PyTorch搭建LSTM实现时间序列负荷预测
目录
- I. 前言
- II. 数据处理
- III. LSTM模型
- IV. 训练
- V. 测试
- VI. 源码及数据
I. 前言
在上一篇文章深入理解PyTorch中LSTM的输入和输出(从input输入到Linear输出)中,我详细地解释了如何利用PyTorch来搭建一个LSTM模型,本篇文章的主要目的是搭建一个LSTM模型用于时间序列预测。
系列文章:
PyTorch搭建LSTM实现多变量多步长时序负荷预测
PyTorch搭建LSTM实现多变量时序负荷预测
PyTorch深度学习LSTM从input输入到Linear输出
PyTorch搭建双向LSTM实现时间序列负荷预测
II. 数据处理
数据集为某个地区某段时间内的电力负荷数据,除了负荷以外,还包括温度、湿度等信息。
本篇文章暂时不考虑其它变量,只考虑用历史负荷来预测未来负荷。
本文中,我们根据前24个时刻的负荷下一时刻的负荷。有关多变量预测请参考:PyTorch搭建LSTM实现多变量时间序列预测(负荷预测)。
def load_data(file_name):
global MAX, MIN
df = pd.read_csv('data/new_data/' + file_name, encoding='gbk')
columns = df.columns
df.fillna(df.mean(), inplace=True)
MAX = np.max(df[columns[1]])
MIN = np.min(df[columns[1]])
df[columns[1]] = (df[columns[1]] - MIN) / (MAX - MIN)
return df
class MyDataset(Dataset):
def __init__(self, data):
self.data = data
def __getitem__(self, item):
return self.data[item]
def __len__(self):
return len(self.data)
def nn_seq(file_name, B):
print('处理数据:')
data = load_data(file_name)
load = data[data.columns[1]]
load = load.tolist()
load = torch.FloatTensor(load).view(-1)
data = data.values.tolist()
seq = []
for i in range(len(data) - 24):
train_seq = []
train_label = []
for j in range(i, i + 24):
train_seq.append(load[j])
train_label.append(load[i + 24])
train_seq = torch.FloatTensor(train_seq).view(-1)
train_label = torch.FloatTensor(train_label).view(-1)
seq.append((train_seq, train_label))
# print(seq[:5])
Dtr = seq[0:int(len(seq) * 0.7)]
Dte = seq[int(len(seq) * 0.7):len(seq)]
train_len = int(len(Dtr) / B) * B
test_len = int(len(Dte) / B) * B
Dtr, Dte = Dtr[:train_len], Dte[:test_len]
train = MyDataset(Dtr)
test = MyDataset(Dte)
Dtr = DataLoader(dataset=train, batch_size=B, shuffle=False, num_workers=0)
Dte = DataLoader(dataset=test, batch_size=B, shuffle=False, num_workers=0)
return Dtr, Dte
上面代码用了DataLoader来对原始数据进行处理,最终得到了batch_size=B的数据集Dtr和Dte,Dtr为训练集,Dte为测试集。
III. LSTM模型
这里采用了深入理解PyTorch中LSTM的输入和输出(从input输入到Linear输出)中的模型:
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.output_size = output_size
self.num_directions = 1 # 单向LSTM
self.batch_size = batch_size
self.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True)
self.linear = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input_seq):
h_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size).to(device)
c_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size).to(device)
seq_len = input_seq.shape[1] # (5, 24)
# input(batch_size, seq_len, input_size)
input_seq = input_seq.view(self.batch_size, seq_len, 1) # (5, 24, 1)
# output(batch_size, seq_len, num_directions * hidden_size)
output, _ = self.lstm(input_seq, (h_0, c_0)) # output(5, 24, 64)
output = output.contiguous().view(self.batch_size * seq_len, self.hidden_size) # (5 * 24, 64)
pred = self.linear(output) # pred(150, 1)
pred = pred.view(self.batch_size, seq_len, -1) # (5, 24, 1)
pred = pred[:, -1, :] # (5, 1)
return pred
IV. 训练
def LSTM_train(name, b):
Dtr, Dte = nn_seq(file_name=name, B=b)
input_size, hidden_size, num_layers, output_size = 1, 64, 5, 1
model = LSTM(input_size, hidden_size, num_layers, output_size, batch_size=b).to(device)
loss_function = nn.MSELoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练
epochs = 15
cnt = 0
for i in range(epochs):
cnt = 0
print('当前', i)
for (seq, label) in Dtr:
cnt += 1
seq = seq.to(device)
label = label.to(device)
y_pred = model(seq)
loss = loss_function(y_pred, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if cnt % 100 == 0:
print('epoch', i, ':', cnt - 100, '~', cnt, loss.item())
state = {'model': model.state_dict(), 'optimizer': optimizer.state_dict()}
torch.save(state, LSTM_PATH)
一共训练了15轮:
V. 测试
def test(name, b):
global MAX, MIN
Dtr, Dte = nn_seq(file_name=name, B=b)
pred = []
y = []
print('loading model...')
input_size, hidden_size, num_layers, output_size = 1, 64, 5, 1
model = LSTM(input_size, hidden_size, num_layers, output_size, batch_size=b).to(device)
model.load_state_dict(torch.load(LSTM_PATH)['model'])
model.eval()
print('predicting...')
for (seq, target) in Dte:
target = list(chain.from_iterable(target.data.tolist()))
y.extend(target)
seq = seq.to(device)
seq_len = seq.shape[1]
seq = seq.view(model.batch_size, seq_len, 1) # (5, 24, 1)
with torch.no_grad():
y_pred = model(seq)
y_pred = list(chain.from_iterable(y_pred.data.tolist()))
pred.extend(y_pred)
y, pred = np.array(y), np.array(pred)
y = (MAX - MIN) * y + MIN
pred = (MAX - MIN) * pred + MIN
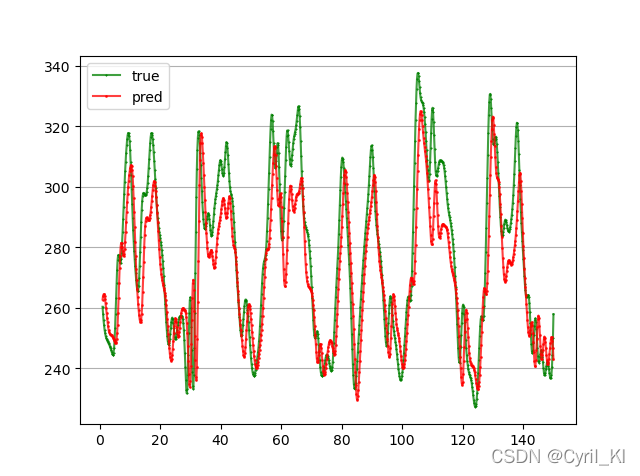
print('accuracy:', get_mape(y, pred))
# plot
x = [i for i in range(1, 151)]
x_smooth = np.linspace(np.min(x), np.max(x), 600)
y_smooth = make_interp_spline(x, y[0:150])(x_smooth)
plt.plot(x_smooth, y_smooth, c='green', marker='*', ms=1, alpha=0.75, label='true')
y_smooth = make_interp_spline(x, pred[0:150])(x_smooth)
plt.plot(x_smooth, y_smooth, c='red', marker='o', ms=1, alpha=0.75, label='pred')
plt.grid(axis='y')
plt.legend()
plt.show()
MAPE为6.07%:

VI. 源码及数据
源码及数据我放在了GitHub上,LSTM-Load-Forecasting
以上就是PyTorch搭建LSTM实现时间序列负荷预测的详细内容,更多关于PyTorch搭建LSTM时间序列负荷预测的资料请关注我们其它相关文章!
相关推荐
-

Pytorch 如何实现LSTM时间序列预测
开发环境说明: Python 35 Pytorch 0.2 CPU/GPU均可 1.LSTM简介 人类在进行学习时,往往不总是零开始,学习物理你会有数学基础.学习英语你会有中文基础等等. 于是对于机器而言,神经网络的学习亦可不再从零开始,于是出现了Transfer Learning,就是把一个领域已训练好的网络用于初始化另一个领域的任务,例如会下棋的神经网络可以用于打德州扑克. 我们这讲的是另一种不从零开始学习的神经网络--循环神经网络(Recurrent Neural Network, RNN
-
基于pytorch的lstm参数使用详解
lstm(*input, **kwargs) 将多层长短时记忆(LSTM)神经网络应用于输入序列. 参数: input_size:输入'x'中预期特性的数量 hidden_size:隐藏状态'h'中的特性数量 num_layers:循环层的数量.例如,设置' ' num_layers=2 ' '意味着将两个LSTM堆叠在一起,形成一个'堆叠的LSTM ',第二个LSTM接收第一个LSTM的输出并计算最终结果.默认值:1 bias:如果' False',则该层不使用偏置权重' b_ih '和' b
-
Python中利用LSTM模型进行时间序列预测分析的实现
时间序列模型 时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征.这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺序的,同样大小的值改变顺序后输入模型产生的结果是不同的. 举个栗子:根据过去两年某股票的每天的股价数据推测之后一周的股价变化:根据过去2年某店铺每周想消费人数预测下周来店消费的人数等等 RNN 和 LSTM 模型 时间序列模型最常用最强大的的工具就是递归神经网络(recurrent neural n
-
pytorch实现用CNN和LSTM对文本进行分类方式
model.py: #!/usr/bin/python # -*- coding: utf-8 -*- import torch from torch import nn import numpy as np from torch.autograd import Variable import torch.nn.functional as F class TextRNN(nn.Module): """文本分类,RNN模型""" def __ini
-
PyTorch搭建LSTM实现时间序列负荷预测
目录 I. 前言 II. 数据处理 III. LSTM模型 IV. 训练 V. 测试 VI. 源码及数据 I. 前言 在上一篇文章深入理解PyTorch中LSTM的输入和输出(从input输入到Linear输出)中,我详细地解释了如何利用PyTorch来搭建一个LSTM模型,本篇文章的主要目的是搭建一个LSTM模型用于时间序列预测. 系列文章: PyTorch搭建LSTM实现多变量多步长时序负荷预测 PyTorch搭建LSTM实现多变量时序负荷预测 PyTorch深度学习LSTM从input输入
-
PyTorch搭建双向LSTM实现时间序列负荷预测
目录 I. 前言 II. 原理 Inputs Outputs batch_first 输出提取 III. 训练和预测 IV. 源码及数据 I. 前言 前面几篇文章中介绍的都是单向LSTM,这篇文章讲一下双向LSTM. 系列文章: PyTorch搭建LSTM实现多变量多步长时序负荷预测 PyTorch搭建LSTM实现多变量时序负荷预测 PyTorch深度学习LSTM从input输入到Linear输出 PyTorch搭建LSTM实现时间序列负荷预测 II. 原理 关于LSTM的输入输出在深入理解Py
-
PyTorch搭建ANN实现时间序列风速预测
目录 数据集 特征构造 数据处理 1.数据预处理 2.数据集构造 ANN模型 1.模型训练 2.模型预测及表现 数据集 数据集为Barcelona某段时间内的气象数据,其中包括温度.湿度以及风速等.本文将简单搭建来对风速进行预测. 特征构造 对于风速的预测,除了考虑历史风速数据外,还应该充分考虑其余气象因素的影响.因此,我们根据前24个时刻的风速+下一时刻的其余气象数据来预测下一时刻的风速. 数据处理 1.数据预处理 数据预处理阶段,主要将某些列上的文本数据转为数值型数据,同时对原始数据进行归一
-
PyTorch搭建LSTM实现多变量多步长时序负荷预测
目录 I. 前言 II. 数据处理 III. LSTM模型 IV. 训练和预测 V. 源码及数据 I. 前言 在前面的两篇文章PyTorch搭建LSTM实现时间序列预测(负荷预测)和PyTorch搭建LSTM实现多变量时间序列预测(负荷预测)中,我们利用LSTM分别实现了单变量单步长时间序列预测和多变量单步长时间序列预测. 本篇文章主要考虑用PyTorch搭建LSTM实现多变量多步长时间序列预测. 系列文章: PyTorch搭建双向LSTM实现时间序列负荷预测 PyTorch搭建LSTM实现多变
-
PyTorch搭建LSTM实现多变量时序负荷预测
目录 I. 前言 II. 数据处理 III. LSTM模型 IV. 训练 V. 测试 VI. 源码及数据 I. 前言 在前面的一篇文章PyTorch搭建LSTM实现时间序列预测(负荷预测)中,我们利用LSTM实现了负荷预测,但我们只是简单利用负荷预测负荷,并没有利用到其他一些环境变量,比如温度.湿度等. 本篇文章主要考虑用PyTorch搭建LSTM实现多变量时间序列预测. 系列文章: PyTorch搭建LSTM实现多变量多步长时序负荷预测 PyTorch深度学习LSTM从input输入到Line
-
PyTorch搭建CNN实现风速预测
目录 数据集 特征构造 一维卷积 数据处理 1.数据预处理 2.数据集构造 CNN模型 1.模型搭建 2.模型训练 3.模型预测及表现 数据集 数据集为Barcelona某段时间内的气象数据,其中包括温度.湿度以及风速等.本文将利用CNN来对风速进行预测. 特征构造 对于风速的预测,除了考虑历史风速数据外,还应该充分考虑其余气象因素的影响.因此,我们根据前24个时刻的风速+下一时刻的其余气象数据来预测下一时刻的风速. 一维卷积 我们比较熟悉的是CNN处理图像数据时的二维卷积,此时的卷积是一种局部
-
深入学习PyTorch中LSTM的输入和输出
目录 LSTM参数 Inputs Outputs 案例 LSTM参数 官方文档给出的解释为: 总共有七个参数,其中只有前三个是必须的.由于大家普遍使用PyTorch的DataLoader来形成批量数据,因此batch_first也比较重要.LSTM的两个常见的应用场景为文本处理和时序预测,因此下面对每个参数我都会从这两个方面来进行具体解释. input_size:在文本处理中,由于一个单词没法参与运算,因此我们得通过Word2Vec来对单词进行嵌入表示,将每一个单词表示成一个向量,此时input
-
PyTorch搭建一维线性回归模型(二)
PyTorch基础入门二:PyTorch搭建一维线性回归模型 1)一维线性回归模型的理论基础 给定数据集,线性回归希望能够优化出一个好的函数,使得能够和尽可能接近. 如何才能学习到参数和呢?很简单,只需要确定如何衡量与之间的差别,我们一般通过损失函数(Loss Funciton)来衡量:.取平方是因为距离有正有负,我们于是将它们变为全是正的.这就是著名的均方误差.我们要做的事情就是希望能够找到和,使得: 均方差误差非常直观,也有着很好的几何意义,对应了常用的欧式距离.现在要求解这个连续函数的最小
-
如何使用Pytorch搭建模型
1 模型定义 和TF很像,Pytorch也通过继承父类来搭建模型,同样也是实现两个方法.在TF中是__init__()和call(),在Pytorch中则是__init__()和forward().功能类似,都分别是初始化模型内部结构和进行推理.其它功能比如计算loss和训练函数,你也可以继承在里面,当然这是可选的.下面搭建一个判别MNIST手写字的Demo,首先给出模型代码: import numpy as np import matplotlib.pyplot as plt import
-
使用Pytorch搭建模型的步骤
本来是只用Tenorflow的,但是因为TF有些Numpy特性并不支持,比如对数组使用列表进行切片,所以只能转战Pytorch了(pytorch是支持的).还好Pytorch比较容易上手,几乎完美复制了Numpy的特性(但还有一些特性不支持),怪不得热度上升得这么快. 1 模型定义 和TF很像,Pytorch也通过继承父类来搭建自定义模型,同样也是实现两个方法.在TF中是__init__()和call(),在Pytorch中则是__init__()和forward().功能类似,都分别是初始化