Python爬虫实现vip电影下载的示例代码
爬虫目的
实现对各大视频网站vip电影的下载,因为第三方解析网站并没有提供下载的渠道,因此想要实现电影的下载。
实现思路
1.选择一个合适的vip解析网站,这里选择了无名小站的接口,因为尝试了很多网站,有些网站想要爬取很困难,无名小站相对简单,接口为www.wmxz.wang/video.php?url=[vip电影的链接]
2.利用Fiddler进行抓包,模拟浏览器发送post请求,获取电影实际下载地址。
3.使用PyQt5进行包装,实现多样化的功能。(可选)
页面分析
我使用Fiddler抓包,首先,浏览器进入接口,这里随便加一个vip电影的链接,然后来看post请求:
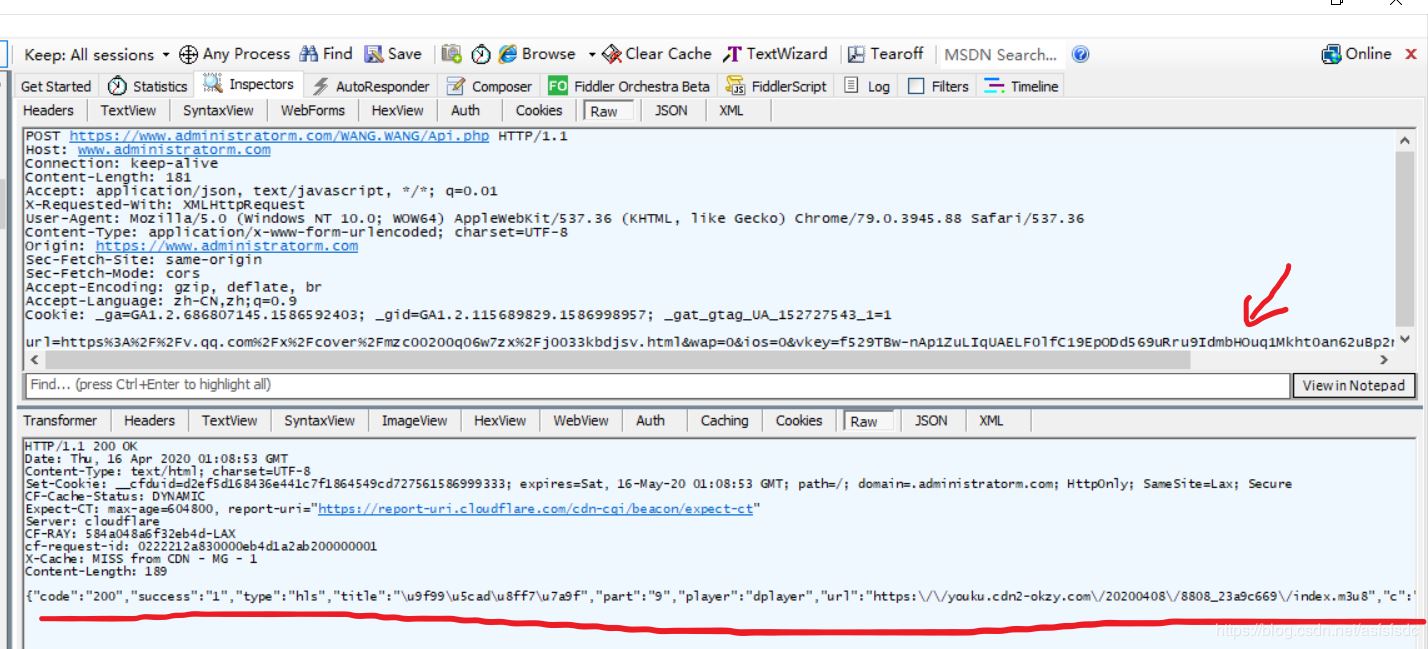
我们已经知道了提交post请求的url,箭头所指的地方是提交的表单,里面的url就是我们要下载vip电影的ur,出现%3F这些是因为将url编码为了ASCII码,这里可能使用urllib对其进行解析,很简单;vkey需要我们获取,其实它就藏在Post请求之前get请求返回的页面中,vkey是动态变化的,每一次都不一样。红线部分是服务器返回的信息,前几天我爬取的时候里面的url还是电影的下载链接,现在变成了一个m3u8文件,里面的网址也是编码后的,我们需要用urllib进行解码,我们手动打开https://youku.cdn2-okzy.com/20200408/8808_23a9c669/index.m3u8看看里面的内容,下载后打开

发现里面并没有我们想要的ts文件,但是在文件中有一行1000k/hls/index.m3u8,也是以m3u8为后缀的,使用前面的url与文件中的部分地址拼接,结果为: https://youku.cdn2-okzy.com/20200408/8808_23a9c669/1000k/hls/index.m3u8,再次用浏览器手动打开,下载内容后发现里面是一个个ts文件,最后将ts文件下载后拼接即可(因为我爬的时候还是电影链接,写博客时发现改了,所以拼接方法我也不会,网上应该容易找到)。

下面我们只要获取vkey就可以得到这些ts文件地址了,我们向前看,找返回内容有vkey的get请求:
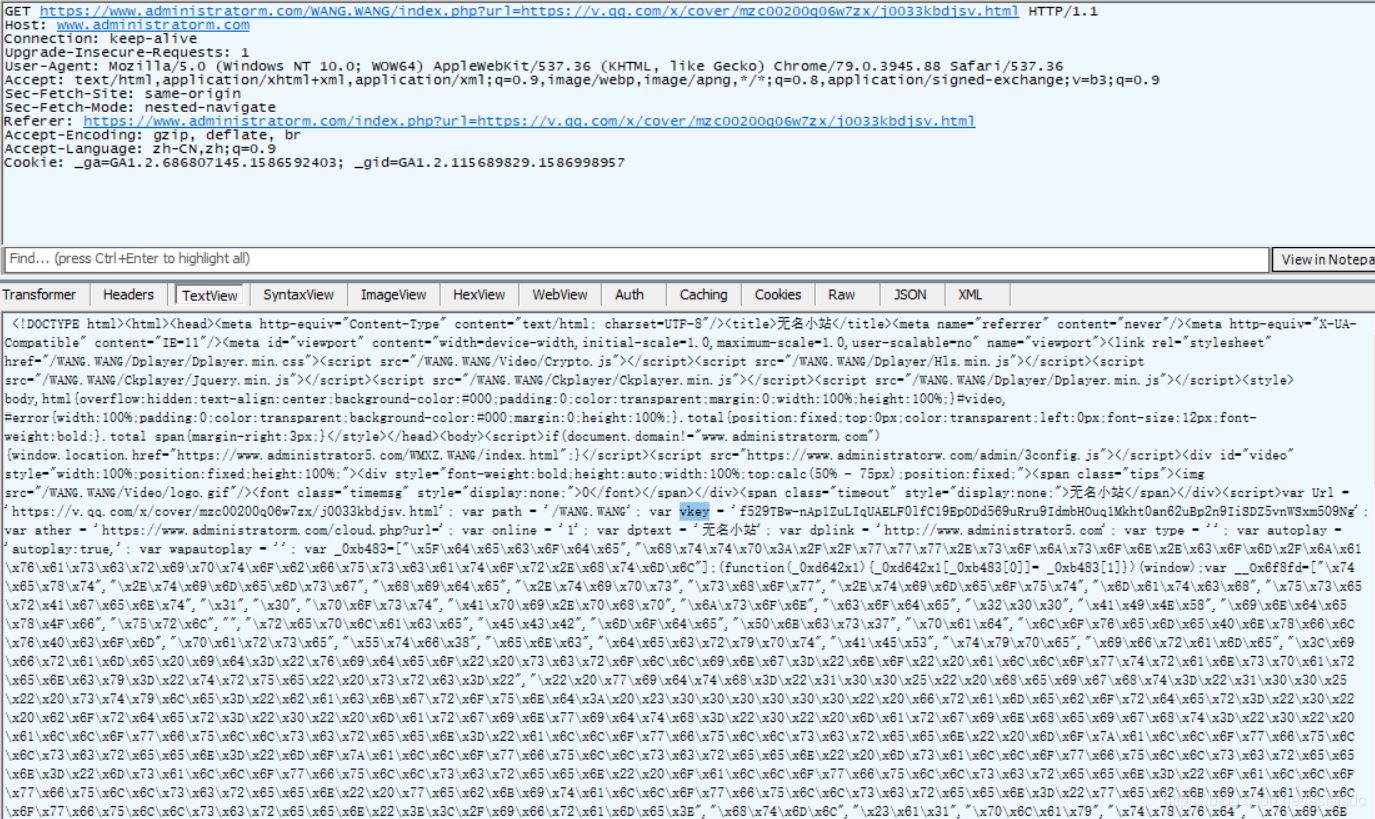
对比发现和post请求中的vkey一样,接下来就可以开始编写代码了。
代码实现
获取vkey,从上面的分析我们可以知道,get请求的网址为
https://www.administratorm.com/WANG.WANG/index.php?url=[要下载的vip电影]
我采用输入链接的方式来拼接get请求要访问的url,顺便使用urllib库将输入链接编码,方便后面的post请求使用
headers1 = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
'Referer':'https://www.administratorm.com/index.php?url=https://v.qq.com/x/cover/mzc00200q06w7zx/j0033kbdjsv.html'
}
headers2 = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'}
#定义接口链接
api_url = 'https://www.administratorm.com/WANG.WANG/Api.php'
input_url = input("请输入电影url链接:")
print("请稍等!")
get_key_url = 'https://www.administratorm.com/WANG.WANG/index.php?url='+input_url
parsed_url = parse.quote(input_url,safe='')
这里创建一个会话,会话是用于服务器记录用户身份的,然后就是发送get请求,获取网页源码,然后使用re匹配到vkey的内容,这里要注意的是get请求中的verify=False参数,其实我也不太明白,是一些网站有SSl认证,加了这个参数就可以跳过认证,加了此参数可能会有很多警告,使用 logging.captureWarnings(True) 设置不显示警告。
sess = requests.session()
vkey = get_key(sess,get_key_url)
def get_key(sess,get_key_url):
logging.captureWarnings(True)
response = sess.get(get_key_url,headers=headers1,verify=False)
response.encoding=response.apparent_encoding
content = response.text
vkey = re.findall('vkey.*?\'(.*?)\'',content)[0]
return vkey
2.制作表单,获取了vkey后,我们就可以制作提交post请求的表单了,代码很简单,就不做介绍了。
datas = make_dataform(parsed_url,vkey)
def make_dataform(parsed_url,vkey):
datas = {
'url':parsed_url,
'wap':'0',
'ios':'0',
'vkey':vkey,
'type':''
}
return datas
3.发送post请求,这里再次说明,由于我原来post请求返回的信息是电影下载地址,所以我获得的url是下载地址,现在再提交post请求获得的是m3u8文件。
download_url = post(sess,datas) def post(sess,datas): response = sess.post(api_url,headers=headers2,data=datas) response.encoding=response.apparent_encoding u = json.loads(response.text) return u['url']
4.下载电影,由于链接不同,我就把我下载电影的代码放到这里,做个参考。
down_load(sess,download_url)
def down_load(sess,download_url):
print("正在准备下载电影")
response = requests.get(download_url,headers=headers2,verify=False)
total_size = response.headers['Content-Length']
print("将要下载的电影大小:{}MB".format(round(int(total_size)/1024/1024,2)))
batch_size = int(total_size)//100
#返回迭代器:是将二进制流按大小分割之后的
k = input("请输入文件路径(C/D):")
filename = input("请输入保存文件名:")
with open(r"{}:/电影/".format(k)+filename+".mp4",'wb') as f:
i = 0
for content in response.iter_content(chunk_size=batch_size):
f.write(content)
print('\r','#'*i+' 已下载{}%'.format(i),end='\r',flush=True)
i += 1
print("下载成功")
程序界面
使用PyQt5将上面的代码包装起来,使其更加美观,并添加一些功能,由于WebEngineView已经不能播放flash了,并且有些需要新建标签的链接打不开,所以中间的浏览器很鸡肋,就图个好看吧。

这里就不详细讲了,PyQt5也比较简单,容易上手,如果需要的话联系我吧。
总结
这是我第一次写博客,如果哪里有问题请及时指出来,欢迎大家指正错误,此爬虫项目只用于入门,请不要用其盈利。否则,后果自负!
到此这篇关于Python爬虫实现vip电影下载的示例代码的文章就介绍到这了,更多相关Python爬虫vip电影下载内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python爬虫获取图片并下载保存至本地的实例
1.抓取煎蛋网上的图片. 2.代码如下: import urllib.request import os #to open the url def url_open(url): req=urllib.request.Request(url) req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0') response=urllib.request.u
-
Python爬虫文件下载图文教程
而今天我们要说的内容是:如果在网页中存在文件资源,如:图片,电影,文档等.怎样通过Python爬虫把这些资源下载下来. 1.怎样在网上找资源: 就是百度图片为例,当你如下图在百度图片里搜索一个主题时,会为你跳出一大堆相关的图片. 还有如果你想学英语,找到一个网站有很多mp3的听力资源,这些可能都是你想获取的内容. 现在是一个互联网的时代,只要你去找,基本上能找到你想要的任何资源. 2.怎样识别网页中的资源: 以上面搜索到的百度图片为例.找到了这么多的内容,当然你可以通过手动一张张的去保存,但这样
-
python实现爬虫下载美女图片
本次爬取的贴吧是百度的美女吧,给广大男同胞们一些激励 在爬取之前需要在浏览器先登录百度贴吧的帐号,各位也可以在代码中使用post提交或者加入cookie 爬行地址:http://tieba.baidu.com/f?kw=%E7%BE%8E%E5%A5%B3&ie=utf-8&pn=0 #-*- coding:utf-8 -*- import urllib2 import re import requests from lxml import etree 这些是要导入的库,代码并没有使用正则
-
Python爬虫实现vip电影下载的示例代码
爬虫目的 实现对各大视频网站vip电影的下载,因为第三方解析网站并没有提供下载的渠道,因此想要实现电影的下载. 实现思路 1.选择一个合适的vip解析网站,这里选择了无名小站的接口,因为尝试了很多网站,有些网站想要爬取很困难,无名小站相对简单,接口为www.wmxz.wang/video.php?url=[vip电影的链接] 2.利用Fiddler进行抓包,模拟浏览器发送post请求,获取电影实际下载地址. 3.使用PyQt5进行包装,实现多样化的功能.(可选) 页面分析 我使用Fiddler抓
-
Python3.x爬虫下载网页图片的实例讲解
一.选取网址进行爬虫 本次我们选取pixabay图片网站 url=https://pixabay.com/ 二.选择图片右键选择查看元素来寻找图片链接的规则 通过查看多个图片路径我们发现取src路径都含有 https://cdn.pixabay.com/photo/ 公共部分且图片格式都为.jpg 因此正则表达式为 re.compile(r'^https://cdn.pixabay.com/photo/.*?jpg$') 通过以上的分析我们可以开始写程序了 #-*- coding:utf-8 -
-
Python实现爬虫从网络上下载文档的实例代码
最近在学习Python,自然接触到了爬虫,写了一个小型爬虫软件,从初始Url解析网页,使用正则获取待爬取链接,使用beautifulsoup解析获取文本,使用自己写的输出器可以将文本输出保存,具体代码如下: Spider_main.py # coding:utf8 from baike_spider import url_manager, html_downloader, html_parser, html_outputer class SpiderMain(object): def __ini
-

使用Python编写简单网络爬虫抓取视频下载资源
我第一次接触爬虫这东西是在今年的5月份,当时写了一个博客搜索引擎,所用到的爬虫也挺智能的,起码比电影来了这个站用到的爬虫水平高多了! 回到用Python写爬虫的话题. Python一直是我主要使用的脚本语言,没有之一.Python的语言简洁灵活,标准库功能强大,平常可以用作计算器,文本编码转换,图片处理,批量下载,批量处理文本等.总之我很喜欢,也越用越上手,这么好用的一个工具,一般人我不告诉他... 因为其强大的字符串处理能力,以及urllib2,cookielib,re,threading这些
-
Python视频爬虫实现下载头条视频功能示例
本文实例讲述了Python视频爬虫实现下载头条视频功能.分享给大家供大家参考,具体如下: 一.需求分析 抓取头条短视频 思路: 分析网页源码,查找解析出视频资源url(查看源代码,搜mp4) 对该url发起请求,返回二进制数据 将二进制数据保存为视频格式 视频链接: http://video.eastday.com/a/170612170956054127565.html 二.代码实现 # encoding: utf-8 import sys reload(sys) sys.setdefault
-
Python 利用scrapy爬虫通过短短50行代码下载整站短视频
近日,有朋友向我求助一件小事儿,他在一个短视频app上看到一个好玩儿的段子,想下载下来,可死活找不到下载的方法.这忙我得帮,少不得就抓包分析了一下这个app,找到了视频的下载链接,帮他解决了这个小问题. 因为这个事儿,勾起了我另一个念头,这不最近一直想把python爬虫方面的知识梳理梳理吗,干脆借机行事,正凑着短视频火热的势头,做一个短视频的爬虫好了,中间用到什么知识就理一理. 我喜欢把事情说得很直白,如果恰好有初入门的朋友想了解爬虫的技术,可以将就看看,或许对你的认识会有提升.如果有高手路过,
-
Python爬虫 批量爬取下载抖音视频代码实例
这篇文章主要为大家详细介绍了python批量爬取下载抖音视频,具有一定的参考价值,感兴趣的小伙伴们可以参考一下 项目源码展示: ''' 在学习过程中有什么不懂得可以加我的 python学习交流扣扣qun,934109170 群里有不错的学习教程.开发工具与电子书籍. 与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容. ''' # -*- coding:utf-8 -*- from contextlib import closing import request
-
Python爬虫实现百度图片自动下载
制作爬虫的步骤 制作一个爬虫一般分以下几个步骤: 分析需求分析网页源代码,配合开发者工具编写正则表达式或者XPath表达式正式编写 python 爬虫代码 效果预览 运行效果如下: 存放图片的文件夹: 需求分析 我们的爬虫至少要实现两个功能:一是搜索图片,二是自动下载. 搜索图片:最容易想到的是爬百度图片的结果,我们就上百度图片看看: 随便搜索几个关键字,可以看到已经搜索出来很多张图片: 分析网页 我们点击右键,查看源代码: 打开源代码之后,发现一堆源代码比较难找出我们想要的资源. 这个时候,就