简单了解 MySQL 中相关的锁
本文主要是带大家快速了解 InnoDB 中锁相关的知识
基础概念解析和RocketMQ详细的源码解析
http://xiazai.jb51.net/202105/yuanma/RocketMQ_jb51.rar
为什么需要加锁
首先,为什么要加锁?我想我不用多说了,想象接下来的场景你就能 GET 了。
你在商场的卫生间上厕所,此时你一定会做的操作是啥?锁门。如果不锁门,上厕所上着上着,啪一下门就被打开了,可能大概也许似乎貌似有那么一丁点的不太合适。
数据也是一样,在并发的场景下,如果不对数据加锁,会直接破坏数据的一致性,并且如果你的业务涉及到钱,那后果就更严重了。
锁门表情包
锁的分类
在 InnoDB 中,都有哪些锁?其实你应该已经知道了很多了,例如面试中会问你存储引擎 MyISAM 和 InnoDB 的区别,你会说 MyIASM 只有表锁,但是 InnoDB 同时支持行锁和表锁。你可能还会被问到乐观锁和悲观锁的区别是啥。
锁的概念、名词很多,如果你没有对锁构建出一个完整的世界观,那么你理解起来就会比较有阻碍,接下来我们把这些锁给分一下类。
按照锁的粒度
按照锁的粒度进行划分可以分为:
- 表锁
- 行锁
这里就不讨论页锁了,页锁是 BDB(BerkeleyDB) 存储引擎中才有的概念,我们这里主要讨论 InnoDB 存储引擎。
按照锁的思想
按照加锁的思想可以分为:
- 悲观锁
- 乐观锁
这里的悲观、乐观和你平时理解的名词是同一个意思。乐观锁认为大概率不会发生冲突,只在必要的时候加锁。而悲观锁认为大概率会冲突,所以无论是否必要加锁都会执行加锁操作。
按照兼容性
按照兼容性可以把锁划分为:
- 共享锁
- 排他锁
被加上共享锁的资源,能够和其他人进行共享,而如果被加上了排他锁,其他人在拿不到这把锁的情况下是无法进行任何操作的。
按照锁的实现
这里的实现就是 InnoDB 中具体的锁的种类了,分别有:
- 意向锁(Intention Locks)
- 记录锁(Record Locks)
- 间隙锁(Gap Locks)
- 临键锁(Next-Key Locks)
- 插入意向锁(Insert Intention Locks)
- 自增锁(AUTO-INC Locks)
即使按照这种分类来对锁进行了划分,看到了这么多的锁的名词可能仍然会有点懵。比如我SELECT ... FOR UPDATE 的时候到底加的是什么锁?
我们应该透过现象看本质,本质是什么?本质是锁到底加在了什么对象上,而这个很好回答:
- 加在了表上
- 加在了行上
而对于加在行上的锁,其本质又是什么?本质是将锁加在了索引上。
意向锁
在 InnoDB 中支持了不同粒度的锁,行锁和表锁。例如lock tables命令就会持有对应表的排他锁。为了使多种不同粒度的锁更实用,InnoDB 设计了意向锁。
意向锁是一种表级锁,它表明了接下来的事务中,会使用哪种类型的锁,它有以下两种类型:
- 共享意向锁(IS) 表明该事务会打算对表中的记录加共享锁
- 独占意向锁(IX) 则是加排他锁
例如,select ... for share就是加的共享意向锁,而SELECT .. FOR UPDATE则是加的独占意向锁。其规则如下:
- 一个事务如果想要获取某张表中某行的共享锁,它必须先获取该表的共享意向锁,或者独占意向锁。
- 同理,如果想获取排他锁,它必须先获取独占意向锁
下图是这几种锁的组合下相互互斥、兼容的情况
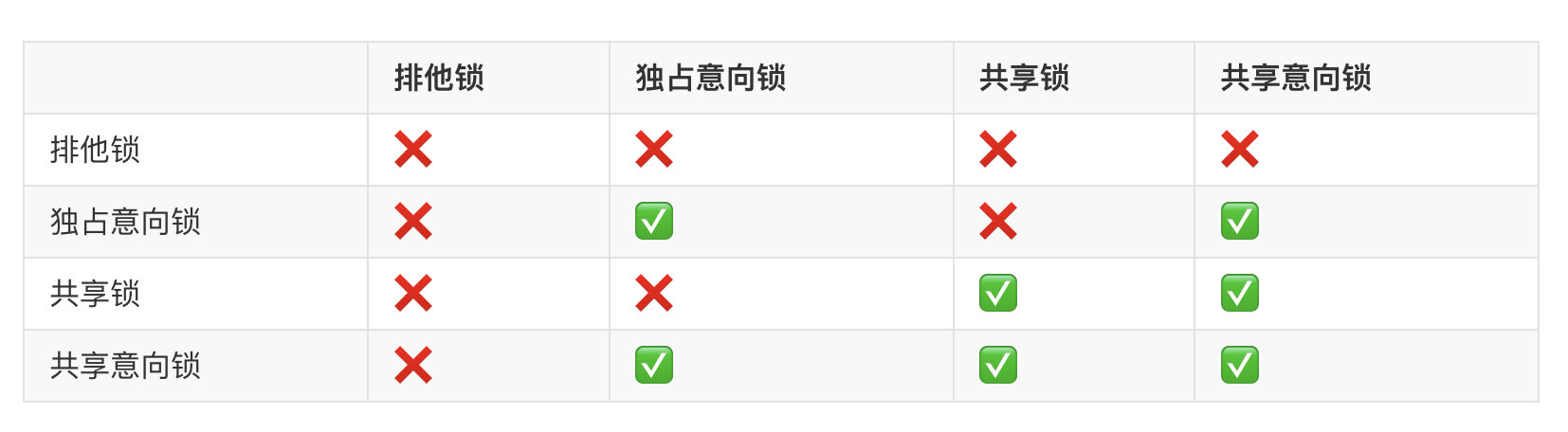
对照上面的表,在相互兼容的情况下,对应的事务就能获取锁,但是如果不兼容则无法获取锁,直到不兼容的锁释放之后才能获取。
看到这里你可能就会有问题了,那既然意向锁除了 LOCK TBALES 之外什么都不阻塞。那我要它何用?
还是通过例子,假设事务 A 获取了 student 表中 id = 100 这行的共享锁,之后事务 B 需要申请 student 表的排他锁。而这两把锁明显是冲突的,而且还是对于同一行。
那 InnoDB 需要如何感知 A 获取了这把锁?遍历整个 B+ 树吗?不,答案就是意向锁。事务 B 申请写表的排他锁时,InnoDB 会发现事务 A 已经获取了该表的意向共享锁,说明 student 表中已经有记录被共享锁锁住了。此时就会阻塞住。
并且,意向锁除了像LOCK TABLES这种操作之外,不会阻塞其他任何操作。换句话说,意向锁只会和表级别的锁之间发生冲突,而不会和行级锁发生冲突。因为意向锁的主要目的是为了表明有人即将、或者正在锁定某一行。
就像你去图书馆找书,你并不需要每个书架挨着挨着找,直接去服务台用电脑一搜,就知道图书馆有没有这本书。
记录锁
这就是记录锁,是行锁的一种。记录锁的锁定对象是对应那行数据所对应的索引。对索引不太清楚的可以看看这篇文章。
当我们执行SELECT * FROM student WHERE id = 1 FOR UPDATE语句时,就会对值为1的索引加上记录锁。至于要是一张表里没有索引该怎么办?这个问题在上面提到的文章中也解释过了,当一张表没有定义主键时,InnoDB 会创建一个隐藏的RowID,并以此 RowID 来创建聚簇索引。后续的记录锁也会加到这个隐藏的聚簇索引上。
当我们开启一个事务去更新 id = 1 这行数据时,如果我们不马上提交事务,然后再启一个事务去更新 id = 1 的行,此时使用 show engine innodb status查看,我们可以看到lock_mode X locks rec but not gap waiting的字样。
X是排他锁的意思,从这可以看出来,记录锁其实也可以分为共享锁、排他锁模式。当我们使用FOR UPDATE是排他,而使用LOCK IN SHARE MODE 则是共享。
而在上面字样中出现的 gap 就是另一种行锁的实现间隙锁。
间隙锁
对于间隙锁(Gap Locks)而言,其锁定的对象也是索引。为了更好的了解间隙锁,我们举个例子。
SELECT name FROM student WHERE age BETWEEN 18 AND 25 FOR UPDATE
假设我们为 age 建立了非聚簇索引,运行该语句会阻止其他事务向 student 表中新增 18-25 的数据,无论表中是否真的有 age 为 18-25 的数据。因为间隙锁的本质是锁住了索引上的一个范围,而 InnoDB 中索引在底层的B+树上的存储是有序的。
再举个例子:
SELECT * FROM student WHERE age = 10 FOR UPDATE;
值得注意的是,这里的 age 不是唯一索引,就是一个简单的非聚簇索引。此时会给 age = 10 的数据加上记录锁,并且锁定 age < 10 的 Gap。如果当前这个事务不提交,其他事务如果要插入一条 age < 10 的数据时,会被阻塞住。
间隙锁是 MySQL 在对性能、并发综合考虑之下的一种折中的解决方案,并且只在**可重复读(RR)下可用,如果当前事务的隔离级别为读已提交(RC)**时,MySQL会将间隙锁禁用。
刚刚说了,记录锁分为共享、排他,间隙锁其实也一样。但是不同于记录锁的一点,共享间隙锁、排他间隙锁相互不互斥,这是怎么回事?
我们还是需要透过现象看到本质,间隙锁的目的是什么?
为了防止其他事务在 Gap 中插入数据
那共享、排他间隙锁在这个目标上是一致的,所以是可以同时存在的。
临键锁
临键锁(Next-Key Locks)是 InnoDB 最后一种行锁的实现,临键锁实际上是记录锁和间隙锁的组合。换句话说,临键锁会给对应的索引加上记录锁,并且外加锁定一个区间。
但是并不是所有临键锁都是这么玩的,对于下面的SQL:
SELECT * FROM student WHERE id = 23;
在这种情况下,id是主键,唯一索引,无论其他事务插入了多少数据,id = 23这条数据永远也只有一条。此时再加一个间隙锁就完全没有必要了,反而会降低并发。所以,在使用的索引是唯一索引的时候,临键锁会降级为记录锁。
假设我们有10,20,30总共3条索引数据。那么对应临键锁来说,可能锁定的区间就会如下:
- (∞, 10]
- (10, 20]
- (20, 30]
- (30, ∞)
InnoDB 的默认事务隔离级别为可重复读(RR),在这个情况下,InnoDB 就会使用临键锁,以防止幻读的出现。
简单解释一下幻读,就是在事务内,你执行了两次查询,第一次查询出来 5 条数据,但是第二次再查,居然查出了 7 条数据,这就是幻读。
可能你在之前的很多博客,或者面试八股文上,了解到过 InnoDB 的RR事务隔离级别可以防止幻读,RR防止幻读的关键就是临键锁。
举个例子,假设 student 表中就两行数据,id分别为90和110.
SELECT * FROM student WHERE id > 100 FOR UPDATE;
当执行该 SQL 语句之后,InnoDB就会给区间 (90, 110] 和(110,∞) 加上间隙锁,同时给 id=110 的索引加上记录锁。这样以来,其他事务就无法向这个区间内新增数据,即使 100 根本不存在。
插入意向锁
接下来是插入意向锁(Insert Intention Locks),当我们执行 INSERT 语句之前会加的锁。本质上是间隙锁的一种。
还是举个例子,假设我们现在有索引记录10、20,事务A、B分别插入索引值为14、16的数据,此时事务A和B都会用插入意向锁锁住 10-20 之间的 Gap,获取了插入意向锁之后就会获取14、16的排他锁。
此时事务A和B是不会相互阻塞的,因为他们插入的是不同的行。
自增锁
最后是自增锁(AUTO-INC Locks),自增锁的本质是表锁,较为特殊。当事务 A 向包含了 AUTO_INCREMENT 列的表中新增数据时,就会持有自增锁。而此时其他的事务 B 则必须要等待,以保证事务 A 取得连续的自增值,中间不会有断层。
好了,通过下面链接获取MQ学习资料,包含基础概念解析和RocketMQ详细的源码解析,持续更新中,大家一定不要错过这份学习资料哦。
http://xiazai.jb51.net/202105/yuanma/RocketMQ_jb51.rar (必收藏)
以上就是简单了解 MySQL 中相关的锁的详细内容,更多关于MySQL锁相关的资料请关注我们其它相关文章!
相关推荐
-

由不同的索引更新解决MySQL死锁套路
前几篇文章介绍了用源码的方式来调试锁相关的信息,这里同样用这个工具来解决一个线上实际的死锁案例,也是我们介绍的第一个两条 SQL 就造成死锁的情况.因为线上的表结构比较复杂,做了一些简化以后如下 CREATE TABLE `t3` ( `id` int(11) NOT NULL AUTO_INCREMENT, `a` varchar(5), `b` varchar(5), PRIMARY KEY (`id`), UNIQUE KEY `uk_a` (`a`), KEY `idx_b` (`b`)
-
详解MySQL(InnoDB)是如何处理死锁的
一.什么是死锁 官方定义如下:两个事务都持有对方需要的锁,并且在等待对方释放,并且双方都不会释放自己的锁. 这个就好比你有一个人质,对方有一个人质,你们俩去谈判说换人.你让对面放人,对面让你放人. 二.为什么会形成死锁 看到这里,也许你会有这样的疑问,事务和谈判不一样,为什么事务不能使用完锁之后立马释放呢?居然还要操作完了之后一直持有锁?这就涉及到 MySQL 的并发控制了. MySQL的并发控制有两种方式,一个是 MVCC,一个是两阶段锁协议.那么为什么要并发控制呢?是因为多个用户同时操作 M
-
一个mysql死锁场景实例分析
前言 最近遇到一个mysql在RR级别下的死锁问题,感觉有点意思,研究了一下,做个记录. 涉及知识点:共享锁.排他锁.意向锁.间隙锁.插入意向锁.锁等待队列 场景 隔离级别:Repeatable-Read 表结构如下 create table t ( id int not null primary key AUTO_INCREMENT, a int not null default 0, b varchar(10) not null default '', c varchar(10) not n
-
实例讲解MySQL中乐观锁和悲观锁
数据库管理系统中并发控制的任务是确保在多个事务同时存取数据库中同一数据不破坏事务的隔离性和统一性以及数据库的统一性 乐观锁和悲观锁式并发控制主要采用的技术手段 悲观锁 在关系数据库管理系统中,悲观并发控制(悲观锁,PCC)是一种并发控制的方法.它可以阻止一个事务以影响其他用户的方式来修改数据.如果一个事务执行的操作的每行数据应用了锁,那只有当这个事务锁释放,其他事务才能够执行与该锁冲突的操作 悲观并发控制主要应用于数据争用激烈的环境,以及发生并发冲突时使用锁保护数据的成本要低于回滚事务的成本环境
-
Mysql查询正在执行的事务以及等待锁的操作方式
使用navicat测试学习: 首先使用set autocommit = 0;(取消自动提交,则当执行语句commit或者rollback执行提交事务或者回滚) 在打开一个执行update 查询 正在执行的事务: SELECT * FROM information_schema.INNODB_TRX 根据这个事务的线程ID(trx_mysql_thread_id): 从上图看出对应的mysql 线程:一个94362 (第二个正在等待锁)另一个是93847(第一个update 正在执行 没有提交事务
-
MySQL 死锁套路:唯一索引 S 锁与 X 锁的爱恨情仇
在初学者从源码理解MySQL死锁问题中介绍了使用调试 MySQL 源码的方式来查看死锁的过程,这篇文章来讲讲一个常见的案例. 毫不夸张的说,有一半以上的死锁问题由唯一索引贡献,后面介绍的很多死锁的问题都跟唯一索引有关.这次我们讲一段唯一索引 S 锁与 X 锁的爱恨情仇 我们来看一个简化过的例子 # 构造数据 CREATE TABLE `t1` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(10), `level` int(11),
-
简单了解 MySQL 中相关的锁
本文主要是带大家快速了解 InnoDB 中锁相关的知识 基础概念解析和RocketMQ详细的源码解析 http://xiazai.jb51.net/202105/yuanma/RocketMQ_jb51.rar 为什么需要加锁 首先,为什么要加锁?我想我不用多说了,想象接下来的场景你就能 GET 了. 你在商场的卫生间上厕所,此时你一定会做的操作是啥?锁门.如果不锁门,上厕所上着上着,啪一下门就被打开了,可能大概也许似乎貌似有那么一丁点的不太合适. 数据也是一样,在并发的场景下,如果不对数据加锁
-
MySQL中的悲观锁与乐观锁
在关系型数据库中,悲观锁与乐观锁是解决资源并发场景的解决方案,接下来将详细讲解
-
MySQL中的乐观锁,悲观锁和MVCC全面解析
前言 在数据库的实际使用过程中,我们常常会遇到不希望数据被同时写或者读的情景,例如秒杀场景下,两个请求同时读到系统还有库存1个,然后又先后把库存更新为0,这时候就会出现超卖的情况,这时候货物的实际库存和我们的记录就会对应不上了. 为了解决这种资源竞争导致的数据不一致等问题,我们需要有一种机制来进行保证数据的正确访问和修改,而在数据库中,这种机制就是数据库的并发控制.其中乐观并发控制,悲观并发控制和多版本并发控制是数据库并发控制主要采用的技术手段. 悲观并发控制 本质 维基百科:在关系数据库管理系
-
简单介绍MySQL中的事务机制
从一个问题开始 最近银行这个事情闹的比较厉害啊,很多储户的钱放在银行,就不翼而飞了,而银行还不管不问,说是用户的责任,打官司,用户还能输了,这就是"社会主义".咱还是少发牢骚,多种树,莫谈国事. 说到银行存钱,就不得不说一下从银行取钱这件事情,从ATM机取钱这件简单的事情,实际上主要分为以下几个步骤: 登陆ATM机,输入密码: 连接数据库,验证密码: 验证成功,获得用户信息,比如存款余额等: 用户输入需要取款的金额,按下确认键: 从后台数据库中减掉用户账户上的对应金额: ATM吐出钱:
-
简单谈谈MySQL中的int(m)
我们在设计表的时候,如果碰到需要设置int(整型)的时候,通常会按照惯例(大家都这样写)设置成int(11).那么这里为什么是11呢?代表的又是什么呢? 以前我一直以为这里是在限制int显示的宽度,后来仔细研究和通过上网查询发现,事实并不是那样的. 确切的来说,这里的"宽度"只是一个"预期值",它所代表的仅仅是你在设计数据表结构时,想让该列日后显示的值宽度为多少,但是具体存入值的宽度多少不会受任何影响. 当然,它的作用不仅如此,在存入数据的时候,还是有一定区别的,这
-
简单讲解MySQL中的多源复制
近日ORACLE发布几个新的功能在最新的Mysql5.7.2的版本上,由此有了此篇文章.大多数的改善是在数据库性能和复制相关的功能上,这个新版本会带给我们不可思议的效果. 在这篇文章里,我将要用一些简单的步奏来尝试了解这新的多源复制工作原理以及我们怎样进行自己的测试.需要说明的是,这还是一个开发版本,不是给生产环境准备的.因此这篇文章是打算给那些想了解此新功能的人,看看它是如何在应用中工作的,都是在临时环境中进行相关操作. 什么是多源复制? 首先,我们需要清楚 multi-master 与mul
-
简单介绍MySQL中索引的使用方法
数据库索引是一个数据结构,提高操作的速度,在一个表中可以使用一个或多个列,提供两个快速随机查找和高效的顺序访问记录的基础创建索引. 在创建索引时,它应该被认为是将SQL查询的那些列上创建一个或多个索引的列. 实际上,指数也保持主键或索引字段和指针的实际表中每条记录的表型. 用户无法看到索引,它们只是用来加快查询速度,将用于数据库搜索引擎找到的记录速度非常快. INSERT和UPDATE语句表上的索引需要更多的时间,成为快速对这些表的SELECT语句.究其原因是,当进行插入或更新,数据库以及需要惰
-
简单解析MySQL中的cardinality异常
前段时间,一大早上,就收到报警,警告php-fpm进程的数量超过阈值.最终发现是一条sql没用到索引,导致执行数据库查询慢了,最终导致php-fpm进程数增加.最终通过analyze table feed_comment_info_id_0000 命令更新了Cardinality ,才能再次用到索引. 排查过程如下: sql语句: select id from feed_comment_info_id_0000 where obj_id=101 and type=1; 索引信息: show in
-
简单分析MySQL中的primary key功能
在5.1.46中优化器在对primary key的选择上做了一点改动: Performance: While looking for the shortest index for a covering index scan, the optimizer did not consider the full row length for a clustered primary key, as in InnoDB. Secondary covering indexes will now be pref
-
简单介绍MySQL中GROUP BY子句的使用
可以使用GROUP BY组值一列,并且如果愿意的话,可以将该列进行计算.使用COUNT,SUM,AVG等功能的分组列. 要了解GROUP BY子句考虑的EMPLOYEE_TBL的的表具有以下记录: mysql> SELECT * FROM employee_tbl; +------+------+------------+--------------------+ | id | name | work_date | daily_typing_pages | +------+------+----