深入浅析RabbitMQ镜像集群原理
目录
- 集群架构
- 1)首先一个基本的 RabbitMQ 集群不是高可用的
- 2)其次 RabbitMQ 集群本身并没有提供负载均衡的功能
- 3)接着假设我们只采用一台 HAProxy
- 4)最后,任何想要连接到 RabbitMQ 集群的客户端
- 搭建集群准备:
- 1、准备3个虚拟机
- 2、设置node1、node2、node3的hosts
- 安装Erlang:
- 安装RabbitMQ:
- 同步cookie:
- 集群搭建:
集群架构
RabbitMQ 集群是一个或多个节点的逻辑分组,集群中的每个节点都是对等的
每个节点共享所有的用户,虚拟主机,队列,交换器,绑定关系,运行时参数和其他分布式状态等信息。
一个高可用,负载均衡的 RabbitMQ 集群架构应类似下图:
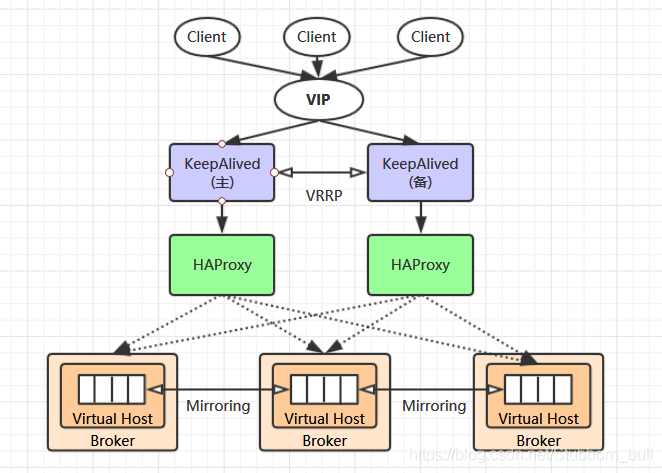
这里对上面的集群架构做一下解释说明:
1)首先一个基本的 RabbitMQ 集群不是高可用的
虽然集群共享队列,但在默认情况下,消息只会被路由到某一个节点的符合条件的队列上,并不会同步到其他节点的相同队列上。
假设消息路由到 node1 的 my-queue 队列上,但是 node1 突然宕机了,那么消息就会丢失
想要解决这个问题,需要开启队列镜像,将集群中的队列彼此之间进行镜像,此时消息就会被拷贝到处于同一个镜像分组中的所有队列上。
2)其次 RabbitMQ 集群本身并没有提供负载均衡的功能
也就是说对于一个三节点的集群,每个节点的负载可能都是不相同的,想要解决这个问题可以通过硬件负载均衡或者软件负载均衡的方式
这里我们选择使用 HAProxy 来进行负载均衡,当然也可以使用其他负载均衡中间件,如LVS等。
HAProxy 同时支持四层和七层负载均衡,并基于单一进程的事件驱动模型,因此它可以支持非常高的井发连接数。
3)接着假设我们只采用一台 HAProxy
那么它就存在明显的单点故障的问题
所以至少需要两台 HAProxy ,同时这两台 HAProxy 之间需要能够自动进行故障转移,通常的解决方案就是 KeepAlived 。
KeepAlived 采用 VRRP (Virtual Router Redundancy Protocol,虚拟路由冗余协议) 来解决单点失效的问题
它通常由一组一备两个节点组成,同一时间内只有主节点会提供对外服务,并同时提供一个虚拟的 IP 地址 (Virtual Internet Protocol Address ,简称 VIP) 。
如果主节点故障,那么备份节点会自动接管 VIP 并成为新的主节点 ,直到原有的主节点恢复。
4)最后,任何想要连接到 RabbitMQ 集群的客户端
只需要连接到虚拟 IP,而不必关心集群是何种架构。
搭建集群准备:
1、准备3个虚拟机
vi /etc/hostname #修改虚拟机名称 node1 node2 node3
| 虚拟机(机器)名称 | node1 | node2 | node3 |
|---|---|---|---|
| ip | 192.168.0.101 | 192.168.0.102 | 192.168.0.103 |
| 安装 | Erlang+RabbitMQ | Erlang+RabbitMQ | Erlang+RabbitMQ |
2、设置node1、node2、node3的hosts
vi /etc/hosts #修改虚拟机hosts node1 node2 node3
文件内容:
192.168.0.101 node1 192.168.0.102 node2 192.168.0.103 node3
安装Erlang:
由于RabbitMQ是基于Erlang(面向高并发的语言)语言开发,所以在安装RabbitMQ之前,需要先安装Erlang。
1.选择Erlang和RabbitMQ版本,这里选择RabbitMQ3.9.x、Erlang24.0,查看对应版本

3.更新基本系统,安装任何软件包之前,建议使用以下命令更新软件包和存储库
yum -y update
4、安装 tar
yum install -y tar
5、首先要先安装GCC、 GCC-C++、 Openssl等依赖模块:
yum -y install make gcc gcc-c++ kernel-devel m4 ncurses-devel openssl-devel
6、再安装ncurses模块
yum -y install ncurses-devel yum install ncurses-devel
7、将安装包拷贝到linux下:

8、解压ErLang安装包
[root@node1 /]# cd /usr/local/ #先切换到安装包目录 [root@nodel local]# ls #查看文件 bin etc games include lib lib64 libexec otp_src_24.0 otp_src_24.0.tar.gz sbin share src [root@nodel local]# tar -xvf otp_src_24.0.tar.gz #解压文件
9、创建安装的目录/usr/local/erlang
[root@node1 local]# mkdir erlang [root@node1 local]# ls bin erlang etc games include lib lib64 libexec otp_src_24.0 otp_src_24.0.tar.gz sbin share src [root@node1 local]#
10、切换到解压后的目录
[root@node1 local]# cd otp_src_24.0 [root@node1 otp_src_24.0]# ls AUTHORS bootstrap configure.src erl-build-tool-vars.sh HOWTO LICENSE.txt Makefile.in otp_patch_apply otp_versions.table prebuilt.files system xcomp bin configure CONTRIBUTING.md erts lib make otp_build OTP_VERSION plt README.md TAR.include [root@node1 otp_src_24.0]#
11、配置安装路径
./configure --prefix=/usr/local/erlang --with-ssl --enable-threads --enable-smp-support --enable-kernel-poll --enable-hipe --without-javac
erlang的编译需要用到java环境,如果不装,会报错如下,但不影响后续操作

12、进行编译安装
make && make install
13、查看安装
[root@node1 local]# cd erlang/ [root@node1 erlang]# ll total 4 drwxr-xr-x. 2 root root 4096 Aug 7 23:30 bin drwxr-xr-x. 3 root root 19 Aug 7 23:30 lib [root@node1 erlang]#
14、配置环境变量
vi /etc/profile
加入一下配置:
######### erlang ############# PATH=$PATH:/usr/local/erlang/bin ########################################
15、使配置生效:
source /etc/profile
16、直接输入 erl 、得到如下图得安装成功,输入 halt(). 退出

安装RabbitMQ:
1、Github下载

2、将安装包拷贝到linux下:

3、解压到 /usr/local/ 目录下
[root@node1 local]# tar -xvf rabbitmq-server-generic-unix-3.9.3.tar.xz ****** [root@node1 local]# ls bin etc include lib64 otp_src_24.0 rabbitmq_server-3.9.3 sbin src erlang games lib libexec otp_src_24.0.tar.gz rabbitmq-server-generic-unix-3.9.3.tar.xz share
4、添加环境变量
vi /etc/profile
加入一下配置:
######### RabbitMQ ############# PATH=$PATH:/usr/local/rabbitmq_server-3.9.3/sbin ########################################
5、使配置生效:
source /etc/profile
6、切换到解压后的目录
[root@node1 local]# cd rabbitmq_server-3.9.3/ [root@node1 rabbitmq_server-3.9.3]# ls escript LICENSE-APACHE2-excanvas LICENSE-erlcloud LICENSE-MIT-Erlware-Commons LICENSE-MIT-Sammy LICENSE-rabbitmq_aws etc LICENSE-APACHE2-ExplorerCanvas LICENSE-httpc_aws LICENSE-MIT-Flot LICENSE-MIT-Sammy060 plugins INSTALL LICENSE-APL2-Stomp-Websocket LICENSE-ISC-cowboy LICENSE-MIT-jQuery LICENSE-MPL sbin LICENSE LICENSE-BSD-base64js LICENSE-MIT-EJS LICENSE-MIT-jQuery164 LICENSE-MPL2 share LICENSE-APACHE2 LICENSE-BSD-recon LICENSE-MIT-EJS10 LICENSE-MIT-Mochi LICENSE-MPL-RabbitMQ [root@node1 rabbitmq_server-3.9.3]# cd sbin/ [root@node1 sbin]# ls rabbitmqctl rabbitmq-defaults rabbitmq-diagnostics rabbitmq-env rabbitmq-plugins rabbitmq-queues rabbitmq-server rabbitmq-streams rabbitmq-upgrade [root@node1 sbin]#
7、启动web管理插件
[root@node1 sbin]# rabbitmq-plugins enable rabbitmq_management Enabling plugins on node rabbit@localhost: rabbitmq_management The following plugins have been configured: rabbitmq_management rabbitmq_management_agent rabbitmq_web_dispatch Applying plugin configuration to rabbit@localhost... The following plugins have been enabled: rabbitmq_management rabbitmq_management_agent rabbitmq_web_dispatch started 3 plugins.
8、后台启动rabbitmq服务
rabbitmq-server -detached
9、启用了rabbitmq的管理插件,会有一个web管理界面,默认监听端口15672,将此端口在防火墙上打开,则可以访问web界面:

使用默认的用户 guest / guest (此也为管理员用户)登陆,会发现无法登陆,
报错:User can only log in via localhost。
那是因为默认是限制了guest用户只能在本机登陆,也就是只能登陆localhost:15672。
可以通过修改配置文件rabbitmq.conf,取消这个限制: loopback_users这个项就是控制访问的,
如果只是取消guest用户的话,只需要loopback_users.guest = false 即可。或者添加远程用户
10、添加远程用户
# 添加用户 rabbitmqctl add_user 用户名 密码 # 设置用户角色,分配操作权限 rabbitmqctl set_user_tags 用户名 角色 # 为用户添加资源权限(授予访问虚拟机根节点的所有权限) rabbitmqctl set_permissions -p / 用户名 ".*" ".*" ".*"
角色有四种:
- administrator:可以登录控制台、查看所有信息、并对rabbitmq进行管理
- monToring:监控者;登录控制台,查看所有信息
- policymaker:策略制定者;登录控制台指定策略
- managment:普通管理员;登录控制
这里创建用户rabbitadmin,密码rabbitadmin,设置administrator角色,赋予所有权限
[root@node1 sbin]# rabbitmqctl add_user rabbitadmin rabbitadmin Adding user "rabbitadmin" ... Done. Don't forget to grant the user permissions to some virtual hosts! See 'rabbitmqctl help set_permissions' to learn more. [root@node1 sbin]# rabbitmqctl set_user_tags rabbitadmin administrator Setting tags for user "rabbitadmin" to [administrator] ... [root@node1 sbin]# rabbitmqctl set_permissions -p / rabbitadmin ".*" ".*" ".*" Setting permissions for user "rabbitadmin" in vhost "/" ... [root@node1 sbin]#
11、登录,其他两台虚拟机也是如上配置

同步cookie:
1、如何查看cookie
[root@node1 rabbitmq]# pwd /usr/local/rabbitmq_server-3.9.3/var/log/rabbitmq [root@node1 rabbitmq]# more rabbit\@node1.log ****** 2021-08-14 21:11:06.883853-04:00 [info] <0.222.0> node : rabbit@node1 2021-08-14 21:11:06.883853-04:00 [info] <0.222.0> home dir : /root 2021-08-14 21:11:06.883853-04:00 [info] <0.222.0> config file(s) : (none) 2021-08-14 21:11:06.883853-04:00 [info] <0.222.0> cookie hash : baCpCWaCXrmkyZweJiNbVw== 2021-08-14 21:11:06.883853-04:00 [info] <0.222.0> log(s) : /usr/local/rabbitmq_server-3.9.3/var/log/rabbitmq/rabbit@node1.log 2021-08-14 21:11:06.883853-04:00 [info] <0.222.0> : /usr/local/rabbitmq_server-3.9.3/var/log/rabbitmq/rabbit@node1_upgrade.log 2021-08-14 21:11:06.883853-04:00 [info] <0.222.0> : <stdout> 2021-08-14 21:11:06.883853-04:00 [info] <0.222.0> database dir : /usr/local/rabbitmq_server-3.9.3/var/lib/rabbitmq/mnesia/rabbit@node1
我的${home}目录是/root,切换到root目录下,该文件是一个隐藏文件,需要使用 ls -al 命令查看
[root@node1 ~]# pwd /root [root@node1 ~]# ls -la total 52 dr-xr-x---. 2 root root 4096 Aug 14 21:10 . dr-xr-xr-x. 18 root root 4096 Nov 12 2020 .. -rw-------. 1 root root 993 Nov 7 2020 anaconda-ks.cfg -rw-------. 1 root root 14288 Aug 14 23:07 .bash_history -rw-r--r--. 1 root root 18 Dec 28 2013 .bash_logout -rw-r--r--. 1 root root 176 Dec 28 2013 .bash_profile -rw-r--r--. 1 root root 176 Dec 28 2013 .bashrc -rw-r--r--. 1 root root 100 Dec 28 2013 .cshrc -r--------. 1 root root 20 Aug 14 00:00 .erlang.cookie -rw-r--r--. 1 root root 129 Dec 28 2013 .tcshrc [root@node1 ~]#
2、同步(拷贝.cookie时,各节点都必须停止MQ服务,在node1上执行远程操作命令)
scp /root/.erlang.cookie root@node2:/root/ scp /root/.erlang.cookie root@node3:/root/
集群搭建:
1、启动RabbitMQ服务,顺带启动Erlang虚拟机和RabbitMQ应用服务,在node1、node2、node3执行命令
rabbitmq-server -detached
2、RabbitMQ 集群的搭建需要选择其中任意一个节点为基准,将其它节点逐步加入。这里我们以 node1 为基准节点,将 node2 和 node3 加入集群。在 node2 和node3 上执行以下命令:
# 1.停止服务 rabbitmqctl stop_app # rabbitmqctl stop会将Erlang虚拟机关闭,rabbitmqctl stop_app只关闭RabbitMQ服务 # 2.重置状态 rabbitmqctl reset # 3.节点加入, 在一个node加入cluster之前,必须先停止该node的rabbitmq应用,即先执行stop_app # node2加入node1, node3加入node2 rabbitmqctl join_cluster rabbit@node1 # 4.启动服务 rabbitmqctl start_app
join_cluster 命令有一个可选的参数 --ram ,该参数代表新加入的节点是内存节点,默认是磁盘节点。
如果是内存节点,则所有的队列、交换器、绑定关系、用户、访问权限和 vhost 的元数据都将存储在内存中,
如果是磁盘节点,则存储在磁盘中。
内存节点可以有更高的性能,但其重启后所有配置信息都会丢失,
因此RabbitMQ 要求在集群中至少有一个磁盘节点,其他节点可以是内存节点。
当内存节点离开集群时,它可以将变更通知到至少一个磁盘节点;
然后在其重启时,再连接到磁盘节点上获取元数据信息。
除非是将 RabbitMQ 用于 RPC 这种需要超低延迟的场景,
否则在大多数情况下,RabbitMQ 的性能都是够用的,可以采用默认的磁盘节点的形式。
另外,如果节点以磁盘节点的形式加入,则需要先使用 reset 命令进行重置,然后才能加入现有群集,重置节点会删除该节点上存在的所有的历史资源和数据。
采用内存节点的形式加入时可以略过 reset 这一步,因为内存上的数据本身就不是持久化的
3、查看集群状态
此时可以在任意节点上使用 rabbitmqctl cluster_status 命令查看集群状态,输出如下:
[root@node1 ~]# rabbitmqctl cluster_status Cluster status of node rabbit@node1 ... Basics Cluster name: rabbit@node1 Disk Nodes rabbit@node1 rabbit@node2 rabbit@node3 Running Nodes rabbit@node1 rabbit@node2 rabbit@node3 Versions rabbit@node1: RabbitMQ 3.9.3 on Erlang 24.0 rabbit@node2: RabbitMQ 3.9.3 on Erlang 24.0 rabbit@node3: RabbitMQ 3.9.3 on Erlang 24.0 Maintenance status Node: rabbit@node1, status: not under maintenance Node: rabbit@node2, status: not under maintenance Node: rabbit@node3, status: not under maintenance Alarms Free disk space alarm on node rabbit@node3 Network Partitions (none) Listeners Node: rabbit@node1, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication Node: rabbit@node1, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0 Node: rabbit@node1, interface: [::], port: 15672, protocol: http, purpose: HTTP API Node: rabbit@node2, interface: [::], port: 15672, protocol: http, purpose: HTTP API Node: rabbit@node2, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication Node: rabbit@node2, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0 Node: rabbit@node3, interface: [::], port: 15672, protocol: http, purpose: HTTP API Node: rabbit@node3, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication Node: rabbit@node3, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0 Feature flags Flag: drop_unroutable_metric, state: enabled Flag: empty_basic_get_metric, state: enabled Flag: implicit_default_bindings, state: enabled Flag: maintenance_mode_status, state: enabled Flag: quorum_queue, state: enabled Flag: stream_queue, state: enabled Flag: user_limits, state: enabled Flag: virtual_host_metadata, state: enabled [root@node1 ~]#
4、UI 界面查看

镜像队列:
1、镜像的配置是通过 policy 策略的方式,以命令的方式设置 或 UI界面设置

2、参数说明:
- Name:policy的名称
- Pattern: queue的匹配模式(正则表达式)
- priority:可选参数,policy的优先级
- Definition:镜像定义,包括三个部分ha-mode、ha-params、ha-sync-mode
- ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes
- all:表示在集群中所有的节点上进行镜像
- exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定
- nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定
- ha-params:ha-mode模式需要用到的参数
- ha-sync-mode:进行队列中消息的同步方式,有效值为automatic(自动)和manual(手动)
3、对队列名称以“queue_”开头的所有队列进行镜像,并在集群的两个节点上完成进行,policy的设置命令为:
[root@node1 ~]# rabbitmqctl set_policy ha-queue-two '^queue_' '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
Setting policy "ha-queue-two" for pattern "^queue_" to "{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}" with priority "0" for vhost "/" ...
[root@node1 ~]#
4、在任意节点(我在node1节点)创建queue_testQueue队列,并查看镜像状态

上图Node中的+1表示备份,下图中的Mirrors就是备份的节点,若node1宕机了node3就会代替node1继续提供服务

测试:首先关闭node1节点

然后查看node3节点上的镜像状态,发现在node2节点也进行了备份,以此说明:就算整个集群只剩下一台机器了,依然能消费队列里面的消息

5、复制系数
若ha-mode 的值为 all ,代表消息会被同步到所有节点的相同队列中,如果你的集群有很多节点,那么此时复制的性能开销就比较大,此时需要选择合适的复制系数。
通常可以遵循过半写原则,即对于一个节点数为 n 的集群,只需要同步到 n/2+1 个节点上即可。
6、集群的关闭与重启
没有一个直接的命令可以关闭整个集群,需要逐一进行关闭。但是需要保证在重启时,最后关闭的节点最先被启动。如果第一个启动的不是最后关闭的节点,那么这个节点会等待最后关闭的那个节点启动,默认进行 10 次连接尝试,超时时间为 30 秒,如果依然没有等到,则该节点启动失败。
这带来的一个问题是,假设在一个三节点的集群当中,关闭的顺序为 node1,node2,node3,如果 node1 因为故障暂时没法恢复,此时 node2 和 node3 就无法启动。想要解决这个问题,可以先将 node1 节点进行剔除,命令如下:
rabbitmqctl forget_cluster_node rabbit@node1 --offline
此时需要加上 -offline 参数,它允许节点在自身没有启动的情况下将其他节点剔除。
7、解除集群
重置当前节点:
# 1.停止服务 rabbitmqctl stop_app # 2.重置集群状态 rabbitmqctl reset # 3.重启服务 rabbitmqctl start_app
重新加入集群:
# 1.停止服务 rabbitmqctl stop_app # 2.重置状态 rabbitmqctl reset # 3.节点加入 rabbitmqctl join_cluster rabbit@node1 # 4.重启服务 rabbitmqctl start_app
完成后重新检查 RabbitMQ 集群状态:
rabbitmqctl cluster_status
除了在当前节点重置集群外,还可在集群其他正常节点将节点踢出集群
rabbitmqctl forget_cluster_node rabbit@node3
8、变更节点类型
我们可以将节点的类型从RAM更改为Disk,反之亦然。假设我们想要反转rabbit@node2和rabbit@node1的类型,将前者从RAM节点转换为磁盘节点,而后者从磁盘节点转换为RAM节点。为此,我们可以使用change_cluster_node_type命令。必须首先停止节点。
# 1.停止服务 rabbitmqctl stop_app # 2.变更类型 ram disc rabbitmqctl change_cluster_node_type disc # 3.重启服务 rabbitmqctl start_app
9、清除 RabbitMQ 节点配置
# 如果遇到不能正常退出直接kill进程 systemctl stop rabbitmq-server # 查看进程 ps aux|grep rabbitmq # 清除节点rabbitmq配置 rm -rf /var/lib/rabbitmq/mnesia
到此这篇关于深入浅析RabbitMQ镜像集群原理的文章就介绍到这了,更多相关RabbitMQ镜像集群内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
docker部署rabbitmq集群的实现方法
拉取rabbitmq management镜像 docker pull rabbitmq:3.7-rc-management 若不使用Rabbitmq的management功能,可以拉取镜像:rabbitmq:3.7-rc 参考: https://hub.docker.com/_/rabbitmq/ 创建网络 创建rabbitmq私有网络 # docker network create rabbitmqnet # docker network ls NETWORK ID NAME DRIVER
-

Docker集群的创建与管理实例详解
本文详细讲述了Docker集群的创建与管理.分享给大家供大家参考,具体如下: 在<Docker简单安装与应用入门教程>中编写一个应用程序,并将其转化为服务,在<Docker分布式应用教程>中,使应用程序在生产过程中扩展5倍,并定义应该如何运行.现在将此应用程序部署到集群上,并在多台机器上运行它,通过将多台机器连接到Dockerized集群上,使多容器.多机器应用成为可能. Swarm(集群)是运行Docker并加入到一个集群中的一组机器,在这种情况下,您将继续运行以往的Docker
-
一篇文章带你从入门到精通:RabbitMQ
目录 1. 浅浅道来 1.1 什么是中间件? 1.1.1 分布式的概念(补充) 1.2 什么是消息中间件/消息队列(MQ) 1.2.1 消息队列应用场景 1.3 什么是 RabbitMQ 2. 下载与安装 2.1 手动安装 2.1.1 下载安装过程 2.1.2 配置 Web 界面管理 2.1.3 简单介绍 Web 界面管理 2.2 Docker 安装 2.2.1 配置 yum 2.2.2 安装 docker 2.2.3 安装 RabbitMQ (任选其一) 3. RabbitMQ 协议和模型 3
-
深入浅析RabbitMQ镜像集群原理
目录 集群架构 1)首先一个基本的 RabbitMQ 集群不是高可用的 2)其次 RabbitMQ 集群本身并没有提供负载均衡的功能 3)接着假设我们只采用一台 HAProxy 4)最后,任何想要连接到 RabbitMQ 集群的客户端 搭建集群准备: 1.准备3个虚拟机 2.设置node1.node2.node3的hosts 安装Erlang: 安装RabbitMQ: 同步cookie: 集群搭建: 集群架构 RabbitMQ 集群是一个或多个节点的逻辑分组,集群中的每个节点都是对等的 每个节点
-
Docker搭建RabbitMq的普通集群和镜像集群的详细操作
目录 一.搭建RabbitMq的运行环境 1.通过search查询rabbitmq镜像 2.通过pull拉取rabbitmq的官方最新镜像 3.创建容器 4.启动管理页面 5.设置erlang cookie 二.普通模式 三.镜像模式 普通集群:多个节点组成的普通集群,消息随机发送到其中一个节点的队列上,其他节点仅保留元数据,各个节点仅有相同的元数据,即队列结构.交换器结构.vhost等.消费者消费消息时,会从各个节点拉取消息,如果保存消息的节点故障,则无法消费消息,如果做了消息持久化,那么得等
-
Quartz集群原理以及配置应用的方法详解
1.Quartz任务调度的基本实现原理 Quartz是OpenSymphony开源组织在任务调度领域的一个开源项目,完全基于Java实现.作为一个优秀的开源调度框架,Quartz具有以下特点: (1)强大的调度功能,例如支持丰富多样的调度方法,可以满足各种常规及特殊需求: (2)灵活的应用方式,例如支持任务和调度的多种组合方式,支持调度数据的多种存储方式: (3)分布式和集群能力,Terracotta收购后在原来功能基础上作了进一步提升.本文将对该部分相加阐述. 1.1 Quartz 核心元素
-
Centos7.3 RabbitMQ分布式集群搭建示例
本文介绍了Centos7.3 RabbitMQ分布式集群搭建示例,分享给大家,具体如下: 注意事项 centos 7.x 关闭firewall 三台机器: 172.17.250.97 rabbiMQ01 172.17.250.98 rabbiMQ03 172.17.250.99 rabbiMQ02 配置 hosts 172.17.250.97 fz-rabbitMQ01 172.17.250.99 fz-rabbitMQ02 172.17.250.98 fz-rabbitMQ03 $ syste
-
Nacos配置中心集群原理及源码分析
目录 Nacos集群工作原理 配置变更同步入口 AsyncNotifyService AsyncTask 目标节点接收请求 NacosDelayTaskExecuteEngine ProcessRunnable processTasks DumpProcessor.process Nacos作为配置中心,必然需要保证服务节点的高可用性,那么Nacos是如何实现集群的呢? 下面这个图,表示Nacos集群的部署图. Nacos集群工作原理 Nacos作为配置中心的集群结构中,是一种无中心化节点的设计
-
浅析Redis 切片集群的数据倾斜问题
目录 Redis 中如何应对数据倾斜 什么是数据倾斜 数据量倾斜 bigkey导致倾斜 Slot分配不均衡导致倾斜 Hash Tag导致倾斜 数据访问倾斜 总结 参考 Redis 中如何应对数据倾斜 什么是数据倾斜 如果 Redis 中的部署,采用的是切片集群,数据是会按照一定的规则分散到不同的实例中保存,比如,使用 Redis Cluster 或 Codis. 数据倾斜会有下面两种情况: 1.数据量倾斜:在某些情况下,实例上的数据分布不均衡,某个实例上的数据特别多. 2.数据访问倾斜:虽然每个
-
阿里云服务器部署RabbitMQ集群的详细教程
目录 一.为什么要搭建RabbitMQ集群? 二.RabbitMQ集群的三种模式 ️单机模式 普通集群模式 镜像队列 三.阿里云服务器下Docker搭建RabbitMQ集群 ️Docker安装RabbitMQ集群 测试RabbitMQ集群 四.SpringBoot整合RabbitMQ集群 创建Maven聚合工程 引入共有依赖 创建生产者 创建消费者 ️核心源码 五.测试消息的生产与消费 小结 一.为什么要搭建RabbitMQ集群? 未部署集群的缺点 如果RabbitMQ集群只有一个broker节
-
深入浅析Redis 集群伸缩原理
Redis 节点分别维护自己负责的槽和对应的数据.伸缩原理:Redis 槽和对应数据在不同节点之间移动 环境:CentOS7 搭建 Redis 集群 一.集群扩容 1. 手动扩容 (1) 准备节点 9007,并加入集群 192.168.11.40:9001> cluster meet 192.168.11.40 9007 [注意]若 cluster meet 加入已存在于其它集群的节点,会导致集群合并,造成数据错乱!.建议使用 redis-cli 的 add-node: # 若节点已加入其它集群
-
docker搭建rabbitmq集群环境的方法
本文主要讲述如何用docker搭建rabbitmq的集群.分享给大家,希望此文章对各位有所帮助. 下载镜像 采用bijukunjummen该镜像. git clone https://github.com/bijukunjummen/docker-rabbitmq-cluster.git 运行 启动集群 cd docker-rabbitmq-cluster/cluster docker-compose up -d ...... Status: Downloaded newer image for