如何将yolov5中的PANet层改为BiFPN详析
目录
- 一、Add
- 二、Concat
- 总结
本文以YOLOv5-6.1版本为例
一、Add
1.在common.py后加入如下代码
# 结合BiFPN 设置可学习参数 学习不同分支的权重
# 两个分支add操作
class BiFPN_Add2(nn.Module):
def __init__(self, c1, c2):
super(BiFPN_Add2, self).__init__()
# 设置可学习参数 nn.Parameter的作用是:将一个不可训练的类型Tensor转换成可以训练的类型parameter
# 并且会向宿主模型注册该参数 成为其一部分 即model.parameters()会包含这个parameter
# 从而在参数优化的时候可以自动一起优化
self.w = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
self.conv = nn.Conv2d(c1, c2, kernel_size=1, stride=1, padding=0)
self.silu = nn.SiLU()
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon)
return self.conv(self.silu(weight[0] * x[0] + weight[1] * x[1]))
# 三个分支add操作
class BiFPN_Add3(nn.Module):
def __init__(self, c1, c2):
super(BiFPN_Add3, self).__init__()
self.w = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
self.conv = nn.Conv2d(c1, c2, kernel_size=1, stride=1, padding=0)
self.silu = nn.SiLU()
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化
# Fast normalized fusion
return self.conv(self.silu(weight[0] * x[0] + weight[1] * x[1] + weight[2] * x[2]))
2.yolov5s.yaml进行修改
# YOLOv5 by Ultralytics, GPL-3.0 license # Parameters nc: 80 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple anchors: - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 # YOLOv5 v6.0 backbone backbone: # [from, number, module, args] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3, [1024]], [-1, 1, SPPF, [1024, 5]], # 9 ] # YOLOv5 v6.0 BiFPN head head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, BiFPN_Add2, [256, 256]], # cat backbone P4 [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, BiFPN_Add2, [128, 128]], # cat backbone P3 [-1, 3, C3, [256, False]], # 17 (P3/8-small) [-1, 1, Conv, [512, 3, 2]], # 为了BiFPN正确add,调整channel数 [[-1, 13, 6], 1, BiFPN_Add3, [256, 256]], # cat P4 <--- BiFPN change 注意v5s通道数是默认参数的一半 [-1, 3, C3, [512, False]], # 20 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, BiFPN_Add2, [256, 256]], # cat head P5 [-1, 3, C3, [1024, False]], # 23 (P5/32-large) [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]
3.修改yolo.py,在parse_model函数中找到elif m is Concat:语句,在其后面加上BiFPN_Add相关语句:
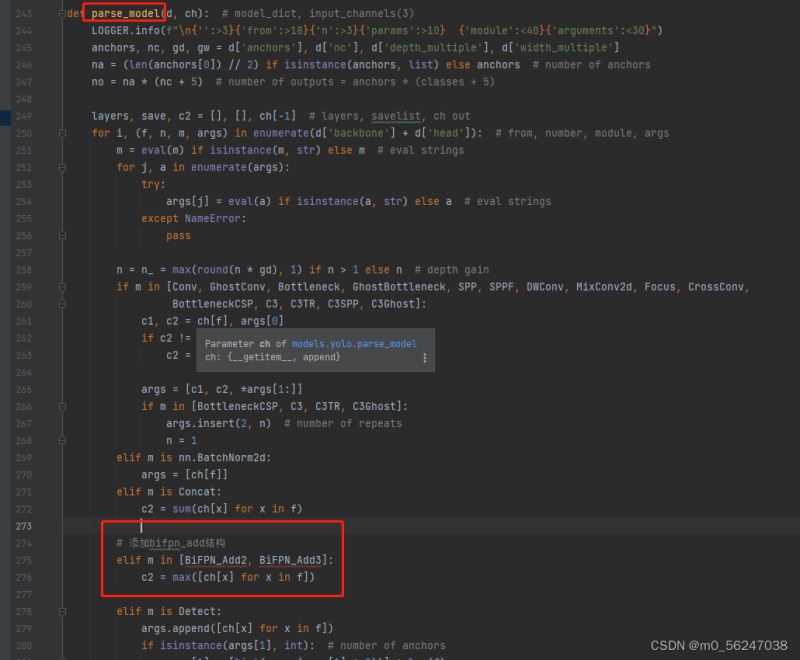
# 添加bifpn_add结构
elif m in [BiFPN_Add2, BiFPN_Add3]:
c2 = max([ch[x] for x in f])
4.修改train.py,向优化器中添加BiFPN的权重参数
将BiFPN_Add2和BiFPN_Add3函数中定义的w参数,加入g1
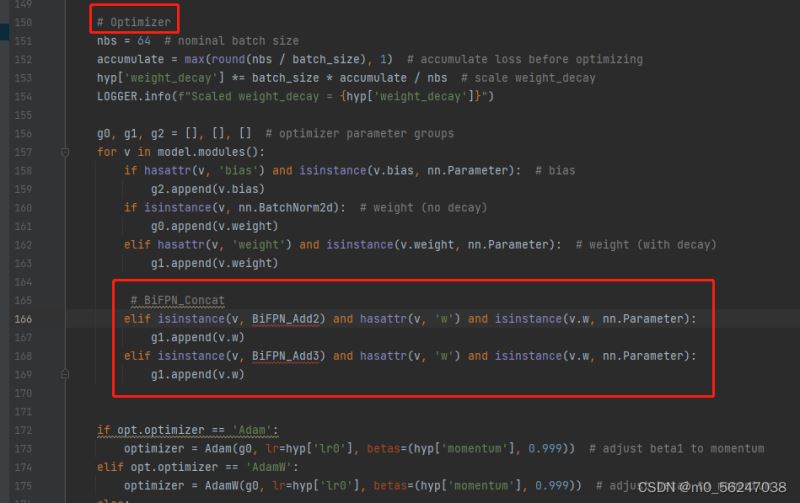
# BiFPN_Concat
elif isinstance(v, BiFPN_Add2) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
g1.append(v.w)
elif isinstance(v, BiFPN_Add3) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
g1.append(v.w)
然后导入一下这两个包

二、Concat
1.在common.py后加入如下代码
# 结合BiFPN 设置可学习参数 学习不同分支的权重
# 两个分支concat操作
class BiFPN_Concat2(nn.Module):
def __init__(self, dimension=1):
super(BiFPN_Concat2, self).__init__()
self.d = dimension
self.w = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化
# Fast normalized fusion
x = [weight[0] * x[0], weight[1] * x[1]]
return torch.cat(x, self.d)
# 三个分支concat操作
class BiFPN_Concat3(nn.Module):
def __init__(self, dimension=1):
super(BiFPN_Concat3, self).__init__()
self.d = dimension
# 设置可学习参数 nn.Parameter的作用是:将一个不可训练的类型Tensor转换成可以训练的类型parameter
# 并且会向宿主模型注册该参数 成为其一部分 即model.parameters()会包含这个parameter
# 从而在参数优化的时候可以自动一起优化
self.w = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化
# Fast normalized fusion
x = [weight[0] * x[0], weight[1] * x[1], weight[2] * x[2]]
return torch.cat(x, self.d)
2.yolov5s.yaml进行修改
# YOLOv5 by Ultralytics, GPL-3.0 license # Parameters nc: 80 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple anchors: - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 # YOLOv5 v6.0 backbone backbone: # [from, number, module, args] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3, [1024]], [-1, 1, SPPF, [1024, 5]], # 9 ] # YOLOv5 v6.0 BiFPN head head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, BiFPN_Concat2, [1]], # cat backbone P4 <--- BiFPN change [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, BiFPN_Concat2, [1]], # cat backbone P3 <--- BiFPN change [-1, 3, C3, [256, False]], # 17 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14, 6], 1, BiFPN_Concat3, [1]], # cat P4 <--- BiFPN change [-1, 3, C3, [512, False]], # 20 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, BiFPN_Concat2, [1]], # cat head P5 <--- BiFPN change [-1, 3, C3, [1024, False]], # 23 (P5/32-large) [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]
3.修改yolo.py,在parse_model函数中找到elif m is Concat:语句,在其后面加上BiFPN_Concat相关语句:
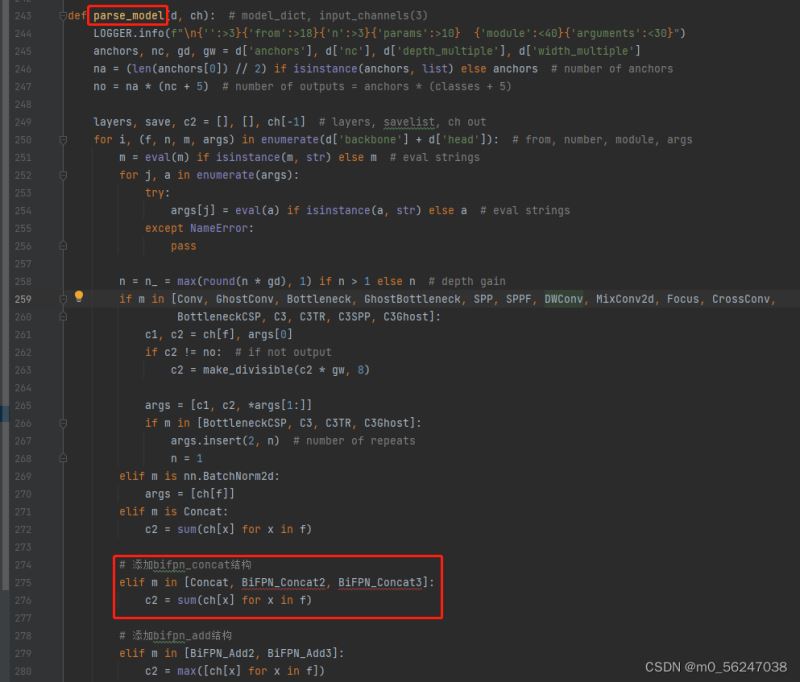
# 添加bifpn_concat结构
elif m in [Concat, BiFPN_Concat2, BiFPN_Concat3]:
c2 = sum(ch[x] for x in f)
4.修改train.py,向优化器中添加BiFPN的权重参数
添加复方式同上(Add)
# BiFPN_Concat
elif isinstance(v, BiFPN_Concat2) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
g1.append(v.w)
elif isinstance(v, BiFPN_Concat3) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
g1.append(v.w)
至此,大功告成~~~
reference:
【YOLOv5-6.x】设置可学习权重结合BiFPN(Add操作)
【YOLOv5-6.x】设置可学习权重结合BiFPN(Concat操作)
总结
到此这篇关于如何将yolov5中的PANet层改为BiFPN的文章就介绍到这了,更多相关yolov5 PANet层改BiFPN内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

如何将yolov5中的PANet层改为BiFPN详析
目录 一.Add 二.Concat 总结 本文以YOLOv5-6.1版本为例 一.Add 1.在common.py后加入如下代码 # 结合BiFPN 设置可学习参数 学习不同分支的权重 # 两个分支add操作 class BiFPN_Add2(nn.Module): def __init__(self, c1, c2): super(BiFPN_Add2, self).__init__() # 设置可学习参数 nn.Parameter的作用是:将一个不可训练的类型Tensor转换成可以训练的类型
-
微信小程序swiper-dot中的点如何改成滑块详解
目录 背景 目标效果 思路 实现 swiper监听change 自定义dot模块 change事件中的逻辑 写在最后 本文主要介绍如何基于已有的组件(比如微信小程序的swiper,还有我们平时h5用的比较多的swiper.js等),实现一个滑块样式的指示面板.demo基于小程序,但是逻辑通用. 背景 最近要做一个新的小程序,在首页部分有一个swiper模块,因为设计同学的出色发挥
-
Android页面中引导蒙层的使用方法详解
蒙层是什么,蒙层是一层透明的呈灰色的视图,是在用户使用App时让用户快速学会使用的一些指导.类似于一些引导页面,只不过比引导页面更加生动形象而已.在GitHub上有具体的demo. 地址为 github源码地址,需要的可以去上面下载源码看看 使用引导蒙层非常简单,只要在你的项目中导入一个GuideView类即可,当然,别忘了在values的资源文件下加上相应的一些数值. 下面是GuideView的原码 public class GuideView extends RelativeLayout
-
Vue3.0中Ref与Reactive的区别示例详析
目录 Ref与Reactive Ref Reactive Ref与Reactive的区别 shallowRef 与shallowReactive toRaw ---只修改数据不渲染页面 markRaw --- 不追踪数据 toRef --- 跟数据源关联 不修改UI toRefs ---设置多个toRef属性值 customRef ---自定义一个ref ref 捆绑页面的标签 总结 Ref与Reactive Ref Ref 用来创建基础类型的响应式数据,模板默认调用value显示数据.方法中修
-
Javascript中click与blur事件的顺序详析
一.现象 最近在开发中碰到了一个需求,具体需求如下图. 这是一个很常见的需求,input框负责在点击回车和失焦的时候确认输入.button负责清除输入,input绑定代码为: input.addEventListener('blur',function(){ console.log('input blur'); }); input.addEventListener('keyup',function(){ console.log('input keyup'); }); "X"绑定的代码为
-
Linux中改变文件权限的chmod命令详析
前言 Linux的chmod命令是用来改变文件权限的,对于文件或者目录的普通权限,共有 3 种,分别为: r:读取: w:写入: x:执行. 今天为大家详细介绍下chmod命令的意义和用法 chmod命令 改变文件权限 一.符号模式 命令格式: chmod [who] operator [permission] filename who包含的选项及其含义: u 文件属主权限. g 属组用户权限. o 其他用户权限. a 所有用户(文件属主.属组用户及其他用户). operator包含的选项及其含
-
golang中定时器cpu使用率高的现象详析
前言: 废话少说,上线一个用golang写的高频的任务派发系统,上线跑着很稳定,但有个缺点就是当没有任务的时候,cpu的消耗也在几个百分点. 平均值在3%左右的cpu使用率.你没有任务的时候,cpu还跑到3%,这个说不过去呀.通过查看进程pidstat捕获得知,system系统的cpu消耗也不少. sys的cpu占用率高一般是由于大量的syscall系统调用引起的-. 下面的截图是用strace统计出来的系统调用-. 我们发现 futex 和 pselect6 的syscall非常的多-.
-
python中时间转换datetime和pd.to_datetime详析
前言 我们在python对数据进行操作时,经常会选取某一时间段的数据进行分析.这里为大家介绍两个我经常用到的用来选取某一时间段数据的函数:datetime( )和pd.to_datetime( ). (一)datetime( ) (1)获取指定的时间和日期.datetime(%Y,%m,%d,%H,%M,%S) datetime共有6个参数,分别代表的是年月日时分秒.其中年月日是必须要传入的参数,时分秒可以不传入,默认全为零. eg: (2)将Str和Unicode转化为datetimedate
-
Laravel中为什么不使用blpop取队列详析
前言 Redis 的 list 数据结构常用来做消息队列,通常使用的命令有 lpop/rpop ,还有带阻塞版的 blpop/brpop 等.Laravel 5.3 消息队列也是用的 lpop 取消息,为什么不用阻塞版的 blpop 呢? blpop 不用一直轮询,还可以同时取多个队列,blpop high low 30,更方便实现队列的优先级. 安全队列和不安全队列 什么是不安全的队列?比如客户端 lpop(统一以 lpop 为例) 从 redis 取出来的 job(任务)还没处理完进程挂掉了
-
C++中4种强制类型转换的区别详析
前言 C++即支持C风格的类型转换,又有自己风格的类型转换.C风格的转换格式很简单,但是有不少缺点的: 1.转换太过随意,可以在任意类型之间转换.你可以把一个指向const对象的指针转换成指向非const对象的指针,把一个指向基类对象的指针转换成一个派生类对象的指针,这些转换之间的差距是非常巨大的,但是传统的C语言风格的类型转换没有区分这些. 2.C风格的转换没有统一的关键字和标示符.对于大型系统,做代码排查时容易遗漏和忽略. C++风格完美的解决了上面两个问题.1.对类型转换做了细分,提供了四