Python进阶之高级用法详细总结
一、Lambda表达式
Lambda表达式又被称之为匿名函数
格式
lambda 参数列表:函数体
def add(x,y): return x+y print(add(3,4)) #上面的函数可以写成Lambda函数 add_lambda=lambda x,y:x+y add_lambda(3,4)
二、map函数
函数就是有输入和输出,map的输入和输出对应关系如下图所示:

就是要把一个可迭代的对象按某个规则映射到新的对象上。
因此map函数要有两个参数,一个是映射规则,一个是可迭代对象。
list1=[1,2,3,4,5] r=map(lambda x:x+x,list) print(list1(r))
结果:[2,4,6,8,10]
m1=map(lambda x,y:x*x+y,[1,2,3,4,5],[1,2,3,4,5]) print(list(ml))
结果:[2,6,12,20,30]
三、filter函数
filter的输入和输出对应关系如下图所示:

def is_not_none(s): return s and len(s.strip())>0 list2=['','','hello','xxxx', None,'ai'] result=filter(is_not_none, list2) print(list(result))
结果:[‘hello',‘xxxx',‘ai']
四、reduce函数

from functools import reduce f=lambda x,y:x+y x=reduce(f,[1,2,3,4,5]) print(r)
结果:15=1+2+3+4+5
相当于每一次计算都是基于前一次计算的结果:
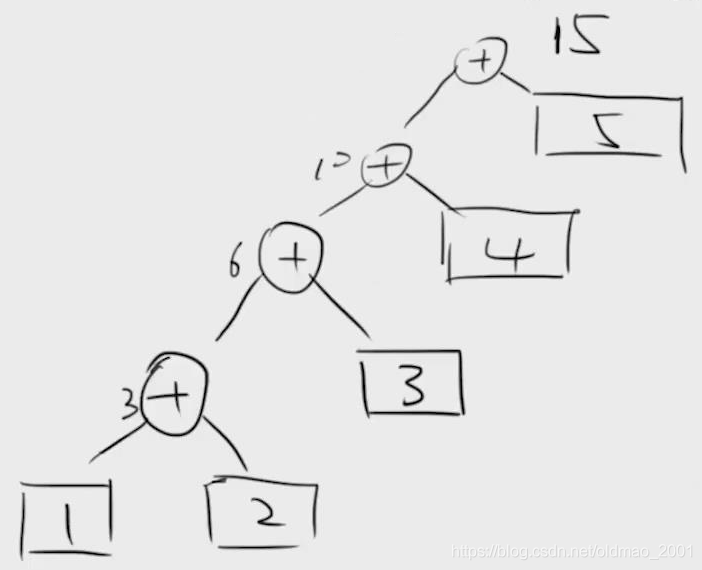
还可以为reduce计算添加初始值:
from functools import reduce f=lambda x,y:x+y x=reduce(f,[1,2,3,4,5],10) print(r)
结果:25=10+1+2+3+4+5
五、三大推导式
5.1 列表推导式
list1=[1,2,3,4,5,6] f=map(lambda x:x+x,list1) print(list(f)) list2=[i+i for i in list1] print(list2) list3=[i**3 for i in list1] print(list3) #筛选列表的例子 list4=[i*4 for i in list1 if i>3] print(list4) #结果 [2,4,6,8,10,12] [2,4,6,8,10,12] [1,8,27,64,125,216] [16,25,36]
5.2 集合推导式
直接把上面代码copy下来,然后把列表改成集合
list1={1,2,3,4,5,6}
list2={i+i for i in list1}
print(list2)
list3={i**3 for i in list1}
print(list3)
#筛选列表的例子
list4={i*4 for i in list1 if i>3}
print(list4)
#结果
{2, 4, 6, 8, 10, 12}
{64, 1, 8, 216, 27, 125}#这里是乱序的
{16, 24, 20}
5.3 字典推导式
s={
"zhangsan":20,
"lisi":15,
"wangwu":31
}
#拿出所有的key,并变成列表
s_key=[ key for key, value in s.items()]
print(s_key)
#结果
['zhangsan','lisi','wangwu']
# 交换key和value位置,注意冒号的位置
s1={ value: key for key, value in s.items()}
print(s1)
#结果
{20:'zhangsan',15:'1isi',31:'wangwu'}
s2={ key: value for key, value in s.items() if key=="1isi"}
print(s2)
#结果
{"lisi":15}
六、闭包
闭包:一个返回值是函数的函数
import time def runtime(): def now_time(): print(time.time()) return now_time #返回值是函数名字 f=runtime()#f就被赋值为一个函数now_time()了 f()#运行f相当于运行now_time()
再来看一个带参数的例子:
假设有一个csv文件,内容有三行,具体如下:
a,b,c,d,e
1,2,3,4,5
6,7,8,9,10
def make_filter(keep):# keep=8
def the_filter(file_name):
file=open(file name)#打开文件
lines=file.readlines()#按行读取文件
file.close()#关闭文件
filter_doc=[i for i in lines if keep in i]#过滤文件内容
return filter_doc
return the_filter
filter1=make_filter("8")#这一行调用了make_filter函数,且把8做为参数传给了keep,接受了the_filter函数作为返回值
#这里的filter1等于函数the_filter
filter_result=filter1("data.csv")#把文件名data.csv作为参数传给了函数the_filter
print(filter_result)
#结果
['6,7,8,9,10']
七、装饰器、语法糖、注解
# 这是获取函数开始运行时间的函数
import time
def runtime(func):
def get_time():
print(time.time())
func()# run被调用
return get_time
@runtime
def run()
print('student run')
#运行
run()
#结果
当前时间
student run
由于有装饰器@runtime的存在,会把run这个函数作为参数丢到runtime(func)里面去,如果调整打印时间代码的位置会有不同结果:
# 这是获取函数结束运行时间的函数
import time
def runtime(func):
def get_time():
func()# run被调用
print(time.time())
return get_time
@runtime
def run()
print('student run')
#运行
run()
#结果
student run
当前时间
这里还要注意,这里还用到了闭包的概念,在运行run函数的时候,调用的实际上是get_time函数。
对于多个参数的函数如何调用,看下面例子
#有一个参数
import time
def runtime(func):
def get_time(i):
func(i)# run被调用
print(time.time())
return get_time
@runtime
def run(i)
print('student run')
#运行
run(1)
#有两个参数
import time
def runtime(func):
def get_time(i,j):
func(i,j)# run被调用
print(time.time())
return get_time
@runtime
def run(i,j)
print('student run')
#运行
run(1,2)
可以发现,这样写对于函数的多态不是很好,因此可以写为:
#自动适配参数
import time
def runtime(func):
def get_time(*arg):
func(*arg)# run被调用
print(time.time())
return get_time
@runtime
def run(i)
print('student1 run')
@runtime
def run(i,j)
print('student2 run')
#运行
run(1)
run(1,2)
再次进行扩展,更为普适的写法,可以解决传入类似i=4的关键字参数写法:
#自动适配参数
import time
def runtime(func):
def get_time(*arg,**kwarg):
func(*arg,**kwarg)# run被调用
print(time.time())
return get_time
@runtime
def run(i)
print('student1 run')
@runtime
def run(*arg,**kwarg)
print('student2 run')
@runtime
def run()
print('no param run')
#运行
run(1)
run(1,2,j=4)
run()
到此这篇关于Python进阶之高级用法详细总结的文章就介绍到这了,更多相关Python高级用法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

解决python2中unicode()函数在python3中报错的问题
python2中的unicode()函数在python3中会报错: NameError: name 'unicode' is not defined There is no such name in Python 3, no. You are trying to run Python 2 code in Python 3. In Python 3, unicode has been renamed to str. 翻译过来就是:Python 3中没有这样的名字,没有. 您正在尝试在Python
-
python-opencv中的cv2.inRange函数用法说明
本次目标是将一副图像从rgb颜色空间转换到hsv颜色空间,颜色去除白色背景部分 具体就调用了cv2的两个函数,一个是rgb转hsv的函数 具体用法 hsv = cv2.cvtColor(rgb_image, cv2.COLOR_BGR2HSV) 然后利用cv2.inRange函数设阈值,去除背景部分 mask = cv2.inRange(hsv, lower_red, upper_red) #lower20===>0,upper200==>0, 函数很简单,参数有三个 第一个参数:hsv指的是
-
python中的内置函数max()和min()及mas()函数的高级用法
max(iterable, *[, key, default]) max(arg1, arg2, *args[, key]) 函数功能为取传入的多个参数中的最大值,或者传入的可迭代对象元素中的最大值.默认数值型参数,取值大者:字符型参数,取字母表排序靠后者.还可以传入命名参数key,其为一个函数,用来指定取最大值的方法.default命名参数用来指定最大值不存在时返回的默认值. eg a.传入的多个参数的最大值 print(max(1,2,3,4)) 输出 b.1 传入可迭代对象时,取其元素最大
-
python print()函数的end参数和sep参数的用法说明
最近在学习python过程中,对print()打印输出函数进行了进一步学习. python 2.6中,print输出内容需要使用引号. python 3.0中的print 函数修改引号为括号,即print() print()函数打印输出默认换行 i=1 while i<10: print(i) i+=1 print("循环结束") #程序运行结果 1 2 3 4 5 6 7 8 9 循环结束 从语法上讲,python 3.0的函数有一下格式: print([object,-]],
-
python Pool常用函数用法总结
1.说明 apply_async(func[,args[,kwds]):使用非堵塞调用func(并行执行,堵塞方式必须等待上一个过程退出才能执行下一个过程),args是传输给func的参数列表,kwds是传输给func的关键词参数列表. close():关闭Pool,使之不再接受新任务. terminate():无论任务是否完成,都要立即终止. join():主进程堵塞,等待子进程退出,必须在close或terminate之后使用. 2.实例 #coding: utf-8 import mult
-
python 如何用map()函数创建多线程任务
对于多线程的使用,我们经常是用thread来创建,比较繁琐. 在Python中,可以使用map函数简化代码.map可以实现多任务的并发 简单说明map()实现多线程原理: task = ['任务1', '任务2', '任务3', -] map 函数一手包办了序列操作.参数传递和结果保存等一系列的操作,map函数负责将线程分给不同的CPU. 在 Python 中有个两个库包含了 map 函数: multiprocessing 和它鲜为人知的子库 multiprocessing.dummy.dumm
-
Python input()函数用法大全
input()函数获取用户输入数据,实现用户交互 语法格式: 变量 = input("提示信息") input()返回的是字符串,无论输入的是数字还是字符串,默认的输入结束键是回车键 input()函数有一些特殊的用法 用法1:通过if判断或iter()函数的哨兵值用法让input()遇到回车键也能持续输入 txt = '' while True: k = input() if k == 'quit': break txt += k + '\n' print('*****以下是输出内容
-
python处理emoji表情(两个函数解决两者之间的联系)
还记得曾经被"滑稽"刷屏的场景吗? 在这个各种表情包横行的时代,emoji表情还能依然占据一定的地位! 这篇文章将带你了解一下,python与emoji之间的会有怎样的联系 emoji库的官方文档:传送门 一.emoji库的安装 pip install emoji 二.函数的作用 emoji库主要有两个函数: emojize():根据code生成emoji表情 demojize():将emoji表情解码为code code与表情的对照表:传送门 1.emojize() 在应用时,需要将
-
Python3去除头尾指定字符的函数strip()、lstrip()、rstrip()用法详解
Python中有三个去除头尾指定字符.空白符的函数,它们依次为: strip: 用来去除头尾字符.空白符(包括\n.\r.\t.' ',即:换行.回车.制表符.空格) lstrip:用来去除开头字符.空白符(包括\n.\r.\t.' ',即:换行.回车.制表符.空格) rstrip:用来去除结尾字符.空白符(包括\n.\r.\t.' ',即:换行.回车.制表符.空格) 从字面可以看出r=right,l=left,strip.rstrip.lstrip是开发中常用的字符串格式化的方法. 注意:这些
-
详解python函数传参传递dict/list/set等类型的问题
传参时传递可变对象,实际上传的是指向内存地址的指针/引用 这个标题是我的结论,也是我在做项目过程查到的.学过C的都知道,函数传参可以传值,也可以传指针.指针的好处此处不再赘述. 先上代码看看效果: def trans(var): return var source = {1: 1} dist = trans(source) source[2] = 2 print(source) print(dist) 运行结果: {1: 1, 2:2} {1: 1, 2:2} 可以看到改变了source时,di
-
python绘图subplots函数使用模板的示例代码
背景 使用python进行图像可视化,很多情况下都需要subplots将多幅图像绘制在一个figure中.因为使用频率足够高,那么程序员就需要将其"封装",方便复用,所以,这里将笔者常用的subplots用法记录之. 如果有python绘图使用subplots出现标题重叠的解决方法 的问题,可以参考之. 模板 显示中文 plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文 使用subplot(221) 对应的subplots代码: fr
-
Python函数参数中的*与**运算符
问题描述 在阅读某些代码时,经常会看到函数定义/调用时的参数前带有 * 或者 ** 运算符,比较糊涂,今天来探究记录一番. 函数定义时的 * 和 ** 查阅相关资料得知,在参数前面加上* 号 ,意味着参数个数不止一个,而带一个星号(*)参数的函数传入的参数存储为一个元组(tuple),带两个(*)号则是表示字典(dict)! 我们定义3个函数来分别测试一下*和**的功能. 第一个函数func1参数列表中有两个参数,其中参数b前有* 第二个函数func2参数列表中有两个参数,其中参数b前有** 第