Xmind用例导入到TAPD的解决方案
目录
- 概述
- XMind2TestCase项目介绍
- 具体修改点
- 使用方法
概述
本方案使用的是,参考开源项目XMind2TestCase的实现逻辑,按照TAPD导入的格式,把XMind2TestCase项目的表头以及数据做一定修改,使生成的数据符合tapd的导入要求。
XMind2TestCase项目介绍
XMind2TestCase ,该工具基于 Python 实现,通过制定测试用例通用模板,
然后使用 XMind这款广为流传且开源的思维导图工具进行用例设计。
其中制定测试用例通用模板是一个非常核心的步骤(具体请看(附件包里面doc/readme)),有了通用的测试用例模板,我们就可以在 XMind 文件上解析并提取出测试用例所需的基本信息,
然后合成常见测试用例管理系统所需的用例导入文件。这样就将 XMind 设计测试用例的便利与常见测试用例系统的高效管理结合起来了!
当前 XMind2TestCase 已实现从 XMind 文件到 TestLink 和 Zentao(禅道) 两大常见用例管理系统的测试用例转换,同时也提供 XMind 文件解析后的两种数据接口
(TestSuites、TestCases两种级别的JSON数据),方便快速与其他测试用例管理系统打通。
项目地址:XMind2TestCase
项目介绍及使用(网盘包里面):xmind2testcase-master\README.md(这个必看,不然不知知道怎么实现喔!!!)
百度网盘链接
链接: https://pan.baidu.com/s/1VDTyBd5_QDPc7kfgjuvWHw?pwd=e15m 提取码: e15m
具体修改点
#修改表头
def xmind_to_zentao_csv_file(xmind_file):
"""Convert XMind file to a zentao csv file"""
xmind_file = get_absolute_path(xmind_file) #路径处理
logging.info('Start converting XMind file(%s) to zentao file...', xmind_file)
testcases = get_xmind_testcase_list(xmind_file) #解析xmind文档,得到原始数据
# print("testcases",testcases)
#fileheader = ["所属模块","用例标题","前置条件","步骤", "预期", "关键词>用例状态", "优先级", "用例类型", "适用阶段?"]
fileheader_tapd = ["用例目录","用例名称","需求ID","前置条件","用例步骤","预期结果","用例类型","用例状态","用例等级","创建人","测试结果","备注说明"]
zentao_testcase_rows = [fileheader_tapd]
for testcase in testcases:
#row = gen_a_testcase_row(testcase)
row = gen_a_testcase_row_tapd(testcase)
zentao_testcase_rows.append(row)
zentao_file = xmind_file[:-6] + '.csv'
if os.path.exists(zentao_file): #判断括号里的文件是否存在
os.remove(zentao_file)
# logging.info('The zentao csv file already exists, return it directly: %s', zentao_file)
# return zentao_file
with open(zentao_file, 'w', encoding='utf8') as f:
writer = csv.writer(f)
writer.writerows(zentao_testcase_rows)
logging.info('Convert XMind file(%s) to a zentao csv file(%s) successfully!', xmind_file, zentao_file)
return zentao_file
#修改为tapd的数据格式、增加获取需求ID
def gen_a_testcase_row_tapd(testcase_dict):
#用例标题
case_title = testcase_dict['name']
#需求ID 产品名称里的目录获取
requirement_id, product_catalog = gen_requirement_id(testcase_dict['product'])
# 所属模块
case_module =product_catalog +"-" + gen_case_module(testcase_dict['suite'])
#前置条件
case_precontion = testcase_dict['preconditions']
#步骤 预期结果
case_step, case_expected_result = gen_case_step_and_expected_result(testcase_dict['steps'])
#用例类型
case_type = gen_case_type(testcase_dict['execution_type'])
# case_type = "功能测试"
#用例状态
case_status = "正常"
#用例等级
case_priority = gen_case_priority(testcase_dict['importance'])
#创建人
case_created_by = ""
#测试结果
case_actual_result= ""
row = [case_module,case_title,requirement_id,case_precontion,case_step,case_expected_result,case_type,case_status,case_priority,case_created_by,case_actual_result]
return row
#修改用例类型
def get_execution_type(topics):
labels = [topic.get('label', '') for topic in topics]
labels = filter_empty_or_ignore_element(labels)
exe_type = 1
for item in labels[::-1]:
if item.lower() in ['性能测试', '性能']:
exe_type = 2
break
if item.lower() in ['功能测试', '功能']:
exe_type = 1
break
if item.lower() in ['安全测试', '安全','安全性测试']:
exe_type = 3
break
if item.lower() in ['其他']:
exe_type = 4
break
return exe_type
使用方法
1、安装库:pip3 install xmind2testcase
2、xmind模板及说明(格式要求里面描述很清晰了):xmind2testcase-master\docs\zentao_testcase_template.xmind
3、运行方式:①运行zentao.py ②使用webtool工具(可放再服务器上多人使用)


其他:
使用案例,好久之前写的,基本能用,最终没有在项目推行,这里共享给大家。
链接: https://pan.baidu.com/s/1VDTyBd5_QDPc7kfgjuvWHw?pwd=e15m 提取码: e15m
特别说明:
1、标签的测试方式已改成:功能测试、性能测试、安全测试、其他
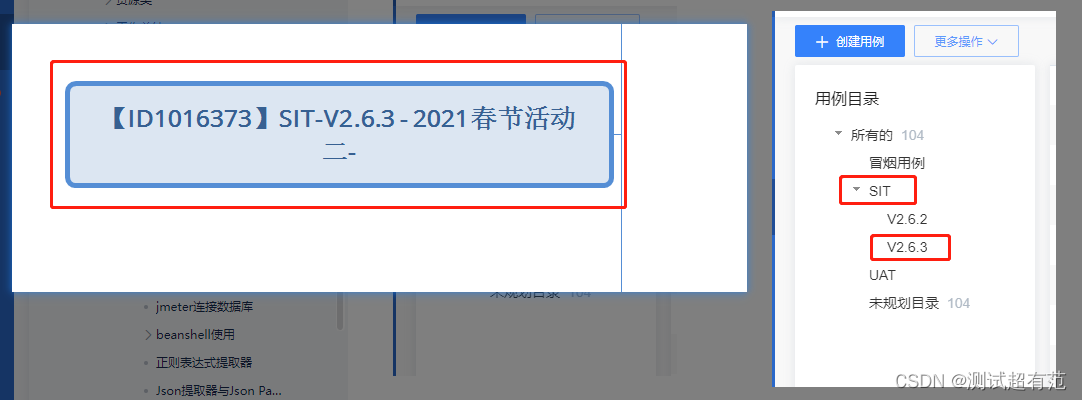
2、根名称做了适用tapd的处理,如下图结构:【ID1016373】SIT-V2.6.3 - 2021春节活动二-
【ID1016373】是需求ID,要需求ID则必须要带【】,且放在前面,没有需求ID则不写这个【】,则结果为空
SIT-V2.6.3 - 2021春节活动二:是在TAPD的目录路径
到此这篇关于Xmind用例导入到TAPD的方案的文章就介绍到这了,更多相关Xmind导入到TAPD内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

使用Python 操作 xmind 绘制思维导图的详细方法
思维导图 思维导图:思维导图又叫心智导图是表达发散性思维的有效的图形思维工具,它简单却又很有效,是一种革命性的思维工具.思维导图运用图文并重的技巧,把各级主题的关系用相互隶属与相关的层级图表现出来,把主题关键词与图像.颜色等建立记忆链接.思维导图充分运用左右脑的机能,利用记忆.阅读.思维的规律,协助人们在科学与艺术.逻辑与想象之间平衡发展,从而开启人类大脑的无限潜能.思维导图因此具有人类思维的强大功能. 思维导图是一种将思维形象化的方法.简单来讲:思维导图就是能有层次感的展示我们想法的思维工具.
-
使用python把xmind转换成excel测试用例的实现代码
前言 因为写好了测试xmind脑图后,然后再编写测试用例,实在是太麻烦了,所以我写了一点测试用例后,就网上百度了下,怎么直接把xmind脑图转换成excel测试用例,纯个人学习笔记 本文参考: https://www.cnblogs.com/xu-xu/articles/11999960.html https://www.cnblogs.com/xu-xu/articles/12000205.html 提示:以下是本篇文章正文内容,下面可供参考 一.确定好自己的xmind的用例格式 因为xmin
-
如何利用python将Xmind用例转为Excel用例
目录 1.Xmind用例编写规范 2.转换代码 3.使用 1.Xmind用例编写规范 1:需求大模块 2:大模块中的小模块(需要根据需求来看需要多少层) 3:用例等级和用例名称 用例等级(转换成Excel文件后,1为High, 2 为 Middle, 3为Low) 转换成excel时,用例的名称为(框出来的1-2-3组合而成),意味着在标等级及之前的节点会组合成用例名称 4:步骤 5:期望结果 6:预置条件,转换成excel时相同层级下的用例会为同一个预置条件 2.转换代码 需要安装python
-
Xmind8 Pro 最新激活序列号
最近需要画思维导图总结,所以下载了Xmind8 .打开以后想要导出,奈何普通版本只能导出.txt文本文档,所以只好动手pj.话不多说看下边. 我们下载点击此处 一.下载XMindCrack.jar文件 XMindCrack.jar 链接: https://pan.baidu.com/s/1CSPo37aEr-n9qawr-THnXQ 提取码: hevv (xmind-8版本Windows:xmind-8-update9-windows) 链接: https://pan.baidu.com/s/1
-
XMind 2021激活码及安装步骤
目录 XMind 2021激活破解 1. 在官网下载XMind2021并安装 2. 激活破解 补充:下面再看下Xmind2021安装激活图文教程 1. 下载Xmind,并安装. 2. 激活破解 3. 完成 XMind 2021激活破解 1. 在官网下载XMind2021并安装 官网:https://www.xmind.cn/download/ 2. 激活破解 2.1 找到需要替换文件的目录 右击软件,打开文件所在的位置(默认路径:C:\Program Files\XMind),找到resourc
-
Xmind用例导入到TAPD的解决方案
目录 概述 XMind2TestCase项目介绍 具体修改点 使用方法 概述 本方案使用的是,参考开源项目XMind2TestCase的实现逻辑,按照TAPD导入的格式,把XMind2TestCase项目的表头以及数据做一定修改,使生成的数据符合tapd的导入要求. XMind2TestCase项目介绍 XMind2TestCase ,该工具基于 Python 实现,通过制定测试用例通用模板,然后使用 XMind这款广为流传且开源的思维导图工具进行用例设计.其中制定测试用例通用模板是一个非常核心
-
IDEA工程运行时总是报xx程序包不存在实际上包已导入(问题分析及解决方案)
IDEA工程运行时,总是报xx程序包不存在,实际上包已导入 先上截图 使用IDEA写Java工程时,使用Maven导入依赖包,程序写好后,代码没有报错,但是执行时就会报图中的错误. 如何解决? 网上找了很多解决方法,都没有解决问题.本人是使用IDEA的新手,也很少使用Maven,学习为主.该办法不一定能解决所有类似的问题,仅作参考. 删除工程目录下的 .iml 文件,删除之前可以看下文件内容: 打开命令行或者IDEA底部Terminal窗口,将目录调整到工程目录下,执行 mvn idea:mod
-
Vue3+Element-plus项目自动导入报错的解决方案
目录 前言 安装步骤 1.安装插件 2.vue.config.js 设置 3.npm run serve 出错 解决方案 1.问题原因 1.1 unimport 包报错 1.2 node.js 和 npm 版本过低 2.解决方法 2.1 降低 unplugin-auto-import 插件版本 2.2 升级 node.js 和 npm 版本 补充:element-plus自动按需导入及出错解决 总结 前言 在创建 Vue3 + Element-plus 项目时,根据 Element-plus 文
-
anaconda jupyter不能导入安装的lightgbm解决方案
问题: 安装lightgbm成功后,无法在anaconda jupyter notebook中导入lightgbm包 原因: lightgbm默认安装在本地python环境中,而anaconda的python环境与本地不是同一个环境,不能使用本地环境中的包 解决方法: 将本地环境中的lightgm包拷贝到anaconda的python环境中 操作方法: 在本地的python环境下,导入lightgbm包,使用lightgbm.__file__输出包的路径 在Anaconda的python环境下,
-
SQL SERVER 2008 64位系统无法导入ACCESS/EXCEL怎么办
操作系统Windows Server 2008 X64,数据库SQL Server 2008 X64,Office 2007(好像只有32位),在存储过程执行OpenDatasource导入Access数据的时候遇到问题了,Oledb 4.0已经不被支持,以下是遇到的若干错误提示: 因为 OLE DB 访问接口 'Microsoft.Jet.OLEDB.4.0' 配置为在单线程单元模式下运行,所以该访问接口无法用于分布式查询. 无法创建链接服务器 "(null)" 的 OLE DB 访
-
解决Python中导入自己写的类,被划红线,但不影响执行的问题
1. 错误描述 之前在学习Python的过程中,导入自己写的包文件时,与之相关的方法等都会被划红线,但并不影响代码执行,如图: 看着红线确实有点强迫症,并且在这个过程当时,当使用该文件里的方法时不会自动提示方法名,只能靠手全部输入,这种容易造成手误,对于小白特别容易降低编写效率 2. 原因分析 pycharm中,source root概念非常重要,当你在代码中写相对路径的时候,就是以source root为起点进行查询. 而pycharm中,当前的项目文件夹 是默认的source root,当你
-
解决Navicat导入数据库数据结构sql报错datetime(0)的问题
错误发生情况: 将数据库从mysql5.7导出为sql,在mysql5.5上进行导入,报sql语句错误:datetime(0)- 错误发生原因 mysql5.7和mysql5.5的datetime.timestamp不兼容 mysql5.7导出的格式为 : datetime(0),mysql5.5则无法识别该语法 解决办法 将导出语句中datetime(0) 改为datetime,或者是timestamp(0) 改为timestamp 保持数据库版本一致 补充知识:navicat导入sql,数据
-
5个可以加速开发的VueUse函数库(小结)
目录 VueUse 有哪些实用程序? 将 VueUse 安装到你的 Vue 项目中 1.useRefHistory 跟踪响应式数据的更改 2.onClickOutside 关闭模态 3.useVModel 简化了 v-model 绑定 4.使用InterpObserver 跟踪元素可见性 5.useTransition 在值之间缓和 最后的想法 VueUse 是 Anthony Fu 的一个开源项目,它为 Vue 开发人员提供了大量适用于 Vue 2 和 Vue 3 的基本 Compositio
-
Java中的设计模式与7大原则归纳整理
Java中的设计模式与7大原则: 一.创建型模式 1.抽象工厂模式(Abstract factory pattern): 提供一个接口, 用于创建相关或依赖对象的家族, 而不需要指定具体类. 2.生成器模式(Builder pattern): 使用生成器模式封装一个产品的构造过程, 并允许按步骤构造. 将一个复杂对象的构建与它的表示分离, 使得同样的构建过程可以创建不同的表示. 3.工厂模式(factory method pattern): 定义了一个创建对象的接口, 但由子类决定要实例化的类是