Python爬取网站图片并保存的实现示例
先看看结果吧,去bilibili上拿到的图片=-=

第一步,导入模块
import requests from bs4 import BeautifulSoup
requests用来请求html页面,BeautifulSoup用来解析html
第二步,获取目标html页面
hd = {'user-agent': 'chrome/10'} # 伪装自己是个(chrome)浏览器=-=
def download_all_html():
try:
url = 'https://www.bilibili.com/' # 将要爬取网站的地址
request = requests.get(url, timeout=30, headers=hd) # 获取改网站的信息
request.raise_for_status() # 判断状态码是否为200,!=200显然爬取失败
request.encoding = request.apparent_encoding # 设置编码格式
return request.text # 返回html页面
except:
return ''
第三步,分析网站html构造
1、显示网站html代码

2、找到图片位置
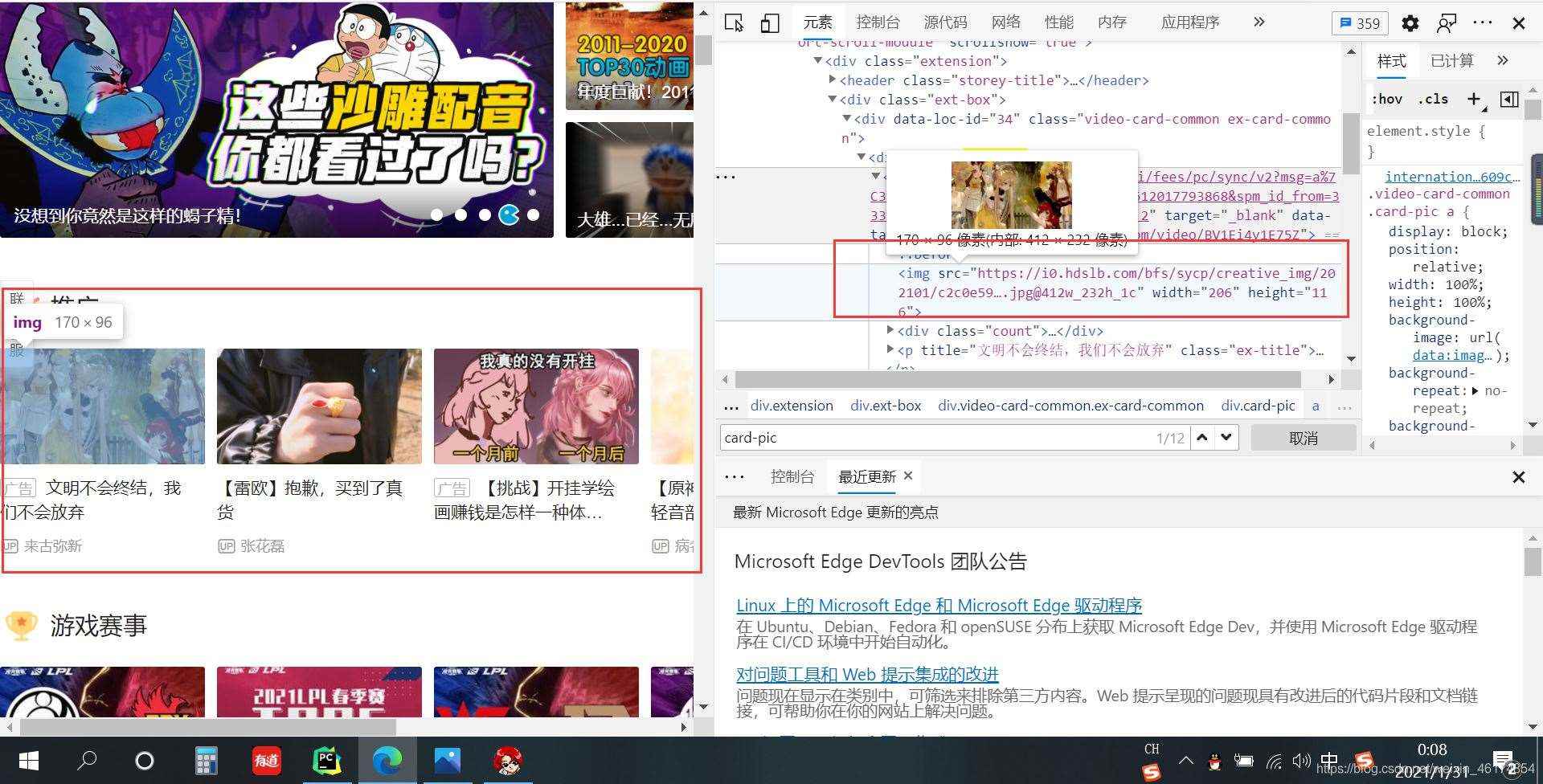
3、分析


第四步,直接上代码注释够详细=-=
def parse_single_html(html):
soup = BeautifulSoup(html, 'html.parser') # 解析html,可以单独去了解一下他的使用
divs = soup.find_all('div', class_='card-pic') # 获取满足条件的div,find_all(所有)
for div in divs: # 瞒住条件的div有多个,我们单独获取
p = div.find('p') # 有源代码可知,每个div下都有一个p标签,存储图片的title,获取p标签
if p == None:
continue
title = p['title'] # 获取p标签中的title属性,用来做图片的名称
img = div.find('img')['src'] # 获取图片的地址
if img[0:6] != 'https:': # 根据源代码发现,有的地址缺少"https:"前缀
img = 'https:' + img # 如果缺少,我们给他添上就行啦,都据情况而定
response = requests.get(img) # get方法得到图片地址(有的是post、put)基本是get
with open('./Img/{}.png'.format(title), 'wb') as f: # 创建用来保存图片的.png文件
f.write(response.content) # 注意,'wb'中的b 必不可少!!
parse_single_html(download_all_html()) # 最后调用我们写的两个函数就行啦,

查看结果
到此这篇关于Python爬取网站图片并保存的实现示例的文章就介绍到这了,更多相关Python爬取图片保存内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python使用mongodb保存爬取豆瓣电影的数据过程解析
创建爬虫项目douban scrapy startproject douban 设置items.py文件,存储要保存的数据类型和字段名称 # -*- coding: utf-8 -*- import scrapy class DoubanItem(scrapy.Item): title = scrapy.Field() # 内容 content = scrapy.Field() # 评分 rating_num = scrapy.Field() # 简介 quote = scrapy.Field(
-
Python3实现爬取指定百度贴吧页面并保存页面数据生成本地文档的方法
分享给大家供大家参考,具体如下:Python3实现爬取指定百度贴吧页面并保存页面数据生成本地文档的方法.分享给大家供大家参考,具体如下: 首先我们创建一个python文件, tieba.py,我们要完成的是,输入指定百度贴吧名字与指定页面范围之后爬取页面html代码,我们首先观察贴吧url的规律,比如: 百度贴吧LOL吧第一页:http://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=0 第二页: http://tieba.baidu.com/f?kw=lol
-
Python3直接爬取图片URL并保存示例
有时候我们会需要从网络上爬取一些图片,来满足我们形形色色直至不可描述的需求. 一个典型的简单爬虫项目步骤包括两步:获取网页地址和提取保存数据. 这里是一个简单的从图片url收集图片的例子,可以成为一个小小的开始. 获取地址 这些图片的URL可能是连续变化的,如从001递增到099,这种情况可以在程序中将共同的前面部分截取,再在最后递增并字符串化后循环即可. 抑或是它们的URL都保存在某个文件中,这时可以读取到列表中: def getUrls(path): urls = [] with open(
-

python requests库爬取豆瓣电视剧数据并保存到本地详解
首先要做的就是去豆瓣网找对应的接口,这里就不赘述了,谷歌浏览器抓包即可,然后要做的就是分析返回的json数据的结构: https://movie.douban.com/j/search_subjects?type=tv&tag=%E5%9B%BD%E4%BA%A7%E5%89%A7&sort=recommend&page_limit=20&page_start=0 这是接口地址,可以大概的分析一下各个参数的规则: type=tv,表示的是电视剧的分类 tag=国产剧,表示是
-
python爬取网站数据保存使用的方法
编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了.问题要从文字的编码讲起.原本的英文编码只有0~255,刚好是8位1个字节.为了表示各种不同的语言,自然要进行扩充.中文的话有GB系列.可能还听说过Unicode和UTF-8,那么,它们之间是什么关系呢?Unicode是一种编码方案,又称万国码,可见其包含之广.但是具体存储到计算机上,并不用这种编码,可以说它起着一个中间人的作用.你可以再把Unicode编码(encode)为UTF-8,或者GB,再存储到计算机
-
Python爬取YY评级分数并保存数据实现过程解析
前言 当需要进行大规模查询时(比如目前遇到的情形:查询某个省所有发债企业的YY评级分数),人工查询显然太过费时,那就写个爬虫吧. 由于该爬虫实在过于简单,就只简单概述下. 一.请求端 通过观察YY评级的网页信息,如下图(F12或右击进入检查,点击network->XHR->headers). 红色框表明是个get请求(其实这种网页基本都是Ajax get,需要总结实际url的规律的). 绿色框即为实际URL,通过分析该URL,其由两部分组成.前半部分为" https://web.ra
-
Python爬取数据保存为Json格式的代码示例
python爬取数据保存为Json格式 代码如下: #encoding:'utf-8' import urllib.request from bs4 import BeautifulSoup import os import time import codecs import json #找到网址 def getDatas(): # 伪装 header={'User-Agent':"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.1
-
Python3爬虫学习之将爬取的信息保存到本地的方法详解
本文实例讲述了Python3爬虫学习之将爬取的信息保存到本地的方法.分享给大家供大家参考,具体如下: 将爬取的信息存储到本地 之前我们都是将爬取的数据直接打印到了控制台上,这样显然不利于我们对数据的分析利用,也不利于保存,所以现在就来看一下如何将爬取的数据存储到本地硬盘. 1 对.txt文件的操作 读写文件是最常见的操作之一,python3 内置了读写文件的函数:open open(file, mode='r', buffering=-1, encoding=None, errors=None,
-
Python 爬虫批量爬取网页图片保存到本地的实现代码
其实和爬取普通数据本质一样,不过我们直接爬取数据会直接返回,爬取图片需要处理成二进制数据保存成图片格式(.jpg,.png等)的数据文本. 现在贴一个url=https://img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-001.jpg 请复制上面的url直接在某个浏览器打开,你会看到如下内容: 这就是通过网页访问到的该网站的该图片,于是我们可以直接利用requests模块,进行这个图片的请求,于是这个网站便会返回给我们该图片的数据,我们
-
Python爬取网站图片并保存的实现示例
先看看结果吧,去bilibili上拿到的图片=-= 第一步,导入模块 import requests from bs4 import BeautifulSoup requests用来请求html页面,BeautifulSoup用来解析html 第二步,获取目标html页面 hd = {'user-agent': 'chrome/10'} # 伪装自己是个(chrome)浏览器=-= def download_all_html(): try: url = 'https://www.bilibili
-
Python爬虫爬取网站图片
此次python3主要用requests,解析图片网址主要用beautiful soup,可以基本完成爬取图片功能, 爬虫这个当然大多数人入门都是爬美女图片,我当然也不落俗套,首先也是随便找了个网址爬美女图片 from bs4 import BeautifulSoup import requests if __name__=='__main__': url='http://www.27270.com/tag/649.html' headers = { "U
-
Python 爬取网页图片详解流程
简介 快乐在满足中求,烦恼多从欲中来 记录程序的点点滴滴. 输入一个网址从这个网址中解析出图片,并将它保存在本地 流程图 程序分析 解析主网址 def get_urls(): url = 'http://www.nipic.com/show/35350678.html' # 主网址 pattern = "(http.*?jpg)" header = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKi
-
Node.js实现爬取网站图片的示例代码
目录 涉及知识点 cheerio简介 什么是cheerio ? 安装cheerio 准备工作 核心代码 示例截图 涉及知识点 开发一个小爬虫,涉及的知识点如下所示: https模块,主要是用户获取网络资源,如:网页源码,图片资源等. cheerio模块,主要用于解析html源码,并可访问,查找html节点内容. fs模块,主要用于文件的读写操作,如保存图片,日志等. 闭包,主要是对于异步操作,对象的隔离保护. cheerio简介 什么是cheerio ? cheerio是为服务器特别定制的,快速
-
php抓取网站图片并保存的实现方法
php如何实现抓取网页图片,相较于手动的粘贴复制,使用小程序要方便快捷多了,喜欢编程的人总会喜欢制作一些简单有用的小软件,最近就参考了网上一个php抓取图片代码,封装了一个php远程抓取图片的类,测试了一下,效果还不错分享给大家,代码如下: 以上就是为大家分享的php抓取网站图片并保存的实现方法,希望对大家的学习有所帮助.
-
nodejs实现爬取网站图片功能
通过实例给大家讲解nodejs实现爬取网站图片功能,以下就是全部内容: 原理: 爬虫是最明显的IO密集型应用场景,显然用node,使得I/O等待开销小数据挖掘比较方便 借助express模块来搭建node服务 并使用request模块获取目标页面的html代码 下载cheerio模块对html代码做处理(cheerio类似jQuery的语法,所以好用又方便) 环境配置: npm install express request cheerio --save (1)引入各个模块 var http =
-
PHP封装的远程抓取网站图片并保存功能类
本文实例讲述了PHP封装的远程抓取网站图片并保存功能类.分享给大家供大家参考,具体如下: <?php /** * 一个用于抓取图片的类 * * @package default * @author WuJunwei */ class download_image { public $save_path; //抓取图片的保存地址 //抓取图片的大小限制(单位:字节) 只抓比size比这个限制大的图片 public $img_size=0; //定义一个静态数组,用于记录曾经抓取过的的超链接地址,避
-
python 爬取英雄联盟皮肤并下载的示例
爬取结果: 爬取代码 import os import json import requests from tqdm import tqdm def lol_spider(): # 存放英雄信息 heros = [] # 存放英雄皮肤 hero_skins = [] # 获取所有英雄信息 url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js' hero_text = requests.get(url).t
-
Python爬取股票信息,并可视化数据的示例
前言 截止2019年年底我国股票投资者数量为15975.24万户, 如此多的股民热衷于炒股,首先抛开炒股技术不说, 那么多股票数据是不是非常难找, 找到之后是不是看着密密麻麻的数据是不是头都大了? 今天带大家爬取雪球平台的股票数据, 并且实现数据可视化 先看下效果图 基本环境配置 python 3.6 pycharm requests csv time 目标地址 https://xueqiu.com/hq 爬虫代码 请求网页 import requests url = 'https://xueq