keras训练浅层卷积网络并保存和加载模型实例
这里我们使用keras定义简单的神经网络全连接层训练MNIST数据集和cifar10数据集:
keras_mnist.py
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from keras.models import Sequential
from keras.layers.core import Dense
from keras.optimizers import SGD
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as np
import argparse
# 命令行参数运行
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True, help="path to the output loss/accuracy plot")
args =vars(ap.parse_args())
# 加载数据MNIST,然后归一化到【0,1】,同时使用75%做训练,25%做测试
print("[INFO] loading MNIST (full) dataset")
dataset = datasets.fetch_mldata("MNIST Original", data_home="/home/king/test/python/train/pyimagesearch/nn/data/")
data = dataset.data.astype("float") / 255.0
(trainX, testX, trainY, testY) = train_test_split(data, dataset.target, test_size=0.25)
# 将label进行one-hot编码
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# keras定义网络结构784--256--128--10
model = Sequential()
model.add(Dense(256, input_shape=(784,), activation="relu"))
model.add(Dense(128, activation="relu"))
model.add(Dense(10, activation="softmax"))
# 开始训练
print("[INFO] training network...")
# 0.01的学习率
sgd = SGD(0.01)
# 交叉验证
model.compile(loss="categorical_crossentropy", optimizer=sgd, metrics=['accuracy'])
H = model.fit(trainX, trainY, validation_data=(testX, testY), epochs=100, batch_size=128)
# 测试模型和评估
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=128)
print(classification_report(testY.argmax(axis=1), predictions.argmax(axis=1),
target_names=[str(x) for x in lb.classes_]))
# 保存可视化训练结果
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 100), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 100), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 100), H.history["acc"], label="train_acc")
plt.plot(np.arange(0, 100), H.history["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("# Epoch")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args["output"])
使用relu做激活函数:

使用sigmoid做激活函数:

接着我们自己定义一些modules去实现一个简单的卷基层去训练cifar10数据集:
imagetoarraypreprocessor.py
''' 该函数主要是实现keras的一个细节转换,因为训练的图像时RGB三颜色通道,读取进来的数据是有depth的,keras为了兼容一些后台,默认是按照(height, width, depth)读取,但有时候就要改变成(depth, height, width) ''' from keras.preprocessing.image import img_to_array class ImageToArrayPreprocessor: def __init__(self, dataFormat=None): self.dataFormat = dataFormat def preprocess(self, image): return img_to_array(image, data_format=self.dataFormat)
shallownet.py
'''
定义一个简单的卷基层:
input->conv->Relu->FC
'''
from keras.models import Sequential
from keras.layers.convolutional import Conv2D
from keras.layers.core import Activation, Flatten, Dense
from keras import backend as K
class ShallowNet:
@staticmethod
def build(width, height, depth, classes):
model = Sequential()
inputShape = (height, width, depth)
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
model.add(Conv2D(32, (3, 3), padding="same", input_shape=inputShape))
model.add(Activation("relu"))
model.add(Flatten())
model.add(Dense(classes))
model.add(Activation("softmax"))
return model
然后就是训练代码:
keras_cifar10.py
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from shallownet import ShallowNet
from keras.optimizers import SGD
from keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
import argparse
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True, help="path to the output loss/accuracy plot")
args = vars(ap.parse_args())
print("[INFO] loading CIFAR-10 dataset")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# 标签0-9代表的类别string
labelNames = ['airplane', 'automobile', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
print("[INFO] compiling model...")
opt = SGD(lr=0.0001)
model = ShallowNet.build(width=32, height=32, depth=3, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])
print("[INFO] training network...")
H = model.fit(trainX, trainY, validation_data=(testX, testY), batch_size=32, epochs=1000, verbose=1)
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32)
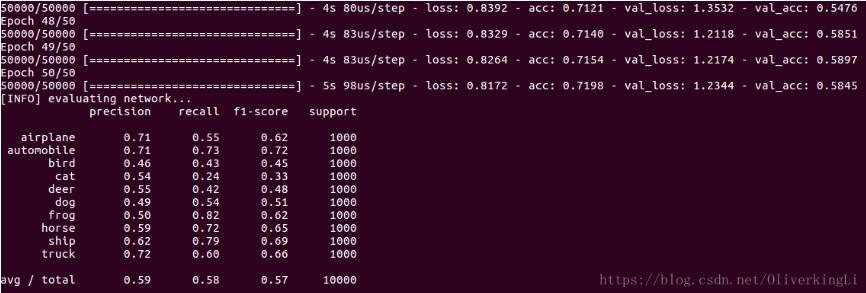
print(classification_report(testY.argmax(axis=1), predictions.argmax(axis=1),
target_names=labelNames))
# 保存可视化训练结果
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 1000), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 1000), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 1000), H.history["acc"], label="train_acc")
plt.plot(np.arange(0, 1000), H.history["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("# Epoch")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args["output"])
代码中可以对训练的learning rate进行微调,大概可以接近60%的准确率。

然后修改下代码可以保存训练模型:
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from shallownet import ShallowNet
from keras.optimizers import SGD
from keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
import argparse
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True, help="path to the output loss/accuracy plot")
ap.add_argument("-m", "--model", required=True, help="path to save train model")
args = vars(ap.parse_args())
print("[INFO] loading CIFAR-10 dataset")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# 标签0-9代表的类别string
labelNames = ['airplane', 'automobile', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
print("[INFO] compiling model...")
opt = SGD(lr=0.005)
model = ShallowNet.build(width=32, height=32, depth=3, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])
print("[INFO] training network...")
H = model.fit(trainX, trainY, validation_data=(testX, testY), batch_size=32, epochs=50, verbose=1)
model.save(args["model"])
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1), predictions.argmax(axis=1),
target_names=labelNames))
# 保存可视化训练结果
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 5), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 5), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 5), H.history["acc"], label="train_acc")
plt.plot(np.arange(0, 5), H.history["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("# Epoch")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args["output"])
命令行运行:

我们使用另一个程序来加载上一次训练保存的模型,然后进行测试:
test.py
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from shallownet import ShallowNet
from keras.optimizers import SGD
from keras.datasets import cifar10
from keras.models import load_model
import matplotlib.pyplot as plt
import numpy as np
import argparse
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True, help="path to save train model")
args = vars(ap.parse_args())
# 标签0-9代表的类别string
labelNames = ['airplane', 'automobile', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
print("[INFO] loading CIFAR-10 dataset")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
idxs = np.random.randint(0, len(testX), size=(10,))
testX = testX[idxs]
testY = testY[idxs]
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
print("[INFO] loading pre-trained network...")
model = load_model(args["model"])
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32).argmax(axis=1)
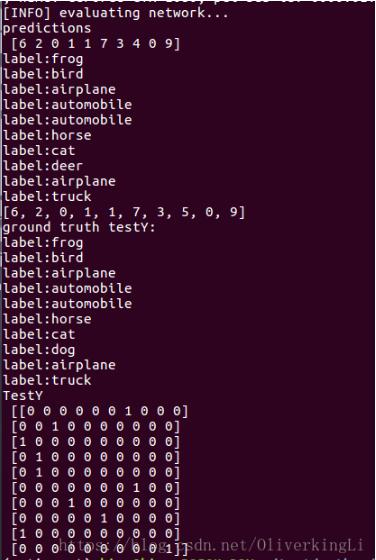
print("predictions\n", predictions)
for i in range(len(testY)):
print("label:{}".format(labelNames[predictions[i]]))
trueLabel = []
for i in range(len(testY)):
for j in range(len(testY[i])):
if testY[i][j] != 0:
trueLabel.append(j)
print(trueLabel)
print("ground truth testY:")
for i in range(len(trueLabel)):
print("label:{}".format(labelNames[trueLabel[i]]))
print("TestY\n", testY)
以上这篇keras训练浅层卷积网络并保存和加载模型实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
keras 如何保存最佳的训练模型
1.只保存最佳的训练模型 2.保存有所有有提升的模型 3.加载模型 4.参数说明 只保存最佳的训练模型 from keras.callbacks import ModelCheckpoint filepath='weights.best.hdf5' # 有一次提升, 则覆盖一次. checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=1,save_best_only=True,mode='max',period=2)
-
Keras 实现加载预训练模型并冻结网络的层
在解决一个任务时,我会选择加载预训练模型并逐步fine-tune.比如,分类任务中,优异的深度学习网络有很多. ResNet, VGG, Xception等等... 并且这些模型参数已经在imagenet数据集中训练的很好了,可以直接拿过来用. 根据自己的任务,训练一下最后的分类层即可得到比较好的结果.此时,就需要"冻结"预训练模型的所有层,即这些层的权重永不会更新. 以Xception为例: 加载预训练模型: from tensorflow.python.keras.applicat
-
使用Keras构造简单的CNN网络实例
1. 导入各种模块 基本形式为: import 模块名 from 某个文件 import 某个模块 2. 导入数据(以两类分类问题为例,即numClass = 2) 训练集数据data 可以看到,data是一个四维的ndarray 训练集的标签 3. 将导入的数据转化我keras可以接受的数据格式 keras要求的label格式应该为binary class matrices,所以,需要对输入的label数据进行转化,利用keras提高的to_categorical函数 label = np_u
-
在Keras中实现保存和加载权重及模型结构
1. 保存和加载模型结构 (1)保存为JSON字串 json_string = model.to_json() (2)从JSON字串重构模型 from keras.models import model_from_json model = model_from_json(json_string) (3)保存为YAML字串 yaml_string = model.to_yaml() (4)从YAML字串重构模型 model = model_from_yaml(yaml_string) 2. 保存和
-
keras训练浅层卷积网络并保存和加载模型实例
这里我们使用keras定义简单的神经网络全连接层训练MNIST数据集和cifar10数据集: keras_mnist.py from sklearn.preprocessing import LabelBinarizer from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from keras.models import Sequential
-
基于pytorch的保存和加载模型参数的方法
当我们花费大量的精力训练完网络,下次预测数据时不想再(有时也不必再)训练一次时,这时候torch.save(),torch.load()就要登场了. 保存和加载模型参数有两种方式: 方式一: torch.save(net.state_dict(),path): 功能:保存训练完的网络的各层参数(即weights和bias) 其中:net.state_dict()获取各层参数,path是文件存放路径(通常保存文件格式为.pt或.pth) net2.load_state_dict(torch.loa
-
pytorch模型的保存和加载、checkpoint操作
其实之前笔者写代码的时候用到模型的保存和加载,需要用的时候就去度娘搜一下大致代码,现在有时间就来整理下整个pytorch模型的保存和加载,开始学习把~ pytorch的模型和参数是分开的,可以分别保存或加载模型和参数.所以pytorch的保存和加载对应存在两种方式: 1. 直接保存加载模型 (1)保存和加载整个模型 # 保存模型 torch.save(model, 'model.pth\pkl\pt') #一般形式torch.save(net, PATH) # 加载模型 model = torc
-
Pytorch模型参数的保存和加载
目录 一.前言 二.参数保存 三.参数的加载 四.保存和加载整个模型 五.总结 一.前言 在模型训练完成后,我们需要保存模型参数值用于后续的测试过程.由于保存整个模型将耗费大量的存储,故推荐的做法是只保存参数,使用时只需在建好模型的基础上加载. 通常来说,保存的对象包括网络参数值.优化器参数值.epoch值等.本文将简单介绍保存和加载模型参数的方法,同时也给出保存整个模型的方法供大家参考. 二.参数保存 在这里我们使用 torch.save() 函数保存模型参数: import torch pa
-
解决tensorflow模型参数保存和加载的问题
终于找到bug原因!记一下:还是不熟悉平台的原因造成的! Q:为什么会出现两个模型对象在同一个文件中一起运行,当直接读取他们分开运行时训练出来的模型会出错,而且总是有一个正确,一个读取错误? 而 直接在同一个文件又训练又重新加载模型预测不出错,而且更诡异的是此时用分文件里的对象加载模型不会出错? model.py,里面含有 ModelV 和 ModelP,另外还有 modelP.py 和 modelV.py 分别只含有 ModelP 和 ModeV 这两个对象,先使用 modelP.py 和 m
-

PyTorch深度学习模型的保存和加载流程详解
一.模型参数的保存和加载 torch.save(module.state_dict(), path):使用module.state_dict()函数获取各层已经训练好的参数和缓冲区,然后将参数和缓冲区保存到path所指定的文件存放路径(常用文件格式为.pt..pth或.pkl). torch.nn.Module.load_state_dict(state_dict):从state_dict中加载参数和缓冲区到Module及其子类中 . torch.nn.Module.state_dict()函数
-
Tensorflow2.1 完成权重或模型的保存和加载
目录 前言 实现方法 1. 读取数据 2. 搭建深度学习模型 3. 使用回调函数在每个 epoch 后自动保存模型权重 4. 使用回调函数每经过 5 个 epoch 对模型权重保存一次 5. 手动保存模型权重到指定目录 6. 手动保存整个模型结构和权重 前言 本文主要使用 cpu 版本的 tensorflow-2.1 来完成深度学习权重参数/模型的保存和加载操作. 在我们进行项目期间,很多时候都要在模型训练期间.训练结束之后对模型或者模型权重进行保存,然后我们可以从之前停止的地方恢复原模型效果继
-
pytorch模型的保存加载与续训练详解
目录 前面 模型保存与加载 方式1 方式2 方式3 总结 前面 最近,看到不少小伙伴问pytorch如何保存和加载模型,其实这部分pytorch官网介绍的也是很清楚的,感兴趣的点击了解详情
-
PyTorch模型的保存与加载方法实例
目录 模型的保存与加载 保存和加载模型参数 保存和加载模型参数与结构 总结 模型的保存与加载 首先,需要导入两个包 import torch import torchvision.models as models 保存和加载模型参数 PyTorch模型将学习到的参数存储在一个内部状态字典中,叫做state_dict.这可以通过torch.save方法来实现.我们导入预训练好的VGG16模型,并将其保存.我们将state_dict字典保存在model_weights.pth文件中. model =