python爬虫scrapy框架的梨视频案例解析
之前我们使用lxml对梨视频网站中的视频进行了下载,感兴趣的朋友点击查看吧。
下面我用scrapy框架对梨视频网站中的视频标题和视频页中对视频的描述进行爬取


分析:我们要爬取的内容并不在同一个页面,视频描述内容需要我们点开视频,跳转到新的url中才能获取,我们就不能在一个方法中去解析我们需要的不同内容
1.爬虫文件
- 这里我们可以仿照爬虫文件中的parse方法,写一个新的parse方法,可以将新的url的响应对象传给这个新的parse方法
- 如果需要在不同的parse方法中使用同一个item对象,可以使用meta参数字典,将item传给callback回调函数
- 爬虫文件中的parse需要yield的Request请求,而item则在新的parse方法中使用yield item传给下一个parse方法或管道文件
import scrapy
# 从items.py文件中导入BossprojectItem类
from bossProject.items import BossprojectItem
class BossSpider(scrapy.Spider):
name = 'boss'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.pearvideo.com/category_5']
# 回调函数接受响应对象,并且接受传递过来的meata参数
def content_parse(self,response):
# meta参数包含在response响应对象中,调用meta,然后根据键值取出对应的值:item
item = response.meta['item']
# 解析视频链接中的对视频的描述
des = response.xpath('//div[@class="summary"]/text()').extract()
des = "".join(des)
item['des'] = des
yield item
# 解析首页视频的标题以及视频的链接
def parse(self, response):
li_list = response.xpath('//div[@id="listvideoList"]/ul/li')
for li in li_list:
href = li.xpath('./div/a/@href').extract()
href = "https://www.pearvideo.com/" + "".join(href)
title = li.xpath('./div[1]/a/div[2]/text()').extract()
title = "".join(title)
item = BossprojectItem()
item["title"] = title
#手动发送请求,并将响应对象传给回调函数
#请求传参:meta={},可以将meta字典传递给请求对应的回调函数
yield scrapy.Request(href,callback=self.content_parse,meta={'item':item})
2.items.py
要将BossprojectItem类导入爬虫文件中才能够创建item对象
import scrapy class BossprojectItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 定义了item属性 title = scrapy.Field() des = scrapy.Field()
3.pipelines.py
open_spider(self,spider)和close_spider(self,spider)重写这两个父类方法,且这两个方法都只执行一次在process_item方法中最好保留return item,因为如果存在多个管道类,return item会自动将item对象传给优先级低于自己的管道类
from itemadapter import ItemAdapter
class BossprojectPipeline:
def __init__(self):
self.fp = None
# 重写父类方法,只调用一次
def open_spider(self,spider):
print("爬虫开始")
self.fp = open('./lishipin.txt','w')
# 接受爬虫文件中yield传递来的item对象,将item中的内容持久化存储
def process_item(self, item, spider):
self.fp.write(item['title'] + '\n\t' + item['des'] + '\n')
# 如果有多个管道类,会将item传递给下一个管道类
# 管道类的优先级取决于settings.py中的ITEM_PIPELINES属性中对应的值
## ITEM_PIPELINES = {'bossProject.pipelines.BossprojectPipeline': 300,} 键值中的值越小优先级越高
return item
# 重写父类方法,只调用一次
def close_spider(self,spider):
self.fp.close()
print("爬虫结束")
4.进行持久化存储
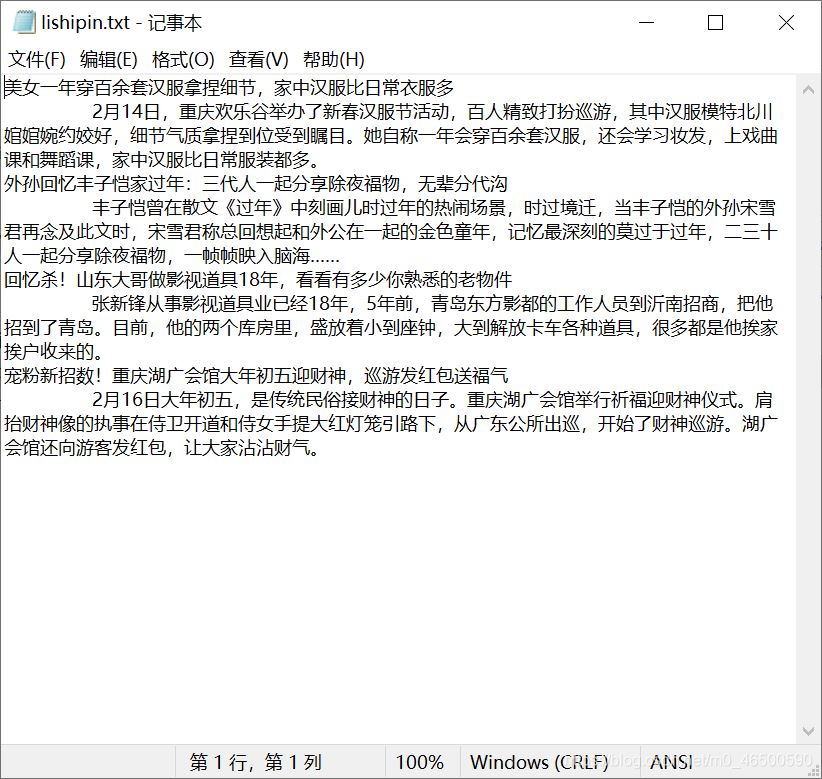
到此这篇关于python爬虫scrapy框架的梨视频案例解析的文章就介绍到这了,更多相关python爬虫scrapy框架内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码
大家可以在Github上clone全部源码. Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu Scrapy官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 基本上按照文档的流程走一遍就基本会用了. Step1: 在开始爬取之前,必须创建一个新的Scrapy项目. 进入打算存储代码的目录中,运行下列命令: scrapy startproject CrawlMe
-

实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250
安装部署Scrapy 在安装Scrapy前首先需要确定的是已经安装好了Python(目前Scrapy支持Python2.5,Python2.6和Python2.7).官方文档中介绍了三种方法进行安装,我采用的是使用 easy_install 进行安装,首先是下载Windows版本的setuptools(下载地址:http://pypi.python.org/pypi/setuptools),下载完后一路NEXT就可以了. 安装完setuptool以后.执行CMD,然后运行一下命令: easy_i
-
Python 利用scrapy爬虫通过短短50行代码下载整站短视频
近日,有朋友向我求助一件小事儿,他在一个短视频app上看到一个好玩儿的段子,想下载下来,可死活找不到下载的方法.这忙我得帮,少不得就抓包分析了一下这个app,找到了视频的下载链接,帮他解决了这个小问题. 因为这个事儿,勾起了我另一个念头,这不最近一直想把python爬虫方面的知识梳理梳理吗,干脆借机行事,正凑着短视频火热的势头,做一个短视频的爬虫好了,中间用到什么知识就理一理. 我喜欢把事情说得很直白,如果恰好有初入门的朋友想了解爬虫的技术,可以将就看看,或许对你的认识会有提升.如果有高手路过,
-
python3 Scrapy爬虫框架ip代理配置的方法
什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板.对于框架的学习,重点是要学习其框架的特性.各个功能的用法即可. 一.背景 在做爬虫项目的过程中遇到ip代理的问题,网上搜了一些,要么是用阿里云的ip代理,要么是搜一些网上现有的ip资源,然后配置在setting文件中.这两个方法都存在一些问题. 1.阿里云ip代理方法,网上大
-
Python爬虫框架Scrapy常用命令总结
本文实例讲述了Python爬虫框架Scrapy常用命令.分享给大家供大家参考,具体如下: 在Scrapy中,工具命令分为两种,一种为全局命令,一种为项目命令. 全局命令不需要依靠Scrapy项目就可以在全局中直接运行,而项目命令必须要在Scrapy项目中才可以运行 全局命令 全局命令有哪些呢,要想了解在Scrapy中有哪些全局命令,可以在不进入Scrapy项目所在目录的情况下,运行scrapy-h,如图所示: 可以看到,此时在可用命令在终端下展示出了常见的全局命令,分别为fetch.runspi
-
python爬虫scrapy基于CrawlSpider类的全站数据爬取示例解析
一.CrawlSpider类介绍 1.1 引入 使用scrapy框架进行全站数据爬取可以基于Spider类,也可以使用接下来用到的CrawlSpider类.基于Spider类的全站数据爬取之前举过栗子,感兴趣的可以康康 scrapy基于CrawlSpider类的全站数据爬取 1.2 介绍和使用 1.2.1 介绍 CrawlSpider是Spider的一个子类,因此CrawlSpider除了继承Spider的特性和功能外,还有自己特有的功能,主要用到的是 LinkExtractor()和rules
-
深入剖析Python的爬虫框架Scrapy的结构与运作流程
网络爬虫(Web Crawler, Spider)就是一个在网络上乱爬的机器人.当然它通常并不是一个实体的机器人,因为网络本身也是虚拟的东西,所以这个"机器人"其实也就是一段程序,并且它也不是乱爬,而是有一定目的的,并且在爬行的时候会搜集一些信息.例如 Google 就有一大堆爬虫会在 Internet 上搜集网页内容以及它们之间的链接等信息:又比如一些别有用心的爬虫会在 Internet 上搜集诸如 foo@bar.com 或者 foo [at] bar [dot] com 之类的东
-
Python爬虫框架Scrapy安装使用步骤
一.爬虫框架Scarpy简介Scrapy 是一个快速的高层次的屏幕抓取和网页爬虫框架,爬取网站,从网站页面得到结构化的数据,它有着广泛的用途,从数据挖掘到监测和自动测试,Scrapy完全用Python实现,完全开源,代码托管在Github上,可运行在Linux,Windows,Mac和BSD平台上,基于Twisted的异步网络库来处理网络通讯,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片. 二.Scrapy安装指南 我们的安装步骤假设你已经安装一下内容:<1>
-
浅析python实现scrapy定时执行爬虫
项目需要程序能够放在超算中心定时运行,于是针对scrapy写了一个定时爬虫的程序main.py ,直接放在scrapy的存储代码的目录中就能设定时间定时多次执行. 最简单的方法:直接使用Timer类 import time import os while True: os.system("scrapy crawl News") time.sleep(86400) #每隔一天运行一次 24*60*60=86400s或者,使用标准库的sched模块 import sched #初始化sch
-
python爬虫scrapy框架的梨视频案例解析
之前我们使用lxml对梨视频网站中的视频进行了下载,感兴趣的朋友点击查看吧. 下面我用scrapy框架对梨视频网站中的视频标题和视频页中对视频的描述进行爬取 分析:我们要爬取的内容并不在同一个页面,视频描述内容需要我们点开视频,跳转到新的url中才能获取,我们就不能在一个方法中去解析我们需要的不同内容 1.爬虫文件 这里我们可以仿照爬虫文件中的parse方法,写一个新的parse方法,可以将新的url的响应对象传给这个新的parse方法 如果需要在不同的parse方法中使用同一个item对象,可
-
python爬虫Scrapy框架:媒体管道原理学习分析
目录 一.媒体管道 1.1.媒体管道的特性 媒体管道实现了以下特性: 图像管道具有一些额外的图像处理功能: 1.2.媒体管道的设置 二.ImagesPipeline类简介 三.小案例:使用图片管道爬取百度图片 3.1.spider文件 3.2.items文件 3.3.settings文件 3.4.pipelines文件 一.媒体管道 1.1.媒体管道的特性 媒体管道实现了以下特性: 避免重新下载最近下载的媒体 指定存储位置(文件系统目录,Amazon S3 bucket,谷歌云存储bucket)
-
Python爬虫scrapy框架Cookie池(微博Cookie池)的使用
下载代码Cookie池(这里主要是微博登录,也可以自己配置置其他的站点网址) 下载代码GitHub:https://github.com/Python3WebSpider/CookiesPool 下载安装过后注意看网页下面的相关基础配置和操作!!!!!!!!!!!!! 自己的设置主要有下面几步: 1.配置其他设置 2.设置使用的浏览器 3.设置模拟登陆 源码cookies.py的修改(以下两处不修改可能会产生bug): 4.获取cookie 随机获取Cookies: http://localho
-
Python爬虫Scrapy框架IP代理的配置与调试
目录 代理ip的逻辑在哪里 如何配置动态的代理ip 在调试爬虫的时候,新手都会遇到关于ip的错误,好好的程序突然报错了,怎么解决,关于ip访问的错误其实很好解决,但是怎么知道解决好了呢?怎么确定是代理ip的问题呢?由于笔者主修语言是Java,所以有些解释可能和Python大佬们的解释不一样,因为我是从Java 的角度看Python.这样也便于Java开发人员阅读理解. 代理ip的逻辑在哪里 一个scrapy 的项目结构是这样的 scrapydownloadertest # 项目文件夹 │ ite
-
Python爬虫Scrapy框架CrawlSpider原理及使用案例
提问:如果想要通过爬虫程序去爬取"糗百"全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬去进行实现的(Request模块回调) 方法二:基于CrawlSpider的自动爬去进行实现(更加简洁和高效) 一.简单介绍CrawlSpider CrawlSpider其实是Spider的一个子类,除了继承到Spider的特性和功能外,还派生除了其自己独有的更加强大的特性和功能.其中最显著的功能就是"LinkExtractors链接提取器&qu
-
python爬虫scrapy框架之增量式爬虫的示例代码
scrapy框架之增量式爬虫 一 .增量式爬虫 什么时候使用增量式爬虫: 增量式爬虫:需求 当我们浏览一些网站会发现,某些网站定时的会在原有的基础上更新一些新的数据.如一些电影网站会实时更新最近热门的电影.那么,当我们在爬虫的过程中遇到这些情况时,我们是不是应该定期的更新程序以爬取到更新的新数据?那么,增量式爬虫就可以帮助我们来实现 二 .增量式爬虫 概念: 通过爬虫程序检测某网站数据更新的情况,这样就能爬取到该网站更新出来的数据 如何进行增量式爬取工作: 在发送请求之前判断这个URL之前是不是
-
Python爬虫 scrapy框架爬取某招聘网存入mongodb解析
创建项目 scrapy startproject zhaoping 创建爬虫 cd zhaoping scrapy genspider hr zhaopingwang.com 目录结构 items.py title = scrapy.Field() position = scrapy.Field() publish_date = scrapy.Field() pipelines.py from pymongo import MongoClient mongoclient = MongoClien
-
Python:Scrapy框架中Item Pipeline组件使用详解
Item Pipeline简介 Item管道的主要责任是负责处理有蜘蛛从网页中抽取的Item,他的主要任务是清晰.验证和存储数据. 当页面被蜘蛛解析后,将被发送到Item管道,并经过几个特定的次序处理数据. 每个Item管道的组件都是有一个简单的方法组成的Python类. 他们获取了Item并执行他们的方法,同时他们还需要确定的是是否需要在Item管道中继续执行下一步或是直接丢弃掉不处理. Item管道通常执行的过程有 清理HTML数据 验证解析到的数据(检查Item是否包含必要的字段) 检查是
-
Python利用Scrapy框架爬取豆瓣电影示例
本文实例讲述了Python利用Scrapy框架爬取豆瓣电影.分享给大家供大家参考,具体如下: 1.概念 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 通过Python包管理工具可以很便捷地对scrapy进行安装,如果在安装中报错提示缺少依赖的包,那就通过pip安装所缺的包 pip install scrapy scrapy的组成结构如下图所示 引擎Scrapy Engine,用于中转调度其他部分的信号和数据