浅谈哪个Python库才最适合做数据可视化
数据可视化是任何探索性数据分析或报告的关键步骤,它可以让我们一眼就能洞察数据集。目前有许多非常好的商业智能工具,比如Tableau、googledatastudio和PowerBI,它们可以让我们轻松地创建图形。
然而,数据分析师或数据科学家还是习惯使用 Python 在 Jupyter notebook 上创建可视化效果。目前最流行的用于数据可视化的 Python 库:Matplotlib、Seaborn、plotlyexpress和Altair。每个可视化库都有自己的特点,没有完美的可视化库,我们应该知道每种数据可视化的优缺点,找到适合自己的才是关键。
准备
首先,让我们导入所有重要的库。很可能你的计算机上已经安装了 Matplotlib 和 Seaborn 。但是,你可能没有Plotly Express 和 Altair。现在可以使用 pip install plotly==4.14.3和pip install altair 数据集轻松安装它们。
import pandas as pd import matplotlib.pyplot as plt %matplotlib inline import altair as alt import plotly.express as px
现在我们将导入数据集。出于演示的目的,我们只创建一个数据框架,其中包含美国人口最多的15个城市。我还将修正城市名称的大写。当我们创建可视化效果时,它将促进编辑过程。
df = pd.read_csv('worldcitiespop.csv')
us = df[df['Country'] == 'us']
us['City'] = us['City'].str.title()
cities = us[['City', 'Population']].nlargest(15, ['Population'], keep='first')
现在我们应该准备好分析每个库。你准备好了吗?
设置难度和初始结果
获胜者:Plotly Express
失败者:Matplotlib、Altair和Seaborn
在这一类中,所有的库都表现良好。它们都很容易设置,基本编辑的结果对大多数分析都足够好,但我们需要有赢家和输家,对吗?
Matplotlib 很容易设置和记住代码。然而,这个图表看起来并不好。它可能会完成数据分析的工作,但在商务会议上的结果并不理想。

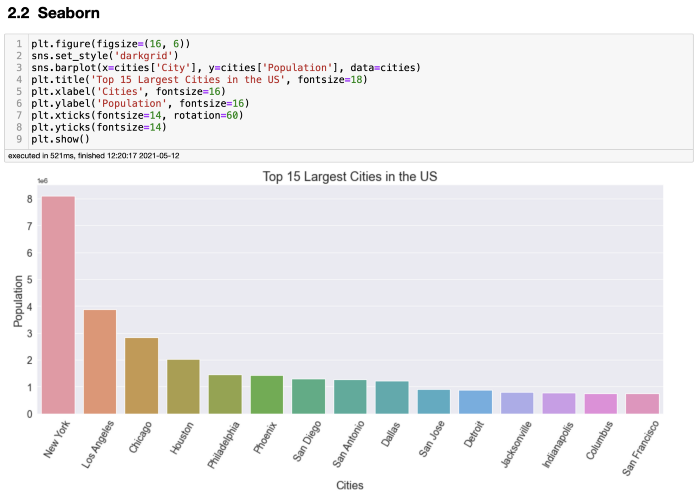
Seaborn 创造了一个更好的图表。它会自动添加 x 轴和 y 轴标签。x 记号看起来更好,但对于基本图表来说,这比 Matplotlib 要好得多。

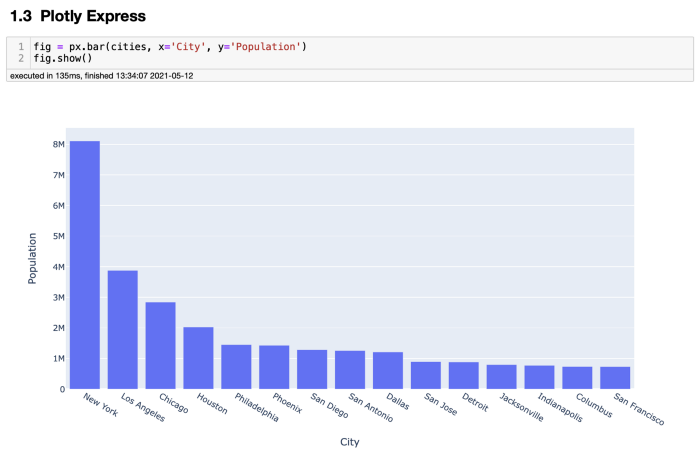
Plotly Expres,表现得非常出色。可以用很少的代码创建一个好看的、专业的条形图。不需要设置图形或字体大小。它甚至可以旋转 x 轴标签。所有这些都只需要一行代码。非常令人印象深刻!
Altair 图表表现良好。它提供了一个好看的图形,但它需要更多的代码,它按字母顺序,这并不可怕,而且在很多情况下都会有帮助,但我觉得这应该是用户应该决定的。

编辑和自定义
优胜者:Plotly Express、Seaborn、Matplotlib
失败者:Altair
我相信这四个库都有可能成为赢家。自定义图表在每一个上的表现却是不同的,但我认为,如果你学习足够,你会学会如何创造美丽的可视化。然而,我正在考虑如何容易地编辑和自定义,把自己想象成一个新用户。
Matplotlib 和 Seaborn 非常容易定制,而且它们的文档非常棒。即使你没有在他们的文档中找到要查找的信息,你也很容易在 Stack Overflow 中找到它。他们还有合作的优势。Seaborn 基于 Matplotlib。因此,如果你知道如何编辑一个,你就会知道如何编辑另一个,这是非常方便的。如果你使用
sns.set_style('darkgrid')
设置 Seaborn 主题,它将影响 Matplotlib,这可能就是为什么 Matplotlib 和 Seaborn 是两个更流行的数据可视化库。

plotly express 从一开始就提供了漂亮的图表,例如,与Matplotlib相比,只需要较少的编辑就可以获得非常不错的可视化效果。它的文档很容易理解,他们通过Shift+Tab提供文档,这非常方便。在我尝试的所有库中,它还提供了最多的定制选项。你可以编辑任何东西,包括字体,标签颜色等,最好的部分是它的毫不费力。它的文档中充满了例子。

我发现 Altair 的文件非常混乱。与其他库不同,Altair没有Shift+Tab快捷键。对于初学者来说,这是非常有问题和困惑的。我能够做一些编辑,但找到有关它的信息是有压力的。在编辑方面与我花在 Matplotlib 和 plotly express 上的时间相比,对于初学者来说,Altair 并不是一个很好的选择。
附加功能
获奖者:Plotly Express 和 Altair
失败者:Matplolib 和 Seaborn
对于这一类,我将考虑除了那些我们可以通过代码实现的功能之外的其他功能。Matplotlib 和 Seaborn 在这一类中是非常基本的。除了代码之外,它们不提供任何额外的编辑或交互选项。然而,Plotly Express 在这一类中大放异彩。首先,图表是互动的。您只需将鼠标悬停在图形上,就可以看到有关它的信息。

Altair 提供了一些选项来保存文件或通过Vega编辑器打开JSON文件。

文档和网站
获奖者:Plotly Express、Altair、Seaborn、Matplotlib
所有这些库的文档都很好。Plotly Express 有一个漂亮的网站,带有代码和可视化演示。很容易阅读和找到有关它的信息。我喜欢他们的网站是多么的精致和精心设计,你甚至可以与图表互动。

Altair 的网站上做得很好。他们的定制文档不是最好的,但是网站看起来不错,很容易找到代码示例。我不会说这是惊人的,但它确实起到了作用。

Seaborn 的网站还可以。有人说他们有最好的文件,包含代码示例。如果你正在寻找定制选项,它可能会变得很棘手,但除此之外,它是一个干净的网站,其文档也相当完整。

Matplotlib有一个完整的网站。在我看来,它有太多的文字,找到一些信息可能有点棘手。然而,信息就在那里。他们还提供PDF格式的文档。

总结
我在本文中分析的四个目前都非常棒的库。所有的可视化库都有优缺点,找好合适自己的才是关键。我最喜欢的是 Plotly Express ,因为它在所有类别中都表现出色。不过,Matplotlib 和 Seaborn 更受欢迎,大多数人都会在电脑上安装它们。Altair 是我最不喜欢之间。你最喜欢的数据可视化库是什么呢?
到此这篇关于浅谈哪个Python库才最适合做数据可视化的文章就介绍到这了,更多相关Python 数据可视化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python数据可视化之画图
安装数据可视化模块matplotlib:pip install matplotlib 导入matplotlib模块下的pyplot 1 折线图 from matplotlib import pyplot #横坐标 year=[2010,2012,2014,2016] #纵坐标 perple=[20,40,60,100] #生成折线图:函数polt pyplot.plot(year,perple) #设置横坐标说明 pyplot.xlabel('year') #设置纵坐标说明 pyplot.yla
-
Python数据可视化库seaborn的使用总结
seaborn是python中的一个非常强大的数据可视化库,它集成了matplotlib,下图为seaborn的官网,如果遇到疑惑的地方可以到官网查看.http://seaborn.pydata.org/ 从官网的主页我们就可以看出,seaborn在数据可视化上真的非常强大. 1.首先我们还是需要先引入库,不过这次要用到的python库比较多. import numpy as np import pandas as pd import matplotlib as mpl import matpl
-
利用Python代码实现数据可视化的5种方法详解
前言 数据科学家并不逊色于艺术家.他们用数据可视化的方式绘画,试图展现数据内隐藏的模式或表达对数据的见解.更有趣的是,一旦接触到任何可视化的内容.数据时,人类会有更强烈的知觉.认知和交流. 数据可视化是数据科学家工作中的重要组成部分.在项目的早期阶段,你通常会进行探索性数据分析(Exploratory Data Analysis,EDA)以获取对数据的一些理解.创建可视化方法确实有助于使事情变得更加清晰易懂,特别是对于大型.高维数据集.在项目结束时,以清晰.简洁和引人注目的方式展现最终结果是非常
-
Python数据可视化正态分布简单分析及实现代码
Python说来简单也简单,但是也不简单,尤其是再跟高数结合起来的时候... 正态分布(Normaldistribution),也称"常态分布",又名高斯分布(Gaussiandistribution),最早由A.棣莫弗在求二项分布的渐近公式中得到.C.F.高斯在研究测量误差时从另一个角度导出了它.P.S.拉普拉斯和高斯研究了它的性质.是一个在数学.物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力. 正态曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟形,因此人
-
利用Python进行数据可视化常见的9种方法!超实用!
前言 如同艺术家们用绘画让人们更贴切的感知世界,数据可视化也能让人们更直观的传递数据所要表达的信息. 我们今天就分享一下如何用 Python 简单便捷的完成数据可视化. 其实利用 Python 可视化数据并不是很麻烦,因为 Python 中有两个专用于可视化的库 matplotlib 和 seaborn 能让我们很容易的完成任务. Matplotlib:基于Python的绘图库,提供完全的 2D 支持和部分 3D 图像支持.在跨平台和互动式环境中生成高质量数据时,matplotlib 会很有帮助
-
python代码实现TSNE降维数据可视化教程
TSNE降维 降维就是用2维或3维表示多维数据(彼此具有相关性的多个特征数据)的技术,利用降维算法,可以显式地表现数据.(t-SNE)t分布随机邻域嵌入 是一种用于探索高维数据的非线性降维算法.它将多维数据映射到适合于人类观察的两个或多个维度. python代码 km.py #k_mean算法 import pandas as pd import csv import pandas as pd import numpy as np #参数初始化 inputfile = 'x.xlsx' #销量及
-
python如何爬取网站数据并进行数据可视化
前言 爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示.直方图展示.词云展示等并根据可视化的数据做进一步的分析,其余分析和展示读者可自行发挥和扩展包括各种分析和不同的存储方式等..... 一.爬取和分析相关依赖包 Python版本: Python3.6 requests: 下载网页 math: 向上取整 time: 暂停进程 pandas:数据分析并保存为csv文件 matplotlib:
-
浅谈哪个Python库才最适合做数据可视化
数据可视化是任何探索性数据分析或报告的关键步骤,它可以让我们一眼就能洞察数据集.目前有许多非常好的商业智能工具,比如Tableau.googledatastudio和PowerBI,它们可以让我们轻松地创建图形. 然而,数据分析师或数据科学家还是习惯使用 Python 在 Jupyter notebook 上创建可视化效果.目前最流行的用于数据可视化的 Python 库:Matplotlib.Seaborn.plotlyexpress和Altair.每个可视化库都有自己的特点,没有完美的可视化库
-
浅谈一下python线程池简单应用
一.线程池简介 传统多线程方案会使用“即时创建,即时销毁”的策略.尽管与创建进程相比,创建线程的时间已经大大的缩短,但是如果提交给线程的任务时执行时间较短,而且执行次数及其频繁,那么服务器将处于不停的创建线程,销毁线程的状态. 一个线程的运行时间可以分为三部分:线程的启动时间.线程体的运行时间和线程的销毁时间. 在多线程处理的情景中,如果线程不能被重用,就意味着每次线程运行都要经过启动.销毁和运行3个过程.这必然会增加系统相应的时间,减低了效率. 线程池在系统启动时即创建大量空闲的线程,程序只要
-
浅谈对python中if、elif、else的误解
今天下午在练习python时用了"if...if...else..."的分支结构,结果运行出来吓我一跳.原来我想当然的认为"if...if...else..."是"if...elif...else..."的简化结构(这个错误的看法好像还是从学C语言继承过来的).学了这么多天才发现其中的区别啊.下面先说说python,然后再说一下C语言里面的if语句. "python中通过if.elif.else等保留字提供单分支.二分支和多分支结构.&
-
浅谈一下Python中5种下划线的含义
目录 1.单前导下划线:_var 2.单末尾下划线 var_ 3. 双前导下划线 __var 4.双前导和双末尾下划线 _var_ 5.单下划线 _ 1.单前导下划线:_var 当涉及到变量和方法名称时,单个下划线前缀有一个约定俗成的含义. 它是对程序员的一个提示 - 意味着Python社区一致认为它应该是什么意思,但程序的行为不受影响. 下划线前缀的含义是告知其他程序员:以单个下划线开头的变量或方法仅供内部使用. 该约定在PEP 8中有定义. 这不是Python强制规定的. Python不像J
-
浅谈使用Python变量时要避免的3个错误
Python编程中经常遇到一些莫名其妙的错误, 其实这不是语言本身的问题, 而是我们忽略了语言本身的一些特性导致的,今天就来看下使用Python变量时导致的3个不可思议的错误, 以后在编程中要多多注意. 关于Python编程运行时新手易犯错误,这里暂不作介绍,详情参见:Python运行的17个时新手常见错误小结 1. 可变数据类型作为函数定义中的默认参数 这似乎是对的?你写了一个小函数,比如,搜索当前页面上的链接,并可选将其附加到另一个提供的列表中. def search_for_links(p
-
浅谈使用Rapidxml 库遇到的问题和分析过程(分享)
C++解析xml的开源库有很多,在此我就不一一列举了,今天主要说下Rapidxml,我使用这个库也并不是很多,如有错误之处还望大家能够之处,谢谢. 附: 官方链接:http://rapidxml.sourceforge.net/ 官方手册:http://rapidxml.sourceforge.net/manual.html 之前有一次用到,碰到了个"坑",当时时间紧迫并未及时查找,今天再次用到这个库,对这样的"坑"不能踩第二次,因此我决定探个究竟. 先写两段示例:
-
浅谈使用Python内置函数getattr实现分发模式
本文研究的主要是使用Python内置函数getattr实现分发模式的相关问题,具体介绍如下. getattr 常见的使用模式是作为一个分发者.举个例子,如果你有一个程序可以以不同的格式输出数据,你可以为每种输出格式定义各自的格式输出函数,然后使用唯一的分发函数调用所需的格式输出函数. 例如,让我们假设有一个以 HTML.XML 和普通文本格式打印站点统计的程序.输出格式在命令行中指定,或者保存在配置文件中.statsout 模块定义了三个函数:output_html.output_xml 和 o
-
浅谈将JNI库打包入jar文件
在Java开发时,我们有时候会接触到很多本地库,这样在对项目打包的时候我们不得不面临一个选择:要么将库文件与包好的jar文件放在一起:要么将库文件包入jar. 将一个不大的项目包成一个jar有诸多发布优势,本次将分享一个将JNI包入jar的方法. [实现思路] 将JNI库(dll.so等)包入jar后,我们无法通过路径来访问它们,而库的读取依赖一个java.library.path下对应名称的外部库文件,我们仅仅需要在调用JNI前将其由jar包释放出来,这类似于文件的拷贝过程. [部署位置的选取
-
浅谈anaconda python 版本对应关系
2020.2.20 更新日志: 本文的初衷是因为安装anaconda的时候你并不知道会包含哪个版本的python,因此我制作了下表 如果你使用的主要的python版本能在下表中找到,那安装对应的anaconda当然更好 但是如果你只是临时想用某个版本的python,或在下表中找不到对应的,你大可以直接安装最新的anaconda,然后用conda create来创建虚拟环境即可,不用非得找到对应的anaconda来装. 最佳的策略是你的机器上只保留一个anaconda,其中包含着你最常用的pyth
-
浅谈对Python变量的一些认识理解
一.Python变量 在大多数语言中,为一个值起一个名字时,把这种行为称为"给变量赋值"或"把值存储在变量中".不过,Python与许多其它计算机语言的有所不同,它并不是把值存储在变量中,而像是把名字"贴"在值的上边(专业一点说法是将名字绑定了对象).所以,有些Python程序员会说Python没有变量,只有名字,通过名字找到它代表的值. Python中的变量,与其它开发语言(如C语言)的不同: 在C语言中,变量类似于一个"容器&quo