教你如何利用Python批量翻译英文Word文档并保留格式
一、需求描述
手上有大量外文文档(本案例以5份为例,分别命名为 test1.docx test2.docx 以此类推),其中一份如下:

基本需求:「批量将这些文档的内容全部翻译成中文,并转存到新的文件中」,效果如下:

高级需求:基本需求满足的同时,要求 「保留原文档的格式」,效果如下:

二、逻辑梳理
2.1 翻译 API
本需求的核心是翻译,策略是利用网络的翻译 API,这里推荐百度翻译开放平台,不考虑并发数的话可以用标准版,免费使用不限字符量!
“
百度翻译开放平台:
http://api.fanyi.baidu.com/api/trans/product/index”
在使用百度的通用翻译 API 之前需要完成以下工作:
1.使用百度账号登录百度翻译开放平台(http://api.fanyi.baidu.com);
2.注册成为开发者,获得APPID;
3.进行开发者认证(如仅需标准版可跳过);
4.开通通用翻译API服务:开通链接
5.参考技术文档和Demo编写代码

完成后在个人页面在即可看到 ID 和密钥,这个很重要!下面给出整理好的通用翻译 API 的 demo,已经对输出做简单修改,代码拿走就能用!


可以看到,测试内容准确的被翻译出来,注意如果需要多次访问 API,免费版有并发数和时间限制,可以用 time 模块睡眠一秒
2.2 格式修改
高级需求的难点就是保留格式,简单来说原文档的页面格式和段落格式是什么,翻译后对应的部分就是什么。
基于上述的逻辑关系,只需要获取原文档的对应内容再赋值给新翻译的文档即可。(暂时只能满足页面设置和段落设置的统一,针对一段中特定词语的格式修改,保证精确性需要基于自然语言处理NLP,本文暂不涉及)
2.2.1 页面样式
页面样式只要包括边距、方向、高度、宽度等等,从原文档中可以看到,采取的是窄边距。但我们无需知道窄边距四个方向应该如何设置,只需要在代码中呈现新旧文档的变量传递即可,具体如下

2.2.2 段落样式
段落样式包括对齐、缩进、间距等等,原文档中采取了段后缩进,标题是居中对齐。这些设置在变量传递中能够很好完成。如果原文档中没有设置的变量值为 None

2.2.3 文字块样式修改
对于字号、加粗、斜体、颜色等样式调整,采取的策略是建立空列表,遍历原文档每一段每一个文字块,获取相应属性并放到各自的列表中,对同一段而言,其包含的文字块属性最多的选项赋值给翻译后文档的对应段落(如同一段全部或大部分的文字是加粗,则翻译后对应段落所有文字块均设置为加粗) 对NLP感兴趣的读者可自行尝试如何高度还原英文文档中某些特定词语的样式修改,并在翻译后的文档中体现出来
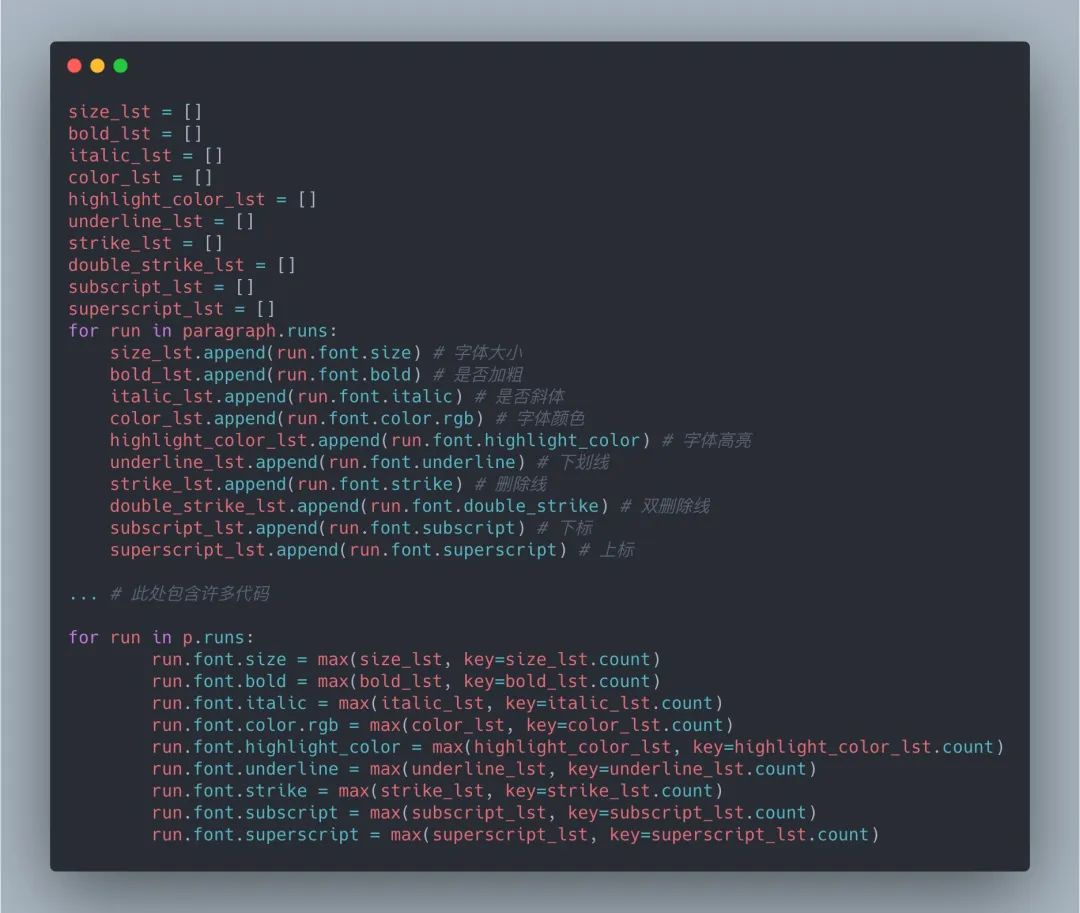
上面的代码不包含对字体的设置,因为没必要把英文的字体传递给中文文档。对中文字体的设置之前的文章有提到过,比较复杂,直接见代码:
from docx.oxml.ns import qn
run.font.name = '微软雅黑'
r = run._element.rPr.rFonts
r.set(qn('w:eastAsia'), '微软雅黑')
2.3 整体实现步骤
现在每个部分操作均以完成,考虑到本例中有多个文档均需要翻译,故全部逻辑如下:
1.利用 glob 模块批处理框架可获取某个文件的绝对路径
2.由 python-docx 完成 Word 文件实例化后对段落进行解析
3.解析出的段落文本交给百度通用翻译 API,解析返回的 Json 格式结果(上面的修改 demo 中已经完成了这一步)并重新写入新的文件
4.同个文件全部解析、翻译并写入新文件后保存文件
三、代码实现
导入需要的模块,除翻译 demo 中需要的库外还需要 glob 库批量获取文件、python-docx 读取文件、time 模块控制访问并发。为什么要 os 模块见下文:
import requests import random import json from hashlib import md5 import time from docx import Document import glob import os
对原 demo 的部分内容进行保留,涉及到 query 参数的代码需要移动到后面的循环中。保留的部分:

效果如下

获取到段落文本后,可以将段落文本赋值给 query 参数,调用 API demo 的后续代码。输出结果的同时用 add_paragraph 将结果写入新文档

最后保存成新文件,期望命名为 原文件名_translated 的形式,可用 os.path.basename 方法获取并经字符串拼接达到目的:
wordfile_new.save(path + r'\\' + os.path.basename(file)[:-5] + '_translated.docx')

单个文件操作完成后将读取和创建文件的代码块放到批处理框架内:

完成了上面的内容后,基本需求就完成了。根据我们梳理的对样式的修改知识,再把样式调整的代码加进来就行了,最终完整代码如下:

代码运行完毕后得到五个新的翻译后文件

翻译效果如下,可以看到英文被翻译成中文,并且样式大部分保留!

至此,所有文档都被成功翻译,当然这是机器翻译的,具体应用时还需要对关键部分进一步人工调整,不过整体来说还是一次成功的Python办公自动化尝试!
相关推荐
-
十个Python自动化常用操作,即拿即用
一.遍历文件夹 代码如下,大家可以根据自己的路径进行修改 import os for dirpath, dirnames, filenames in os.walk(r'C:\\Program Files (x86)'): print(f'打开文件夹{dirpath}') # 当前文件夹路径 if dirnames: print(dirnames) # 包含文件夹名称[列表形式] if filenames: print(fil
-

python使用pytest接口自动化测试的使用
简单的设计思路 利用pytest对一个接口进行各种场景测试并且断言验证 配置文件独立开来(conf文件),实现不同环境下只需要改环境配置即可 测试的场景读取excle的测试用例,可支持全量执行或者自定义哪条用例执行(用例内带加密变量): 接口入参还包含了加密的逻辑,所以需加一层加密处理 用例的样例: 应用的库包含: import pytest import time, json import base64, hmac import hashlib, uuid, re import request
-
python实现百度文库自动化爬取
项目介绍 可以下载doc,ppt,pdf.对于doc文档可以下载,doc中的表格无法下载,图片格式的文档也可以下载.ppt和pdf是先下载图片再放到ppt中.只要是可以预览的都可以下载. 已有功能 将可以预览的word文档下载为word文档,如果文档是扫描件,同样支持. 将可以预览的ppt和pdf下载为不可编辑的ppt,因为网页上只有图片,所以理论上无法下载可编辑的版本. 环境安装 pip install requests pip install my_fake_useragent pip in
-
Python 实现的 Google 批量翻译功能
首先声明,没有什么不良动机,因为经常会用 translate.google.cn,就想着用 Python 模拟网页提交实现文档的批量翻译.据说有 API,可是要收费. 生成 Token Google 为防爬虫而生成 token 的代码是 Javascript 的,且是根据网站的 TKK 值和提交的文本动态生成.更新规律未知,只好定时去取一下了. 网上能找到的 Python 代码大部分是去调用 PyExecJS 库,先不说执行效率的高低(大概是差一个数量级),首先是舍近求远,不纯粹,本人不喜欢.
-
如何用 Python 子进程关闭 Excel 自动化中的弹窗
利用Python进行Excel自动化操作的过程中,尤其是涉及VBA时,可能遇到消息框/弹窗(MsgBox).此时需要人为响应,否则代码卡死直至超时 [^1] [^2].根本的解决方法是VBA代码中不要出现类似弹窗,但有时我们无权修改被操作的Excel文件,例如这是我们进行自动化测试的对象.所以本文记录从代码角度解决此类问题的方法. 假想场景 使用xlwings(或者其他自动化库)打开Excel文件test.xlsm,读取Sheet1!A1单元格内容.很简单的一个操作: import xlwing
-
python调用有道智云API实现文件批量翻译
最近工作过程中,需要对一批文件进行汉译英的翻译,对单个文档手工复制.粘贴的翻译方式过于繁琐,考虑到工作的重复性和本人追求提高效率.少动手(懒),想通过调用已有的接口的方法,自己实现一个批量翻译工具,一劳永逸.在网上找了几款翻译API,通过对比翻译的结果和学习成本,选择了有道智云的服务,自己开发了一个批量翻译的小软件.详细记录一下使用和开发过程,后面的小伙伴们有相关需求,可以参考. 批量文档翻译工具的使用 我这里开发批量文档翻译工具使用python作为开发工具,功能如下: 1)通过文件夹
-
python+requests+pytest接口自动化的实现示例
1.发送get请求 #导包 import requests #定义一个url url = "http://xxxxxxx" #传递参数 payload="{\"head\":{\"accessToken\":\"\",\"lastnotice\":0,\"msgid\":\"\"},\"body\":{\"user_name\&
-
使用Python自动化Microsoft Excel和Word的操作方法
将Excel与Word集成,无缝生成自动报告 毫无疑问,微软的Excel和Word是公司和非公司领域使用最广泛的两款软件.它们实际上是"工作"的同义词.通常情况下,每一周我们都会将两者结合起来,并以某种方式发挥它们的优点.虽然一般的日常用途不会要求自动化,但有时自动化可能是必需的.也就是说,当您有大量的图表.图形.表格和报告要生成时,如果您选择手动方式,它可能会成为一项极其繁琐的工作.其实没必要这样.实际上,有一种方法可以在Python中创建一个管道,您可以将两者无缝集成,在Excel
-
python自动化之如何利用allure生成测试报告
Allure测试报告框架帮助你轻松实现"高大上"报告展示.本文通过示例演示如何从0到1集成Allure测试框架.重点展示了如何将Allure集成到已有的自动化测试工程中.以及如何实现报表的优化展示.Allure非常强大,支持多种语言多种测试框架,无论是Java/Python还是Junit/TestNG,其他语言或者框架实现的流程和本文一致,具体配置参照各语言框架规范 安装 安装allure Windows用户: scoop install allure (需要先下载并安装Scoo
-
教你怎么用Python处理excel实现自动化办公
一.介绍 实现的是把某个文件夹下的所有文件名提取出来,放入一个列表,在与excel中的某列进行对比,如果一致的话,对另一列进行操作,比如我们在统计人员活动情况的时候,对参加的人需要进行记录. 二.步骤 代统计名单 比如下面这个目录是参与活动的人员名单,每个文件夹为每个人参与活动的相关资料,有些目录是很多人一起参与一个活动,这个时候我要把文件遍历,把名字输入到一个列表中. 相关代码如下 # 保存指定目录下文件名到列表 def Save_name(dirPath): filePath = dirPa
-
Python 制作自动化翻译工具
妈妈再也不用担心我的英语了. 一个可能你似曾相识的场景 阅读内容包含大量英文的 PPT.Word.Excel 或者记事本时,由于英语不熟悉,为了流利地阅读,需要打开浏览器进入谷歌翻译的主界面,然后把英文复制到谷歌翻译的输入框中,最后又把翻译结果复制回 PPT.Word 和 Excel. 要是一个两个单词还好,要是发现有 100 个单词不认识,就必须复制粘贴 200 次,如此机械性重复性的工作,应该交给程序来做,这就是我设计下面这个自动化翻译工具的初衷. 提升办公效率的法宝 如上图,运行程序并保持