深入解析Apache Hudi内核文件标记机制
目录
- 1. 摘要
- 2. 为何引入Markers机制
- 3. 现有的直接标记机制及其局限性
- 4. 基于时间线服务器的标记机制提高写入性能
- 5. 标记相关的写入选项
- 6. 性能
- 7. 总结
1. 摘要
Hudi 支持在写入时自动清理未成功提交的数据。Apache Hudi 在写入时引入标记机制来有效跟踪写入存储的数据文件。 在本博客中,我们将深入探讨现有直接标记文件机制的设计,并解释了其在云存储(如 AWS S3、Aliyun OSS)上针对非常大批量写入的性能问题。 并且演示如何通过引入基于时间轴服务器的标记来提高写入性能。
2. 为何引入Markers机制
Hudi中的marker是一个表示存储中存在对应的数据文件的标签,Hudi使用它在故障和回滚场景中自动清理未提交的数据。
每个标记条目由三部分组成
- 数据文件名
- 标记扩展名 (.marker)
- 创建文件的 I/O 操作(CREATE - 插入、MERGE - 更新/删除或 APPEND - 两者之一)。
例如标记91245ce3-bb82-4f9f-969e-343364159174-0_140-579-0_20210820173605.parquet.marker.CREATE指示相应的数据文件是91245ce3-bb82-4f9f-969e-343364159174-0_140-579-0_20210820173605.parquet
并且 I/O 类型是 CREATE。
在写入每个数据文件之前,Hudi 写入客户端首先在存储中创建一个标记,该标记会被持久化,在提交成功后会被写入客户端显式删除。
标记对于写客户端有效地执行不同的操作很有用,标记主要有如下两个作用
删除重复/部分数据文件:通过 Spark 写入 Hudi 时会有多个 Executor 进行并发写入。一个 Executor 可能失败,留下部分数据文件写入,在这种情况下 Spark 会重试 Task ,当启用speculative execution时,可以有多次attempts成功将相同的数据写入不同的文件,但最终只有一次attempt会交给 Spark Driver程序进程进行提交。标记有助于有效识别写入的部分数据文件,其中包含与后来成功写入的数据文件相比的重复数据,并在写入和提交完成之前清理这些重复的数据文件。
回滚失败的提交:写入时可能在中间失败,留下部分写入的数据文件。在这种情况下,标记条目会在提交失败时保留在存储中。在接下来的写操作中,写客户端首先回滚失败的提交,通过标记识别这些提交中写入的数据文件并删除它们。
接下来我们将深入研究现有的标记机制,阐述其性能问题,并演示新的基于时间轴服务器的标记机制来解决该问题。
3. 现有的直接标记机制及其局限性
现有的标记机制简单地创建与每个数据文件相对应的新标记文件,标记文件名如前面所述。 每个 marker 文件被写入在相同的目录层次结构中,即提交即时和分区路径,在Hudi表的基本路径下的临时文件夹.hoodie/.temp下。 例如,下图显示了向 Hudi 表写入数据时创建的标记文件和相应数据文件的示例。 在获取或删除所有marker文件路径时,该机制首先列出临时文件夹.hoodie/.temp/<commit_instant>下的所有路径,然后进行操作。
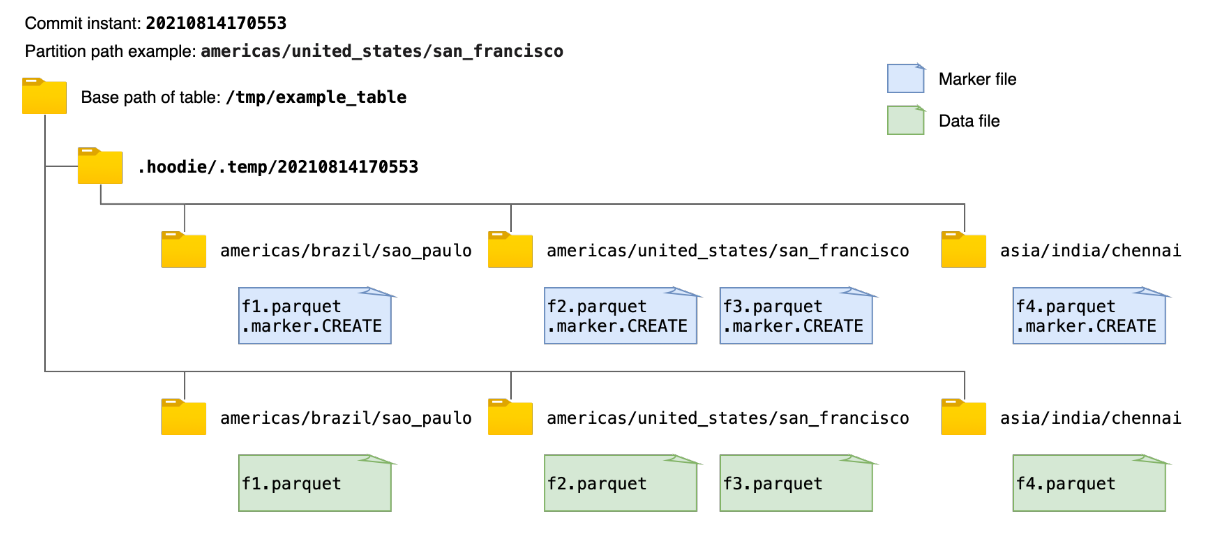
虽然扫描整个表以查找未提交的数据文件效率更高,但随着要写入的数据文件数量的增加,要创建的标记文件的数量也会增加。 这可能会为 AWS S3 等云存储带来性能瓶颈。 在 AWS S3 中,每个文件创建和删除调用都会触发一个 HTTP 请求,并且对存储桶中每个前缀每秒可以处理的请求数有速率限制。 当并发写入的数据文件数量和 marker 文件数量巨大时,marker 文件的操作会成为写入性能的显着性能瓶颈。而在像 HDFS 这样的存储上,用户可能几乎不会注意到这一点,其中文件系统元数据被有效地缓存在内存中。
4. 基于时间线服务器的标记机制提高写入性能
为解决上述 AWS S3 速率限制导致的性能瓶颈,我们引入了一种利用时间线服务器的新标记机制,该机制优化了存储标记的相关延迟。 Hudi 中的时间线服务器用作提供文件系统和时间线视图。 如下图所示,新的基于时间线服务器的标记机制将标记创建和其他标记相关操作从各个执行器委托给时间线服务器进行集中处理。 时间线服务器在内存中为相应的标记请求维护创建的标记,时间线服务器通过定期将内存标记刷新到存储中有限数量的底层文件来实现一致性。 通过这种方式,即使数据文件数量庞大,也可以显着减少与标记相关的实际文件操作次数和延迟,从而提高写入性能。

为了提高处理标记创建请求的效率,我们设计了在时间线服务器上批量处理标记请求。 每个标记创建请求在 Javalin 时间线服务器中异步处理,并在处理前排队。 对于每个批处理间隔,例如 20 毫秒,调度线程从队列中拉出待处理的请求并将它们发送到工作线程进行处理。 每个工作线程处理标记创建请求,并通过重写存储标记的底层文件。有多个工作线程并发运行,考虑到文件覆盖的时间比批处理时间长,每个工作线程写入一个不被其他线程触及的独占文件以保证一致性和正确性。 批处理间隔和工作线程数都可以通过写入选项进行配置。
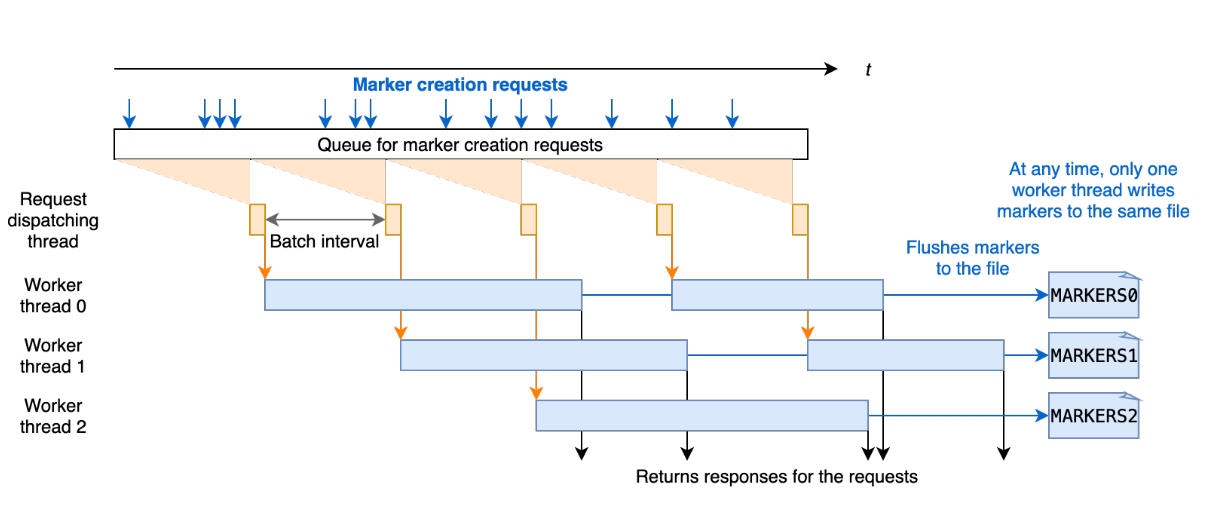
请注意工作线程始终通过将请求中的标记名称与时间线服务器上维护的所有标记的内存副本进行比较来检查标记是否已经创建。 存储标记的底层文件仅在第一个标记请求(延迟加载)时读取。 请求的响应只有在新标记刷新到文件后才会返回,以便在时间线服务器故障的情况下,时间线服务器可以恢复已经创建的标记。 这些确保存储和内存中副本之间的一致性,并提高处理标记请求的性能。
5. 标记相关的写入选项
我们在 0.9.0 版本中引入了以下与标记相关的新写入选项,以配置标记机制。
- hoodie.write.markers.type,要使用的标记类型。支持两种模式:
direct,每个数据文件对应的单独标记文件由编写器直接创建; timeline_server_based,标记操作全部在时间线服务中处理作为代理。 为了提高效率新的标记条目被批处理并存储在有限数量的基础文件中。默认值为direct。 - hoodie.markers.timeline_server_based.batch.num_threads,用于在时间轴服务器上批处理标记创建请求的线程数。默认值为20。
- hoodie.markers.timeline_server_based.batch.interval_ms,标记创建批处理的批处理间隔(以毫秒为单位)。默认值为50。
6. 性能
我们通过使用 Amazon EMR 和 Spark 和 S3 批量插入大规模数据集来评估direct和timeline_server_based的标记机制的写入性能。 输入数据大约为 100GB。 我们通过设置最大 parquet 文件大小为 1MB 和并行度为 240 来配置写入操作以并发生成大量数据文件。 正如我们之前提到的,而直接标记机制的延迟对于较小数量的增量写入是可以接受的,对于产生更多数据文件的大批量插入/写入,开销会急剧增加。
如下图所示,由于是批处理,基于时间线服务器的标记机制生成的存储标记的文件要少得多,从而导致标记相关的 I/O 操作的时间要少得多,因此与直接相比,写入完成时间减少了 31%。 标记文件机制。

7. 总结
我们发现由于 AWS S3 等云存储上文件创建和删除调用的速率限制,现有的直接标记文件机制会导致性能瓶颈。 为了解决这个问题我们引入了一种利用时间线服务器的新标记机制,它将标记创建和其他与标记相关的操作从各个 Executor 委托给时间线服务器,并使用批处理来提高性能。使用 Spark 和 S3 在 Amazon EMR 上进行的性能评估表明,与标记相关的 I/O 延迟和整体写入时间有所减少。
以上就是深入解析Apache Hudi内核文件标记机制的详细内容,更多关于Apache Hudi内核文件标记的资料请关注我们其它相关文章!
相关推荐
-
Apache教程Hudi与Hive集成手册
目录 1. Hudi表对应的Hive外部表介绍 2. Hive对Hudi的集成 3. 创建Hudi表对应的hive外部表 4. 查询Hudi表对应的Hive外部表 4.1 操作前提 4.2 COW类型Hudi表的查询 4.2.1 COW表实时视图查询 4.2.2 COW表增量查询 4.3 MOR类型Hudi表的查询 4.3.1 MOR表读优化视图 4.3.2 MOR表实时视图 4.3.3 MOR表增量查询 5. Hive侧源码修改 1. Hudi表对应的Hive外部表介绍 Hudi源表对应一份H
-

Apache Hudi数据布局黑科技降低一半查询时间
目录 1. 背景 2. Clustering架构 2.1 调度Clustering 2.2 运行Clustering 2.3 Clustering配置 3. 表查询性能 3.1 进行Clustering之前 3.2 进行Clustering之后 4. 总结 1. 背景 Apache Hudi将流处理带到大数据,相比传统批处理效率高一个数量级,提供了更新鲜的数据.在数据湖/仓库中,需要在摄取速度和查询性能之间进行权衡,数据摄取通常更喜欢小文件以改善并行性并使数据尽快可用于查询,但很多小文件会导致查
-
Apache Hudi性能提升三倍的查询优化
目录 1. 背景 2. 设置 3. 测试 4. 结果 5. 总结 从 Hudi 0.10.0版本开始,我们很高兴推出在数据库领域中称为 Z-Order 和 Hilbert 空间填充曲线的高级数据布局优化技术的支持. 1. 背景 Amazon EMR 团队最近发表了一篇很不错的文章展示了对数据进行聚簇是如何提高查询性能的,为了更好地了解发生了什么以及它与空间填充曲线的关系,让我们仔细研究该文章的设置. 文章中比较了 2 个 Apache Hudi 表(均来自 Amazon Reviews 数据集)
-
Apache Hudi异步Clustering部署操作的掌握
目录 1. 摘要 2. 介绍 3. Clustering策略 3.1 计划策略 3.2 执行策略 3.3 更新策略 4. 异步Clustering 4.1 HoodieClusteringJob 4.2 HoodieDeltaStreamer 4.3 Spark Structured Streaming 5. 总结和未来工作 1. 摘要 在之前的一篇博客中,我们介绍了Clustering(聚簇)的表服务来重新组织数据来提供更好的查询性能,而不用降低摄取速度,并且我们已经知道如何部署同步Clust
-
Apache Hudi结合Flink的亿级数据入湖实践解析
目录 1. 实时数据落地需求演进 2. 基于Spark+Hudi的实时数据落地应用实践 3. 基于Flink自定义实时数据落地实践 4. 基于Flink + Hudi的落地数据实践 5. 后续应用规划及展望 5.1 取代离线报表,提高报表实时性及稳定性 5.2 完善监控体系,提升落数据任务稳定性 5.3 落数据中间过程可视化探索 本次分享分为5个部分介绍Apache Hudi的应用与实践 1. 实时数据落地需求演进 实时平台上线后,主要需求是开发实时报表,即抽取各类数据源做实时etl后,吐出实时
-
Apache Hudi基于华米科技应用湖仓一体化改造
目录 1. 应用背景及痛点介绍 2. 技术方案选型 3. 问题与解决方案 3.1.增量数据字段对齐问题 3.2 全球存储兼容性问题 3.3 云主机时区统一问题 3.4 升级新版本问题 3.5 多分区Upsert性能问题 3.6 数据特性适应问题 4. 上线收益 4.1 成本方面 4.2 效率方面 4.3 稳定性层面 4.4 查询性能层面 5. 总结与展望 1. 应用背景及痛点介绍 华米科技是一家基于云的健康服务提供商,拥有全球领先的智能可穿戴技术.在华米科技,数据建设主要围绕两类数据:设备数据和
-
深入解析Apache Hudi内核文件标记机制
目录 1. 摘要 2. 为何引入Markers机制 3. 现有的直接标记机制及其局限性 4. 基于时间线服务器的标记机制提高写入性能 5. 标记相关的写入选项 6. 性能 7. 总结 1. 摘要 Hudi 支持在写入时自动清理未成功提交的数据.Apache Hudi 在写入时引入标记机制来有效跟踪写入存储的数据文件. 在本博客中,我们将深入探讨现有直接标记文件机制的设计,并解释了其在云存储(如 AWS S3.Aliyun OSS)上针对非常大批量写入的性能问题. 并且演示如何通过引入基于时间轴服
-
Apache Hudi灵活的Payload机制硬核解析
1.摘要 Apache Hudi 的Payload是一种可扩展的数据处理机制,通过不同的Payload我们可以实现复杂场景的定制化数据写入方式,大大增加了数据处理的灵活性.Hudi Payload在写入和读取Hudi表时对数据进行去重.过滤.合并等操作的工具类,通过使用参数 "hoodie.datasource.write.payload.class"指定我们需要使用的Payload class.本文我们会深入探讨Hudi Payload的机制和不同Payload的区别及使用场景. 2
-
解析Apache Dubbo的SPI实现机制
一.SPI 在Java中,SPI体现了面向接口编程的思想,满足开闭设计原则. 1.1.JDK自带SPI实现 从JDK1.6开始引入SPI机制后,可以看到很多使用SPI的案例,比如最常见的数据库驱动实现,在JDK中只定义了java.sql.Driver的接口,具体实现由各数据库厂商来提供.下面一个简单的例子来快速了解下Java SPI的使用方式: 1)定义一个接口 package com.vivo.study public interface Car { void getPrice(); } 2)
-
OnZoom基于Apache Hudi的一体架构实践解析
1. 背景 OnZoom是Zoom新产品,是基于Zoom Meeting的一个独一无二的在线活动平台和市场.作为Zoom统一通信平台的延伸,OnZoom是一个综合性解决方案,为付费的Zoom用户提供创建.主持和盈利的活动,如健身课.音乐会.站立表演或即兴表演,以及Zoom会议平台上的音乐课程. 在OnZoom data platform中,source数据主要分为MySQL DB数据和Log数据. 其中Kafka数据通过Spark Streaming job实时消费,MySQL数据通过Spark
-
Apache Hudi的多版本清理服务彻底讲解
目录 1. 回收空间以控制存储成本 2. 问题描述 3. 深入了解 Hudi清理服务 4. 清理服务 5. 例子 6. 配置 7. 运行命令 8. 未来计划 Apache Hudi提供了MVCC并发模型,保证写入端和读取端之间快照级别隔离.在本篇博客中我们将介绍如何配置来管理多个文件版本,此外还将讨论用户可使用的清理机制,以了解如何维护所需数量的旧文件版本,以使长时间运行的读取端不会失败. 1. 回收空间以控制存储成本 Hudi 提供不同的表管理服务来管理数据湖上表的数据,其中一项服务称为Cle
-
Apache Hudi基于华米科技应用湖仓一体化改造
目录 1. 应用背景及痛点介绍 2. 技术方案选型 3. 问题与解决方案 3.1.增量数据字段对齐问题 3.2 全球存储兼容性问题 3.3 云主机时区统一问题 3.4 升级新版本问题 3.5 多分区Upsert性能问题 3.6 数据特性适应问题 4. 上线收益 4.1 成本方面 4.2 效率方面 4.3 稳定性层面 4.4 查询性能层面 5. 总结与展望 1. 应用背景及痛点介绍 华米科技是一家基于云的健康服务提供商,拥有全球领先的智能可穿戴技术.在华米科技,数据建设主要围绕两类数据:设备数据和