浅谈redis五大数据结构和使用场景
老规矩,先抛结论后验证
string:有点像java的hashMap,存的时候什么key,取的时候也什么key,常用于做缓存,保存用户信息、查询列表等;
hash:这个有点像hashMap的value又套了个hashMap,下文有举例,一看就明白了;
list:有序列表,类似Java的linkedList,可以在左边右边插入数据;
set:去重集合,类似Java的hashset,可用于求交集,比如共同好友;
zset:带权重的set集合,可用于做排行榜;
为了方便理解,我们基于这个dog类来做测试,有手就能学会的那种
//Dog类,属性不重要,随便写的
public class Dog {
private String name;
private String like;
}
================分割线================
//new三只小狗
Dog dog1 = new Dog("蔡徐鸡", "唱跳");
Dog dog2 = new Dog("蔡徐公鸡", "rap");
Dog dog3 = new Dog("蔡徐老母鸡", "篮球");
================分割线================
//我们用jedis来操作redis
Jedis jedis = new Jedis();
1、String:
说明:有点像java的hashMap,存的时候什么key,取的时候也什么key,常用于做缓存,保存用户信息、查询列表等;
操作:set方法,第一个参数是key,第二个参数是value;

key可以随便设置,方便后面对比,我们这里设置key为“string”,value就是dog
//set
jedis.set("string",dog1.toString());
//get
jedis.get("string");
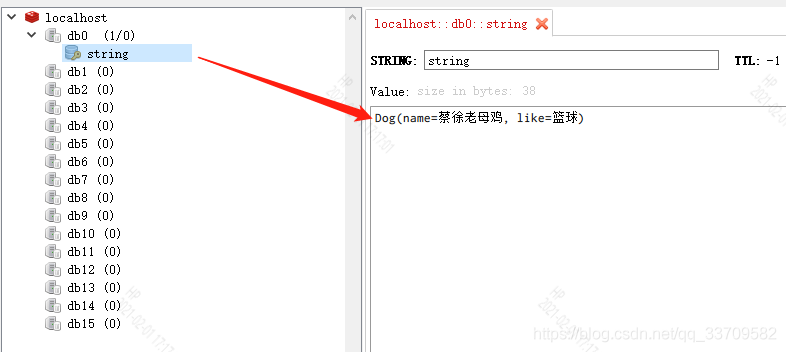
看下它在redis中长什么样 (左边很多db,这个不用管,看db0就行)

如果有多个相同的key,前面的会被覆盖掉
jedis.set("string",dog1.toString());
jedis.set("string",dog2.toString());
jedis.set("string",dog3.toString());
2、hash
说明:hashMap的value又套了个hashMap;
操作:hset方法,第一个参数是key,第二个参数是field,第三个参数是value

我还没想到怎么比较好的解释这个field,说多了怕误导你们,反正这个就像你new了个hashMap,然后这个hashMap的value又是个hashMap,然后你真正的数据是存在第二个hashMap里面的
//类似redis的key
HashMap<Object, Object> key = new HashMap<>();
key.put("key",dog1);
//类似redis的field,这才是redis的hash类型真正存放数据的
HashMap<Object, Object> field = new HashMap<>();
key.put("field",field);
还没懂的话就往下面看,别纠结上面那个举例,我也不知道那样说合理不合理
jedis.hset("hash", "field1", dog1.toString());
jedis.hset("hash", "field2", dog2.toString());
jedis.hset("hash", "field3", dog3.toString());
看下在redis中长什么样

再看下hash类型在jedis中的方法应该就懂了

hget会让你输入两个参数,第一个是key,第二个是field,这个方法直接返回的是dog对象;
而hgetAll只需要输入一个参数,然后返回一个map给你,这个map里面装的全是狗,懂了吧,如果你要获取具体的dog对象,你还的输入一个key,这个key就是那个field;
Map<String, String> dogMap= jedis.hgetAll("hash");
System.out.println(dogMap);
//下面是打印出来的map
{field1=Dog(name=蔡徐鸡, like=唱跳),
field3=Dog(name=蔡徐老母鸡, like=篮球),
field2=Dog(name=蔡徐公鸡, like=rap)}
-----------------------------分割线-------------------------------------
String dog= jedis.hget("hash", "field1");
System.out.println(dog);
//下面是打印出来的dog
Dog(name=蔡徐鸡, like=唱跳)
list
说明:有序列表,类似Java的linkedList,可以在左边右边插入数据;
操作:左插入lpush、右插入rpush
我们先插入一条蔡徐鸡
jedis.lpush("list",dog1.toString());

然后在蔡徐鸡的左右两边各插一条数据,
jedis.rpush("list",dog2.toString());//蔡徐公鸡
jedis.lpush("list",dog3.toString());//蔡徐老母鸡
仔细看下面的顺序

set
说明:去重集合,类似Java的set,可用于求交集,比如共同好友;
操作:放入元素sadd,求set的交集sinterstore,sinterstore方法可以有多个参数,因为这个方法会在redis生成一个set,用来存放交集,所以第一个参数是新生成set的名字,后面的参数全都是指定哪些set加入求交集方法
我们先设置两个set,第一个set存放dog1和dog2,第二个set存放dog2和dog3
jedis.sadd("set1",dog1.toString(),dog2.toString());
jedis.sadd("set2",dog2.toString(),dog3.toString());


我们再往set1里面放个dog1试试
jedis.sadd("set1",dog1.toString());
再看看redis的set1里面有几个dog1,既然是set,肯定不允许放入重复数据,所以应该跟上面一样

我们再来看看如何获取set的交集
目前set1里面有蔡徐鸡和蔡徐公鸡,set2里面有蔡徐公鸡和蔡徐老母鸡,那交集就是蔡徐公鸡,来看看是不是
//这个方法会在redis生成一个set,用来存放交集
//第一个参数是指定新生成set的名字,后面的参数全都是指定哪些set加入求交集方法
jedis.sinterstore("set","set1","set2");
来看下reids中有没有生成一个叫set的key

可以看到redis生成了一个名叫set的key,并且它的值是set1和set2的交集,大名鼎鼎的蔡徐公鸡~~
zset
说明:带权重的set集合,可用于做排行榜;
操作:添加元素zadd,需要指定元素的权重
jedis.zadd("zset", 100, dog1.toString());//权重为100的dog1
jedis.zadd("zset", 200, dog2.toString());//权重为200的dog2
jedis.zadd("zset", 300, dog3.toString());//权重为300的dog3
看看redis中的zset是否按照权重排列

of course!!
说明:以上操作redis的方法仅作为理解redis数据类型举例,实际上每个数据类型都还有很多很多其它方法,具体的本文不展开叙述,其次,我们生产中使用redis时,一定要记得给key设置过期时间,除开一些需要对key做持久化的场景,因为redis是运行在内存中的,如果所有key都持久存在于内存,你服务器顶不住的鸭!!!
到此这篇关于浅谈redis五大数据结构和使用场景的文章就介绍到这了,更多相关redis 数据结构和使用场景内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

redis内部数据结构之SDS简单动态字符串详解
前言 reids 没有直接使用C语言传统的字符串表示(以空字符结尾的字符数组)而是构建了一种名为简单动态字符串的抽象类型,并为redis的默认字符串表示,因为C字符串不能满足redis对字符串的安全性.效率以及功能方面的需求 1.SDS 定义 在C语言中,字符串是以'\0'字符结尾(NULL结束符)的字符数组来存储的,通常表达为字符指针的形式(char *).它不允许字节0出现在字符串中间,因此,它不能用来存储任意的二进制数据. sds的类型定义 typedef char *sds; 每个sds
-
详解Redis数据结构之跳跃表
1.简介 我们先不谈Redis,来看一下跳表. 1.1.业务场景 场景来自小灰的算法之旅,我们需要做一个拍卖行系统,用来查阅和出售游戏中的道具,类似于魔兽世界中的拍卖行那样,还有以下需求: 拍卖行拍卖的商品需要支持四种排序方式,分别是:按价格.按等级.按剩余时间.按出售者ID排序,排序查询要尽可能地快.还要支持输入道具名称的精确查询和不输入名称的全量查询. 这样的业务场景所需要的数据结构该如何设计呢?拍卖行商品列表是线性的,最容易表达线性结构的是数组和链表.假如用有序数组,虽然查找的时候可以使用
-
通俗易懂的Redis数据结构基础教程(入门)
Redis有5个基本数据结构,string.list.hash.set和zset.它们是日常开发中使用频率非常高应用最为广泛的数据结构,把这5个数据结构都吃透了,你就掌握了Redis应用知识的一半了. string 首先我们从string谈起.string表示的是一个可变的字节数组,我们初始化字符串的内容.可以拿到字符串的长度,可以获取string的子串,可以覆盖string的子串内容,可以追加子串. Redis的字符串是动态字符串,是可以修改的字符串,内部结构实现上类似于Java的ArrayL
-
详解redis数据结构之sds
详解redis数据结构之sds 字符串在redis中使用非常广泛,在redis中,所有的数据都保存在字典(Map)中,而字典的键就是字符串类型,并且对于很大一部分字典值数据也是又字符串组成的.以下是sds的具体存储结构: 从图中可以看出,sds的属性有三个:len.free和buf数组.这里len字段是用来保存sds字符串中所包含字符数目的,free字段则是用来保存buf数组中空余的部分的长度的,而buf数组则是实际用来保存字符串的.比如如下结构保存了"Hello World!"这个字
-
redis数据结构之intset的实例详解
redis数据结构之intset的实例详解 在redis中,intset主要用于保存整数值,由于其底层是使用数组来保存数据的,因而当对集合进行数据添加时需要对集合进行扩容和迁移操作,因而也只有在数据量不大时redis才使用该数据结构来保存整数集合.其具体的底层数据结构如下: typedef struct intset { // 编码方式 uint32_t encoding; // 集合包含的元素数量 uint32_t length; // 保存元素的数组 int8_t contents[]; }
-
redis中的数据结构和编码详解
redis中的数据结构和编码: 背景: 1>redis在内部使用redisObject结构体来定义存储的值对象. 2>每种类型都有至少两种内部编码,Redis会根据当前值的类型和长度来决定使用哪种编码实现. 3>编码类型转换在Redis写入数据时自动完成,这个转换过程是不可逆的,转换规则只能从小内存编码向大内存编码转换. 源码: 值对象redisObject: typedef struct redisObject { unsigned ty
-
Redis中5种数据结构的使用场景介绍
一.redis 数据结构使用场景 原来看过 redisbook 这本书,对 redis 的基本功能都已经熟悉了,从上周开始看 redis 的源码.目前目标是吃透 redis 的数据结构.我们都知道,在 redis 中一共有5种数据结构,那每种数据结构的使用场景都是什么呢? String--字符串 Hash--字典 List--列表 Set--集合 Sorted Set--有序集合 下面我们就来简单说明一下它们各自的使用场景: 1. String--字符串 String 数据结构是简单的 key-
-
详解redis数据结构之压缩列表
详解redis数据结构之压缩列表 redis使用压缩列表作为列表键和哈希键的底层实现之一.当一个列表键只包含少量的列表项,并且每个列表项都是由小整数值或者是短字符串组成,那么redis就会使用压缩列表存储列表项:同理,当一个哈希表包含的键值对都是由小整数值或者是短字符串组成,并且存储的键值对数目不多时,redis也会使用压缩列表来存储哈希表.以下是压缩列表存储结构: zlbytes长度为4个字节,记录了整个压缩列表所占用的字节数 zltail长度为4个字节,记录了压缩列表起始位置到压缩列表尾节
-
浅谈redis五大数据结构和使用场景
老规矩,先抛结论后验证 string:有点像java的hashMap,存的时候什么key,取的时候也什么key,常用于做缓存,保存用户信息.查询列表等: hash:这个有点像hashMap的value又套了个hashMap,下文有举例,一看就明白了: list:有序列表,类似Java的linkedList,可以在左边右边插入数据: set:去重集合,类似Java的hashset,可用于求交集,比如共同好友: zset:带权重的set集合,可用于做排行榜: 为了方便理解,我们基于这个dog类来做测
-
浅谈Redis在直播场景的实践方案
背景信息 视频直播间作为直播系统对外的表现形式,是整个系统的核心之一.除了视频直播窗口外,直播间的在线用户.礼物.评论.点赞.排行榜等数据信息时效性高,互动性强,对系统时延有着非常高的要求,非常适合使用Redis缓存服务来处理. 本篇最佳实践将向您展示使用Redis版搭建视频直播间信息系统的示例.您将了解三类信息的构建方法: 实时排行类信息 计数类信息 时间线信息 实时排行类信息 实时排行类信息包含直播间在线用户列表.各种礼物的排行榜.弹幕消息(类似于按消息维度排序的消息排行榜)等,适合使用Re
-
浅谈Redis存储数据类型及存取值方法
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合) String存取值: 是 redis 最基本的类型 一个 key 对应一个 value.value其实不仅是String,也可以是数字.string 类型是二进制安全的.意思是 redis 的 string 可以包含任何数据.比如jpg图片或者序列化的对象.string 类型是 Redis 最基本的数据类型,string 类型的值最大能存储 512M
-
浅谈redis缓存在项目中的使用
背景 Redis 是一个开源的内存数据结构存储系统. 可以作为数据库.缓存和消息中间件使用. 支持多种类型的数据结构. Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence). 通过 Redis 哨兵(Sentinel)和 Redis 集群(Cluster)的自动分区,提供高可用性(high availability). 基本数
-
浅谈Redis 缓存的三大问题及其解决方案
目录 一.缓存穿透 1. 常见解决方案 2. 布隆过滤器 3. 缓存空数据与布隆过滤器的比较 二.缓存击穿 解决方案 三.缓存雪崩 解决方案 Redis 经常用于系统中的缓存,这样可以解决目前 IO 设备无法满足互联网应用海量的读写请求的问题. 一.缓存穿透 缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起 id 为-1 的数据或者特别大的不存在的数据.有可能是黑客利用漏洞攻击从而去压垮应用的数据库. 1. 常见解决方案 对于缓存穿透问题,常见的解决方案有以下三种: 验证拦截:
-
浅谈redis整数集为什么不能降级
目录 前言 基本结构 何时使用intset intset 添加元素 类型变动 升级 加入65535 旧数据移位 降级 为什么不实现降级 小结 前言 整数集合相信有的同学没有听说过,因为redis对外提供的只有封装的五大对象!而我们本系列主旨是学习redis内部结构.内部结构是redis五大结构重要支撑! 前面我们分别从redis内部结构分析了redis的List.Hash.Zset三种数据结构了.今天我们再来分析set数据结构内部是如何存储的 基本结构 在src/t_set.c中我们发现这样一段
-
浅谈redis的maxmemory设置以及淘汰策略
redis的maxmemory参数用于控制redis可使用的最大内存容量.如果超过maxmemory的值,就会动用淘汰策略来处理expaire字典中的键. 关于redis的淘汰策略: Redis提供了下面几种淘汰策略供用户选择,其中默认的策略为noeviction策略: · noeviction:当内存使用达到阈值的时候,所有引起申请内存的命令会报错. · allkeys-lru:在主键空间中,优先移除最近未使用的key. · volatile-lru:在设置了过期时间的键空间中,优
-
浅谈Redis主从复制以及主从复制原理
面临问题 1. 机器故障.我们部署到一台 Redis 服务器,当发生机器故障时,需要迁移到另外一台服务器并且要保证数据是同步的.而数据是最重要的,如果你不在乎,基本上也就不会使用 Redis 了. 2. 容量瓶颈.当我们有需求需要扩容 Redis 内存时,从 16G 的内存升到 64G,单机肯定是满足不了.当然,你可以重新买个 128G 的新机器. 解决办法 要实现分布式数据库的更大的存储容量和承受高并发访问量,我们会将原来集中式数据库的数据分别存储到其他多个网络节点上.Redis 为了解决这个
-
浅谈Redis中的RDB快照
一.概述 所谓的快照,就是记录某一个瞬间东西,比如当我们给风景拍照时,那一个瞬间的画面和信息就记录到了一张照片. 所以,RDB 快照就是记录某一个瞬间的内存数据,记录的是实际数据,而 AOF 文件记录的是命令操作的日志,而不是实际的数据. 因此在 Redis 恢复数据时, RDB 恢复数据的效率会比 AOF 快些,因为直接将 RDB 文件读入内存就可以了,不需要像 AOF 那样还需要额外执行操作命令的步骤才能恢复数据. 接下来,就来具体聊聊 RDB 快照 . 二.快照怎么用? 要熟悉一个东西,先
-
浅谈Redis跟MySQL的双写问题解决方案
目录 写在前面 三种读写缓存策略 Cache-AsidePattern(旁路缓存模式) Read-Through/Write-Through(读写穿透) WriteBehindPattern(异步缓存写入) 旁路缓存模式解析 CacheAsidePattern的一些疑问 CacheAsidePattern的缺陷 项目中有遇到这个问题,跟MySQL中的数据不一致,研究一番发现这里面细节并不简单,特此记录一下. 写在前面 严格意义上任何非原子操作都不可能保证一致性,除非用阻塞读写实现强一致性,所以缓