教你用Python读取CSV文件的5种方式
目录
- 第一招:简单的读取
- 第二招:用nametuple
- 第三招:用tuple类型转换
- 第四招:用DictReader
- 第五招:用字典转换
典型的数据集stocks.csv:
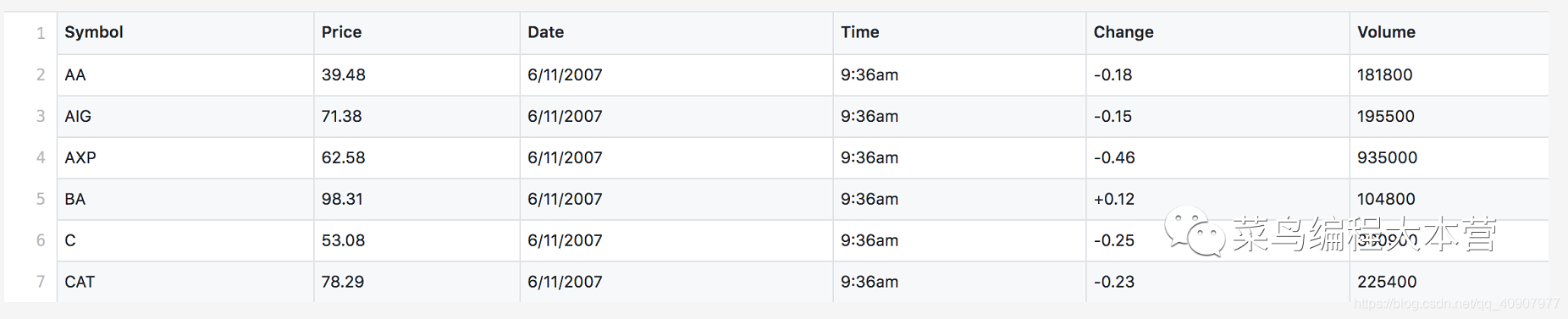
一个股票的数据集,其实就是常见的表格数据。有股票代码,价格,日期,时间,价格变动和成交量。这个数据集其实就是一个表格数据,有自己的头部和身体。
第一招:简单的读取
我们先来看一种简单读取方法,先用csv.reader()函数读取文件的句柄f生成一个csv的句柄,其实就是一个迭代器,我们看一下这个reader的源码:
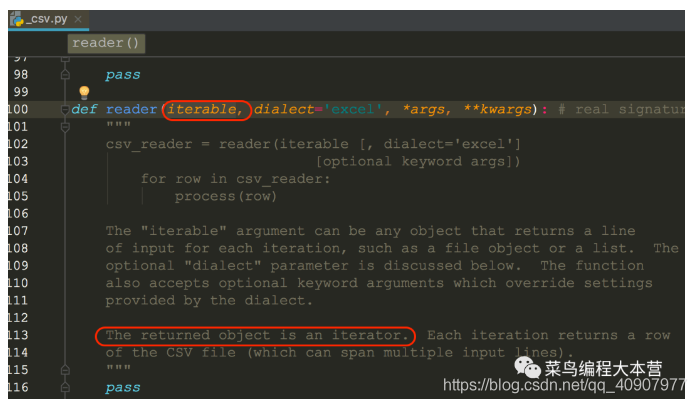
喂给reader一个可迭代对象或者是文件的object,然后返回一个可迭代对象。

- 首先读取csv 文件,然后用csv.reader生成一个csv迭代器f_csv
- 然后利用迭代器的特性,next(f_csv)获取csv文件的头,也就是表格数据的头
- 接着利用for循环,一行一行打印row的内容,也就是表格数据的身体

第二招:用nametuple
上面的第一招其实是最简单的,下面我们用nametuple 来包裹一下这个生成的row数据。

- nametuple其实是一个非常有用的类,这个类属于collections模块,而这个模块简直就是一个百宝箱里面有非常多的牛逼的库;
- 这里我们用next(f_csv)其实就是获取表格的头部来初始化这个Row;
- 然后循环来构造这个Row的数据,把我们表格里面的每一行的数据都喂成nametuple格式的row_info;
- 这样做的好处就是你可以随心所欲的访问这个row_info里面的数据,就想访问类数据一样,比如row_info.price
第三招:用tuple类型转换
如果我们对csv数据每一行的类型都非常清楚的话,嘿嘿可以用一个设定好的数据格式转换头来对数据进行转换。
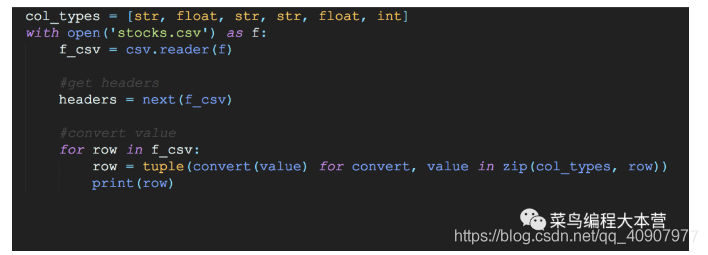
操作的步骤其实跟上面差不多,就是对数据结果的清洗处理稍微不一样。这里非常巧妙的zip来构造一个嵌套的数据列表,然后用convert(data)把csv文件里面每一行的数据进行类型转换,这招真的不错!
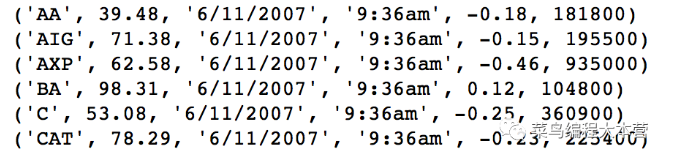
看一下结果:
第四招:用DictReader
上面用的nametuple其实也是一个数据的映射,有没有什么方法可以直接把csv 的内容用映射的方法读取,直接出来一个字典,还真有的,来看一下代码:

是不是非常简捷,原来csv模块直接内置了DictReader(),按照字典的方法进行读取,然后生成一个有序的字典,看一下结果:
有兴趣的可以看一下这个DictReader()的源码,它其实一个内部构造的迭代器类,在内部的__next__其实也是用的OrderedDict(zip(self.fieldnames, row))来生成的。
第五招:用字典转换
如果我们需要对这个csv里面的数据进行清洗,因为读出来的时候都是字符串,我们需要更新为特定的数据类型,这个时候也可以用字典转换这一招,也是非常巧妙的,我们看一下源码:

原来的数据价格Price和成交量,我希望最后读取生成的是一个浮点型数据和整形的数据,这么搞呢,用一个字典来巧妙的更新key即可。
- 首先我们声明一个自定义的类型转换器field_types;
- 然后循环生成一个可迭代的对象(key,conversion(row[key]);
- 最后更新一下字典里面相同的key,比如row[‘price']的内容就会被更新了
参考链接 :
用Python读取CSV文件的5种方式https://mp.weixin.qq.com/s/cs4buSULva1FgCctp_fB6g
到此这篇关于教你用Python读取CSV文件的5种方式的文章就介绍到这了,更多相关Python读取CSV文件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python读取csv文件分隔符设置方法
Windows下的分隔符默认的是逗号,而MAC的分隔符是分号.拿到一份用分号分割的CSV文件,在Win下是无法正确读取的,因为CSV模块默认调用的是Excel的规则. 所以我们在读取文件的时候需要添加分割符变量. import csv import os cwd = os.getcwd() print ("Current folder is %s" % (cwd) ) csvfile = open( cwd + '\data\eclipse\change-metrics.csv','r
-
python读取当前目录下的CSV文件数据
在处理数据的时候,经常会碰到CSV类型的文件,下面将介绍如何读取当前目录下的CSV文件,步骤如下 1.获取当前目录所有的CSV文件名称: #创建一个空列表,存储当前目录下的CSV文件全称 file_name = [] #获取当前目录下的CSV文件名 def name(): #将当前目录下的所有文件名称读取进来 a = os.listdir() for j in a: #判断是否为CSV文件,如果是则存储到列表中 if os.path.splitext(j)[1] == '.csv': file_
-

使用Python pandas读取CSV文件应该注意什么?
示例文件 将以下内容保存为文件 people.csv. id,姓名,性别,出生日期,出生地,职业,爱好 1,张小三,m,1992-10-03,北京,工程师,足球 2,李云义,m,1995-02-12,上海,程序员,读书 下棋 3,周娟,女,1998-03-25,合肥,护士,音乐,跑步 4,赵盈盈,Female,2001-6-32,,学生,画画 5,郑强强,男,1991-03-05,南京(nanjing),律师,历史-政治 如果一切正常的话,在Jupyter Notebook 中应该显示以下内容:
-
解决Python中pandas读取*.csv文件出现编码问题
1.问题 在使用Python中pandas读取csv文件时,由于文件编码格式出现以下问题: Traceback (most recent call last): File "pandas\_libs\parsers.pyx", line 1134, in pandas._libs.parsers.TextReader._convert_tokens File "pandas\_libs\parsers.pyx", line 1240, in pandas._libs
-
Python Pandas批量读取csv文件到dataframe的方法
PYTHON Pandas批量读取csv文件到DATAFRAME 首先使用glob.glob获得文件路径.然后定义一个列表,读取文件后再使用concat合并读取到的数据. #读取数据 import pandas as pd import numpy as np import glob,os path=r'e:\tj\month\fx1806' file=glob.glob(os.path.join(path, "zq*.xls")) print(file) dl= [] for f i
-
Python读取csv文件实例解析
这篇文章主要介绍了Python读取csv文件实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 创建一个csv文件,命名为data.csv,文本内容如下: root,123456,login successfully root,wrong,wrong password wrong,123456,nonexistent username ,123456,username is null root,,password is null 使用Exc
-
Python pandas读取CSV文件的注意事项(适合新手)
目录 前言 示例文件 文件编码 空值 日期错误 函数映射 方法1:直接使用labmda表达式 方法二:使用自定义函数 方法三:使用数值字典映射 总结 前言 本文是给使用pandas的新手而写,主要列出一些常见的问题,根据笔者所踩过的坑,进行归纳总结,希望对读者有所帮助. 示例文件 将以下内容保存为文件 people.csv. id,姓名,性别,出生日期,出生地,职业,爱好 1,张小三,m,1992-10-03,北京,工程师,足球 2,李云义,m,1995-02-12,上海,程序员,读书 下棋 3
-
python读取csv文件指定行的2种方法详解
csv是Comma-Separated Values的缩写,是用文本文件形式储存的表格数据,比如如下的表格 就可以存储为csv文件,文件内容是: No.,Name,Age,Score 1,Apple,12,98 2,Ben,13,97 3,Celia,14,96 4,Dave,15,95 假设上述csv文件保存为"A.csv",如何用Python像操作Excel一样提取其中的一行,也就是一条记录,利用Python自带的csv模块,有2种方法可以实现: 方法一:reader 第一种方法使
-
Python实现序列化及csv文件读取
这篇文章主要介绍了Python实现序列化及csv文件读取,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.python 序列化: 序列化指的是将对象转化为"串行化"数据形式,存储到硬盘或通过网路传输到其他地方,反序列化是指相反的过程,将读取到串行化数据转化成对象.使用pickle模块中的函数,实现序列化和反序列化操作. 序列化使用: pickle.dump(obj,file) obj是被序列化的对象,file指的是存储的文件. pi
-
教你用Python读取CSV文件的5种方式
目录 第一招:简单的读取 第二招:用nametuple 第三招:用tuple类型转换 第四招:用DictReader 第五招:用字典转换 典型的数据集stocks.csv: 一个股票的数据集,其实就是常见的表格数据.有股票代码,价格,日期,时间,价格变动和成交量.这个数据集其实就是一个表格数据,有自己的头部和身体. 第一招:简单的读取 我们先来看一种简单读取方法,先用csv.reader()函数读取文件的句柄f生成一个csv的句柄,其实就是一个迭代器,我们看一下这个reader的源码: 喂给re
-
python读取csv文件并把文件放入一个list中的实例讲解
如下所示: #coding=utf8 ''' 读取CSV文件,把csv文件放在一份list中. ''' import csv class readCSV(object): def __init__(self,path="Demo.csv"): #创建一个属性用来保存要操作CSV的文件 self.path=path try: #打开一个csv文件,并赋予读的权限 self.csvHand=open(self.path,"r") #调用csv的reader函数读取csv
-
python 读取.csv文件数据到数组(矩阵)的实例讲解
利用numpy库 (缺点:有缺失值就无法读取) 读: import numpy my_matrix = numpy.loadtxt(open("1.csv","rb"),delimiter=",",skiprows=0) 写: numpy.savetxt('2.csv', my_matrix, delimiter = ',') 可能遇到的问题: SyntaxError: (unicode error) 'unicodeescape' codec
-
使用python读取csv文件快速插入数据库的实例
如下所示: # -*- coding:utf-8 -*- # auth:ckf # date:20170703 import pandas as pd import cStringIO import warnings from sqlalchemy import create_engine import sys reload(sys) sys.setdefaultencoding('utf8') warnings.filterwarnings('ignore') engine = create_
-
利用Python读取CSV文件并计算某一列的均值和方差
近日需要对excel的csv文件进行处理,求取某银行历年股价的均值方差等一系列数据 文件的构成很简单,部分如下所示 总共有接近七千行数据,主要的工作就是将其中的股价数据提取出来,放入一个数组之中,然后利用numpy模块即可求出需要的数据. 这里利用了csv模块来对文件进行处理,最终实现的代码如下: import csv import numpy as np with open('pingan_stock.csv') as csv_file: row = csv.reader(csv_file,
-
Python读取csv文件做K-means分析详情
目录 1.运行环境及数据 2.基于时间序列的分析2D 2.1 2000行数据结果展示 2.2 6950行数据结果展示 2.3 300M,约105万行数据结果展示 3.经纬度高程三维坐标分类显示3D-空间点聚类 3.1 2000行数据结果显示 3.2 300M的CSV数据计算显示效果 1.运行环境及数据 Python3.7.PyCharm Community Edition 2021.1.1,win10系统. 使用的库:matplotlib.numpy.sklearn.pandas等 数据:CSV
-
Python读取CSV文件并计算某一列的均值和方差
近日需要对excel的csv文件进行处理,求取某银行历年股价的均值方差等一系列数据 文件的构成很简单,部分如下所示 总共有接近七千行数据,主要的工作就是将其中的股价数据提取出来,放入一个数组之中,然后利用numpy模块即可求出需要的数据. 这里利用了csv模块来对文件进行处理,最终实现的代码如下: import csv import numpy as np with open('pingan_stock.csv') as csv_file: row = csv.reader(csv_file,
-
Python读取CSV文件并进行数据可视化绘图
介绍:文件 sitka_weather_07-2018_simple.csv是阿拉斯加州锡特卡2018年1月1日的天气数据,其中包含当天的最高温度和最低温度.数据文件存储与data文件夹下,接下来用Python读取该文件数据,再基于数据进行可视化绘图.(详细细节请看代码注释) sitka_highs.py import csv # 导入csv模块 from datetime import datetime import matplotlib.pyplot as plt filename = 'd