Python中BeautifulSoup通过查找Id获取元素信息
比如如下的html
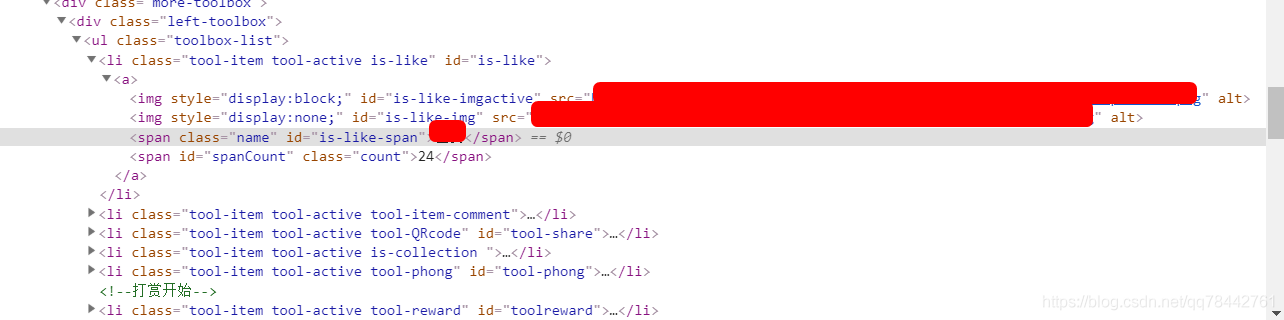
他是在span标签下的class为name,id为is-like-span
这样就可以通过这样的代码进行方法:
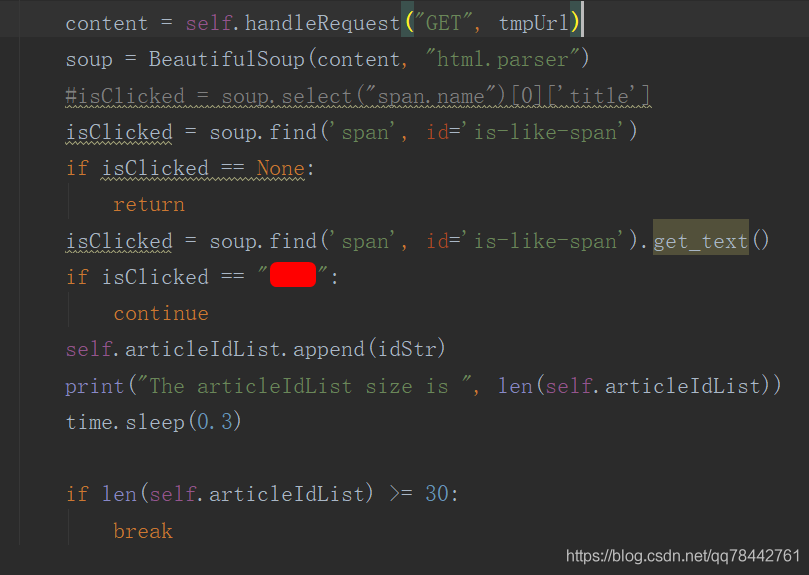
isCliked = soup.find('span', id = 'is-like-span'
通过这种方式去获取即可,如果里面的为字符串则调用get_text()即可
到此这篇关于Python中BeautifulSoup通过查找Id获取元素信息的文章就介绍到这了,更多相关BeautifulSoup Id获取元素信息内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python使用BeautifulSoup库解析HTML基本使用教程
BeautifulSoup是Python的一个第三方库,可用于帮助解析html/XML等内容,以抓取特定的网页信息.目前最新的是v4版本,这里主要总结一下我使用的v3版本解析html的一些常用方法. 准备 1.Beautiful Soup安装 为了能够对页面中的内容进行解析,本文使用Beautiful Soup.当然,本文的例子需求较简单,完全可以使用分析字符串的方式. 执行 sudo easy_install beautifulsoup4 即可安装. 2.requests模块的安装 reque
-
python利用beautifulSoup实现爬虫
以前讲过利用phantomjs做爬虫抓网页 http://www.jb51.net/article/55789.htm 是配合选择器做的 利用 beautifulSoup(文档 :http://www.crummy.com/software/BeautifulSoup/bs4/doc/)这个python模块,可以很轻松的抓取网页内容 # coding=utf-8 import urllib from bs4 import BeautifulSoup url ='http://www.baidu.
-
python基于BeautifulSoup实现抓取网页指定内容的方法
本文实例讲述了python基于BeautifulSoup实现抓取网页指定内容的方法.分享给大家供大家参考.具体实现方法如下: # _*_ coding:utf-8 _*_ #xiaohei.python.seo.call.me:) #win+python2.7.x import urllib2 from bs4 import BeautifulSoup def jd(url): page = urllib2.urlopen(url) html_doc = page.read() soup = B
-
python BeautifulSoup使用方法详解
直接看例子: 复制代码 代码如下: #!/usr/bin/python# -*- coding: utf-8 -*-from bs4 import BeautifulSouphtml_doc = """<html><head><title>The Dormouse's story</title></head><body><p class="title"><b>T
-
python3第三方爬虫库BeautifulSoup4安装教程
Python3安装第三方爬虫库BeautifulSoup4,供大家参考,具体内容如下 在做Python3爬虫练习时,从网上找到了一段代码如下: #使用第三方库BeautifulSoup,用于从html或xml中提取数据 from bs4 import BeautifulSoup 自己实践后,发现出现了错误,如下所示: 以上错误提示是说没有发现名为"bs4"的模块.即"bs4"模块未安装. 进入Python安装目录,以作者IDE为例, 控制台提示第三
-
python爬虫之BeautifulSoup 使用select方法详解
本文介绍了python爬虫之BeautifulSoup 使用select方法详解 ,分享给大家.具体如下: <html><head><title>The Dormouse's story</title></head> <body> <p class="title" name="dromouse"><b>The Dormouse's story</b></
-
Python爬虫beautifulsoup4常用的解析方法总结
摘要 如何用beautifulsoup4解析各种情况的网页 beautifulsoup4的使用 关于beautifulsoup4,官网已经讲的很详细了,我这里就把一些常用的解析方法做个总结,方便查阅. 装载html文档 使用beautifulsoup的第一步是把html文档装载到beautifulsoup中,使其形成一个beautifulsoup对象. import requests from bs4 import BeautifulSoup url = "http://new.qq.com/o
-
python 解析html之BeautifulSoup
复制代码 代码如下: # coding=utf-8 from BeautifulSoup import BeautifulSoup, Tag, NavigableString from SentenceSpliter import SentenceSpliter from os.path import basename,dirname,isdir,isfile from os import makedirs from shutil import copyfile import io import
-
python中bs4.BeautifulSoup的基本用法
导入模块 from bs4 import BeautifulSoup soup = BeautifulSoup(html_doc,"html.parser") 下面看下常见的用法 print(soup.a) # 拿到soup中的第一个a标签 print(soup.a.name) # 获取a标签的名称 print(soup.a.string) # 获取a标签的文本内容 print(soup.a.text) # 获取a标签的文本内容 print(soup.a["href"
-

Python中BeautifulSoup通过查找Id获取元素信息
比如如下的html 他是在span标签下的class为name,id为is-like-span 这样就可以通过这样的代码进行方法: isCliked = soup.find('span', id = 'is-like-span' 通过这种方式去获取即可,如果里面的为字符串则调用get_text()即可 到此这篇关于Python中BeautifulSoup通过查找Id获取元素信息的文章就介绍到这了,更多相关BeautifulSoup Id获取元素信息内容请搜索我们以前的文章或继续浏览下面的相关文章
-
js中利用tagname和id获取元素的方法
本文分享了js中利用tagname和id获取元素的3种方法,供大家参考,具体内容如下 方法一:整体法,先获取所有的元素,再通过ai+-b的方法来算出需要的元素 方法二:数组法,在全局环境下建立空数组,遇到需要循环的结构时,在循环中获取元素,并放入数组 方法三:函数法,遇到相同的几组元素时,只操作一组元素,并用函数传参来实现所有的效果 具体代码如下 <!DOCTYPE html> <html lang="en"> <head> <meta cha
-
Python中BeautifulSoup模块详解
目录 前言 安装库 导入库 解析文档示例 提取数据示例 CSS选择器 实例小项目 总结 前言 BeautifulSoup是主要以解析web网页的Python模块,它会提供一些强大的解释器,以解析网页,然后提供一些函数,从页面中提取所需要的数据,目前是Python爬虫中最常用的模块之一. 安装库 在使用前需要安装库,这里建议安装bs4,也就是第四版本,因为根据官方文档第三版的已经停止更新.同时安装lxml解释器 pip3 install bs4 pip3 install lxml 导入库 from
-
在python中使用正则表达式查找可嵌套字符串组
在网上看到一个小需求,需要用正则表达式来处理.原需求如下: 找出文本中包含"因为--所以"的句子,并以两个词为中心对齐输出前后3个字,中间全输出,如果"因为"和"所以"中间还存在"因为""所以",也要找出来,另算一行,输出格式为: 行号 前面3个字 *因为* 全部 &所以& 后面3个字(标点符号算一个字) 2 还不是 *因为* 这里好, &所以& 没有人 实现方法如下: #e
-
Python中的is和id用法分析
本文实例讲述了Python中的is和id用法.分享给大家供大家参考.具体分析如下: (ob1 is ob2) 等价于 (id(ob1) == id(ob2)) 首先id函数可以获得对象的内存地址,如果两个对象的内存地址是一样的,那么这两个对象肯定是一个对象.和is是等价的.Python源代码为证. 复制代码 代码如下: static PyObject * cmp_outcome(int op, register PyObject *v, register PyObject *w) { int
-
Python lxml解析HTML并用xpath获取元素的方法
代码 使用方法见注释 #-*- coding: UTF-8 -*- from lxml import etree source = u''' <div><p class="p1" data-a="1">测试数据1</p> <p class="p1" data-a="2">测试数据2</p> <p class="p1" data-a="
-
mybatis中insert主键ID获取和多参数传递的示例代码
一.插入数据主键ID获取 一般我们在做业务开发时,经常会遇到插入一条数据并使用到插入数据的ID情况.如果先插入在查询的话需要多一次sql查询,未免效率太低.因此mybatis也有提供插入数据并返回主键ID的方式.如下 1.Insert/update 1.1.属性解释 keyProperty selectKey 语句结果应该被设置的目标属性.如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表. resultType 结果的类型.MyBatis 通常可以推算出来,但是为了更加确定写上也不会有什
-
js querySelector和getElementById通过id获取元素的区别
这是sina同事xiaoniu发现的,如下 <!DOCTYPE html> <html> <head> <meta charset="utf-8"/> </head> <body> <div id="02E503E2A1C011CFC85B7B701A0677EC0900000000000001"></div> <script> var str = '02E5
-
Python中的二叉树查找算法模块使用指南
python中的二叉树模块内容: BinaryTree:非平衡二叉树 AVLTree:平衡的AVL树 RBTree:平衡的红黑树 以上是用python写的,相面的模块是用c写的,并且可以做为Cython的包. FastBinaryTree FastAVLTree FastRBTree 特别需要说明的是:树往往要比python内置的dict类慢一些,但是它中的所有数据都是按照某个关键词进行排序的,故在某些情况下是必须使用的. 安装和使用 安装方法 安装环境: ubuntu12.04, py
-
深入理解Python中命名空间的查找规则LEGB
名字空间 Python 的名字空间是 Python 一个非常核心的内容. 其他语言中如 C 中,变量名是内存地址的别名,而在 Python 中,名字是一个字符串对象,它与他指向的对象构成一个{name:object}关联. Python 由很多名字空间,而 LEGB 则是名字空间的一种查找规则. 作用域 Python 中name-object的关联存储在不同的作用域中,各个不同的作用域是相互独立的.而我们就在不同的作用域中搜索name-object. 举个栗子,来说明作用域是相互独立的. In