使用docker搭建kong集群操作
docker容器下搭建kong的集群很简单,官网介绍的也很简单,初学者也许往往不知道如何去处理,经过本人的呕心沥血的琢磨,终于搭建出来了。
主要思想:不同的kong连接同一个数据库(就这么一句话)
难点:如何在不同的主机上用kong连接同一数据库
要求:
1、两台主机 172.16.100.101 172.16.100.102
步骤:
1、在101上安装数据库(这里就用cassandra)
docker run -d --name kong-database \
-p 9042:9042 \
cassandra:latest
2、迁移数据库(可以理解初始化数据库)
docker run --rm \ --link kong-database:kong-database \ -e "KONG_DATABASE=cassandra" \ -e "KONG_PG_HOST=kong-database" \ -e "KONG_CASSANDRA_CONTACT_POINTS=kong-database" \ kong:latest kong migrations up
3、安装kong
docker run -d --name kong \ --link kong-database:kong-database \ -e "KONG_DATABASE=cassandra" \ -e "KONG_PG_HOST=kong-database" \ -e "KONG_CASSANDRA_CONTACT_POINTS=kong-database" \ -e "KONG_PROXY_ACCESS_LOG=/dev/stdout" \ -e "KONG_ADMIN_ACCESS_LOG=/dev/stdout" \ -e "KONG_PROXY_ERROR_LOG=/dev/stderr" \ -e "KONG_ADMIN_ERROR_LOG=/dev/stderr" \ -p 8000:8000 \ -p 8443:8443 \ -p 8001:8001 \ -p 8444:8444 \ kong:latest
注意:以上三部都是在101上完成的,且官网上都有https://getkong.org/install/docker/?_ga=2.68209937.1607475054.1519611673-2089953626.1519354770,接下来的第四步则是在另一主机102上完成,同一主机上可以用link,不同主机的容器关联就不能使用link了,如下配置即可
4、在102上安装另一个kong,实现多节点kong集群
docker run -d --name kong\ -e "KONG_DATABASE=cassandra" \ -e "KONG_PG_HOST=kong-database" \ -e "KONG_CASSANDRA_CONTACT_POINTS=172.16.100.101" \ -e "KONG_PROXY_ACCESS_LOG=/dev/stdout" \ -e "KONG_ADMIN_ACCESS_LOG=/dev/stdout" \ -e "KONG_PROXY_ERROR_LOG=/dev/stderr" \ -e "KONG_ADMIN_ERROR_LOG=/dev/stderr" \ -p 8000:8000 \ -p 8443:8443 \ -p 8001:8001 \ -p 8444:8444 \ kong:latest
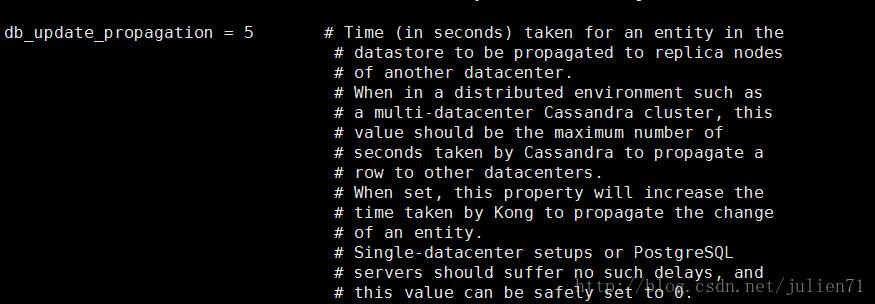
5、这里使用的是cassandra数据库,所以需要修改一个配置 db_update_propagation 这个参数,默认是0,可以改成 5,进入容器
docker exec -it kong bash //进入kong容器 cd etc/kong //进入该目录下 cp kong.conf.default kong.conf //复制kong.conf.default文件为kong.conf文件 vi kong.conf //修改db_update_propagation这个配置项
exit //退出空容器
docker restart kong //重新启动kong
注:101和102上的kong都需要修改这个配置项,关于db_update_propagation配置项的介绍可以去官网看下
6、验证kong集群
可以在101上注册一个api如下
curl -i -X POST \ --url http://172.16.100.101:8001/apis/ \ --data 'name=example-api' \ --data 'hosts=example.com' \ --data 'upstream_url=http://mockbin.org'
然后查询这个api是否注册成功:
curl -i http://172.16.100.101:8001/apis/example-api
返回如下:

你也可以通过102机器主机进行查询:
curl -i http://172.16.100.102:8001/apis/example-api
如果也返回和上面一样的结果说明可以访问同一个api了,api信息是保存在数据库中的,也是就说可以访问同一个数据库了,这样你的kong集群也就搭建成功了,希望对你有所帮助。
补充知识:使用docker-compose创建hadoop集群
下载docker镜像
首先下载需要使用的五个docker镜像
docker pull bde2020/hadoop-namenode:1.1.0-hadoop2.7.1-java8 docker pull bde2020/hadoop-datanode:1.1.0-hadoop2.7.1-java8 docker pull bde2020/hadoop-resourcemanager:1.1.0-hadoop2.7.1-java8 docker pull bde2020/hadoop-historyserver:1.1.0-hadoop2.7.1-java8 docker pull bde2020/hadoop-nodemanager:1.1.0-hadoop2.7.1-java8
设置hadoop配置参数
创建 hadoop.env 文件,内容如下:
CORE_CONF_fs_defaultFS=hdfs://namenode:8020 CORE_CONF_hadoop_http_staticuser_user=root CORE_CONF_hadoop_proxyuser_hue_hosts=* CORE_CONF_hadoop_proxyuser_hue_groups=* HDFS_CONF_dfs_webhdfs_enabled=true HDFS_CONF_dfs_permissions_enabled=false YARN_CONF_yarn_log___aggregation___enable=true YARN_CONF_yarn_resourcemanager_recovery_enabled=true YARN_CONF_yarn_resourcemanager_store_class=org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore YARN_CONF_yarn_resourcemanager_fs_state___store_uri=/rmstate YARN_CONF_yarn_nodemanager_remote___app___log___dir=/app-logs YARN_CONF_yarn_log_server_url=http://historyserver:8188/applicationhistory/logs/ YARN_CONF_yarn_timeline___service_enabled=true YARN_CONF_yarn_timeline___service_generic___application___history_enabled=true YARN_CONF_yarn_resourcemanager_system___metrics___publisher_enabled=true YARN_CONF_yarn_resourcemanager_hostname=resourcemanager YARN_CONF_yarn_timeline___service_hostname=historyserver YARN_CONF_yarn_resourcemanager_address=resourcemanager:8032 YARN_CONF_yarn_resourcemanager_scheduler_address=resourcemanager:8030 YARN_CONF_yarn_resourcemanager_resource___tracker_address=resourcemanager:8031
创建docker-compose文件
创建 docker-compose.yml 文件,内如如下:
version: "2" services: namenode: image: bde2020/hadoop-namenode:1.1.0-hadoop2.7.1-java8 container_name: namenode volumes: - hadoop_namenode:/hadoop/dfs/name environment: - CLUSTER_NAME=test env_file: - ./hadoop.env resourcemanager: image: bde2020/hadoop-resourcemanager:1.1.0-hadoop2.7.1-java8 container_name: resourcemanager depends_on: - namenode - datanode1 - datanode2 - datanode3 env_file: - ./hadoop.env historyserver: image: bde2020/hadoop-historyserver:1.1.0-hadoop2.7.1-java8 container_name: historyserver depends_on: - namenode - datanode1 - datanode2 - datanode3 volumes: - hadoop_historyserver:/hadoop/yarn/timeline env_file: - ./hadoop.env nodemanager1: image: bde2020/hadoop-nodemanager:1.1.0-hadoop2.7.1-java8 container_name: nodemanager1 depends_on: - namenode - datanode1 - datanode2 - datanode3 env_file: - ./hadoop.env datanode1: image: bde2020/hadoop-datanode:1.1.0-hadoop2.7.1-java8 container_name: datanode1 depends_on: - namenode volumes: - hadoop_datanode1:/hadoop/dfs/data env_file: - ./hadoop.env datanode2: image: bde2020/hadoop-datanode:1.1.0-hadoop2.7.1-java8 container_name: datanode2 depends_on: - namenode volumes: - hadoop_datanode2:/hadoop/dfs/data env_file: - ./hadoop.env datanode3: image: bde2020/hadoop-datanode:1.1.0-hadoop2.7.1-java8 container_name: datanode3 depends_on: - namenode volumes: - hadoop_datanode3:/hadoop/dfs/data env_file: - ./hadoop.env volumes: hadoop_namenode: hadoop_datanode1: hadoop_datanode2: hadoop_datanode3: hadoop_historyserver:
创建并启动hadoop集群
sudo docker-compose up
启动hadoop集群后,可以使用下面命令查看一下hadoop集群的容器信息
# 查看集群包含的容器,以及export的端口号 sudo docker-compose ps Name Command State Ports ------------------------------------------------------------ datanode1 /entrypoint.sh /run.sh Up 50075/tcp datanode2 /entrypoint.sh /run.sh Up 50075/tcp datanode3 /entrypoint.sh /run.sh Up 50075/tcp historyserver /entrypoint.sh /run.sh Up 8188/tcp namenode /entrypoint.sh /run.sh Up 50070/tcp nodemanager1 /entrypoint.sh /run.sh Up 8042/tcp resourcemanager /entrypoint.sh /run.sh Up 8088/tc # 查看namenode的IP地址 sudo docker inspect namenode | grep IPAddress
也可以通过 http://:50070 查看集群状态。
提交作业
要提交作业,我们首先需要登录到集群中的一个节点,这里我们就登录到namenode节点。
sudo docker exec -it namenode /bin/bash
准备数据并提交作业
cd /opt/hadoop-2.7.1 # 创建用户目录 hdfs dfs -mkdir /user hdfs dfs -mkdir /user/root # 准备数据 hdfs dfs -mkdir input hdfs dfs -put etc/hadoop/*.xml input # 提交作业 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar grep input output 'dfs[a-z.]+' # 查看作业执行结果 hdfs dfs -cat output/*
清空数据
hdfs dfs -rm input/* hdfs dfs -rmdir input/ hdfs dfs -rm output/* hdfs dfs -rmdir output/
停止集群
可以通过CTRL+C来终止集群,也可以通过 “sudo docker-compose stop”。
停止集群后,创建的容器并不会被删除,此时可以使用 “sudo docker-compose rm” 来删除已经停止的容器。也可以使用 “sudo docker-compose down” 来停止并删除容器。
删除容器后,使用 “sudo docker volume ls” 可以看到上面集群使用的volume信息,我们可以使用 “sudo docker rm ” 来删除。
以上这篇使用docker搭建kong集群操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
利用nexus作为私库进行代理docker,进行上传和下载镜像操作
一.nexus的配置 1.创建docker proxy 用于从外网仓库中拉取镜像至本地仓库中. 点击"create Repository",选择docker(proxy)进行创建 填写参数 点击"create repository" 创建 2.创建docker hosted 用于将自己的镜像上传至私库 点击"create Repository",选择docker(hosted)进行创建 填写参数: 点击"create repositor
-
解决Docker中的error during connect异常情况
刚开始接触Docker,遇到异常问题难免会手忙脚乱.没事的,学习就是这样子,在困难中不断地找到解决问题的方法,贵在坚持,加油! 来了来了,问题来了,不要慌,看下面: 我们正常打开了Docker后执行命令后报出error during connect异常. 后面给出了对应异常错误的解释: No connection could be made because the target machine actively refused it.(无法连接,因为目标机器主动拒绝它.)这下子我们知道问题在哪了
-
docker安装kong网关的方法示例
1.创建一个Docker network docker network create kong-net 2.创建数据库 以PostgreSQL为例 docker run -d --name kong-database \ --network=kong-net \ -p 5432:5432 \ -e "POSTGRES_USER=kong" \ -e "POSTGRES_DB=kong" \ postgres:9.6 3.准备数据库 docker run --rm \
-
解决docker run 或者 docker restart 启动镜像就自动退出
执行命令:docker run --name centos8 -d centos /bin/bash,通过docker ps查看正在运行中容器,找不到centos8. 通过docker ps -a查看发现,centos8容器已经处于停止状态了 [root@MiWiFi-R4A-srv server]$ docker run --name centos8 -d centos /bin/bash a770630ca865b3c3346a321a383f302ed22af9281be8482f4f4d
-
docker内网搭建dns使用域名访问替代ip:port的操作
比如我内网有个jenkins,我如果要访问它我得牢牢记住它的ip和端口,一个服务我还能记住,多个的话我可能需要一个方便记忆的域名记录一些内网服务 第1步: 准备好docker环境 第2步:下载好镜像 docker pull andyshinn/dnsmasq:2.75 第3步:运行dnsmasq #后台启动 docker run -d -p 53:53/tcp -p 53:53/udp --cap-add=NET_ADMIN --name dns-server andyshinn/dnsmasq
-
Docker 拉取镜像及标签操作 pull | tag
重翻Fabric项目的源码,发现Docker部分内容,有很多不尽理解的地方,看着看着,就看到使用docker pull拉取Fabric镜像及使用docker tag为镜像重命名,稍作思虑,发现虽然使用过,却未求甚解,得过且过,如今已经忘了如何运用-- 1. docker pull 从镜像源拉取镜像,一般来说是从Docker Hub拉取镜像(image) docker pull [OPTIONS] NAME[:TAG|@DIGEST] 选项,简写 默认 描述 –all-tags , -a 从镜像库
-
Docker容器时区调整操作
如何检查Docker容器时区是否与宿主机一致? 1.进入宿主机, 执行以下命令: # 查看宿主机时间 [root@localhost ~]# date 2018年 06月 27日 星期三 22:42:44 CST 2.进入到容器中,执行以下命令 # 查看容器时间 root@lksjoid909090:/#date Wed Jul 27 14:43:31 UTC 2018 CST应该是指(China Shanghai Time,东八区时间) UTC应该是指(Coordinated Universa
-
使用docker搭建kong集群操作
docker容器下搭建kong的集群很简单,官网介绍的也很简单,初学者也许往往不知道如何去处理,经过本人的呕心沥血的琢磨,终于搭建出来了. 主要思想:不同的kong连接同一个数据库(就这么一句话) 难点:如何在不同的主机上用kong连接同一数据库 要求: 1.两台主机 172.16.100.101 172.16.100.102 步骤: 1.在101上安装数据库(这里就用cassandra) docker run -d --name kong-database \ -p 9042:9042 \ c
-
mongodb使用docker搭建replicaSet集群与变更监听(最新推荐)
目录 安装环境 docker方式mongodb集群安装 目录与key准备 运行mongodb 配置节点 官方客户端验证 变更监听 在mongodb如果需要启用变更监听功能(watch),mongodb需要在replicaSet或者cluster方式下运行. replicaSet和cluster从部署难度相比,replicaSet要简单许多.如果所存储的数据量规模不算太大的情况下,那么使用replicaSet方式部署mongodb是一个不错的选择. 安装环境 mongodb版本:mongodb-6
-
详解docker搭建redis集群的环境搭建
本文介绍了docker搭建redis集群的环境搭建,分享给大家,废话不多说,具体如下: 下载镜像 docker pull redis 准备配置文件 mkdir /home/docker/redis/ wget https://raw.githubusercontent.com/antirez/redis/3.0/redis.conf -O /home/docker/redis/redis.conf cd /home/docker/redis/ sed -i 's/# slaveof <maste
-
ubuntu docker搭建Hadoop集群环境的方法
spark要配合Hadoop的hdfs使用,然而Hadoop的特点就是分布式,在一台主机上搭建集群有点困难,百度后发现可以使用docker构建搭建,于是开搞: github项目:https://github.com/kiwenlau/hadoop-cluster-docker 参考文章://www.jb51.net/article/109698.htm docker安装 文章中安装的是docker.io 但是我推荐安装docker-ce,docker.io版本太老了,步骤如下: 1.国际惯例更新
-

基于docker搭建redis集群的方法
下载redis镜像 docker pull yyyyttttwwww/redis 取别名 docker tag docker.io/yyyyttttwwww/redis redis 删除原先的镜像标签 docker rmi docker.io/yyyyttttwwww/redis 启动6个节点的redis容器 注意网络用的是net1 docker run -it -d --name r1 -p 5001:6379 --net=net1 --ip 172.19.0.101 redis bash
-
5分钟教你实现用docker搭建Redis集群模式和哨兵模式
如果让你为开发.测试环境分别搭一套哨兵和集群模式的redis,你最快需要多久,或许你需要一天?2小时?事实是可以更短. 是的,你已经猜到了,用docker部署,真的只需要十几分钟. 一.准备工作 拉取redis镜像 运行如下命令: docker pull redis 该命令拉取的镜像是官方镜像,当然你可以搜索其他的镜像,这里不做深入 查看镜像情况: 二.部署redis哨兵主从模式 什么是哨兵模式?--请自行百度 1.什么是docker compose? Docker Compose 可以理解为将
-
Docker搭建RabbitMQ集群的方法步骤
目录 集群模式介绍 1.普通集群的搭建 1.1.普通集群架构介绍 1.2.环境准备 1.3.集群搭建 2.镜像集群的搭建 2.1.配置镜像集群的策略 集群模式介绍 RabbitMQ集群模式有两种:普通模式和镜像模式 普通模式:默认模式,多个节点组成的普通集群,消息随机发送到其中一个节点的队列上,其他节点仅保留元数据,各个节点仅有相同的元数据,即队列结构.交换器结构.交换器与队列绑定关系.vhost.消费者消费消息时,会从各个节点拉取消息,如果保存消息的节点故障,则无法消费消息,如果做了消息持久化
-
docker搭建kafka集群的方法实现
目录 一.原生Docker命令 二.镜像选择 三.集群规划 四.Zookeeper集群安装 五.Kafka集群安装 一.原生Docker命令 1. 删除所有dangling数据卷(即无用的Volume,僵尸文件) docker volume rm $(docker volume ls -qf dangling=true) 2. 删除所有dangling镜像(即无tag的镜像) docker rmi $(docker images | grep "^<none>" | awk
-
docker搭建Zookeeper集群的方法步骤
目录 0.前言 1.前提 2.开始搭建 解释 创建zoo.cfg 3.docker搭建 1.docker创建网络 2.启动第1个zk节点 3.启动第2个zk节点 4.启动第3个zk节点 4.访问节点 1.进入zk第一个节点的docker容器内部 2.使用zk的客户端进行访问 3.在zk中使用命令 0.前言 之前在学springcloud的时候,提到有些项目还是使用zookeeper作为注册中心. 因此决定掌握这个技能,但是本地为了测试而部署一套zookeeper集群还是比较麻烦的. 所以打算使用
-
基于Docker搭建iServer集群
目录 前言 一.安装Docker 二.下载 iServer 镜像 三.启动iServer 四.发布服务 五.搭建集群 前言 Linux容器虚拟技术(LXC,Linux Container)是一种轻量级的虚拟化手段,它利用内核虚拟化技术提供轻量级的虚拟化,来隔离进程和资源.Docker扩展了LXC,提供了更高级别的API,并简化了应用的打包和部署,为终端用户创建彼此独立的私有环境,可有效节约开发者和系统管理员的环境部署时间. 一.安装Docker 参考博客 https://www.runoob.c