python selenium实现智联招聘数据爬取
一、主要目的
最近在玩Python网络爬虫,然后接触到了selenium这个模块,就捉摸着搞点有意思的,顺便记录一下自己的学习过程。
二、前期准备
- 操作系统:windows10
- 浏览器:谷歌浏览器(Google Chrome)
- 浏览器驱动:chromedriver.exe (我的版本—>89.0.4389.128 )
- 程序中我使用的模块
import csv import os import re import json import time import requests from selenium.webdriver import Chrome from selenium.webdriver.remote.webelement import WebElement from selenium.webdriver.common.by import By from selenium.webdriver.support import ui from selenium.webdriver.support import expected_conditions from lxml import etree chrome = Chrome(executable_path='chromedriver')
- 用的的第三方包均可用 pip install 进行安装
- 上面代码中的最后一行表示创建一个浏览器对象
三、思路分析
1.大致看了一下网站主页,需要先登录后才能进行信息的获取,所以只能先模拟登录。



进入登录页面的时候是显示二维码登录,我们不用这个,因为确实不怎么方便,我们通过模拟点击页面上的按钮进入到账号、密码登录的页面输入进行登录。下面是如何驱动浏览器进行上述的一系列操作⬇⬇⬇⬇⬇⬇
# 获取登录页面
chrome.get(url)
# 找出账号密码登录的页面
chrome.find_element_by_class_name('zppp-panel-qrcode-bar__triangle').click()
chrome.find_element_by_xpath('//div[@class="zppp-panel-normal__inner"]/ul/li[2]').click()
# 找到账户密码的交互接口并进行输入
user_name = chrome.find_elements_by_xpath('//div[@class="zppp-input__container"]/input')[0]
pass_word = chrome.find_elements_by_xpath('//div[@class="zppp-input__container"]/input')[1]
# 进行需要登录的账号密码输入
user_name.send_keys('**********')
pass_word.send_keys('***********')
# 输入完成后点击登录
chrome.find_element_by_class_name('zppp-submit').click()
# 此处手动实现滑块验证
# 动动你的小鼠标
2.登陆后大致看了一下主页决定先从城市开始爬,在它的原文件中分析出它的位置,如图↓
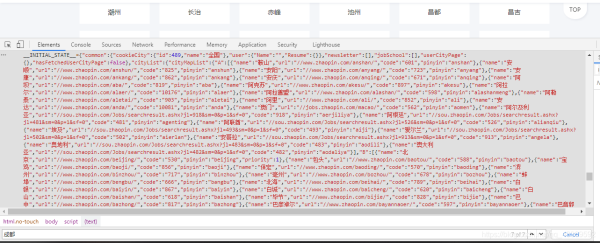
我用的是requests请求获取到网页原文件,再使用正则匹配到我们需要的内容(就是上图中那一坨红色的↑),之后再进行一系列的解析获取到每个城市与其对应的url ⬇⬇⬇⬇⬇⬇
resp = requests.get(url, headers=headers)
if resp.status_code == 200:
html = resp.text
json_data = re.search(r'<script>__INITIAL_STATE__=(.*?)</script>', html).groups()[0]
data = json.loads(json_data)
cityMapList = data['cityList']['cityMapList'] # dict
for letter, citys in cityMapList.items():
# print(f'-----{letter}-------')
for city in citys: # citys 是个列表,里面嵌套的字典
'''
{
'name': '鞍山',
'url': '//www.zhaopin.com/anshan/',
'code': '601',
'pinyin': 'anshan'
}
'''
city_name = city['name']
city_url = 'https:' + city['url']
此处我们获取的是所有的城市和它url,如果都要进行爬取的话数据量略大,因此我们可以筛选出需要爬取的城市减轻工作量,反正爬取城市我们想怎么改就怎么改哈哈哈哈哈。
3.接下来我们就可以进行工作的查找了,既然我们用的是Python来爬取的,那就查询Python相关的工作吧。
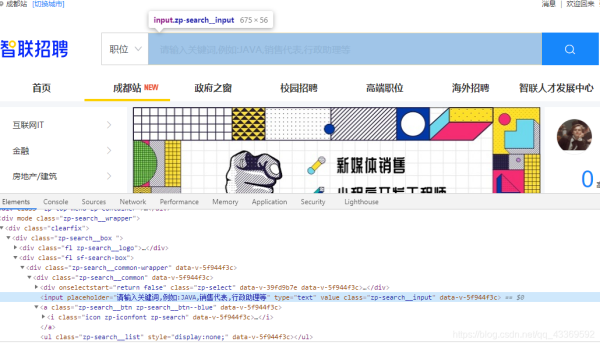
首先还是要找到输入搜索信息的框框并找出它的接口,然后进行输入(这里输入的是Python),输入完成后找到右边的搜索按钮(就是那个放大镜)进行点击操作,下面是模拟浏览器操作的代码实现⬇⬇⬇⬇⬇
# 根据class_name 查询WebElement找出输入的位置
input_seek: WebElement = chrome.find_element_by_class_name('zp-search__input')
input_seek.send_keys('Python') # 输入Python
click: WebElement =
# 找出搜索 按钮并点击
chrome.find_element_by_xpath('//div[@class="zp-search__common"]//a')
click.click()
chrome.switch_to.window(chrome.window_handles[1])
这里就有一个需要注意的地方了:在输入Python点击搜索按钮后会弹出一个新的窗口,而驱动浏览器的 程序还在第一个窗口,因此需要使用 swiitch_to_window(chrome.window_handles[n]) --<n表示目标窗口的 位置,最开始的第一个窗口是0> 方法进行窗口的切换。
4.数据的解析和提取
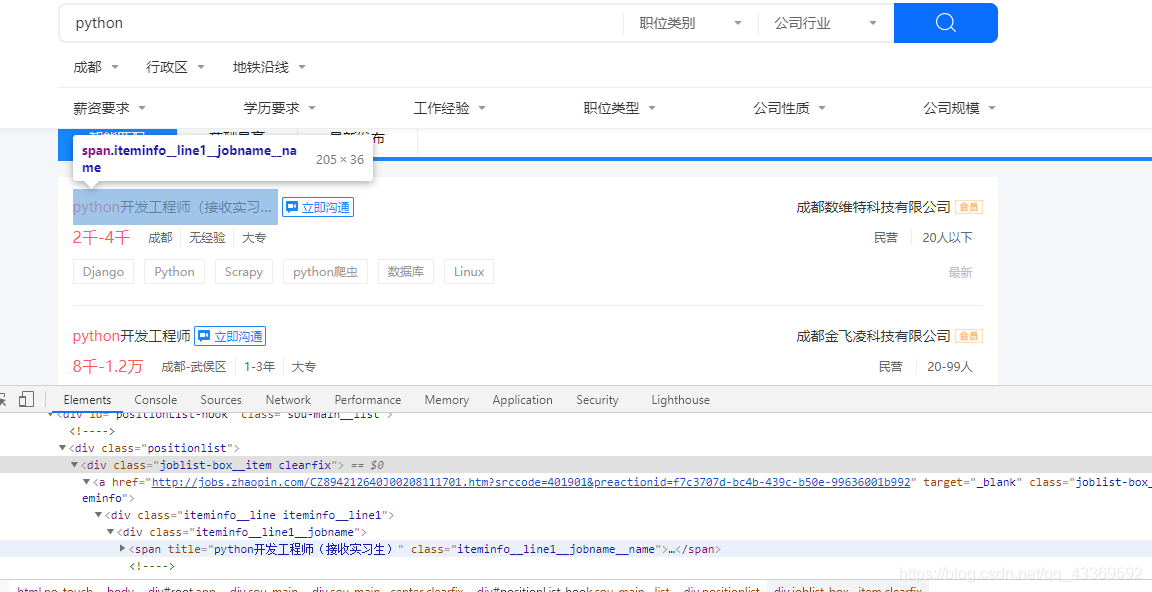
很明显可以看出需要的信息都在 class="positionlist "下,进一步分析可知数据都在 a标签下,接下来就可以使用Xpath进行数据的提取⬇⬇⬇⬇⬇
root = etree.HTML(html)
divs = root.xpath('//div[@class="positionlist"]') # element对象
for div in divs:
# 岗位 # 里面对应的是一个个列表
position = div.xpath('.//a//div[@class="iteminfo__line1__jobname"]/span[1]')
# 公司
company = div.xpath('//a//div[@class="iteminfo__line1__compname"]/span/text()')
# 薪资
money = div.xpath('.//a//div[@class="iteminfo__line2__jobdesc"]/p/text()')
# 位置
city = div.xpath('//a//div[@class="iteminfo__line2__jobdesc"]/ul/li[1]/text()')
# 经验
experience = div.xpath('.//a//div[@class="iteminfo__line2__jobdesc"]/ul/li[2]/text()')
# 学历
education = div.xpath('.//a//div[@class="iteminfo__line2__jobdesc"]/ul/li[3]/text()')
# 规模
scale = div.xpath('.//a//div[@class="iteminfo__line2__compdesc"]/span[1]/text()')
# 人数
people = div.xpath('.//a//div[@class="iteminfo__line2__compdesc"]/span[2]/text()')
5.获取下一页
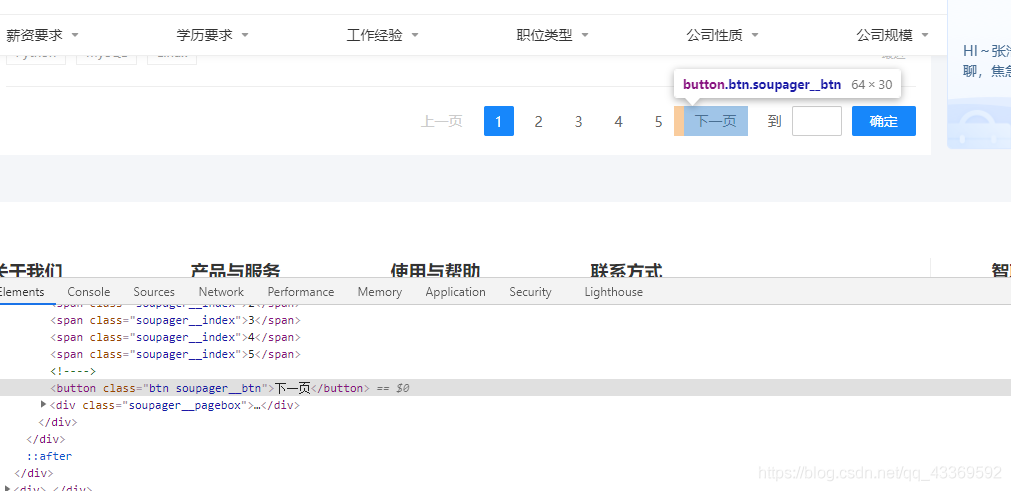
找到下一页按钮并模拟浏览器进行点击,获取到每一页所有的数据。
四、具体源代码
import csv
import os
import re
import json
import time
import requests
from selenium.webdriver import Chrome
from selenium.webdriver.remote.webelement import WebElement
from selenium.webdriver.common.by import By
from selenium.webdriver.support import ui
from selenium.webdriver.support import expected_conditions
from lxml import etree
chrome = Chrome(executable_path='chromedriver')
# 模拟登录
def login(url):
# 获取登录页面
chrome.get(url)
# 找出账号密码登录的页面
chrome.find_element_by_class_name('zppp-panel-qrcode-bar__triangle').click()
chrome.find_element_by_xpath('//div[@class="zppp-panel-normal__inner"]/ul/li[2]').click()
# 找到账户密码的交互接口并进行输入
user_name = chrome.find_elements_by_xpath('//div[@class="zppp-input__container"]/input')[0]
pass_word = chrome.find_elements_by_xpath('//div[@class="zppp-input__container"]/input')[1]
# 此处输入登录智联招聘的账号密码
user_name.send_keys('***********')
pass_word.send_keys('**********')
# 输入完成后点击登录
chrome.find_element_by_class_name('zppp-submit').click()
# 此处手动实现滑块验证
# 动动手指滑一划完成登录
time.sleep(10)
get_allcity('https://www.zhaopin.com/citymap')
# 在登录状态下进行所有城市信息的获取
def get_allcity(url):
resp = requests.get(url, headers=headers)
if resp.status_code == 200:
html = resp.text
json_data = re.search(r'<script>__INITIAL_STATE__=(.*?)</script>', html).groups()[0]
data = json.loads(json_data)
cityMapList = data['cityList']['cityMapList'] # dict
for letter, citys in cityMapList.items():
# print(f'-----{letter}-------')
for city in citys: # citys 是个列表,里面嵌套的字典
'''
{
'name': '鞍山',
'url': '//www.zhaopin.com/anshan/',
'code': '601',
'pinyin': 'anshan'
}
'''
city_name = city['name']
city_url = 'https:' + city['url']
# 筛选城市
query_citys = ('成都')
if city_name in query_citys:
print(f'正在获取{city_name}的信息')
get_city_job(city_url)
time.sleep(3)
else:
# print(f'{city_name} 不在搜索范围内!')
pass
else:
print('网页获取失败')
def get_city_job(url):
chrome.get(url) # 打开城市信息
# 根据class_name 查询WebElement找出输入的位置
input_seek: WebElement = chrome.find_element_by_class_name('zp-search__input')
input_seek.send_keys('Python') # 输入Python
click: WebElement = chrome.find_element_by_xpath('//div[@class="zp-search__common"]//a') # 找出搜索按钮并点击
click.click()
# 切换到第二个页面
chrome.switch_to.window(chrome.window_handles[1])
time.sleep(1)
time.sleep(1)
# 等待class_name为“sou-main__list” div元素出现
ui.WebDriverWait(chrome, 30).until(
expected_conditions.visibility_of_all_elements_located((By.CLASS_NAME, 'sou-main__list')),
'查找的元素一直没有出现'
)
# 判断当前查询结果是否不存在
no_content = chrome.find_elements_by_class_name('positionlist')
if not no_content:
print('当前城市未查找到Python岗位')
else:
# 提取查找结果
parse(chrome.page_source)
def parse(html):
root = etree.HTML(html)
divs = root.xpath('//div[@class="positionlist"]') # element对象
items = {}
for div in divs:
# 岗位
position = div.xpath('.//a//div[@class="iteminfo__line1__jobname"]/span[1]')
# 公司
company = div.xpath('//a//div[@class="iteminfo__line1__compname"]/span/text()')
# 薪资
money = div.xpath('.//a//div[@class="iteminfo__line2__jobdesc"]/p/text()')
# 位置
city = div.xpath('//a//div[@class="iteminfo__line2__jobdesc"]/ul/li[1]/text()')
# 经验
experience = div.xpath('.//a//div[@class="iteminfo__line2__jobdesc"]/ul/li[2]/text()')
# 学历
education = div.xpath('.//a//div[@class="iteminfo__line2__jobdesc"]/ul/li[3]/text()')
# 规模
scale = div.xpath('.//a//div[@class="iteminfo__line2__compdesc"]/span[1]/text()')
# 人数
people = div.xpath('.//a//div[@class="iteminfo__line2__compdesc"]/span[2]/text()')
for position_, company_, money_, city_, experience_, education_, scale_, people_ in zip(position, company,
money, city, experience,
education, scale,
people):
# title="python爬虫工程师" 获取它的title属性值
string = position_.attrib.get('title')
items['position'] = string
items['company'] = company_
items['money'] = money_.strip()
items['city'] = city_
items['experience'] = experience_
items['education'] = education_
items['scale'] = scale_
items['people'] = people_
itempipeline(items)
# 获取下一页
next_page()
def itempipeline(items):
has_header = os.path.exists(save_csv) # 文件头
with open(save_csv, 'a', encoding='utf8') as file:
writer = csv.DictWriter(file, fieldnames=items.keys())
if not has_header:
writer.writeheader() # 写入文件头
writer.writerow(items)
def next_page():
# 找到下一页按钮
time.sleep(0.5)
button = chrome.find_elements_by_xpath('//div[@class="soupager"]/button[@class="btn soupager__btn"]')
if not button:
print(f'获取完毕,请在 {save_csv} 里查看!!')
exit()
else:
button[0].click() # 点击下一页
time.sleep(1)
parse(chrome.page_source)
if __name__ == '__main__':
n = 0
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3823.400 QQBrowser/10.7.4307.400',
'Cookie': 'aQQ_ajkguid=B4D4C2CC-2F46-D252-59D7-83356256A4DC; id58=e87rkGBclxRq9+GOJC4CAg==; _ga=GA1.2.2103255298.1616680725; 58tj_uuid=4b56b6bf-99a3-4dd5-83cf-4db8f2093fcd; wmda_uuid=0f89f6f294d0f974a4e7400c1095354c; wmda_new_uuid=1; wmda_visited_projects=%3B6289197098934; als=0; cmctid=102; ctid=15; sessid=E454865C-BA2D-040D-1158-5E1357DA84BA; twe=2; isp=true; _gid=GA1.2.1192525458.1617078804; new_uv=4; obtain_by=2; xxzl_cid=184e09dc30c74089a533faf230f39099; xzuid=7763438f-82bc-4565-9fe8-c7a4e036c3ee'
}
save_csv = 'chengdu-python.csv'
login(
'https://passport.zhaopin.com/login?bkUrl=%2F%2Fi.zhaopin.com%2Fblank%3Fhttps%3A%2F%2Fwww.zhaopin.com%2Fbeijing%2F')
五、部分成果展示
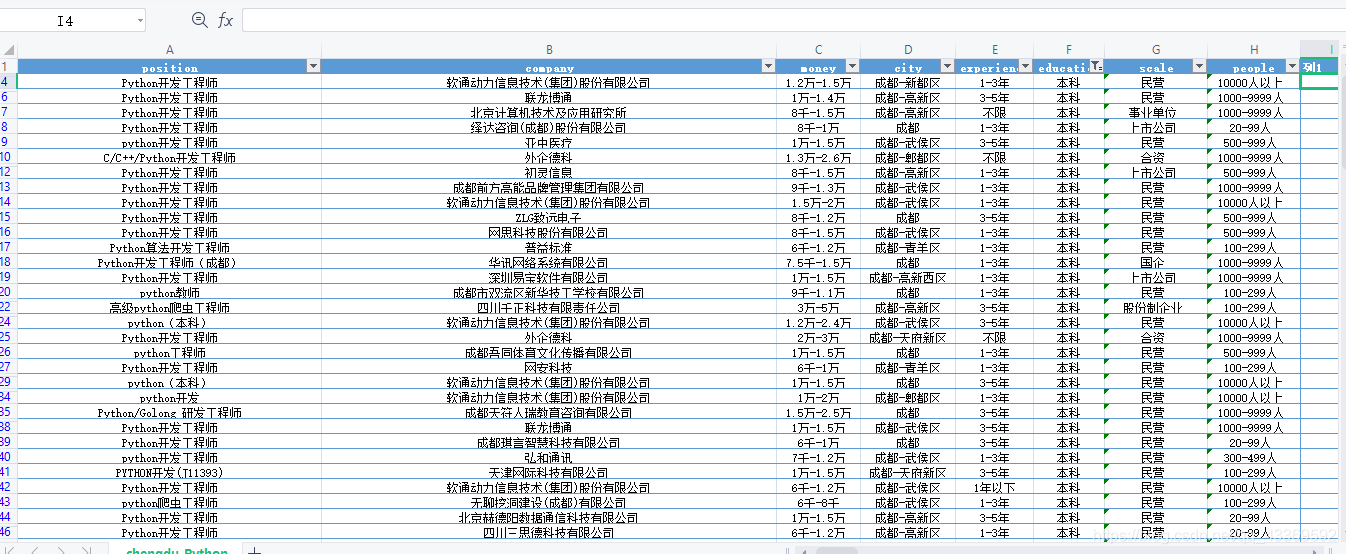
六、总结
个人认为智联的反爬还是比较友好的,为什么呢?因为之前在测试程序的时候模拟登录了好几十次,都是在短时间内,而且一开始比较担心IP被封但是最后也没出什么问题。还有就是selenium受网速影响比较大,等待时间设置过长吧,会影响程序速度,但是时间过短吧又会损数据。
到此这篇关于python selenium实现智联招聘数据爬取的文章就介绍到这了,更多相关selenium实现智联招聘爬取内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python+Selenium定位不到元素常见原因及解决办法(报:NoSuchElementException)
在做web应用的自动化测试时,定位元素是必不可少的,这个过程经常会碰到定位不到元素的情况(报selenium.common.exceptions.NoSuchElementException),一般可以从以下几个方面着手解决: 1.Frame/Iframe原因定位不到元素: 这个是最常见的原因,首先要理解下frame的实质,frame中实际上是嵌入了另一个页面,而webdriver每次只能在一个页面识别,因此需要先定位到相应的frame,对那个页面里的元素进行定位. 解决方案: 如果iframe
-
如何使用selenium和requests组合实现登录页面
这篇文章主要介绍了如何使用selenium和requests组合实现登录页面,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.在这里selenium的作用 (1)模拟的登录. (2)获取登录成功之后的cookies 代码 def start_login(self): chrome_options = Options() # 禁止图片加载,禁止推送通知 prefs = { "profile.default_content_setting_val
-
基于python requests selenium爬取excel vba过程解析
目的:基于办公与互联网隔离,自带的office软件没有带本地帮助工具,因此在写vba程序时比较不方便(后来发现07有自带,心中吐血,瞎折腾些什么).所以想到通过爬虫在官方摘录下来作为参考. 目标网站:https://docs.microsoft.com/zh-cn/office/vba/api/overview/ 所使工具: python3.7,requests.selenium库 前端方面:使用了jquery.jstree(用于方便的制作无限层级菜单 设计思路: 1.分析目标页面,可分出两部分
-

使用Selenium实现微博爬虫(预登录、展开全文、翻页)
前言 在CSDN发的第一篇文章,时隔两年,终于实现了爬微博的自由!本文可以解决微博预登录.识别"展开全文"并爬取完整数据.翻页设置等问题.由于刚接触爬虫,有部分术语可能用的不正确,请大家多指正! 一.区分动态爬虫和静态爬虫 1.静态网页 静态网页是纯粹的HTML,没有后台数据库,不含程序,不可交互,体量较少,加载速度快.静态网页的爬取只需四个步骤:发送请求.获取相应内容.解析内容及保存数据. 2.动态网页 动态网页上的数据会随时间及用户交互发生变化,因此数据不会直接呈现在网页源代码中,
-
Python + selenium + requests实现12306全自动抢票及验证码破解加自动点击功能
测试结果: 整个买票流程可以再快一点,不过为了稳定起见,有些地方等待了一些时间 完整程序,拿去可用 整个程序分了三个模块:购票模块(主体).验证码识别模块.余票查询模块 购票模块: from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.commo
-
python+selenium小米商城红米K40手机自动抢购的示例代码
使用环境 1.python3 2.selenium selenium使用简述 1.安装selenium pip install selenium 2.安装ChromeDriver 下载地址:http://chromedriver.storage.googleapis.com/index.html 注意:下载的ChromeDriver需要与Chrome版本一致. 1)Chrome版本查看: 2)ChromeDriver对应版本下载: 3)ChromeDriver下载后解压到任意文件夹,建议可以放到
-
python爬虫之利用Selenium+Requests爬取拉勾网
一.前言 利用selenium+requests访问页面爬取拉勾网招聘信息 二.分析url 观察页面可知,页面数据属于动态加载 所以现在我们通过抓包工具,获取数据包 观察其url和参数 url="https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false" 参数: city=%E5%8C%97%E4%BA%AC ==>城市 first=true ==>无用 pn=
-
python selenium实现智联招聘数据爬取
一.主要目的 最近在玩Python网络爬虫,然后接触到了selenium这个模块,就捉摸着搞点有意思的,顺便记录一下自己的学习过程. 二.前期准备 操作系统:windows10 浏览器:谷歌浏览器(Google Chrome) 浏览器驱动:chromedriver.exe (我的版本->89.0.4389.128 ) 程序中我使用的模块 import csv import os import re import json import time import requests from sele
-
Python爬取智联招聘数据分析师岗位相关信息的方法
进入智联招聘官网,在搜索界面输入'数据分析师',界面跳转,按F12查看网页源码,点击network 选中XHR,然后刷新网页 可以看到一些Ajax请求, 找到画红线的XHR文件,点击可以看到网页的一些信息 在Header中有Request URL,我们需要通过找寻Request URL的特点来构造这个请求网址, 点击Preview,可以看到我们所需要的信息就存在result中,这信息基本是json格式,有些是列表: 下面我们通过Python爬虫来爬取上面的信息: 代码如下: import req
-
python智联招聘爬虫并导入到excel代码实例
这篇文章主要介绍了python智联招聘爬虫并导入到excel代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 写了一个智联招聘的爬虫,只要输入职位关键字,就能快速导出智联招聘上的数据,存在excel表里- import requests,openpyxl #建立excel表 joblist=[] wb=openpyxl.Workbook() sheet=wb.active sheet.title='智联招聘数据' sheet['A1']=
-
Python 详解通过Scrapy框架实现爬取百度新冠疫情数据流程
目录 前言 环境部署 插件推荐 爬虫目标 项目创建 webdriver部署 项目代码 Item定义 中间件定义 定义爬虫 pipeline输出结果文本 配置文件改动 验证结果 总结 前言 闲来无聊,写了一个爬虫程序获取百度疫情数据.申明一下,研究而已.而且页面应该会进程做反爬处理,可能需要调整对应xpath. Github仓库地址:代码仓库 本文主要使用的是scrapy框架. 环境部署 主要简单推荐一下 插件推荐 这里先推荐一个Google Chrome的扩展插件xpath helper,可以验
-
Python 基于Selenium实现动态网页信息的爬取
目录 一.Selenium介绍与配置 1.Selenium简介 2. Selenium+Python环境配置 二.网页自动化测试 1.启动浏览器并打开百度搜索 2.定位元素 三.爬取动态网页的名人名言 1. 网页数据分析 2. 翻页分析 3.爬取数据的存储 4. 爬取数据 四.爬取京东网站书籍信息 五.总结 一.Selenium介绍与配置 1.Selenium简介 Selenium 是ThoughtWorks专门为Web应用程序编写的一个验收测试工具.Selenium测试直接运行在浏览器中,可以
-
基于Python的Post请求数据爬取的方法详解
为什么做这个 和同学聊天,他想爬取一个网站的post请求 观察 该网站的post请求参数有两种类型:(1)参数体放在了query中,即url拼接参数(2)body中要加入一个空的json对象,关于为什么要加入空的json对象,猜测原因为反爬虫.既有query参数又有空对象体的body参数是一件脑洞很大的事情. 一开始先在apizza网站 上了做了相关实验才发现上面这个规律的,并发现该网站的请求参数要为raw形式,要是直接写代码找规律不是一件容易的事情. 源码 import requests im
-
python爬虫scrapy基于CrawlSpider类的全站数据爬取示例解析
一.CrawlSpider类介绍 1.1 引入 使用scrapy框架进行全站数据爬取可以基于Spider类,也可以使用接下来用到的CrawlSpider类.基于Spider类的全站数据爬取之前举过栗子,感兴趣的可以康康 scrapy基于CrawlSpider类的全站数据爬取 1.2 介绍和使用 1.2.1 介绍 CrawlSpider是Spider的一个子类,因此CrawlSpider除了继承Spider的特性和功能外,还有自己特有的功能,主要用到的是 LinkExtractor()和rules
-
python使用XPath解析数据爬取起点小说网数据
1. xpath 的介绍 xpath是一门在XML文档中查找信息的语言 优点: 可以在xml中找信息 支持HTML的查找 可以通过元素和属性进行导航 但是Xpath需要依赖xml的库,所以我们需要去安装lxml的库. 安装lxml库 我们先要安装lxml的库,直接在pycharm里安装即可: XML的树形结构: 元素-元素-属性-文本 使用XPath选取节点: nodename: 选取此节点的所有节点 /从根节点选择 // 从匹配选择的当前节点选择文档中的节点,而不考虑他们的位置 . 选择当前节
-
Python实现微信好友数据爬取及分析
前言 随着微信的普及,越来越多的人开始使用微信.微信渐渐从一款单纯的社交软件转变成了一个生活方式,人们的日常沟通需要微信,工作交流也需要微信.微信里的每一个好友,都代表着人们在社会里扮演的不同角色. 今天这篇文章会基于Python对微信好友进行数据分析,这里选择的维度主要有:性别.头像.签名.位置,主要采用图表和词云两种形式来呈现结果,其中,对文本类信息会采用词频分析和情感分析两种方法.常言道:工欲善其事,必先利其器也.在正式开始这篇文章前,简单介绍下本文中使用到的第三方模块: itchat:微
-
Python实现抖音热搜定时爬取功能
目录 抖音热搜榜 requests爬取 selenium爬取 数据解析 设置定时运行 大家好,我是丁小杰. 上次和大家分享了Python定时爬取微博热搜示例介绍,堪称摸鱼神器,一个热榜不够看?今天我们再来爬取一下抖音热搜榜,感兴趣的小伙伴可以自己动手尝试一下哦. 抖音热搜榜 链接:https://tophub.today/n/K7GdaMgdQy 整个热榜共50条数据,本次爬取的内容:排名.热度.标题.链接. requests 爬取 requests 是一种非常简单的方法,由于该页面没有反爬措施