, 若为 `host` 是TCP/IP socket 若为 `hostssl` 是SSL加密的TCP/IP socket DATABASE 参数设置 DATA
-
postgresql表死锁问题的排查方式
1.查询激活的执行中的sql,查看有哪些更新update的sql. select * from pg_stat_activity where state = 'active'; 2. 查询表中存在的锁 select a.locktype, a.database, a.pid, a.mode, a.relation, b.relname from pg_locks a join pg_class b on a.relation = b.oid where lower(b.relname) = 'h
-
Postgresql 跨库同步表及postgres_fdw的用法说明
postgres_fdw模块 PostgreSQL 9.3 add postgres_fdw extension for accessing remote tables PostgreSQL 9.3新增了一个postgres_fdw模块, 已经整合在源码包中. 用于创建postgres外部表. 注:db_des为目标库,developer_month_orders_data为表名.意思就是从查询库a中建立同名FOREIGN关联表, 可以查询目标库中的数据.以下命令在需要建立的关联库中执行. 目标
-
PostgreSql 导入导出sql文件格式的表数据实例
PostgreSql默认导出的文件格式是.backup,而我们很多数据库导入数据库脚本时是.sql文件格式的,PostgreSql作为国内的新潮,会不会不支持导出.sql文件格式吗?答案是当然不会.下面我们借助Pg Admin III工具来导出.sql的脚本的. 一.导出 首先,你当然得有一张完整的数据表啦,并且保证里面是有数据的: 有了表和数据之后,选中该表: 选中右键 --> 备份 我们可以看到文件名默认以.backup格式的方式进行数据备份的. 首先将自定义格式 --> 无格式 点开之后
-
在postgresql中运行sql文件并导出结果的操作
方法一 在psql中运行 在终端进入用户test下的数据库testdb: $ psql -p 5432 -U test -d testdb 假设要执行的.sql文件叫做d1.sql,存放路径为:/mnt/hgfs/share/database/2.18.0_rc2/dbgen/queries/d1.sql,导出的文件叫做d1.out,存放的路径为:/mnt/hgfs/share/database/2.18.0_rc2/dbgen/queries/out/d1.out testdb=# \o /m
-
postgresql 实现获取所有表名,字段名,字段类型,注释
获取表名及注释: select relname as tabname,cast(obj_description(relfilenode,'pg_class') as varchar) as comment from pg_class c where relkind = 'r' and relname not like 'pg_%' and relname not like 'sql_%' order by relname 过滤掉分表: 加条件 and relchecks=0 即可 获取字段名.类
-
在postgreSQL中运行sql脚本和pg_restore命令方式
今天踩坑了,把powerdesign生成的sql脚本文件,用pg_restore命令一直运行... 过程惨不忍睹,一直以为是编码问题,修改了serve和client的encoding,结果... 记录一下这个错误: postgreSQL运行sql脚本文件: psql -d dbname -U username -f (脚本所在位置).sql postgerSQL的pg_restore命令 用法: pg_restore [选项]- [文件名] 一般选项: -d, --dbname=名字 连接数据库
-
PostgreSQL LIST、RANGE 表分区的实现方案
简 介 PG分区:就是把逻辑上的一个大表分割成物理上的几块. 分区的优点 1. 某些类型的查询性能得到提升 2. 更新的性能也可以得到提升,因为某块的索引要比在整个数据集上的索引要小. 3. 批量删除可以通过简单的删除某个分区来实现. 4. 可以将很少用的数据移动到便宜的.转速慢的存储介质上. 分区实现原理 10.x版本之前PG表分区的实现原理:PG中是通过表的继承来实现的,建立一个主表,里面是空的,然后每个分区去继承它.无论何时,该主表里面都必须是空的 官网建议:只有当表本身大小超过了机器物理
-
浅谈PostgreSQL表分区的三种方式
目录 一.简介 二.三种方式 2.1.Range范围分区 2.2.List列表分区 2.3.Hash哈希分区 三.总结 一.简介 表分区是解决一些因单表过大引用的性能问题的方式,比如某张表过大就会造成查询变慢,可能分区是一种解决方案.一般建议当单表大小超过内存就可以考虑表分区了.PostgreSQL的表分区有三种方式: Range:范围分区: List:列表分区: Hash:哈希分区. 本文通过示例讲解如何进行这三种方式的分区. 二.三种方式 为方便,我们通过Docker的方式启动一个Postg
-
PostgreSQL 创建表分区
创建表分区步骤如下: 1. 创建主表 CREATE TABLE users ( uid int not null primary key, name varchar(20)); 2. 创建分区表(必须继承上面的主表) CREATE TABLE users_0 ( check (uid >= 0 and uid< 100) ) INHERITS (users); CREATE TABLE users_1 ( check (uid >= 100)) INHERITS (users); 3.
-
MySQL数据库表分区注意事项大全【推荐】
表分区与数据库分区是不一样的那么碰到表分区使用时我们要注意一些什么事情呢,今天我们来看一篇关于MySQL数据库表分区注意事项的细节. 1.分区列索引约束 若表有primary key或unique key,则分区表的分区列必须包含在primary key或unique key列表里,这是为了确保主键的效率,否则同一主键区的东西一个在A分区,一个在B分区,显然会比较麻烦. 2.各分区类型条件 range 每个分区包含那些分区表达式的值位于一个给定的连续区间内的行.这些区间要连续且不能相互重叠 li
-
创建mysql表分区的方法
表分区是最近才知道的哦 ,以前自己做都是分表来实现上亿级别的数据了,下面我来给大家介绍一下mysql表分区创建与使用吧,希望对各位同学会有所帮助.表分区的测试使用,主要内容来自于其他博客文章以及mysql5.1的参考手册mysql测试版本:mysql5.5.28mysql物理存储文件(有mysql配置的datadir决定存储路径)格式简介数据库engine为MYISAM frm表结构文件,myd表数据文件,myi表索引文件.INNODB engine对应的表物理存储文件innodb的数据库的物理
-
MySQL的表分区详解
一.什么是表分区通俗地讲表分区是将一大表,根据条件分割成若干个小表.mysql5.1开始支持数据表分区了.如:某用户表的记录超过了600万条,那么就可以根据入库日期将表分区,也可以根据所在地将表分区.当然也可根据其他的条件分区. 二.为什么要对表进行分区为了改善大型表以及具有各种访问模式的表的可伸缩性,可管理性和提高数据库效率.分区的一些优点包括: 1).与单个磁盘或文件系统分区相比,可以存储更多的数据. 2).对于那些已经失去保存意义的数据,通常可以通过删除与那些数据有关的
-
SQL Server表分区删除详情
目录 一.引言 二.演示 2.1.数据查询 2.1.1. 查看分区元数据 2.1.2.统计每个分区的数据量 2.2.删除实操 2.2.1.合并原表分区 2.2.2.备份原表所有索引的创建脚本 2.2.3.删除原表所有索引 2.2.4.创建临时表 2.2.5.更改原表数据空间类型 2.2.6.移动原表分区数据到临时表 2.2.7.创建原表所有索引 到临时表 2.2.8.删除原表 2.2.9.删除分区方案和分区函数 2.2.10重命名表名 一.引言 删除分区又称为合并分区,简单地讲就是将多个分区的数
-
SQL server 2005的表分区
下面来说下,在SQL SERVER 2005的表分区里,如何对已经存在的有数据的表进行分区,其实道理和之前在http://www.cnblogs.com/jackyrong/archive/2006/11/13/559354.html说到一样,只不过交换下顺序而已,下面依然用例子说明: 依然在c盘的data2目录下建立4个文件夹,用来做4个文件组,然后建立数据库 use masterIF EXISTS (SELECT name FROM sys.databases WHERE name =
-
oracle表空间表分区详解及oracle表分区查询使用方法
此文从以下几个方面来整理关于分区表的概念及操作:1.表空间及分区表的概念2.表分区的具体作用3.表分区的优缺点4.表分区的几种类型及操作方法5.对表分区的维护性操作.(1.) 表空间及分区表的概念表空间:是一个或多个数据文件的集合,所有的数据对象都存放在指定的表空间中,但主要存放的是表, 所以称作表空间. 分区表: 当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区.表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间
-
Oracle数据表分区的策略
正在看的ORACLE教程是:Oracle数据表分区的策略.本文描述通过统计分析出医院信息系统需分区的表,对需分区的表选择分区键,即找出包括在你的分区键中的列(表的属性),对大型数据的管理比较有意义, 本文的工作在Oracle8.1.6下实现. Oracle虽然是一个大型的DBMS,但如果不对记录比较多的表进行处理,仍然发挥不了Oracle管理大型数据的强大功能,因此对某些表进行分区,具有如下优点: 分区表中每个分区可以在逻辑上认为是一个独立的对象: 可以在一个表中的一个或多个分区上进行如删除.移