python实现文法左递归的消除方法
前言
- 继词法分析后,又来到语法分析范畴。完成语法分析需要解决几个子问题,今天就完成文法左递归的消除。
- 没借鉴任何博客,完全自己造轮子。
开始之前
- 文法左递归消除程序的核心是对字符串的处理,输入的产生式作为字符串,对它的拆分、替换与合并操作贯穿始终,处理过程的逻辑和思路稍有错漏便会漏洞百出。
- 采用直接改写法,不理解左递归消除方法很难读懂代码。
要求
- CFG文法判断
- 左递归的类型
- 消除直接左递归和间接左递归
- 界面
源码
import os
import tkinter as tk
import tkinter.messagebox
import tkinter.font as tf
zhuizhong = ""
wenfa = {"非左递归文法"}
xi_ = ""
huo = ""
window = tk.Tk()
window.title('消除左递归')
window.minsize(500,500)
#转换坐标显示形式为元组
def getIndex(text, pos):
return tuple(map(int, str.split(text.index(pos), ".")))
def zhijie(x,y):
if not len(y):
pass
else:
if x == y[0]:
wenfa.discard("非左递归文法")
#处理直接左递归
zuobian = y.split('|')
feizhongjie = []
zhongjie = []
for item in zuobian:
if x in item:
item = item[1:]
textt = str(item) + str(x) + "'"
feizhongjie.append(textt)
else:
text = str(item) + str(x) + "'"
zhongjie.append(text)
if not zhongjie:#处理A -> Ax的情况
zhongjie.append(str(x + "'"))
cheng = str(x) + " -> " + "|".join(zhongjie)
zi = str(x) + "'" + " -> " + "|".join(feizhongjie) + "|є"
text_output.insert('insert','直接左递归文法','tag1')
text_output.insert('insert','\n')
text_output.insert('insert',cheng,'tag2')
text_output.insert('insert','\n')
text_output.insert('insert',zi,'tag2')
'''
加上会判断输出非递归产生式,但会导致间接左递归不能删除多余产生式
else:
h ="不变: " + x + " -> " + y
text_output.insert('insert','非左递归文法','tag1')
text_output.insert('insert','\n')
text_output.insert('insert',h,'tag2')
'''
text_output.insert('insert','\n')
def zhijie2(x,y):
if not len(y):
pass
else:
if x == y[0]:
wenfa.discard("非左递归文法")
#处理直接左递归
zuobian = y.split('|')
feizhongjie = []
zhongjie = []
for item in zuobian:
if x in item:
item = item[1:]
textt = str(item) + str(x) + "'"
feizhongjie.append(textt)
else:
text = str(item) + str(x) + "'"
zhongjie.append(text)
cheng = str(x) + " -> " + "|".join(zhongjie)
zi = str(x) + "'" + " -> " + "|".join(feizhongjie) + "|є"
text_output.insert('insert',"间接左递归文法",'tag1')
text_output.insert('insert','\n')
text_output.insert('insert',cheng,'tag2')
text_output.insert('insert','\n')
text_output.insert('insert',zi,'tag2')
text_output.insert('insert','\n')
def tihuan(xk,yi,yk):
yi_you = []
yi_wu =[]
yi_he = ""
yi_wuhe = ""
yi_zhong = ""
yi_feizhong = []
if xk in yi:
yk_replace = yk.split('|')
yi_fenjie = yi.split('|')#将含非终结与不含分开
for ba in yi_fenjie:
if xk in ba:
yi_you.append(ba)
else:
yi_wu.append(ba)
yi_he = "|".join(yi_you)
for item in yk_replace:
yi_zhong = yi_he.replace(xk,item)#替换
yi_feizhong.append(yi_zhong)
yi_wuhe = "|".join(yi_wu)#再合并
global zhuizhong
zhuizhong = "|".join(yi_feizhong) + "|" + yi_wuhe
#点击按钮后执行的函数
def changeString():
text_output.delete('1.0','end')
text = text_input.get('1.0','end')
text_list = list(text.split('\n'))#一行一行的拿文法
text_list.pop()
if not text_list[0]:
print(tkinter.messagebox.showerror(title = '出错了!',message='输入不能为空'))
else:
for cfg in text_list:
x,y = cfg.split('->')#将文法左右分开
x = ''.join(x.split())#消除空格
y = ''.join(y.split())
if not (len(x) == 1 and x >= 'A' and x <= 'Z'):
pos = text_input.search(x, '1.0', stopindex="end")
result = tkinter.messagebox.showerror(title = '出错了!',
message='非上下文无关文法!坐标%s'%(getIndex(text_input, pos),))
# 返回值为:ok
print(result)
return 0
else:
zhijie(x,y)
for i in range(len(text_list)):
for k in range(i):
xi,yi = text_list[i].split('->')
xi = ''.join(xi.split())#消除空格
yi = ''.join(yi.split())
xk,yk = text_list[k].split('->')
xk = ''.join(xk.split())#消除空格
yk = ''.join(yk.split())
tihuan(xk,yi,yk)
tihuan(xk,zhuizhong,yk)
global xi_
xi_ = xi
zhijie2(xi_,zhuizhong)
for item in wenfa:
text_output.insert('insert',item,'tag1')
#创建文本输入框和按钮
text_input = tk.Text(window, width=80, height=16)
text_output = tk.Text(window, width=80, height=20)
#简单样式
ft = tf.Font(family='微软雅黑',size=12)
text_output.tag_config("tag1",background="yellow",foreground="red",font=ft)
text_output.tag_config('tag2',font = ft)
#按钮
button = tk.Button(window,text="消除左递归",command=changeString,padx=32,pady=4,bd=4)
text_input.pack()
text_output.pack()
button.pack()
window.mainloop()
是不是很难懂,看看半吊子流程图主要流程
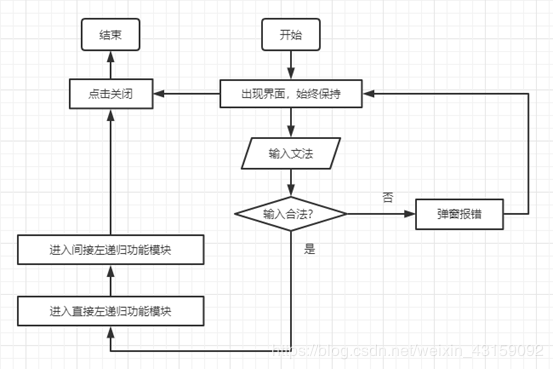
直接左递归

间接左递归合并

运行截图

总结
(1)确定方向
做一件事并不难,最难的是没有方向,不知道要做什么;只是感觉时光流逝自己却一点东西都没产出。幸好有具体的题目可供选择,这一次我稍有纠结之后,果断选择文法左递归消除,说实话,我认为这个最简单。
(2)开始实现
首先将消除左递归的方法理解透彻,找到了程序的本质就是对字符串的操作。
完成直接左递归算法非常顺利,我思路严谨步步为营,几乎没有bug,后续测试仅仅加上一些边缘情况的判断,比如空值,让程序面对复杂产生式也游刃有余。
将间接左递归的产生式合并的算法也很顺利,因为我在草稿纸上已经勾勒好了每一步需要得到什么,写代码时,一步一个输出,看是否符合预期,后续测试稍微小补增强健壮性。真正难点在于构思思路,就连最外层两个迭代都考虑了很久。
这两个算法的逻辑和思路是很复杂的,字符串的分分合合,分别存储,使用列表和字符串数据类型不下十个,再加上几个全局变量,我对自己清晰的思路略感自豪。
(3)不足之处
1、我希望能够实现,非左递归文法,左递归和间接左递归的一起输入一起识别一起消除,碰到非左递归文法就输出“非左递归文法”,然后将其不做任何修改输出。如果实现这个,如何让间接左递归不被当做非左递归文法处理呢?我没想到解决方案。
2、我对非终结符的判断采用的是是否包含,没有更进一步判断位置,比如消除 D -> Dh|sD|h,D在s后,这就不能很好的处理。
3、对于间接左递归文法产生式的输入顺序是有要求的,还没能做到随意输入。
(4)遇到的问题
我遇到的问题都是关于整体结构和取舍妥协,比如我最终选择将输入使用两个循环,一个是对一个个产生式进行迭代,消除直接左递归,第二个再从头采用下标嵌套两层循环来合并间接左递归。
在解决不足之处1时,我花了不少时间,用尽了方法,比如全局变量,集合,甚至还将代码备份,进行较大改动,最后还是妥协了。
在写两个核心算法的时候,我每一步拿到什么数据类型,拿到什么内容,都很小心的确认,一步一步推进,没出现“bug找一天”的情况。每到一步需要一个新的变量存储,我就在方法最开始加一个,tihuan()这个方法就有六个变量,现在想来,空间复杂度挺高。
(5)总结
这次的设计完全自主,没有借鉴任何博客,我也知道可能有些我认为很难的东西在大牛面前都不值一提,或许程序整体架构就差之甚远。无论如何,题目要求的东西我做到了,而且花的时间不算长,还是挺有成就感。但是,我绝对不会骄傲,根本没有骄傲的资本。
从画出界面,接收文本输入,取到产生式,判断类型,消除直接左递归,合并间接左递归再到消除间接左递归。有条有理,一步一个脚印,方能万丈高楼平地起。
到此这篇关于python实现文法左递归的消除方法的文章就介绍到这了,更多相关python文法左递归消除内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python递归函数绘制分形树的方法
分形几何学的基本思想:客观事物具有自相似性的层次结构,局部和整体在形态,功能,信息,时间,空间等方面具有统计意义上的相似性,称为自相似性,自相似性是指局部是整体成比例缩小的性质. 我们先看一下我们最终要绘制的图形: 案例分析: 代码: ## 绘制分型树,末梢的树枝的颜色不同 import turtle def draw_brach(brach_length): if brach_length > 5: if brach_length < 40: turtle.color('green') el
-
详解python中递归函数
函数执行流程 def foo1(b,b1=3): print("foo1 called",b,b1) def foo2(c): foo3(c) print("foo2 called",c) def foo3(d): print("foo3 called",d) def main(): print("main called") foo1(100,101) foo2(200) print("main ending &qu
-
Python递归函数实例讲解
Python递归函数实例 1.打开Python开发工具IDLE,新建'递归.py'文件,并写代码如下: def digui(n): if n == 0 : print ('') return print ('*'*n) digui(n-1) if __name__ == '__main__': digui(5) 这里递归打印*号,先打印后递归 2.F5运行程序,打印内容如下: ***** **** *** ** * 3.更改一下打印和递归的 顺序,先递归后打印,代码如下: def digui(n
-
python递归全排列实现方法
本文实例为大家分享了python递归全排列的实现方法,供大家参考,具体内容如下 排列:从n个元素中任取m个元素,并按照一定的顺序进行排列,称为排列: 全排列:当n==m时,称为全排列: 比如:集合{ 1,2,3}的全排列为: { 1 2 3} { 1 3 2 } { 2 1 3 } { 2 3 1 } { 3 2 1 } { 3 1 2 } 递归思想: 取出数组中第一个元素放到最后,即a[1]与a[n]交换,然后递归求a[n-1]的全排列 1)如果数组只有一个元素n=1,a={1} 则全排列就是
-
Python理解递归的方法总结
递归 一个函数在执行过程中一次或多次调用其本身便是递归,就像是俄罗斯套娃一样,一个娃娃里包含另一个娃娃. 递归其实是程序设计语言学习过程中很快就会接触到的东西,但有关递归的理解可能还会有一些遗漏,下面对此方面进行更加深入的理解 递归的分类 这里根据递归调用的数量分为线性递归.二路递归与多重递归 线性递归 如果一个递归调用最多开始一个其他递归调用,我们称之为线性递归. 例如: def binary_search(data, target, low, high): """ 二分查
-
python实现文法左递归的消除方法
前言 继词法分析后,又来到语法分析范畴.完成语法分析需要解决几个子问题,今天就完成文法左递归的消除. 没借鉴任何博客,完全自己造轮子. 开始之前 文法左递归消除程序的核心是对字符串的处理,输入的产生式作为字符串,对它的拆分.替换与合并操作贯穿始终,处理过程的逻辑和思路稍有错漏便会漏洞百出. 采用直接改写法,不理解左递归消除方法很难读懂代码. 要求 CFG文法判断 左递归的类型 消除直接左递归和间接左递归 界面 源码 import os import tkinter as tk import tk
-
Python技法之简单递归下降Parser的实现方法
目录 1. 算术运算表达式求值 2. 生成表达式树 左递归和运算符优先级陷阱 3. 相关包 参考 总结 1. 算术运算表达式求值 在上一篇博文<Python技法:用re模块实现简易tokenizer>中,我们介绍了用正则表达式来匹配对应的模式,以实现简单的分词器.然而,正则表达式不是万能的,它本质上是一种有限状态机(finite state machine,FSM), 无法处理含有递归语法的文本,比如算术运算表达式. 要解析这类文本,需要另外一种特定的语法规则.我们这里介绍可以表示上下文无关文
-
python非递归全排列实现方法
刚刚开始学习python,当前看到了函数这一节.结合数组操作,写了个非递归的全排列生成.原理是插入法,也就是在一个有n个元素的已有排列中,后加入的元素,依次在前,中,后的每一个位置插入,生成n+1个新的全排列.因为Python切割数组或者字符串,以及合并比较方便,所以,程序会节省很多代码. def getArrayInsertCharToStr(STR,CHAR): arr =[] s_len = len(STR) index =0 while index <= s_len: #分割字符串 ar
-
Python用csv写入文件_消除空余行的方法
只做简单地记录,方便一下使用!python关于csv模块的介绍网上有很多资料,这里就不在赘诉.直接给出代码和解释. 数据: Symbol,Price,Date,Time,Change,Volume "AA",39.48,"6/11/2007","9:36am",-0.18,181800 "AIG",71.38,"6/11/2007","9:36am",-0.15,195500 "
-
Python数据类型之列表和元组的方法实例详解
引言 我们前面的文章介绍了数字和字符串,比如我计算今天一天的开销花了多少钱我可以用数字来表示,如果是整形用 int ,如果是小数用 float ,如果你想记录某件东西花了多少钱,应该使用 str 字符串型,如果你想记录表示所有开销的物品名称,你应该用什么表示呢? 可能有人会想到我可以用一个较长的字符串表示,把所有开销物品名称写进去,但是问题来了,如果你发现你记录错误了,想删除掉某件物品的名称,那你是不是要在这个长字符串中去查找到,然后删除,这样虽然可行,那是不是比较麻烦呢. 这种情况下,你是不是
-
Python 列表反转显示的四种方法
第一种,使用reversed 函数,reversed返回的结果是一个反转的迭代器,我们需要对其进行 list 转换 listNode = [1,2,3,4,5] newList = list(reversed(listNode)) print(newList) #结果 [5,4,3,2,1] 第二种,使用sorted函数,sorted是排序函数,它是对一个列表进行排序后生成一个新的list列表,而sort则是在原来的列表上直接进行排序. listNode = [1,2,3,4,5] newLis
-
Python读取和存储yaml文件的方法
YAML 是 "YAML Ain't a Markup Language"(YAML 不是一种标记语言)的递归缩写.在开发的这种语言时,YAML 的意思其实是:"Yet Another Markup Language"(仍是一种标记语言). YAML 的语法和其他高级语言类似,并且可以简单表达清单.散列表,标量等数据形态.它使用空白符号缩进和大量依赖外观的特色,特别适合用来表达或编辑数据结构.各种配置文件.倾印调试内容.文件大纲(例如:许多电子邮件标题格式和YAML
-
Python字符串拼接、截取及替换方法总结分析
本文实例讲述了Python字符串拼接.截取及替换方法.分享给大家供大家参考,具体如下: python字符串连接 python字符串连接有几种方法,我开始用的第一个方法效率是最低的,后来看了书以后就用了后面的2种效率高的方法,跟大家分享一下. 先介绍下效率比较低的方法: a = ['a','b','c','d'] content = '' for i in a: content = content + i print content content的结果是:'abcd' 后来我看了书以后,发现书上
-
使用70行Python代码实现一个递归下降解析器的教程
第一步:标记化 处理表达式的第一步就是将其转化为包含一个个独立符号的列表.这一步很简单,且不是本文的重点,因此在此处我省略了很多. 首先,我定义了一些标记(数字不在此中,它们是默认的标记)和一个标记类型: token_map = {'+':'ADD', '-':'ADD', '*':'MUL', '/':'MUL', '(':'LPAR', ')':'RPAR'} Token = namedtuple('Token', ['name', 'value']) 下面就是我用来标记 `expr` 表
-
python实现删除文件与目录的方法
本文实例讲述了python实现删除文件与目录的方法.分享给大家供大家参考.具体实现方法如下: os.remove(path) 删除文件 path. 如果path是一个目录, 抛出 OSError错误.如果要删除目录,请使用rmdir(). remove() 同 unlink() 的功能是一样的 在Windows系统中,删除一个正在使用的文件,将抛出异常.在Unix中,目录表中的记录被删除,但文件的存储还在. os.removedirs(path) 递归地删除目录.类似于rmdir(), 如果子目