Python音乐爬虫完美绕过反爬
目录
- 前言
- 开始
- 分析(x0)
- 分析(x1)
- 分析(x2)
- 分析(x3)
- 分析(x4)
- 通过分析获取到音乐
- JavaScript绕过之参数冗余
- CSRF攻击与防御
- 总结
- 代码
前言
大家好,我叫善念。
这是我的第二篇博客,也是第一篇技术博客,希望大家多多支持,让我更加有动力去更新一些python爬虫类的案例教程。

开始
确立目标网址:点击进入
进入到跳转页面:
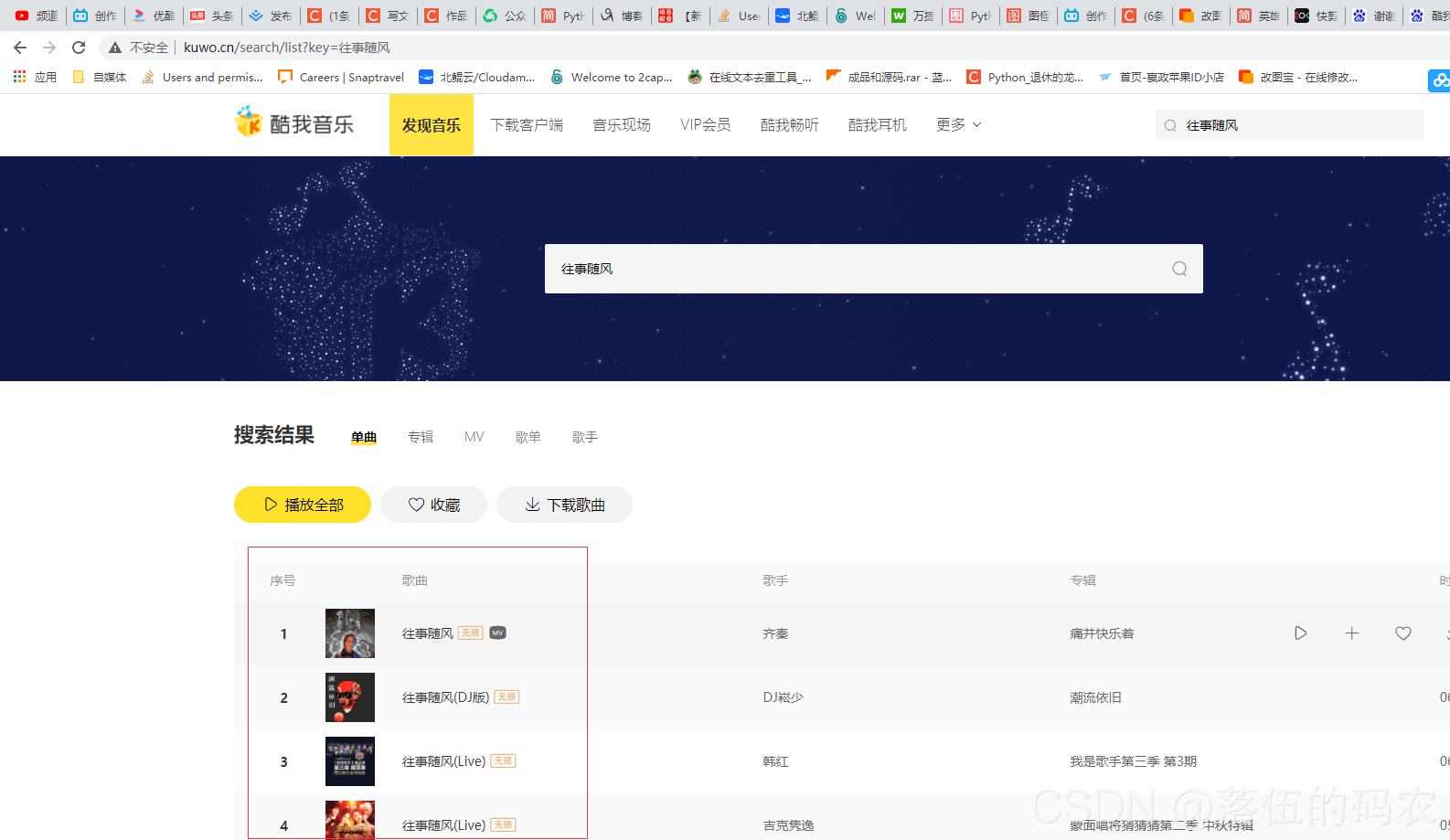
可以看到出现了咱们需要的一些音乐
分析(x0)
这些音乐的源文件地址是否在咱们的网页元素中,然后再查看网页源代码中是否有咱们需要的内容。(注:网页元素与网页源代码不一定是一样的,网页元素是经过浏览器渲染后的源代码,而源代码纯粹就是服务器给咱们传送过来的原始数据)
网页元素中只有封面图片的资源,没用音频源文件地址:

网页源代码中同样没有咱们需要的内容:

分析(x1)
其实没有才正常(这种大型网站的数据不会让你这么轻易抓取)....不过是带大家走一遍流程,对别的网站也要这样分析
那么咱们开始播放音乐抓包,看是否能抓到数据:

果然是经过触发播放按钮后,服务器传给咱们客户端的。(ajax)
而咱们抓到的这个源文件地址

除了这两段外,其它的应该都是固定死的。
分析(x2)
那么我假设这两段是从我开始访问这首歌曲页面的时候生成的,比如后面那串数字为这首音乐在服务器数据库中的对应的一个ID值呢?
假设是合理的,不过由于咱们前面已经查看过源代码和网页元素中找不到这些值,我就不在这里浪费时间了。
分析(x3)
这里我和大家讲一下,咱们向服务器发送一个网址请求,服务器给咱们返回的可不止一个数据包,一般都是N个数据包。当我们看到源代码中没有时候,也许它正悄悄地通过Ajax传给我们了?
Ajax在网上有很多的解释,但是大家未必能理解。从服务器获得源代码数据,然后通过浏览器渲染执行JavaScript获得一些数据(音乐)。
这样说大家应该就懂了,那么咱们开始抓当前页面的包:

Ajax异步请求的数据,都会在XHR中。所以直接筛选就好了。这个包我已经抓到了,get请求然后看下返回的值。

果然就是这个包数据都是对应的,然后打开看看里面是否有音乐源文件地址:

并没有,但是有一个rid出现了两次。
分析(x4)
那么它是否是咱们音乐的ID(索引)值?
接着看下面的包:

这个get请求很关键,它的参数中利用到了咱们的rid这个值
而他返回值里正好有咱们的音乐源文件地址:

通过分析获取到音乐
通过咱们的分析,已经可以理清思路了。
首先抓取这个包获取到rid
然后传递rid进行这个包的请求获取到音乐文件地址
JavaScript绕过之参数冗余

可以看到这个rid获取的地址中有key值是url编码很轻松就可以解码:
import requests keywords = '%E5%BE%80%E4%BA%8B%E9%9A%8F%E9%A3%8E' print(requests.utils.unquote(keywords)) # 往事随风
而pn=1意思就是第一页嘛,30就是这一页总共30条音乐数据咯,1代表状态码请求成功,而最后reqId这个值如何获取呢?

有能力的自己去逆向JavaScript,而咱们这里直接把这里的参数都删除掉,同样可以访问到咱们的rid,为什么呢?
当你访问百度的时候

可以看到多余了很多你看不懂的参数,而这些参数实际上可以直接删除掉!

结果是一样的,这个就叫参数冗余。
CSRF攻击与防御
当咱们直接访问这个链接确出现这样的画面?

而咱们如果把请求头全部放到咱们的pycharm中利用Python模拟发送请求却可以成功(自行测试)

可以看到请求中有一个参数叫csrf,这个叫做防跨站点攻击。
这个就好理解了,当我们用浏览器直接访问的话,尽管可以带cookies,但是咱们是没法携带这个参数的。而当我们把请求头完整的复制在pycharm中Python运行的话,就可以携带这个参数,那么就可以访问。
目的就是保护此api防止任意情况下都可以随便访问。
而这个csrf参数不就是咱们cookies中的值么?那么是不是咱们首先需要获取cookies?因为cookies会过期阿,为了让你的程序永久有效,那么最好的办法就是自动获取cookies
总结
那么所有的原理都可以搞清楚了
首先访问首页获取cookies,然后绕过JavaScript删除多余的参数获取到rid,最后通过rid进行访问获取到音乐源地址(这里的参数也可以删除),最后保存数据!
全程干货,分析网站反扒手段,Python采集整站任意音乐!
代码
"""
author: 善念
date: 2021-04-12
"""
import requests
import jsonpath
from urllib.request import urlretrieve
import urllib.parse
def get_csrf():
# 保持cookies 维持客户端与服务器之间的会话
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1618229629; _ga=GA1.2.1951895595.1618229638; _gid=GA1.2.369506281.1618229638; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1618230532; kw_token=ZOMA0RIOLV',
'Host': 'www.kuwo.cn',
'Pragma': 'no-cache',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
}
s.get('http://www.kuwo.cn/', headers=headers)
url = f'http://www.kuwo.cn/api/www/search/searchMusicBykeyWord?key={keyword}&pn=1&rn=30&httpsStatus=1&reqId=a3b6cb30-9b8a-11eb-bc04-b33703ed2ebb'
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1618229629; _ga=GA1.2.1951895595.1618229638; _gid=GA1.2.369506281.1618229638; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1618229710; kw_token=UTBATXE1HY',
'csrf': s.cookies.get_dict()['kw_token'],
'Host': 'www.kuwo.cn',
'Pragma': 'no-cache',
'Referer': f'http://www.kuwo.cn/search/list?key={keyword}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
}
r = s.get(url, headers=headers)
print(r.text)
rid = jsonpath.jsonpath(r.json(), '$..rid')[0]
print(rid)
return rid
def get_music_url(rid):
url = f'http://www.kuwo.cn/url?format=mp3&rid={rid}&response=url&type=convert_url3&br=128kmp3&from=web&httpsStatus=1'
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1618231398; _ga=GA1.2.52993118.1618231399; _gid=GA1.2.889494894.1618231399; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1618231413; _gat=1; kw_token=VBM6N1XEG4P',
'Host': 'www.kuwo.cn',
'Pragma': 'no-cache',
'Referer': f'http://www.kuwo.cn/search/list?key={keyword}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
}
music_url = s.get(url, headers=headers).json().get('url')
print(music_url)
return music_url
def get_music(music_url):
urlretrieve(music_url, f'{urllib.parse.unquote(keyword)}'+'.mp3')
def go():
rid = get_csrf()
music_url = get_music_url(rid)
get_music(music_url)
if __name__ == '__main__':
s = requests.session()
keyword = input('请输入您要下载的音乐名字:')
keyword = urllib.parse.quote(keyword)
go()
到此这篇关于Python音乐爬虫完美绕过反爬的文章就介绍到这了,更多相关Python爬取音乐内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python如何爬取qq音乐歌词到本地
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 闲来无事听听歌,听到无聊唠唠嗑,你有没有特别喜欢的音乐,你有没有思考或者尝试过把自己喜欢的歌曲的歌词全部给下载下来呢? 没错,我这么干了,今天我们以QQ音乐为例,使用Python爬虫的方式把自己喜欢的音乐的歌词爬取到本地! 下面就来详细讲解如何一步步操作,文末附完整代码. 01 寻找真正的客户端(client_search)(客户端搜索) 搜索网站:https://y.q
-
python爬取网易云音乐热歌榜实例代码
首先找到要下载的歌曲排行榜的链接,这里用的是: https://music.163.com/discover/toplist?id=3778678 然后更改你要保存的目录,目录要先建立好文件夹,例如我的是保存在D盘-360下载-网易云热歌榜文件夹内,就可以完成下载. 如果文件夹没有提前建好,会报错[Errno 2] No such file or directory. 代码实现: from urllib import request from bs4 import BeautifulSoup i
-

python实现可下载音乐的音乐播放器
本文实例为大家分享了tkinter+pygame+spider实现音乐播放器,供大家参考,具体内容如下 1.确定页面 SongSheet ------ 显示歌单 MusicCtrl ------显示音乐一些控件(播放,跳转,音量调节) SearchWindows ------搜索栏(搜索歌曲默认显示20条,可下载) songSheet.py #!/usr/bin/env python # -*- coding:utf-8 -*- # @Author: Minions # @Date: 2019-
-
python给视频添加背景音乐并改变音量的具体方法
用到给视频添加背景音乐,并改变音量.记录一下,与碰到同样问题的朋友共享. import subprocess inmp4='E:/PycharmProjects/untitled2/hecheng/191030_232_xs.mp4' inmp3='E:/PycharmProjects/untitled2/hecheng/bg.mp3' inmp32='E:/PycharmProjects/untitled2/hecheng/bg2.mp3' outmp3='E:/PycharmProjects
-
python中加背景音乐如何操作
在python中加背景音乐的方法: 1.导入pygame资源包: 2.修改音乐的file路径: 3.使用init()方法进行初始化: 4.使用load()方法添加音乐文件: 5.使用play()方法播放音乐流即可. 下面的代码直接复制粘贴到自己的代码即可实现音乐的添加.(第二行的音乐的地址需要写自己的地址) import pygame# 导入pygame资源包 file=r'E:\Python_Exercise\123.mp3'# 音乐的路径 pygame.mixer.init()# 初始化 t
-
python实现音乐播放和下载小程序功能
(本篇部分代码综合整理自B站,B站有手把手说明的教程) 1.网易云非付费内容爬取器(声明:由于技术十分简单,未到触犯软件使用规则的程度)驱动Edge浏览器(自己写驱动会更高端)进入界面,爬取列表中第一个音频地址并存入相应文件夹中.这里有一个最简单的爬虫程序和一个最简单的tkinter GUI编程. 注意,要先在网易云音乐网页中将第一个对应音频链接的位置定位: 对于以上定位可通过如下方式获得(定位器): req = driver.find_element_by_id('m-search') a_i
-
基于python实现音乐播放器代码实例
核心播放模块(pygame内核) import time import pygame import easygui as gui file = r'D:\CloudMusic\G.E.M.邓紫棋,艾热 - 光年之外 (热爱版).mp3' #这里为音乐文件路径 pygame.mixer.init() gui.msgbox("正在播放"+file) track = pygame.mixer.music.load(file) pygame.mixer.music.play() time.sl
-
Python基于爬虫实现全网搜索并下载音乐
现在写一篇博客总是喜欢先谈需求或者本内容的应用场景,是的,如果写出来的东西没有任何应用价值,确实也没有实际意义.今天的最早的需求是来自于如何免费[白嫖]下载全网优质音乐,我去b站上面搜索到了一个大牛做过的一个歌曲搜素神器,界面是这样的: 确实很好用的,而且涵盖了互联网上面大多数主流的音乐网站,涉及到的版本也很多,可谓大而全,但是一个技术人的追求远远不会如此,于是我就想去了解其中背后的原理,因为做过网络爬虫的人都知道,爬虫只能爬取某一页或者某些页的网站资源,所以我很好奇它背后是怎么实现的? 笔者一
-
python打开音乐文件的实例方法
按推荐顺序排列 1.使用playsound库 from playsound import playsound playsound('xx.mp3') 2.使用pygame库 from pygame import mixer import time mixer.init() mixer.music.load('xx.mp3') mixer.music.play() time.sleep(5) mixer.music.stop() 3.使用mp3play库(仅支持python2,对python3不
-
如何基于Python批量下载音乐
这篇文章主要介绍了如何基于Python批量下载音乐,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 音乐是生活的调剂品,目前很多的音乐只能播放不能下载.生为技术员的我们,怎么甘心呢? 知识点: requests 正则表达式 开发环境: 版 本:anaconda5.2.0(python3.6.5) 编辑器:pycharm 第三方库: requests parsel 网页分析 目标站点:http://music.taihe.com/search?ke
-
如何用Python一次性下载抖音上音乐
Python 链接抖音 python下载抖音内容的帖子网上有一些,但都比较麻烦,需要通过adb连接安卓手机后,模拟操作.我这么懒,这种事儿玩不来-那么,该如何获取抖音内容呢?网上搜了下大概有两种方式,一个是浏览器插件快抖,另外一个是我今天要说的抖音网页版.其实这两者差别不是很大,都是先将抖音内容下载至服务器后,通过开发简单网站配置域名后,让大家访问.让我们来看看抖音网页版: 爬虫实现分析 热歌榜内容 大家先开看看这个抖音热歌榜歌曲,每页20首歌曲,一个55页.但细不细心大家都能发现,很多歌曲存在