Python3 pandas.concat的用法说明
前面给大家分享了pandas.merge用法详解,这节分享pandas数据合并处理的姊妹篇,pandas.concat用法详解,参考利用Python进行数据分析与pandas官网进行整理。
pandas.merge参数列表如下图,其中只有objs是必须得参数,另外常用参数包括objs、axis、join、keys、ignore_index。

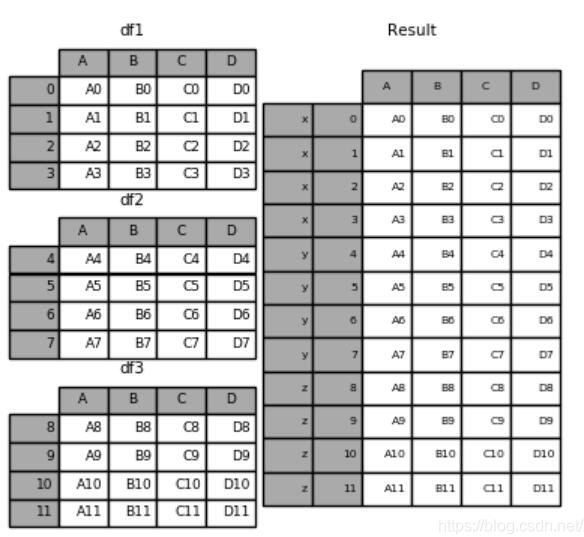
1.pd.concat([df1,df2,df3]), 默认axis=0,在0轴上合并。

2.pd.concat([df1,df4],axis=1)–在1轴上合并
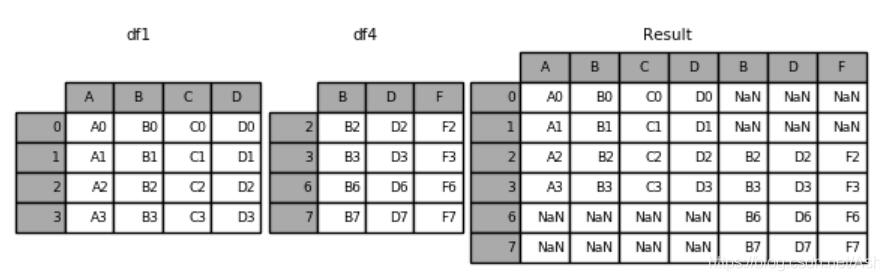
3.pd.concat([df1,df2,df3],keys=[‘x', ‘y', ‘z'])–合并时便于区分建立层次化索引。
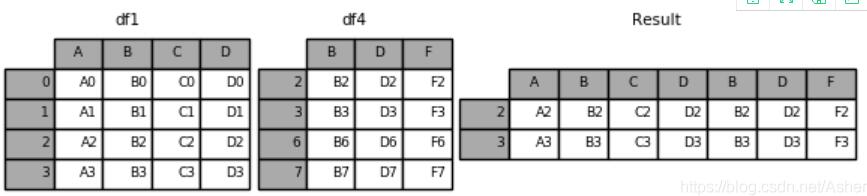
4.pd.concat([df1, df4], axis=1, join=‘inner')–采用内连接合并,join默认为outer外连接。
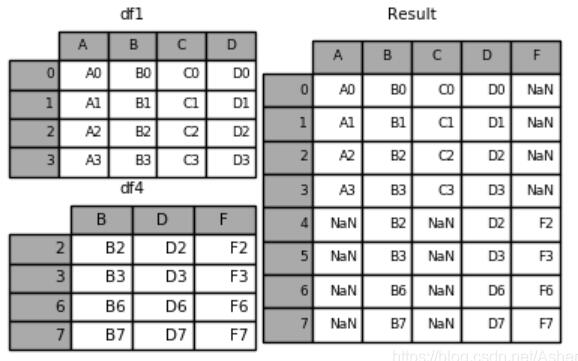
5.pd.concat([df1, df4], ignore_index=True)–当原来DataFrame的索引没有意义的时候,concat之后可以不需要原来的索引。
姊妹篇:pandas.merge用法详解!!!
补充:python3:pandas(合并concat和merge)
pandas处理多组数据的时候往往会要用到数据的合并处理,其中有三种方式,concat、append和merge。
1、concat
用concat是一种基本的合并方式。而且concat中有很多参数可以调整,合并成你想要的数据形式。axis来指明合并方向。axis=0是预设值,因此未设定任何参数时,函数默认axis=0。(0表示上下合并,1表示左右合并)
import pandas as pd import numpy as np #定义资料集 df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d']) df2 = pd.DataFrame(np.ones((3,4))*1, columns=['a','b','c','d']) df3 = pd.DataFrame(np.ones((3,4))*2, columns=['a','b','c','d']) #concat纵向合并 res = pd.concat([df1, df2, df3], axis=0) #打印结果 print(res) ''' a b c d 0 0.0 0.0 0.0 0.0 1 0.0 0.0 0.0 0.0 2 0.0 0.0 0.0 0.0 0 1.0 1.0 1.0 1.0 1 1.0 1.0 1.0 1.0 2 1.0 1.0 1.0 1.0 0 2.0 2.0 2.0 2.0 1 2.0 2.0 2.0 2.0 2 2.0 2.0 2.0 2.0 '''
上述index为0,1,2,0,1,2形式。为什么会出现这样的情况,其实是仍然按照合并前的index组合起来的。若希望递增,请看下面示例:
ignore_index (重置 index)
重置后的index为0,1,……8
res = pd.concat([df1, df2, df3], axis=0, ignore_index=True)# 将ignore_index设置为True print(res) #打印结果 ''' a b c d 0 0.0 0.0 0.0 0.0 1 0.0 0.0 0.0 0.0 2 0.0 0.0 0.0 0.0 3 1.0 1.0 1.0 1.0 4 1.0 1.0 1.0 1.0 5 1.0 1.0 1.0 1.0 6 2.0 2.0 2.0 2.0 7 2.0 2.0 2.0 2.0 8 2.0 2.0 2.0 2.0 '''
join (合并方式)
join='outer'为预设值,因此未设定任何参数时,函数默认join='outer'。此方式是依照column来做纵向合并,有相同的column上下合并在一起,其他独自的column个自成列,原本没有值的位置皆以NaN填充。
import pandas as pd import numpy as np #定义资料集 df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'], index=[1,2,3]) df2 = pd.DataFrame(np.ones((3,4))*1, columns=['b','c','d','e'], index=[2,3,4]) res = pd.concat([df1, df2], axis=0, join='outer') #纵向"外"合并df1与df2 print(res) ''' a b c d e 1 0.0 0.0 0.0 0.0 NaN 2 0.0 0.0 0.0 0.0 NaN 3 0.0 0.0 0.0 0.0 NaN 2 NaN 1.0 1.0 1.0 1.0 3 NaN 1.0 1.0 1.0 1.0 4 NaN 1.0 1.0 1.0 1.0 ''' res = pd.concat([df1, df2], axis=0, join='inner') #纵向"内"合并df1与df2 #打印结果 print(res) ''' b c d 1 0.0 0.0 0.0 2 0.0 0.0 0.0 3 0.0 0.0 0.0 2 1.0 1.0 1.0 3 1.0 1.0 1.0 4 1.0 1.0 1.0 '''
join_axes (依照 axes 合并)
import pandas as pd import numpy as np #定义资料集 df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'], index=[1,2,3]) df2 = pd.DataFrame(np.ones((3,4))*1, columns=['b','c','d','e'], index=[2,3,4]) #依照`df1.index`进行横向合并 res = pd.concat([df1, df2], axis=1, join_axes=[df1.index]) #打印结果 print(res) # a b c d b c d e # 1 0.0 0.0 0.0 0.0 NaN NaN NaN NaN # 2 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0 # 3 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
上述脚本中,join_axes=[df1.index]表明按照df1的index来合并,可以看到结果中去掉了df2中出现但df1中没有的index=4这一行。
2、append (添加数据)
append只有纵向合并,没有横向合并。
import pandas as pd import numpy as np #定义资料集 df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d']) df2 = pd.DataFrame(np.ones((3,4))*1, columns=['a','b','c','d']) df3 = pd.DataFrame(np.ones((3,4))*1, columns=['a','b','c','d']) s1 = pd.Series([1,2,3,4], index=['a','b','c','d']) #将df2合并到df1的下面,以及重置index,并打印出结果 res = df1.append(df2, ignore_index=True) print(res) # a b c d # 0 0.0 0.0 0.0 0.0 # 1 0.0 0.0 0.0 0.0 # 2 0.0 0.0 0.0 0.0 # 3 1.0 1.0 1.0 1.0 # 4 1.0 1.0 1.0 1.0 # 5 1.0 1.0 1.0 1.0 #合并多个df,将df2与df3合并至df1的下面,以及重置index,并打印出结果 res = df1.append([df2, df3], ignore_index=True) print(res) # a b c d # 0 0.0 0.0 0.0 0.0 # 1 0.0 0.0 0.0 0.0 # 2 0.0 0.0 0.0 0.0 # 3 1.0 1.0 1.0 1.0 # 4 1.0 1.0 1.0 1.0 # 5 1.0 1.0 1.0 1.0 # 6 1.0 1.0 1.0 1.0 # 7 1.0 1.0 1.0 1.0 # 8 1.0 1.0 1.0 1.0 #合并series,将s1合并至df1,以及重置index,并打印出结果 res = df1.append(s1, ignore_index=True) print(res) # a b c d # 0 0.0 0.0 0.0 0.0 # 1 0.0 0.0 0.0 0.0 # 2 0.0 0.0 0.0 0.0 # 3 1.0 2.0 3.0 4.0
3、merge
根据两组数据中的关键字key来合并(key在两组数据中是完全一致的)。
3.1依据一组key合并
import pandas as pd
#定义资料集并打印出
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
print(left)
# A B key
# 0 A0 B0 K0
# 1 A1 B1 K1
# 2 A2 B2 K2
# 3 A3 B3 K3
print(right)
# C D key
# 0 C0 D0 K0
# 1 C1 D1 K1
# 2 C2 D2 K2
# 3 C3 D3 K3
#依据key column合并,并打印出
res = pd.merge(left, right, on='key')
print(res)
A B key C D
# 0 A0 B0 K0 C0 D0
# 1 A1 B1 K1 C1 D1
# 2 A2 B2 K2 C2 D2
# 3 A3 B3 K3 C3 D3
3.2 根据两组key合并
合并时有4种方法how = ['left', 'right', 'outer', 'inner'],预设值how='inner'。
inner:按照关键字组合之后,去掉组合中有合并项为NaN的行。
outer :保留所有组合
left:仅保留左边合并项为NaN的行
right:仅保留右边合并项为NaN的行
import pandas as pd
import numpy as np
#定义资料集并打印出
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
print(left)
'''
key1 key2 A B
0 K0 K0 A0 B0
1 K0 K1 A1 B1
2 K1 K0 A2 B2
3 K2 K1 A3 B3
'''
print(right)
'''
key1 key2 C D
0 K0 K0 C0 D0
1 K1 K0 C1 D1
2 K1 K0 C2 D2
3 K2 K0 C3 D3
'''
#依据key1与key2 columns进行合并,并打印出四种结果['left', 'right', 'outer', 'inner']
res = pd.merge(left, right, on=['key1', 'key2'], how='inner')
print(res)
'''
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
'''
res = pd.merge(left, right, on=['key1', 'key2'], how='outer')
print(res)
'''
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K0 K1 A1 B1 NaN NaN
2 K1 K0 A2 B2 C1 D1
3 K1 K0 A2 B2 C2 D2
4 K2 K1 A3 B3 NaN NaN
5 K2 K0 NaN NaN C3 D3
'''
res = pd.merge(left, right, on=['key1', 'key2'], how='left')
print(res)
'''
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K0 K1 A1 B1 NaN NaN
2 K1 K0 A2 B2 C1 D1
3 K1 K0 A2 B2 C2 D2
4 K2 K1 A3 B3 NaN NaN
'''
res = pd.merge(left, right, on=['key1', 'key2'], how='right')
print(res)
'''
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
3 K2 K0 NaN NaN C3 D3
'''
3.3 Indicator
indicator=True会将合并的记录放在新的一列。
import pandas as pd
#定义资料集并打印出
df1 = pd.DataFrame({'col1':[0,1], 'col_left':['a','b']})
df2 = pd.DataFrame({'col1':[1,2,2],'col_right':[2,2,2]})
print(df1)
# col1 col_left
# 0 0 a
# 1 1 b
print(df2)
# col1 col_right
# 0 1 2
# 1 2 2
# 2 2 2
# 依据col1进行合并,并启用indicator=True,最后打印出
res = pd.merge(df1, df2, on='col1', how='outer', indicator=True)
print(res)
# col1 col_left col_right _merge
# 0 0.0 a NaN left_only
# 1 1.0 b 2.0 both
# 2 2.0 NaN 2.0 right_only
# 3 2.0 NaN 2.0 right_only
# 自定indicator column的名称,并打印出
res = pd.merge(df1, df2, on='col1', how='outer', indicator='indicator_column')
print(res)
# col1 col_left col_right indicator_column
# 0 0.0 a NaN left_only
# 1 1.0 b 2.0 both
# 2 2.0 NaN 2.0 right_only
# 3 2.0 NaN 2.0 right_only
3.4 依据index合并
import pandas as pd
#定义资料集并打印出
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=['K0', 'K2', 'K3'])
print(left)
# A B
# K0 A0 B0
# K1 A1 B1
# K2 A2 B2
print(right)
# C D
# K0 C0 D0
# K2 C2 D2
# K3 C3 D3
#依据左右资料集的index进行合并,how='outer',并打印出
res = pd.merge(left, right, left_index=True, right_index=True, how='outer')
print(res)
# A B C D
# K0 A0 B0 C0 D0
# K1 A1 B1 NaN NaN
# K2 A2 B2 C2 D2
# K3 NaN NaN C3 D3
#依据左右资料集的index进行合并,how='inner',并打印出
res = pd.merge(left, right, left_index=True, right_index=True, how='inner')
print(res)
# A B C D
# K0 A0 B0 C0 D0
# K2 A2 B2 C2 D2
3.5 解决overlapping的问题
下面脚本中,boys和girls均有属性age,但是两者值不同,因此需要在合并时加上后缀suffixes,以示区分。
import pandas as pd
#定义资料集
boys = pd.DataFrame({'k': ['K0', 'K1', 'K2'], 'age': [1, 2, 3]})
girls = pd.DataFrame({'k': ['K0', 'K0', 'K3'], 'age': [4, 5, 6]})
#使用suffixes解决overlapping的问题
res = pd.merge(boys, girls, on='k', suffixes=['_boy', '_girl'], how='inner')
print(res)
# age_boy k age_girl
# 0 1 K0 4
# 1 1 K0 5
以上是pandas中有关于合并的一些操作。当然,如果练习的多了,几个方法也是大同小异。希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
详解pandas数据合并与重塑(pd.concat篇)
1 concat concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合 pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False) 参数说明 objs: series,dataframe或者是panel构成的序列lsit axis: 需要合并链接的轴,0是行,1是列
-
详解Python3 pandas.merge用法
摘要 数据分析与建模的时候大部分时间在数据准备上,包括对数据的加载.清理.转换以及重塑.pandas提供了一组高级的.灵活的.高效的核心函数,能够轻松的将数据规整化.这节主要对pandas合并数据集的merge函数进行详解.(用过SQL或其他关系型数据库的可能会对这个方法比较熟悉.)码字不易,喜欢请点赞!!! 1.merge函数的参数一览表 2.创建两个DataFrame 3.pd.merge()方法设置连接字段. 默认参数how是inner内连接,并且会按照相同的字段key进行合并,即等价于o
-
Python使用Pandas库常见操作详解
本文实例讲述了Python使用Pandas库常见操作.分享给大家供大家参考,具体如下: 1.概述 Pandas 是Python的核心数据分析支持库,提供了快速.灵活.明确的数据结构,旨在简单.直观地处理关系型.标记型数据.Pandas常用于处理带行列标签的矩阵数据.与 SQL 或 Excel 表类似的表格数据,应用于金融.统计.社会科学.工程等领域里的数据整理与清洗.数据分析与建模.数据可视化与制表等工作. 数据类型:Pandas 不改变原始的输入数据,而是复制数据生成新的对象,有普通对象构成的
-
pandas的连接函数concat()函数的具体使用方法
concat()函数的具体用法 pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True) 参数含义 objs:Series,DataFrame或Panel对象的序列或映射.如果传递了dict,则排序的键将用作键参数,除非它被传递,在这种情况下,将选择值(见下文).任何
-

Python3 pandas.concat的用法说明
前面给大家分享了pandas.merge用法详解,这节分享pandas数据合并处理的姊妹篇,pandas.concat用法详解,参考利用Python进行数据分析与pandas官网进行整理. pandas.merge参数列表如下图,其中只有objs是必须得参数,另外常用参数包括objs.axis.join.keys.ignore_index. 1.pd.concat([df1,df2,df3]), 默认axis=0,在0轴上合并. 2.pd.concat([df1,df4],axis=1)–在1轴
-
pandas.DataFrame.drop_duplicates 用法介绍
如下所示: DataFrame.drop_duplicates(subset=None, keep='first', inplace=False) subset考虑重复发生在哪一列,默认考虑所有列,就是在任何一列上出现重复都算作是重复数据 keep 包含三个参数first, last, False,first是指,保留搜索到的第一个重复数据,之后的都删除:last是指,保留搜索到的最后一个重复数据,之前的搜索到的重复数据都删除,False是指,把所有搜索到的重复数据都删除,一个都不保留,即如果有
-
Python2和Python3中print的用法示例总结
前言 最近在学习python,对于python的print一直很恼火,老是不按照预期输出.在python2中print是一种输出语句,和if语句,while语句一样的东西,在python3中为了填补python2的各种坑,将print变为函数,因此导致python3中print的一些使用和python2很不一样.下面就来给大家详细的总结了关于Python2和Python3中print的用法,话不多说了,来一起看看详细的介绍吧. 一.Python2中的print用法 在Python2 中 prin
-
python3序列化与反序列化用法实例
本文实例讲述了python3序列化与反序列化用法.分享给大家供大家参考.具体如下: #coding=utf-8 import pickle aa={} aa["title"]="我是好人" aa["num"]=2 t=pickle.dumps(aa)#序列化这个字典 print(t) f=pickle.loads(t)#反序列化,还原原来的状态 print(f) 运行结果如下: (dp0 S'num' p1 I2 sS'title' p2 S'\
-
python3 pandas 读取MySQL数据和插入的实例
python 代码如下: # -*- coding:utf-8 -*- import pandas as pd import pymysql import sys from sqlalchemy import create_engine def read_mysql_and_insert(): try: conn = pymysql.connect(host='localhost',user='user1',password='123456',db='test',charset='utf8')
-
python3.6生成器yield用法实例分析
本文实例讲述了python3.6生成器yield用法.分享给大家供大家参考,具体如下: 今天看源码的时候看到了一个比较有意思的函数:yield 功能与return类似,都是返回定义的函数的一个结果,不同的是return返回后这次调用函数就结束了,除了返回值,其余临时变量都会被清除.而yield会停止在当前步,并保留其余变量的值,等下次调用该函数时,从yield的下一步继续往下运行. yield的好处是如果函数需要很大的内存,比方说需要计算并返回一个很大的数列,如果用return,我们只能用一个l
-
Python Pandas数据分析工具用法实例
1.介绍 Pandas是基于Numpy的专业数据分析工具,可以灵活高效的处理各种数据集,也是我们后期分析案例的神器.它提供了两种类型的数据结构,分别是DataFrame和Series,我们可以简单粗暴的把DataFrame理解为Excel里面的一张表,而Series就是表中的某一列 2.创建DataFrame # -*- encoding=utf-8 -*- import pandas if __name__ == '__main__': pass test_stu = pandas.DataF
-
解析pandas apply() 函数用法(推荐)
目录 Series.apply() apply 函数接收带有参数的函数 DataFrame.apply() apply() 计算日期相减示例 参考 理解 pandas 的函数,要对函数式编程有一定的概念和理解.函数式编程,包括函数式编程思维,当然是一个很复杂的话题,但对今天介绍的 apply() 函数,只需要理解:函数作为一个对象,能作为参数传递给其它函数,也能作为函数的返回值. 函数作为对象能带来代码风格的巨大改变.举一个例子,有一个类型为 list 的变量,包含 从 1 到 10 的数据,需
-
mybatis模糊查询之bind标签和concat函数用法详解
1.二种方式都可以用来模糊查询,都能预防 SQL 注入.但是在更换数据库情况下,bind标签通用. <if test=" userName != null and userName !=""> and userName like concat('%' ,#{userName},'%') </if> 2.使用concat函数连接字符串,在mysql中这个函数支持多个参数,但是在oracle中这个函数只支持2个参数,由于不同数据库之间的语法差异,更换数据库