MySQL使用索引优化性能
目录
- 1.索引问题
- 2.索引的存储分类
- 3.如何使用索引
- 3.1使用索引
- 3.2存在索引但不使用索引
- 4.查看索引使用情况
- 5.两个简单实用的优化方法
- 5.1定期分析表和检查表
- 5.2定期优化表
1.索引问题
索引是数据库优化中最常用也是最重要的手段之一,通过索引通常可以帮助用户解决大多数 的SQL性能问题。本章节将对MySQL中的索引的分类、存储、使用方法做详细的介绍。
2.索引的存储分类
MyISAM存储引擎的表数据和索引是自动分开存储的,各自是独立的一个文件;InnoDB存储引擎的表数据和索引是存储在同一个表空间里面,但可以有多个文件组成。MySQL中索引的存储类型目前只有两种(BTREE和HASH),具体和表的存储引擎相关:MyISAM和InnoDB存储引擎都只支持BTREE索引;MEMORY/HEAP存储引擎可以支持HASH和BTREE索引。MySQL目前不支持函数索引,但是能对列的前面某一部分进索引,例如上章节库存表goods_stock.LotNO批次字段,可以只取Model的前4个字符进行索引,这个特性可以大大缩小索引文件的大小,我们在设计表结构的时候也可以对文本列根据此特性进行灵活设计。下面是创建前缀索引的一个例子:
EXPLAIN SELECT * FROM goods_stock WHERE LotNO LIKE '2021%';

-- 创建前缀索引 CREATE INDEX idx_stock_2 ON goods_stock (LotNO(4));

3.如何使用索引
索引用于快速找出在某个列中有一特定值的行。对相关列使用索引是提高SELECT操作性能的最佳途径。查询要使用索引最主要的条件是查询条件中需要使用索引关键字,如果是多列索引,那么只有查询条件使用了多列关键字最左边的前缀时,才可以使用索引,否则将不能使用索引。
3.1使用索引
在MySQL中,下列几种情况下有可能使用到索引。
对于创建的多列索引,只要查询的条件中用到了最左边的列,索引一般就会被使用, 举例说明如下:
-- 首先在库存表goods_stock按Model,Brand的顺序创建一个复合索引 CREATE INDEX idx_stock_1 ON goods_stock (Model,Brand);
然后按Model进行表查询,具体命令如下:
EXPLAIN SELECT * FROM goods_stock WHERE Model='LM358DT';

可以发现即便where条件中不是用Model与Brand字段的组合条件,索引仍然能用到,这就是索引的前缀特性(按照索引列顺序查询)。但是如果只按Brand条件查询表,那么索引就不会被用到,具体如下:
EXPLAIN SELECT * FROM goods_stock WHERE Brand='TI';

对于使用like的查询,后面如果是常量并且只有%号不在第一个字符,索引才可能会被使用,来看下面两个执行计划:
EXPLAIN SELECT * FROM goods_stock WHERE Model LIKE '%LM358';

EXPLAIN SELECT * FROM goods_stock WHERE Model LIKE 'LM358%';

可以发现第一个SQL没有使用索引,而第二个SQL就能够使用索引,区别就在于“%”的位置不同,前者把“%”放到第一位就不能用到索引,而后者没有放到第一位就使用了索引。另外,如果如果like后面跟的是一个列的名字,那么索引也不会被使用。如果对大的文本进行搜索,使用全文索引而不要使用like ‘%...%’。
如果列名是索引,使用column_name is null时候将会使用索引。如下例中查询LotNO为null的记录时候就会用到索引:
EXPLAIN SELECT * FROM goods_stock WHERE LotNO IS NULL;

3.2存在索引但不使用索引
在下列情况下,虽然存在索引,但是MySQL并不会使用相应的索引。
如果MySQL估计使用索引比全表扫描更慢,则不使用索引。例如如果列 key_part1 均匀分布在 1 和 100 之间,下列查询中使用索引就不是很好:
SELECT * FROM table_name where key_part1 > 1 and key_part1 < 90;
如果使用MEMORY/HEAP表并且where条件中不使用“=”进行索引列,那么不会用到索引。HEAP表只有在“=”的条件下才会使用索引。
用or分割开的条件,如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及到的索引都不会被用到,例如:
SHOW INDEX FROM goods_stock;

通过命令可以看到goods_stock库存表有两个索引,然后我们再执行如下语句看是否使用索引:
EXPLAIN SELECT * FROM goods_stock WHERE LotNO='20200821' OR PackageUnit='包';

可见虽然在LotNO这个列上存在索引idx_stock_2,但是这个SQL语句并没有用到这个索引,原因就是or中有一个条件中的列没有索引。
如果列类型是字符串,那么一定记得在where条件中把字符常量值用引号引起来,否则即便这个列上有索引,MySQL也不会用到的,因为MySQL默认把输入的常量值进行转换以后才进行检索,请看如下例子:
DESC goods_stock;

通过DESC命令我们可以看到goods_stock库存表中的LotNO字段是字符型,如果我们在SQL语句中的LotNO字段加入一个数值型为20200821的条件值,因此即便在LotNO上有索引,MySQL也不能正确地用上索引,而是继续进行全表扫描,具体如下:
EXPLAIN SELECT * FROM goods_stock WHERE LotNO=20200821;

4.查看索引使用情况
如果索引正在工作,Handler_read_key的值将很高,这个值代表了一个行被索引值读的次数,很低的值表明增加索引得到的性能改善不高,因为索引并不经常使用。Handler_read_rnd_next的值高则意味着查询运行低效,并且应该建立索引补救。这个值的含义是在数据文件中读下一行的请求数。如果正进行大量的表扫描,Handler_read_rnd_next的值较高,则通常说明表索引不正确或写入的查询没有利用索引。可以先刷新状态再查询,具体如下:
FLUSH STATUS; SHOW STATUS LIKE 'Handler_read%';

参数解释如下:
- Handler_read_first:此选项表明SQL是在做一个全索引扫描,注意是全部,而不是部分,所以说如果存在WHERE语句,这个选项是不会变的。
- Handler_read_key:此选项数值如果很高,MySQL高效的使用了索引,一切运转良好。
- Handler_read_next:此选项表明在进行索引扫描时,按照索引从数据文件里取数据的次数。
- Handler_read_prev:此选项表明在进行索引扫描时,按照索引倒序从数据文件里取数据的次数,一般就是ORDER BY … DESC。
- Handler_read_rnd:就是查询直接操作了数据文件,很多时候表现为没有使用索引或者文件排序。
- Handler_read_rnd_next:此选项值较高时候,则通常说明表索引不正确或写入的查询没有利用索引。
5.两个简单实用的优化方法
对于大多数开发人员来说,可能只希望掌握一些简单实用的优化方法,对于更多更复杂的优化,更倾向于交给专业DBA来做。本小节将向大家介绍两个简单适用的优化方法。
5.1定期分析表和检查表
分析表的语法如下:
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
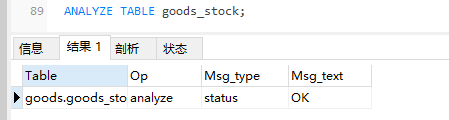
本语句用于分析和存储表的关键字分布,分析的结果将可以使得系统得到准确的统计信息,使得SQL能够生成正确的执行计划。如果用户感觉实际执行计划并不是预期的执行计划,执行一次分析表可能会解决问题。在分析期间,使用一个读取锁定对表进行锁定。这对于MyISAM, BDB和InnoDB表有作用。对于MyISAM表,本语句与使用myisamchk -a相当,下例中对goods_stock表做了表分析:
ANALYZE TABLE goods_stock;
检查表的语法如下:
CHECK TABLE tbl_name [, tbl_name] ... [option] ... option = {QUICK | FAST | MEDIUM | EXTENDED | CHANGED}
检查表的作用是检查一个或多个表是否有错误。CHECK TABLE对MyISAM和InnoDB表有作用。对于MyISAM表,关键字统计数据被更新,例如:
CHECK TABLE goods_stock;

CHECK TABLE也可以检查视图是否有错误,比如在视图定义中被引用的表已不存在,举例如下:
(1)首先我们创建一个表。
CREATE TABLE test ( ID INT(11) );
(2)再创建一个视图。
CREATE VIEW test_view AS SELECT * FROM test;
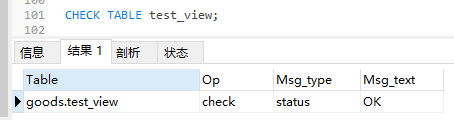
(3)然后CHECK一下该视图,发现没有问题。
CHECK TABLE test_view;
(4)现在删除掉视图依赖的表。
DROP TABLE test;
(5)再来CHECK一下刚才的视图,发现报错了。
CHECK TABLE test_view;

5.2定期优化表
优化表的语法如下:
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
如果已经删除了表的一大部分,或者如果已经对含有可变长度行的表(含有VARCHAR、BLOB或TEXT列的表)进行了很多更改,则应使用OPTIMIZE TABLE 命令来进行表优化。这个命令可以将表中的空间碎片进行合并,并且可以消除由于删除或者更新造成的空间浪费,但OPTIMIZE TABLE命令只对MyISAM、BDB和InnoDB表起作用。以下例子显示了优化goods_stock库存表的过程:
-- 先查看下goods_stock库存表是什么表类型 SHOW TABLE STATUS LIKE 'goods_stock%';

OPTIMIZE TABLE goods_stock;

注意:ANALYZE、CHECK、OPTIMIZE执行期间将对表进行锁定,因此一定注意要在数据库不繁忙的情况下执行相关的操作。
到此这篇关于MySQL使用索引优化性能的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Mysql性能优化案例 - 覆盖索引分享
场景 产品中有一张图片表,数据量将近100万条,有一条相关的查询语句,由于执行频次较高,想针对此语句进行优化 表结构很简单,主要字段: 复制代码 代码如下: user_id 用户ID picname 图片名称 smallimg 小图名称 一个用户会有多条图片记录 现在有一个根据user_id建立的索引:uid 查询语句也很简单:取得某用户的图片集合 复制代码 代码如下: select picname, smallimg from pics where user_id = xxx; 优化前 执行查
-
mysql性能优化之索引优化
作为免费又高效的数据库,mysql基本是首选.良好的安全连接,自带查询解析.sql语句优化,使用读写锁(细化到行).事物隔离和多版本并发控制提高并发,完备的事务日志记录,强大的存储引擎提供高效查询(表记录可达百万级),如果是InnoDB,还可在崩溃后进行完整的恢复,优点非常多.即使有这么多优点,仍依赖人去做点优化,看书后写个总结巩固下,有错请指正. 完整的mysql优化需要很深的功底,大公司甚至有专门写mysql内核的,sql优化攻城狮,mysql服务器的优化,各种参数常量设定,查询语句优化,主
-
Mysql性能优化之索引下推
索引下推(index condition pushdown )简称ICP,在Mysql5.6的版本上推出,用于优化查询. 在不使用ICP的情况下,在使用非主键索引(又叫普通索引或者二级索引)进行查询时,存储引擎通过索引检索到数据,然后返回给MySQL服务器,服务器然后判断数据是否符合条件 . 在使用ICP的情况下,如果存在某些被索引的列的判断条件时,MySQL服务器将这一部分判断条件传递给存储引擎,然后由存储引擎通过判断索引是否符合MySQL服务器传递的条件,只有当索引符合条件时才会将数据检索出
-
Mysql索引性能优化问题解决方案
mysql 创建的优化就是加索引,可是有时候会遇到加索引都没法达到想要的效果的情况, 加上了所以,却还是搜索的全数据,原因是sql EXPLAIN SELECT cs.sid, -- c.courseFrontTitle, -- c.imgBig, cs.studyStatus, coi.fee, -- act.PROC_INST_ID_ AS processId, cs.createDTM, cs.payStatus, cs.isCompleted, cs.saleChannel, cs.is
-
Mysql性能优化案例研究-覆盖索引和SQL_NO_CACHE
场景 产品中有一张图片表pics,数据量将近100万条,有一条相关的查询语句,由于执行频次较高,想针对此语句进行优化 表结构很简单,主要字段: 复制代码 代码如下: user_id 用户ID picname 图片名称 smallimg 小图名称 一个用户会有多条图片记录,现在有一个根据user_id建立的索引:uid,查询语句也很简单:取得某用户的图片集合: 复制代码 代码如下: select picname, smallimg from pics where user_id = xxx; 优化
-
MySQL性能优化之如何高效正确的使用索引
实践是检验真理的唯一途径,本篇只是站在索引使用的全局来定位的,你只需要通读全篇并结合具体的例子,或回忆以往使用过的地方,对整体有个全面认识,并理解索引是如何工作的,就可以了.在后续使用索引,或者优化索引时,可以从这些方面出发,进一步来加深对索引正确高效的使用. 一.索引失效 索引失效,是一个老生常谈的话题了.只要提到数据库优化.使用索引,都能一口气说出一大堆索引失效的场景,什么不能用.什么不该用这类的话,在此,我就不再一一罗列啰嗦了. 索引失效,是指表中有字段创建了索引,由于sql语句书写不当导
-
MySQL索引背后的之使用策略及优化(高性能索引策略)
本章的内容完全基于上文的理论基础,实际上一旦理解了索引背后的机制,那么选择高性能的策略就变成了纯粹的推理,并且可以理解这些策略背后的逻辑. 示例数据库 为了讨论索引策略,需要一个数据量不算小的数据库作为示例.本文选用MySQL官方文档中提供的示例数据库之一:employees.这个数据库关系复杂度适中,且数据量较大.下图是这个数据库的E-R关系图(引用自MySQL官方手册): 图12 MySQL官方文档中关于此数据库的页面为http://dev.mysql.com/doc/employee/en
-
MySQL使用索引优化性能
目录 1.索引问题 2.索引的存储分类 3.如何使用索引 3.1使用索引 3.2存在索引但不使用索引 4.查看索引使用情况 5.两个简单实用的优化方法 5.1定期分析表和检查表 5.2定期优化表 1.索引问题 索引是数据库优化中最常用也是最重要的手段之一,通过索引通常可以帮助用户解决大多数 的SQL性能问题.本章节将对MySQL中的索引的分类.存储.使用方法做详细的介绍. 2.索引的存储分类 MyISAM存储引擎的表数据和索引是自动分开存储的,各自是独立的一个文件:InnoDB存储引擎的表数据和
-
MySQL中索引优化distinct语句及distinct的多字段操作
MySQL通常使用GROUPBY(本质上是排序动作)完成DISTINCT操作,如果DISTINCT操作和ORDERBY操作组合使用,通常会用到临时表.这样会影响性能. 在一些情况下,MySQL可以使用索引优化DISTINCT操作,但需要活学活用.本文涉及一个不能利用索引完成DISTINCT操作的实例. 实例1 使用索引优化DISTINCT操作 create table m11 (a int, b int, c int, d int, primary key(a)) engine=INNODB;
-
深入了解MySQL中索引优化器的工作原理
目录 本文导读 一.MySQL 优化器是如何选择索引的 1.MySQL数据库组成 2.MySQL数据库成本计算 二.MySQL查询成本 三.SELECT 执行过程 总结 本文导读 本文将解读MySQL数据库查询优化器(CBO)的工作原理.简单介绍了MySQL Server的组成,MySQL优化器选择索引额原理以及SQL成本分析,最后通过 select 查询总结整个查询过程. 一.MySQL 优化器是如何选择索引的 下面我们来看这张表,SUB_ODR_ID字段创建了相关的 2 个索引,根据我们前面
-
MySQL利用索引优化ORDER BY排序语句的方法
创建表&创建索引 create table tbl1 ( id int unique, sname varchar(50), index tbl1_index_sname(sname desc) ); 在已有的表创建索引语法 create [unique|fulltext|spatial] index 索引名 on 表名(字段名 [长度] [asc|desc]); MySQL也能利用索引来快速地执行ORDER BY和GROUP BY语句的排序和分组操作. 通过索引优化来实现MySQL的ORDER
-
MySQL 通过索引优化含ORDER BY的语句
关于建立索引的几个准则: 1.合理的建立索引能够加速数据读取效率,不合理的建立索引反而会拖慢数据库的响应速度. 2.索引越多,更新数据的速度越慢. 3.尽量在采用MyIsam作为引擎的时候使用索引(因为MySQL以BTree存储索引),而不是InnoDB.但MyISAM不支持Transcation. 4.当你的程序和数据库结构/SQL语句已经优化到无法优化的程度,而程序瓶颈并不能顺利解决,那就是应该考虑使用诸如memcached这样的分布式缓存系统的时候了. 5.习惯和强迫自己用EXPLAIN来
-
浅谈MySQL索引优化分析
为什么你写的sql查询慢?为什么你建的索引常失效?通过本章内容,你将学会MySQL性能下降的原因,索引的简介,索引创建的原则,explain命令的使用,以及explain输出字段的意义.助你了解索引,分析索引,使用索引,从而写出更高性能的sql语句.还在等啥子?撸起袖子就是干! 案例分析 我们先简单了解一下非关系型数据库和关系型数据库的区别. MongoDB是NoSQL中的一种.NoSQL的全称是Not only SQL,非关系型数据库.它的特点是性能高,扩张性强,模式灵活,在高并发场景表现得尤
-
Mysql数据库之索引优化
MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能出色,但所谓"好马配好鞍",如何能够更好的使用它,已经成为开发工程师的必修课,我们经常会从职位描述上看到诸如"精通MySQL"."SQL语句优化"."了解数据库原理"等要求.我们知道一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,
-
浅谈MySQL的B树索引与索引优化小结
MySQL的MyISAM.InnoDB引擎默认均使用B+树索引(查询时都显示为"BTREE"),本文讨论两个问题: 为什么MySQL等主流数据库选择B+树的索引结构? 如何基于索引结构,理解常见的MySQL索引优化思路? 为什么索引无法全部装入内存 索引结构的选择基于这样一个性质:大数据量时,索引无法全部装入内存. 为什么索引无法全部装入内存?假设使用树结构组织索引,简单估算一下: 假设单个索引节点12B,1000w个数据行,unique索引,则叶子节点共占约100MB,整棵树最多20
-
MySQL性能全面优化方法参考,从CPU,文件系统选择到mysql.cnf参数优化
本文整理了一些MySQL的通用优化方法,做个简单的总结分享,旨在帮助那些没有专职MySQL DBA的企业做好基本的优化工作,至于具体的SQL优化,大部分通过加适当的索引即可达到效果,更复杂的就需要具体分析了,可以参考本站的一些优化案例或者联系我们 1.硬件层相关优化 1.1.CPU相关 在服务器的BIOS设置中,可调整下面的几个配置,目的是发挥CPU最大性能,或者避免经典的NUMA问题: 1.选择Performance Per Watt Optimized(DAPC)模式,发挥CPU最大性能,跑