深入解析HetuEngine实现On Yarn原理
目录
- 什么是On Yarn?
- HetuEngine架构
- HetuEngine On Yarn原理
- 依赖文件
- 租户绑定
- 资源管理
- 客户端使用
摘要:本文介绍HetuEngine实现On Yarn的原理,通过阅读本文,读者可以了解HetuEngine如何在资源使用方面融入Hadoop生态体系。
本文分享自华为云社区《MRS HetuEngine 特性之 On Yarn原理介绍》,作者:一颗柠檬。
HetuEngine是华为自研高性能分布式SQL查询&数据虚拟化引擎。与大数据生态无缝融合,实现海量数据秒级查询;支持多源异构协同,使能数据湖内一站式SQL融合分析。在整合开源能力的同时,MRS HetuEngine相较于开源社区也做了大量的优化,其中一个重要的特性就是On Yarn。
什么是On Yarn?
顾名思义,就是将进程运行在Yarn上,由Yarn进行资源的管理和调度。
不论是TrinoDB/PrestoDB还是openLooKeng,部署方式都是将coordinator和worker进程直接运行在主机上,与主机上的其他应用程序共享资源,无法做到资源隔离,并且难以扩展。
MRS HetuEngine借助Yarn Service提供的能力,将coordinator和worker进程以Yarn application的形式运行在Yarn container中,通过MRS集群的租户划分,可以将HetuEngine计算实例启动在特定租户队列里,从而实现资源隔离。
HetuEngine架构
下图是HetuEngine的拓扑图。HetuEngine向下可以对接各类数据源(比如Hive,GaussDB,HBASE,Elasticsearch等),对外向用户提供CLI/JDBC接口。在同一套MRS集群中,HetuEngine可以在不同租户队列中启动多个HetuEngine计算实例,支持一个租户队列上启动一个计算实例。由HetuEngine的HSBroker实例与Yarn Service交互,将租户队列与计算实例绑定,由HSConsole提供运维管理页面,对HetuEngine的多个计算实例进行运维管理操作,包括启动、停止、删除计算实例,对计算实例进行资源配置,扩缩容等。

HetuEngine On Yarn原理
如前所述,On Yarn就是把进程运行在了Yarn 的container中。HetuEngine 是如何实现将coordinator 和worker运行中Yarn中呢?
Yarn Service提供了一系列API以及一个通用的AM,让用户可以调用API即可将任务提交到Yarn上,由Yarn实现任务的容器化,对容器进行资源和生命周期管理。详细请参考开源社区的介绍。https://hadoop.apache.org/docs/r3.1.0/hadoop-yarn/hadoop-yarn-site/yarn-service/Overview.html
HetuEngine的 On Yarn实现正是借助了Yarn Service所提供的能力。在HetuEngine的HSBroker中,调用Yarn Service的API,拉起application,在container中运行HetuEngine自己的进程,也就是coordinator和worker。其中有以下几个关键点:
Yarn Service API
创建一个Yarn Service服务的接口是/app/v1/services,参数json结构如下。
POST /app/v1/services
{
"name": "hello-world",
"version": "1.0.0",
"description": "hello world example",
"components" :
[
{
"name": "hello",
"number_of_containers": 1,
"artifact": {
"id": "nginx:latest",
"type": "DOCKER"
},
"launch_command": "./start_nginx.sh",
"resource": {
"cpus": 1,
"memory": "256",
"additional" : {
"yarn.io/gpu" : {
"value" : 4,
"unit" : ""
}
}
}
}
]
- name:服务名称,显示在Yarn的resource manager WEB界面servicename;
- version:版本号
- description:服务的描述
- components:一个service中可以包含多个component,以运行不同的任务;
- components.name:component名称
- number_of_containers:此component中container的数量;
- artifact:进程依赖的资源文件,包含id和type信息,type支持docker和tarball
- launch_command:进程启动命令
- resource:此component所需的资源。
HetuEngine的HSBroker根据用户输入构造此json,然后调用Yarn Service API,实现On Yarn。此外Yarn Service还提供stop/delete等API,也由HSBroker调用,实现对HetuEngine计算实例的停止/删除等运维操作。
依赖文件
Yarn Service支持资源文件在HDFS上的形式启动进程,其提供的API可以接收tar包以及docker等形式的资源文件,由Yarn Service自行将HDFS上的文件进行资源本地化。因此,HetuEngine只需将依赖的jar包和资源文件提前部署在HDFS上的指定位置,在调用Yarn Service的API时指定资源文件即可。
租户绑定

HetuEngine支持将计算实例与Yarn的租户队列绑定,每个队列上都可以运行一套coordinator + worker的组合。基于前面Yarn Service能力,只需在构造json时,指定队列信息即可。除了队列,还可以设置container的放置策略(plecement policy),这里不进行详述,可以参考yarn的文档。
资源管理
HetuEngine支持用户自定义coordinator和worker的个数以及CPU内存大小。如下图,在HetuEngine的HSConsole页面,用户可以设置计算实例的CPU,内存,节点个数。内部实现是由HSBroker接收用户输入,将container运行所需的资源大小设置在json的resource段中。
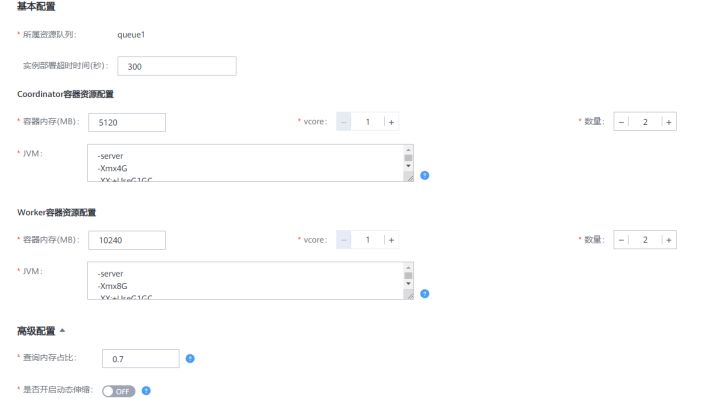
当前HetuEngine支持横向扩展worker的个数,实现资源的弹性伸缩。即使在计算实例处于运行中时,也可以手动调整worker的个数,无需重启计算实例。这得益于Yarn Service的API中提供的flex接口,可以实现向一个运行中的application增加或者减少container的数量。
客户端使用
HetuEngine的计算实例创建完成后,用户可以通过hetu-cli或者JDBC程序进行访问,需要用户绑定对应的租户队列权限,才能向指定的队列提交任务。
Hetu CLI示例:
hetu-cli --catalog hive --tenant tenantName --schema schemaName
租户名:(可选)租户名。指定HetuEngine启动的租户资源队列,不指定为租户的默认队列。使用此参数时,kinit的用户需要具有该租户对应角色的权限。
Hetu JDBC示例:
Properties properties = new Properties();
...…
properties.setProperty("tenant", "default");
properties.setProperty("deploymentMode", "on_yarn");
……
connection = DriverManager.getConnection(url, properties);
……
本文主要介绍了HetuEngine On Yarn的原理,其实现主要是借助了Yarn Service提供的能力,感兴趣的读者可以深入阅读开源社区相关的介绍。
到此这篇关于解析HetuEngine实现On Yarn原理的文章就介绍到这了,更多相关HetuEngine实现On Yarn原理内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

深入解析HetuEngine实现On Yarn原理
目录 什么是On Yarn? HetuEngine架构 HetuEngine On Yarn原理 依赖文件 租户绑定 资源管理 客户端使用 摘要:本文介绍HetuEngine实现On Yarn的原理,通过阅读本文,读者可以了解HetuEngine如何在资源使用方面融入Hadoop生态体系. 本文分享自华为云社区<MRS HetuEngine 特性之 On Yarn原理介绍>,作者:一颗柠檬. HetuEngine是华为自研高性能分布式SQL查询&数据虚拟化引擎.与大数据生态无缝融合,实
-
Tomcat解析XML和反射创建对象原理
下面通过实例代码给大家介绍Tomcat解析XML和反射创建对象原理,具体代码如下所示: import java.lang.reflect.InvocationTargetException; import java.lang.reflect.Method; import java.util.List; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import or
-
通过实例解析JMM和Volatile底层原理
这篇文章主要介绍了通过实例解析JMM和Volatile底层原理,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 JMM和volatile分析 1.JMM:Java Memory Model,java线程内存模型 JMM:它是一个抽象的概念,描述的是线程和内存间的通信,java线程内存模型和CPU缓存模型类似,它是标准化的,用于屏蔽硬件和操作系统对内存访问的差异性. 2.JMM和8大原子操作结合 3.volatile的应用及底层原理探究 volat
-
Web网络安全解析宽字节注入攻击原理
目录 宽字节注入攻击 宽字节注入代码分析 宽字节注入攻击 宽字节注入攻击的测试地址:http://127.0.0.1/sqli/kuanzijie.php?id=1. 访问id=1',页面返回的结果如图46所示,程序并没有报错,反而多了一个转义符(反斜杠). 图46 单引号被转义 从返回的结果可以看出,参数id=1在数据库查询时是被单引号包围的.当传入id=1'时,传入的单引号又被转义符(反斜杠)转义,导致参数ID无法逃逸单引号的包围,所以在一般情况下,此处是不存在SQL注入漏洞的.不过有一个特
-
Web安全解析报错注入攻击原理
目录 1.报错注入攻击 2.报错注入代码分析 1.报错注入攻击 报错注入攻击的测试地址:http://127.0.0.1/sqli/error.php?username=1. 访问该网址时,页面返回ok,如图28所示. 图28 访问username=1时页面的的结果 访问http://127.0.0.1/sqli/error.php?username=1',因为参数username的值是1',在数据库中执行SQL时,会因为多了一个单引号而报错,输出到页面的结果如图29所示. 图29 访问user
-
SQL语句解析执行的过程及原理
目录 一.sqlSession简单介绍 二.获得sqlSession对象源码分析 三.SQL执行流程,以查询为例 一.sqlSession简单介绍 拿到SqlSessionFactory对象后,会调用SqlSessionFactory的openSesison方法,这个方法会创建一个Sql执行器(Executor),这个Sql执行器会代理你配置的拦截器方法. 获得上面的Sql执行器后,会创建一个SqlSession(默认使用DefaultSqlSession),这个SqlSession中也包含了C
-
一文解析MySQL的MVCC实现原理
目录 1. 什么是MVCC 2. 事务的隔离级别 3. Undo Log(回滚日志) 4. MVCC的实现原理 4.1 当前读和快照读 4.2 隐藏字段 4.3 版本链 4.4 Read View(读视图) 5. 不同隔离级别下可见性分析 5.1 READ COMMITTED(读已提交) 5.2 REPEATABLE READ(可重复读) 1. 什么是MVCC MVCC全称是Multi-Version Concurrency Control(多版本并发控制),是一种并发控制的方法,通过维护一个数
-
解析JavaScript实现DDoS攻击原理与保护措施
DDos介绍 最普遍的攻击是对网站进行分布式拒绝服务(DDoS)攻击.在一个典型的DDoS攻击中,攻击者通过发送大量的数据到服务器,占用服务资源.从而达到阻止其他用户的访问. 如果黑客使用JavaScript的DDoS攻击,那么任何一台计算机都可能成为肉鸡,使潜在的攻击量几乎是无限的. Javascript实现DDos攻击原理分析 现在网站的交互性都是通过JavaScript来实现的.通过添加JavaScript直接插入HTML元素,或通过远程来加载JavaScript.浏览器会读取script
-
全面解析PHP验证码的实现原理 附php验证码小案例
拓展 我们需要开启gd拓展,可以使用下面的代码来查看是否开启gd拓展. <?php echo "Hello World!!!!"; echo phpinfo(); ?> 然后在浏览器上Ctrl+F查找gd选项即可验证自己有没有装这个拓展,如果没有的话,还需要自己全装一下这个拓展. 背景图 imagecreatetruecolor 默认生成黑色背景 <?php // 使用gd的imagecreatetruecolor();创建一张背景图 $image = imagecr
-
用WinRAR解析木马病毒的捆绑原理
今天朋友突然想我求救,说网络游戏传奇世界的号被盗了,由于朋友是在家上网,排除了在公共场所帐号和密码被别他人瞟视的可能.据朋友所说,在被盗的前一个多小时,在网上下载了一个网友的照片,并打开浏览了,但是出现的确实是网友的照片,并且是用"Windows 图片和传真查看器"(朋友家是XP系统)打开的,这也可以肯定一定是图片文件.朋友还告诉笔者后缀名是.gif,很显然是图片文件,朋友的电脑也没有安装杀毒软件,并且最重要的是那个文件还没有删.今天朋友突然想我求救,说网络游戏传奇世界的号被盗了,由于