Java从同步容器到并发容器的操作过程
引言
容器是Java基础类库中使用频率最高的一部分,Java集合包中提供了大量的容器类来帮组我们简化开发,我前面的文章中对Java集合包中的关键容器进行过一个系列的分析,但这些集合类都是非线程安全的,即在多线程的环境下,都需要其他额外的手段来保证数据的正确性,最简单的就是通过synchronized关键字将所有使用到非线程安全的容器代码全部同步执行。这种方式虽然可以达到线程安全的目的,但存在几个明显的问题:首先编码上存在一定的复杂性,相关的代码段都需要添加锁。其次这种一刀切的做法在高并发情况下性能并不理想,基本相当于串行执行。JDK1.5中为我们提供了一系列的并发容器,集中在java.util.concurrent包下,用来解决这两个问题,先从同步容器说起。
同步容器Vector和HashTable
为了简化代码开发的过程,早期的JDK在java.util包中提供了Vector和HashTable两个同步容器,这两个容器的实现和早期的ArrayList和HashMap代码实现基本一样,不同在于Vector和HashTable在每个方法上都添加了synchronized关键字来保证同一个实例同时只有一个线程能访问,部分源码如下:
//Vector
public synchronized int size() {};
public synchronized E get(int index) {};
//HashTable
public synchronized V put(K key, V value) {};
public synchronized V remove(Object key) {};
通过对每个方法添加synchronized,保证了多次操作的串行。这种方式虽然使用起来方便了,但并没有解决高并发下的性能问题,与手动锁住ArrayList和HashMap并没有什么区别,不论读还是写都会锁住整个容器。其次这种方式存在另一个问题:当多个线程进行复合操作时,是线程不安全的。可以通过下面的代码来说明这个问题:
public static void deleteVector(){
int index = vectors.size() - 1;
vectors.remove(index);
}
代码中对Vector进行了两步操作,首先获取size,然后移除最后一个元素,多线程情况下如果两个线程交叉执行,A线程调用size后,B线程移除最后一个元素,这时A线程继续remove将会抛出索引超出的错误。
那么怎么解决这个问题呢?最直接的修改方案就是对代码块加锁来防止多线程同时执行:
public static void deleteVector(){
synchronized (vectors) {
int index = vectors.size() - 1;
vectors.remove(index);
}
}
如果上面的问题通过加锁来解决没有太直观的影响,那么来看看对vectors进行迭代的情况:
public static void foreachVector(){
synchronized (vectors) {
for (int i = 0; i < vectors.size(); i++) {
System.out.println(vectors.get(i).toString());
}
}
}
为了避免多线程情况下在迭代的过程中其他线程对vectors进行了修改,就不得不对整个迭代过程加锁,想象这么一个场景,如果迭代操作非常频繁,或者vectors元素很大,那么所有的修改和读取操作将不得不在锁外等待,这将会对多线程性能造成极大的影响。那么有没有什么方式能够很好的对容器的迭代操作和修改操作进行分离,在修改时不影响容器的迭代操作呢?这就需要java.util.concurrent包中的各种并发容器了出场了。
并发容器CopyOnWrite
CopyOnWrite--写时复制容器是一种常用的并发容器,它通过多线程下读写分离来达到提高并发性能的目的,和前面我们讲解StampedLock时所用的解决方案类似:任何时候都可以进行读操作,写操作则需要加锁。不同的是,在CopyOnWrite中,对容器的修改操作加锁后,通过copy一个新的容器来进行修改,修改完毕后将容器替换为新的容器即可。
这种方式的好处显而易见:通过copy一个新的容器来进行修改,这样读操作就不需要加锁,可以并发读,因为在读的过程中是采用的旧的容器,即使新容器做了修改对旧容器也没有影响,同时也很好的解决了迭代过程中其他线程修改导致的并发问题。
JDK中提供的并发容器包括CopyOnWriteArrayList和CopyOnWriteArraySet,下面通过CopyOnWriteArrayList的部分源码来理解这种思想:
//添加元素
public boolean add(E e) {
//独占锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
//复制一个新的数组newElements
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
//修改后指向新的数组
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
public E get(int index) {
//未加锁,直接获取
return get(getArray(), index);
}
代码很简单,在add操作中通过一个共享的ReentrantLock来获取锁,这样可以防止多线程下多个线程同时修改容器内容。获取锁后通过Arrays.copyOf复制了一个新的容器,然后对新的容器进行了修改,最后直接通过setArray将原数组引用指向了新的数组,避免了在修改过程中迭代数据出现错误。get操作由于是读操作,未加锁,直接读取就行。
CopyOnWriteArraySet类似,这里不做过多讲解。
CopyOnWrite容器虽然在多线程下使用是安全的,相比较Vector也大大提高了读写的性能,但它也有自身的问题。
首先就是性能,在讲解ArrayList的文章中提到过,ArrayList的扩容由于使用了Arrays.copyOf每次都需要申请更大的空间以及复制现有的元素到新的数组,对性能存在一定影响。CopyOnWrite容器也不例外,每次修改操作都会申请新的数组空间,然后进行替换。所以在高并发频繁修改容器的情况下,会不断申请新的空间,同时会造成频繁的GC,这时使用CopyOnWrite容器并不是一个好的选择。
其次还有一个数据一致性问题,由于在修改中copy了新的数组进行替换,同时旧数组如果还在被使用,那么新的数据就不能被及时读取到,这样就造成了数据不一致,如果需要强数据一致性,CopyOnWrite容器也不太适合。
并发容器ConcurrentHashMap
ConcurrentHashMap容器相较于CopyOnWrite容器在并发加锁粒度上有了更大一步的优化,它通过修改对单个hash桶元素加锁的达到了更细粒度的并发控制。在了解ConcurrentHashMap容器之前,推荐大家先阅读我之前对HashMap源码分析的文章--Java集合(5)一 HashMap与HashSet,因为在底层数据结构上,ConcurrentHashMap和HashMap都使用了数组+链表+红黑树的方式,只是在HashMap的基础上添加了并发相关的一些控制,所以这里只对ConcurrentHashMap中并发相关代码做一些分析。
还是先从ConcurrentHashMap的写操作开始,这里就是put方法:
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode()); //计算桶的hash值
int binCount = 0;
//循环插入元素,避免并发插入失败
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//如果当前桶无元素,则通过cas操作插入新节点
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break;
}
//如果当前桶正在扩容,则协助扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//hash冲突时锁住当前需要添加节点的头元素,可能是链表头节点或者红黑树的根节点
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
在put元素的过程中,有几个并发处理的关键点:
•如果当前桶对应的节点还没有元素插入,通过典型的无锁cas操作尝试插入新节点,减少加锁的概率,并发情况下如果插入不成功,很容易想到自旋,也就是for (Node<K,V>[] tab = table;;)。
•如果当前桶正在扩容,则协助扩容((fh = f.hash) == MOVED)。这里是一个重点,ConcurrentHashMap的扩容和HashMap不一样,它在多线程情况下或使用多个线程同时扩容,每个线程扩容指定的一部分hash桶,当前线程扩容完指定桶之后会继续获取下一个扩容任务,直到扩容全部完成。扩容的大小和HashMap一样,都是翻倍,这样可以有效减少移动的元素数量,也就是使用2的幂次方的原因,在HashMap中也一样。
•在发生hash冲突时仅仅只锁住当前需要添加节点的头元素即可,可能是链表头节点或者红黑树的根节点,其他桶节点都不需要加锁,大大减小了锁粒度。
通过ConcurrentHashMap添加元素的过程,知道了ConcurrentHashMap容器是通过CAS + synchronized一起来实现并发控制的。这里有个额外的问题:为什么使用synchronized而不使用ReentrantLock?前面我的文章也对synchronized以及ReentrantLock的实现方式和性能做过分析,在这里我的理解是synchronized在后期优化空间上比ReentrantLock更大。
并发容器ConcurrentSkipListMap
java.util中对应的容器在java.util.concurrent包中基本都可以找到对应的并发容器:List和Set有对应的CopyOnWriteArrayList与CopyOnWriteArraySet,HashMap有对应的ConcurrentHashMap,但是有序的TreeMap或并没有对应的ConcurrentTreeMap。
为什么没有ConcurrentTreeMap呢?这是因为TreeMap内部使用了红黑树来实现,红黑树是一种自平衡的二叉树,当树被修改时,需要重新平衡,重新平衡操作可能会影响树的大部分节点,如果并发量非常大的情况下,这就需要在许多树节点上添加互斥锁,那并发就失去了意义。所以提供了另外一种并发下的有序map实现:ConcurrentSkipListMap。
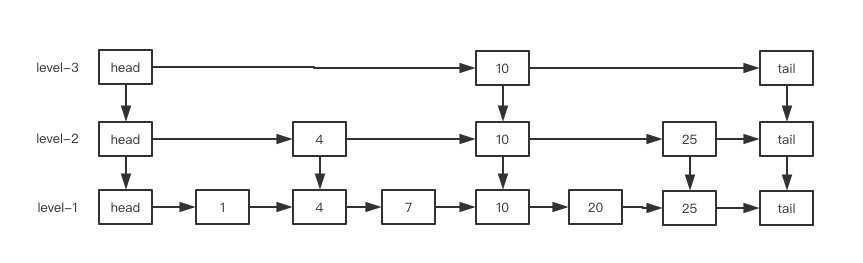
ConcurrentSkipListMap内部使用跳表(SkipList)这种数据结构来实现,他的结构相对红黑树来说非常简单理解,实现起来也相对简单,而且在理论上它的查找、插入、删除时间复杂度都为log(n)。在并发上,ConcurrentSkipListMap采用无锁的CAS+自旋来控制。
跳表简单来说就是一个多层的链表,底层是一个普通的链表,然后逐层减少,通常通过一个简单的算法实现每一层元素是下一层的元素的二分之一,这样当搜索元素时从最顶层开始搜索,可以说是另一种形式的二分查找。
一个简单的获取跳表层数概率算法实现如下:
int random_level() {
K = 1;
while (random(0,1))
K++;
return K;
}
通过简单的0和1获取概率,1层的概率为50%,2层的概率为25%,3层的概率为12.5%,这样逐级递减。
一个三层的跳表添加元素的过程如下:
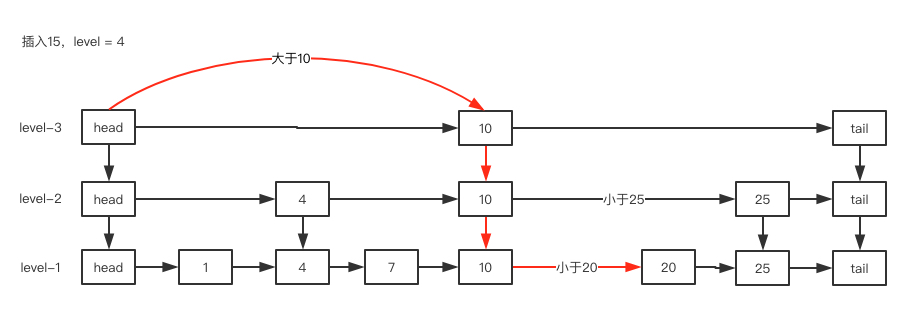
插入值为15的节点:
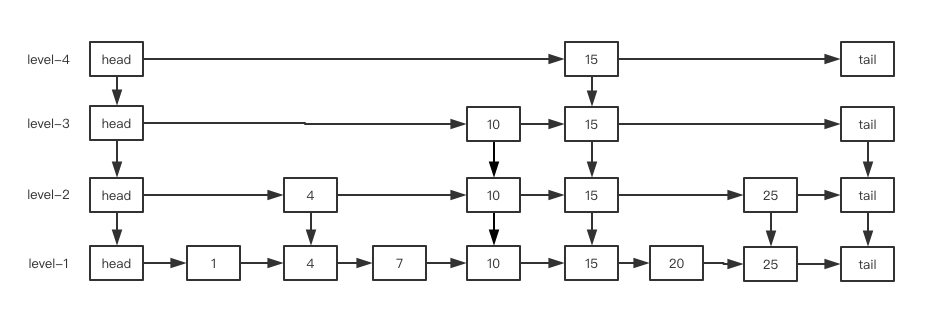
插入后:
维基百科中有一个添加节点的动图,这里也贴出来方便理解:
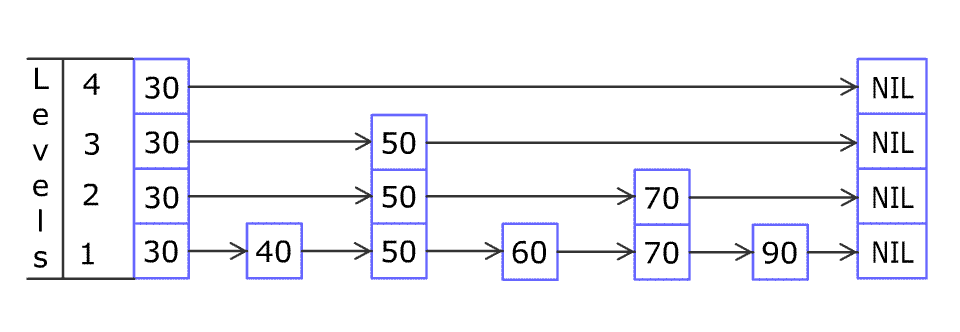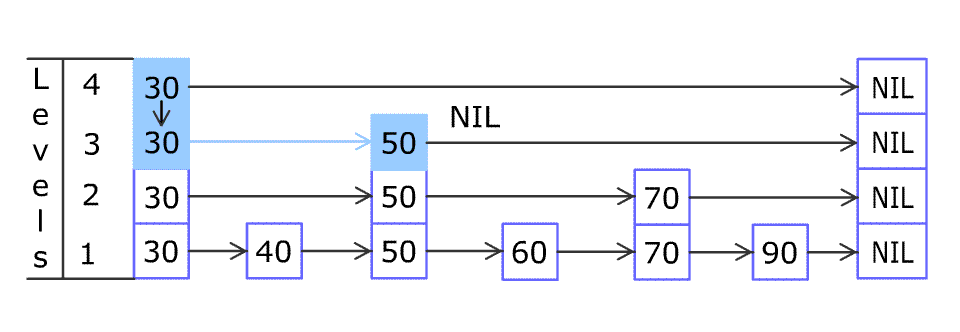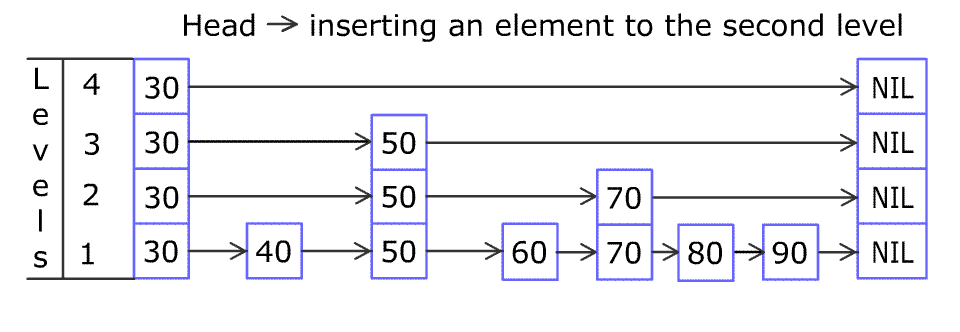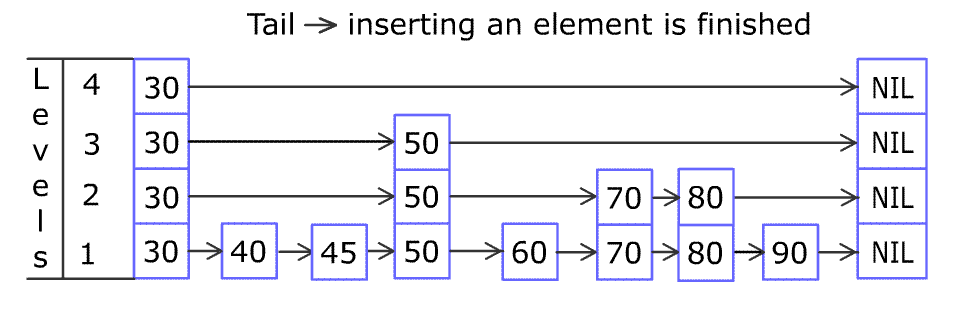
通过分析ConcurrentSkipListMap的put方法来理解跳表以及CAS自旋并发控制:
private V doPut(K key, V value, boolean onlyIfAbsent) {
Node<K,V> z; // added node
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer: for (;;) {
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) { //查找前继节点
if (n != null) { //查找到前继节点
Object v; int c;
Node<K,V> f = n.next; //获取后继节点的后继节点
if (n != b.next) //发生竞争,两次节点获取不一致,并发导致
break;
if ((v = n.value) == null) { // 节点已经被删除
n.helpDelete(b, f);
break;
}
if (b.value == null || v == n)
break;
if ((c = cpr(cmp, key, n.key)) > 0) { //进行下一轮查找,比当前key大
b = n;
n = f;
continue;
}
if (c == 0) { //相等时直接cas修改值
if (onlyIfAbsent || n.casValue(v, value)) {
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
break; // restart if lost race to replace value
}
// else c < 0; fall through
}
z = new Node<K,V>(key, value, n); //9. n.key > key > b.key
if (!b.casNext(n, z)) //cas修改值
break; // restart if lost race to append to b
break outer;
}
}
int rnd = ThreadLocalRandom.nextSecondarySeed(); //获取随机数
if ((rnd & 0x80000001) == 0) { // test highest and lowest bits
int level = 1, max;
while (((rnd >>>= 1) & 1) != 0) // 获取跳表层级
++level;
Index<K,V> idx = null;
HeadIndex<K,V> h = head;
if (level <= (max = h.level)) { //如果获取的调表层级小于等于当前最大层级,则直接添加,并将它们组成一个上下的链表
for (int i = 1; i <= level; ++i)
idx = new Index<K,V>(z, idx, null);
}
else { // try to grow by one level //否则增加一层level,在这里体现为Index<K,V>数组
level = max + 1; // hold in array and later pick the one to use
@SuppressWarnings("unchecked")Index<K,V>[] idxs =
(Index<K,V>[])new Index<?,?>[level+1];
for (int i = 1; i <= level; ++i)
idxs[i] = idx = new Index<K,V>(z, idx, null);
for (;;) {
h = head;
int oldLevel = h.level;
if (level <= oldLevel) // lost race to add level
break;
HeadIndex<K,V> newh = h;
Node<K,V> oldbase = h.node;
for (int j = oldLevel+1; j <= level; ++j) //新添加的level层的具体数据
newh = new HeadIndex<K,V>(oldbase, newh, idxs[j], j);
if (casHead(h, newh)) {
h = newh;
idx = idxs[level = oldLevel];
break;
}
}
}
// 逐层插入数据过程
splice: for (int insertionLevel = level;;) {
int j = h.level;
for (Index<K,V> q = h, r = q.right, t = idx;;) {
if (q == null || t == null)
break splice;
if (r != null) {
Node<K,V> n = r.node;
// compare before deletion check avoids needing recheck
int c = cpr(cmp, key, n.key);
if (n.value == null) {
if (!q.unlink(r))
break;
r = q.right;
continue;
}
if (c > 0) {
q = r;
r = r.right;
continue;
}
}
if (j == insertionLevel) {
if (!q.link(r, t))
break; // restart
if (t.node.value == null) {
findNode(key);
break splice;
}
if (--insertionLevel == 0)
break splice;
}
if (--j >= insertionLevel && j < level)
t = t.down;
q = q.down;
r = q.right;
}
}
}
return null;
}
这里的插入方法很复杂,可以分为3大步来理解:第一步获取前继节点后通过CAS来插入节点;第二步对level层数进行判断,如果大于最大层数,则插入一层;第三步插入对应层的数据。整个插入过程全部通过CAS自旋的方式保证并发情况下的数据正确性。
总结
JDK中提供了丰富的并发容器供我们使用,文章中介绍的也并不全面,重点是要通过了解各种并发容器的原理,明白他们各自独特的使用场景。这里简单做个总结:当并发读远多于修改的场景下需要使用List和Set时,可以考虑使用CopyOnWriteArrayList和CopyOnWriteArraySet;当需要并发使用<Key, Value>键值对存取数据时,可以使用ConcurrentHashMap;当要保证并发<Key, Value>键值对有序时可以使用ConcurrentSkipListMap。
以上所述是小编给大家介绍的Java从同步容器到并发容器的操作过程,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
Java 容器类源码详解 Set
前言 Set 表示由无重复对象组成的集合,也是集合框架中重要的一种集合类型,直接扩展自 Collection 接口.在一个 Set 中,不能有两个引用指向同一个对象,或两个指向 null 的引用.如果对象 a 和 b 的引用满足条件 a.equals(b),那么这两个对象也不能同时出现在集合中. 通常 Set 是不要求元素有序的,但也有一些有序的实现,如 SortedMap 接口.LinkedHashSet 接口等. 概述 Set 的具体实现通常都是基于 Map 的.因为 Map 中键是唯一的,
-
Java容器ArrayList知识点总结
ArrayList 底层实现是数组,访问元素效率高 (查询快,插入.修改.删除元素慢) 与LinkedList相比,它效率高,但线程不安全. ArrayList数组是一个可变数组,可以存取包括null在内的所有元素 每个ArrayList实例都有一个容量,该容量是指用来存储列表元素的数组的大小 随着向ArrayList中不断增加元素,其容量自动增长 在添加大量元素前,应用程序也可以使用ensureCapacity操作来增加ArrayList实例的容量,这样可以减少递增式再分配的数量. 所以如果我
-

详解JavaFX桌面应用开发-Group(容器组)
1:Group的功能 Group可以管理一组节点 Group可以对管理的节点进行增删改查的操作 Group可以管理节点的属性 1.2:看看JDKSE1.9的API Group类有下列可以调用的方法 2:Group的使用 代码如下: package application; import javafx.application.Application; import javafx.scene.Group; import javafx.scene.Scene; import javafx.scene.
-
基于spring-boot和docker-java实现对docker容器的动态管理和监控功能[附完整源码下载]
docker简介 Docker 是一个开源的应用容器引擎,和传统的虚拟机技术相比,Docker 容器性能开销极低,因此也广受开发者喜爱.随着基于docker的开发者越来越多,docker的镜像也原来越丰富,未来各种企业级的完整解决方案都可以直接通过下载镜像拿来即用.因此docker变得越来越重要. 本文目的 本文通过一个项目实例来介绍如果通过docker对外接口来实现对docker容器的管理和监控. 应用场景: 对服务器资源池通过docker进行统一管理,按需分配资源和创建容器,达到资源最大化利
-
spring boot基于Java的容器配置讲解
spring容器是负责实例化.配置.组装组件的容器. 容器的配置有很多,常用的是xml.Java注解和Java代码. 在spring中Ioc容器相关部分是context和beans中.其中context-support保存着许多线程的容器实现.比如AnnotationConfigApplicationContext或者ClassPathXmlApplicationContext.两者只有接收的目标不同,前者接收Java类后者接收Xml文件.但作为spring容器的不同实现殊途同归. 下面我通过s
-
Java同步容器和并发容器详解
同步容器 在 Java 中,同步容器主要包括 2 类: Vector.Stack.HashTableCollections 类中提供的静态工厂方法创建的类(由 Collections.synchronizedXxxx 等方法) Collections类中提供的静态工厂方法创建的类 Vector 实现了 List 接口,Vector 实际上就是一个数组,和 ArrayList 类似,但是Vector 中的方法都是 synchronized 方法,即进行了同步措施. Stack 也是一个同步容器,它
-
Java容器类源码详解 Deque与ArrayDeque
前言 Queue 也是 Java 集合框架中定义的一种接口,直接继承自 Collection 接口.除了基本的 Collection 接口规定测操作外,Queue 接口还定义一组针对队列的特殊操作.通常来说,Queue 是按照先进先出(FIFO)的方式来管理其中的元素的,但是优先队列是一个例外. Deque 接口继承自 Queue接口,但 Deque 支持同时从两端添加或移除元素,因此又被成为双端队列.鉴于此,Deque 接口的实现可以被当作 FIFO队列使用,也可以当作LIFO队列(栈)来使用
-
Java从同步容器到并发容器的操作过程
引言 容器是Java基础类库中使用频率最高的一部分,Java集合包中提供了大量的容器类来帮组我们简化开发,我前面的文章中对Java集合包中的关键容器进行过一个系列的分析,但这些集合类都是非线程安全的,即在多线程的环境下,都需要其他额外的手段来保证数据的正确性,最简单的就是通过synchronized关键字将所有使用到非线程安全的容器代码全部同步执行.这种方式虽然可以达到线程安全的目的,但存在几个明显的问题:首先编码上存在一定的复杂性,相关的代码段都需要添加锁.其次这种一刀切的做法在高并发情况下性
-
Java并发编程之同步容器与并发容器详解
一.同步容器 1.Vector-->ArrayList vector 是线程(Thread)同步(Synchronized)的,所以它也是线程安全的: Arraylist是线程异步(ASynchronized)的,是不安全的: 2.Hashtable-->HashMap Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable: HashMap是非synchronized,这意味着HashMap是非线程安全的; 3.Coll
-
Java并发容器介绍
目录 1.原子类 2.锁 3.并发容器 4.List接口下 5.Map接口下 6.Set接口下 7.Queue接口下 Java并发包(concurrent)是Java用来处理并发问题的利器,该并发包中主要有原子类,锁(lock),并发容器类等等.本系列博客主要就是介绍并发包中一些常用的并发容器,常用的类.那么就让我们一起来揭开并发包的面纱吧. 环境: 基于JDK1.8 1.原子类 首先登场的就是我们的原子类.啥是原子类?原子类用啥用? 第一个问题,啥是原子类:操作具有原子性的类,我们称之为原子类
-
java并发容器CopyOnWriteArrayList实现原理及源码分析
CopyOnWriteArrayList是Java并发包中提供的一个并发容器,它是个线程安全且读操作无锁的ArrayList,写操作则通过创建底层数组的新副本来实现,是一种读写分离的并发策略,我们也可以称这种容器为"写时复制器",Java并发包中类似的容器还有CopyOnWriteSet.本文会对CopyOnWriteArrayList的实现原理及源码进行分析. 实现原理 我们都知道,集合框架中的ArrayList是非线程安全的,Vector虽是线程安全的,但由于简单粗暴的锁同步机制,
-
Java并发容器相关知识总结
一.并发容器 1.1 JDK 提供的并发容器总结 JDK 提供的这些容器大部分在java.util.concurrent包中. ConcurrentHashMap: 线程安全的 HashMap CopyOnWriteArrayList: 线程安全的 List,在读多写少的场合性能非常好,远远好于 Vector. ConcurrentLinkedQueue: 高效的并发队列,使用链表实现.可以看做一个线程安全的 LinkedList,这是一个非阻塞队列. BlockingQueue: 这是一个接口
-
JAVA 并发容器的一些易出错点你知道吗
目录 并发容器 List Set Map Queue 单端阻塞队列 双端阻塞队列 单端非阻塞队列 双端非阻塞队列 有界与无界队列 总结 并发容器 与同步容器一样,并发容器在总体上也可以分为四大类,分别为:List.Set.Map和Queue.总体上如下图所示. 接下来,我们分别介绍下这些并发容器在使用时的注意事项和避免踩到的坑. List 并发容器中的List相对来说比较简单,就一个CopyOnWriteArrayList.大家可以从字面的意思中就能够体会到:CopyOnWrite,在写的时候进
-
Java多线程编程中的两种常用并发容器讲解
ConcurrentHashMap并发容器 ConcurrentHashMap可以做到读取数据不加锁,并且其内部的结构可以让其在进行写操作的时候能够将锁的粒度保持地尽量地小,不用对整个ConcurrentHashMap加锁. ConcurrentHashMap的内部结构 ConcurrentHashMap为了提高本身的并发能力,在内部采用了一个叫做Segment的结构,一个Segment其实就是一个类Hash Table的结构,Segment内部维护了一个链表数组,我们用下面这一幅图来看下Con
-
基于Java并发容器ConcurrentHashMap#put方法解析
jdk1.7.0_79 HashMap可以说是每个Java程序员用的最多的数据结构之一了,无处不见它的身影.关于HashMap,通常也能说出它不是线程安全的.这篇文章要提到的是在多线程并发环境下的HashMap--ConcurrentHashMap,显然它必然是线程安全的,同样我们不可避免的要讨论散列表,以及它是如何实现线程安全的,它的效率又是怎样的,因为对于映射容器还有一个Hashtable也是线程安全的但它似乎只出现在笔试.面试题里,在现实编码中它已经基本被遗弃. 关于HashMap的线程不
-
java并发容器ConcurrentHashMap深入分析
目录 前言 基础回顾 红黑树 红黑树数据结构 红黑树插入数据 多线程竞争下的读写操作 扩容原理 正在扩容 && 有多个线程正在竞争 扩容期间的读操作 扩容期间的写操作 总结 前言 我是fancy,一个年纪轻轻bug量就累计到3200个的程序员,同事们都夸我一个人养活了整个测试组. 最近迷上了并发编程.并发这玩意怎么说呢,就是你平时工作用不到,一用就用在面试上.这不,又卷起了并发容器. 那说起并发容器,你一定也知道那几个,CopyOnWriteArrayList.并发队列BlockingQu