PyTorch学习之软件准备与基本操作总结
一、概述
PyTorch可以认为是一个Python库,可以像NumPy、Pandas一样被调用。PyTorch和NumPy功能是类似的,可以将PyTorch看作用在神经网络(深度学习)里的NumPy,并且加入了GPU支持的NumPy(原生NumPy不支持GPU)。
目前,应用最广、热度最高的深度学习框架为PyTorch和TensorFlow。本系列先从PyTorch开始,后面有机会再去弄TersonFlow,还有时间的话,就再去系统回顾下之前学习的Caffe框架。
小结:PyTorch为深度学习框架,为NumPy的替代品,支持GPU,可以用来搭建和训练深度神经网络。
二、工具准备
暂时确定:Anaconda、Jupyter Notebook。
1、Anaconda。
为了降低WSL在C盘下的负担,深度学习这块,准备在Windows下安装各种环境。Anaconda集成了许多优秀的开发工具。例如:Anaconda Navigator和Anaconda Prompt。前者是一个桌面图形界面,内部集成了很多开发工具,如Jupyter Notebook,VSCode。如果要启动某个软件,直接在界面的软件下Launch就行了。后者是Anaconda的终端,可在其中使用conda命令来管理Python库。conda是一个开源的软件包管理系统和环境管理系统,可以方便地管理Python的库函数以及创建虚拟环境。如果要启动该功能,直接在“开始”菜单找到就行了。
如何完成安装?
1.去这里下载对应版本的Anaconda包。
如果进去之后是一个Buy Now的购买界面,那很有可能就是因为挂了代理,速度跟不上,下载没成功,关掉就好。
2.下载好后双击exe程序。Next、I Agree、All Users操作后,选择安装的路径。装的时候提示路径有警告,我觉得是没啥问题的,但保险起见,还是装在没空格的地方。
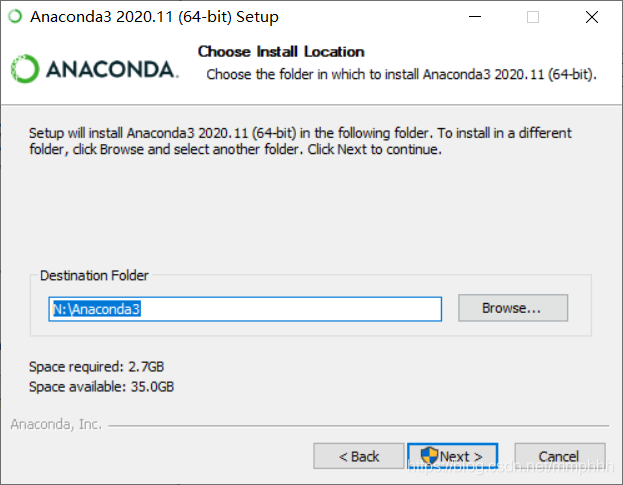
3.Next后出现下面这个情况。这一步是非常重要的!!!需要理解下,不然后面使用Anaconda容易出现问题。
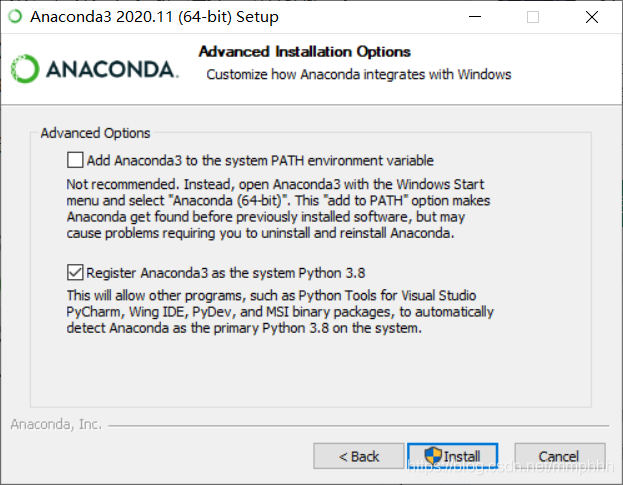
首先关于这段话:
Not recommended.Instead , open Anaconda3 with the Windows startmenu and select “Anaconda (64-bit)”. This “add to PATH” option makesAnaconda get found before previously installed software, but maycause problems requiring you to uninstall and reinstall Anaconda. 不推荐。相反,用Windows开始菜单打开Anaconda3,选择“Anaconda(64位)”。这个“添加到PATH”选项会让你在之前安装的软件之前找到Anaconda,但可能会导致问题,需要你卸载并重新安装Anaconda。
按软件默认的推荐,是不要选中框1内容,将Anaconda添加到路径中。如果选中的话,会将Anaconda添加到系统路径中,这样,就得使用“开始”菜单的Anaconda Navigator或Anaconda命令提示符,来启动Anaconda,不然环境变量是错误的。但如果不选中,以后是可以随时将Anaconda添加到您的PATH中。这里选择不勾选,如果要在命令提示符下使用Anaconda,那就选中该框。由于电脑中没有Python的其他版本,这里直接默认3.8的。next、next并Finish后,完成安装。
如何测试安装?
测试安装的一种好方法是打开Jupyter Notebook。可通过Anaconda Prompt或Anaconda Navigator执行此操作。
1.找到Anaconda Navigator,然后单击Anaconda Navigator。
2.在Jupyter Notebook下,单击Launch。
3.为了在Windows下使用Anaconda中的软件,需要添加下环境变量。
打开命令提示符。运行jupyter notebook,如果出现这个问题,需要配置下路径。
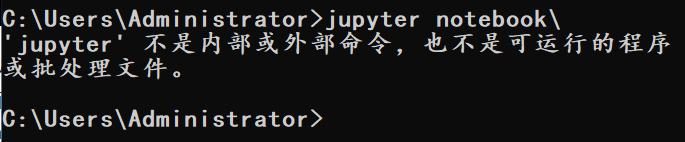
只需要将之前安装时的路径,放到环境变量里的path中去。
三、conda命令
几个非常有用的conda命令。
conda list 列出所有已安装的包 conda install pandas 安装包(比如这里安装Python的Pandas库) conda uninstall pandas 卸载包 conda update pandas
四、PyTorch的安装
在项目开发过程中,由于需求不同,得下载各种不同的框架和库,版本间的差异也会不同,需要不断更新或卸载对应的库,管理非常麻烦。需要创建虚拟环境,来为不同的项目创建独立的空间,这个空间里安装的任何库和框架都是独立的,不会影响到外部环境。这时,就需要上面安装的Anaconda了。
1.打开Anaconda Prompt。在命令行中输入:
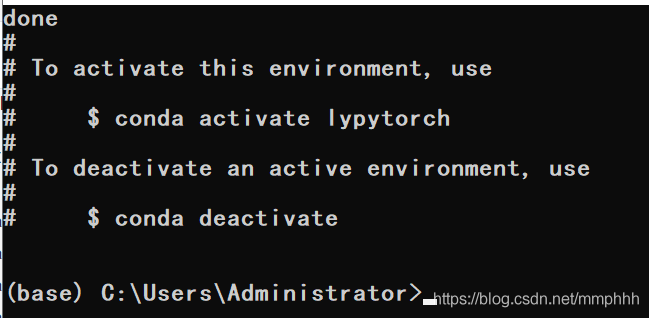
conda create --name lypytorch python=3.8
lypytorch是我的虚拟环境名称,可以自由命名。虚拟环境的运行需要一些库,安装完后,返回下面结果。
2.输入activate lypytorch进入虚拟环境。如果不想使用虚拟环境了,可以输入conda.bat deactivate来关闭当前虚拟环境(直接使用deactivate lypytorch不太行,会提示错误,一个坑点)。

3.浏览器中进入这个页面,进入Pytorch的官网后,点击Get Started进入下载页面。

在Compute Platform中,如果想用GPU计算,得选CUDA等来安装GPU版本的PyTorch。安装GPU版本的PyTorch,得先有块NVIDIA的GPU并且安装了显卡的驱动,并且在安装前,需要提前安装CUDA和CUDNN,这里我自己的电脑,虽然有显卡,但也不是很好的那种,就用CPU版本的。安装GPU版本的PyTorch需要硬件支持,而且准备工作非常多,推荐先使用CPU版本的PyTorch。其实,小规模的神经网络,PyTorch的运行速度并无比较大的区别。
在虚拟环境PyTorch中输入下面命令,就可以开始PyTorch的安装了。
conda install pytorch torchvision torchaudio cpuonly -c pytorch

4.新建的虚拟环境是没有Jupyter的,需要运行下面的指令来安装。
conda install jupyter
运行后的输出。

当然,除了Jupyter外,还可以根据需要使用conda命令安装其他的Python库。
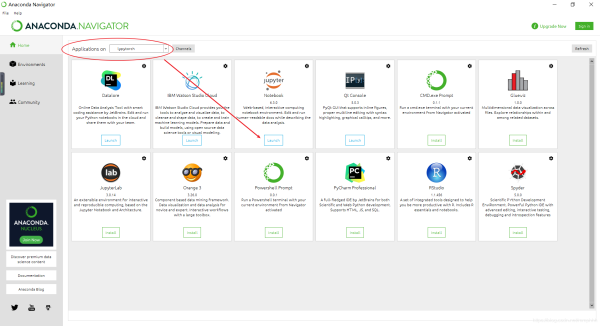
5.安装完后进行测试。打开Anaconda Navigator,由于PyTorch安装在虚拟环境lypytorch中的,可以在Anaconda Navigator界面中的Applications on下拉列表框中选择lypytorch,然后,可以启动该环境下的Jupyter Notebook。
6.打开Jupyter Notebook后,输入import等指令来导入库。
import torch import torchvision torch.__version__
这里的torch是PyTorch的核心库,torchvision包是服务于PyTorch深度学习框架的,用来产生图片、视频数据集、一些流行的模型类和预训练模型。简言之,torchvision由torchvision.datasets、torchvision.models、torchvision.transforms和torchvision.utils四个模块组成。安装的时候,会同时安装了PyTorch和torchvision。结果如下面所示,表示运行成功。

五、Jupyter修改默认路径
Jupyter默认打开的路径不知跑到哪去了,需要修改下默认的启动路径。
1.虚拟环境下,运行下面指令查看配置文件路径。
jupyter notebook --generate-config
得到下面结果:

2.在Windows系统下,找到对应的文件。

3.打开后搜索到下面的代码,把注释去掉后,选择默认的工作路径。
## The directory to use for notebooks and kernels. #c.NotebookApp.notebook_dir = ''
这里D:\Jupyter_PyTorch是我的工作路径,可以修改成自己的。还得注意,指令前面是不能留空格的。同时自己的工作文件夹需要提前新建,否则Jupyter Notebook会找不到这个文件,会产生闪退现象。

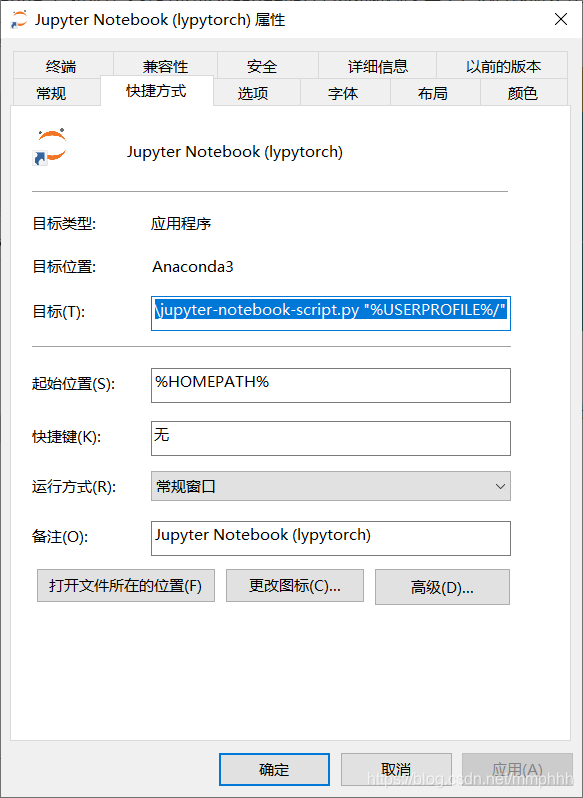
4.更改完,再右键自己虚拟环境下的Jupyter快捷方式,点击属性,将“%USERPROFILE%”删除保存。

右键属性打开后删除对应的路径,并应用下。
5.修改完,可以直接点击程序运行,默认是打开虚拟环境下Jupyter,打开后,新建一个文件,导入一下PyTorch,保存一下,可以看到在之前的工作空间下,已经产生了保存的文件。

Note:
如果命令“jupyter notebook --generate-config”执行有错误,大多是因为没有配置环境变量导致的,需要先进行设置下。
到此这篇关于PyTorch学习之软件准备与基本操作总结的文章就介绍到这了,更多相关PyTorch软件准备与基本操作内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pytorch实现全连接层的操作
全连接神经网络(FC) 全连接神经网络是一种最基本的神经网络结构,英文为Full Connection,所以一般简称FC. FC的准则很简单:神经网络中除输入层之外的每个节点都和上一层的所有节点有连接. 以上一次的MNIST为例 import torch import torch.utils.data from torch import optim from torchvision import datasets from torchvision.transforms import transf
-
pytorch_detach 切断网络反传方式
detach 官方文档中,对这个方法是这么介绍的. detach = _add_docstr(_C._TensorBase.detach, r""" Returns a new Tensor, detached from the current graph. The result will never require gradient. .. note:: Returned Tensor uses the same data tensor as the original on
-
PyTorch的Debug指南
一.ipdb 介绍 很多初学 python 的同学会使用 print 或 log 调试程序,但是这只在小规模的程序下调试很方便,更好的调试应该是在一边运行的时候一边检查里面的变量和方法. 感兴趣的可以去了解 pycharm 的 debug 模式,功能也很强大,能够满足一般的需求,这里不多做赘述,我们这里介绍一个更适用于 pytorch 的一个灵活的 pdb 交互式调试工具. Pdb 是一个交互式的调试工具,集成与 Python 标准库中,它能让你根据需求跳转到任意的 Python 代码断点.查看
-
聊聊PyTorch中eval和no_grad的关系
首先这两者有着本质上区别 model.eval()是用来告知model内的各个layer采取eval模式工作.这个操作主要是应对诸如dropout和batchnorm这些在训练模式下需要采取不同操作的特殊layer.训练和测试的时候都可以开启. torch.no_grad()则是告知自动求导引擎不要进行求导操作.这个操作的意义在于加速计算.节约内存.但是由于没有gradient,也就没有办法进行backward.所以只能在测试的时候开启. 所以在evaluate的时候,需要同时使用两者. mod
-

pytorch实现线性回归以及多元回归
本文实例为大家分享了pytorch实现线性回归以及多元回归的具体代码,供大家参考,具体内容如下 最近在学习pytorch,现在把学习的代码放在这里,下面是github链接 直接附上github代码 # 实现一个线性回归 # 所有的层结构和损失函数都来自于 torch.nn # torch.optim 是一个实现各种优化算法的包,调用的时候必须是需要优化的参数传入,这些参数都必须是Variable x_train = np.array([[3.3],[4.4],[5.5],[6.71],[6.93
-
pytorch 禁止/允许计算局部梯度的操作
一.禁止计算局部梯度 torch.autogard.no_grad: 禁用梯度计算的上下文管理器. 当确定不会调用Tensor.backward()计算梯度时,设置禁止计算梯度会减少内存消耗.如果需要计算梯度设置Tensor.requires_grad=True 两种禁用方法: 将不用计算梯度的变量放在with torch.no_grad()里 >>> x = torch.tensor([1.], requires_grad=True) >>> with torch.n
-
使用pytorch实现线性回归
本文实例为大家分享了pytorch实现线性回归的具体代码,供大家参考,具体内容如下 线性回归都是包括以下几个步骤:定义模型.选择损失函数.选择优化函数. 训练数据.测试 import torch import matplotlib.pyplot as plt # 构建数据集 x_data= torch.Tensor([[1.0],[2.0],[3.0],[4.0],[5.0],[6.0]]) y_data= torch.Tensor([[2.0],[4.0],[6.0],[8.0],[10.0]
-
pytorch中的nn.ZeroPad2d()零填充函数实例详解
在卷积神经网络中,有使用设置padding的参数,配合卷积步长,可以使得卷积后的特征图尺寸大小不发生改变,那么在手动实现图片或特征图的边界零填充时,常用的函数是nn.ZeroPad2d(),可以指定tensor的四个方向上的填充,比如左边添加1dim.右边添加2dim.上边添加3dim.下边添加4dim,即指定paddin参数为(1,2,3,4),本文中代码设置的是(3,4,5,6)如下: import torch.nn as nn import cv2 import torchvision f
-
win10系统配置GPU版本Pytorch的详细教程
一.安装cuda 1.在英伟达官网下载最新版的cuda驱动 https://developer.nvidia.com/zh-cn/cuda-downloads 都选上就行了,然后一路默认安装 输入nvcc -V查看是否安装成功 二.安装pycuda 1.在控制台中输入pip install pycuda 安装pycuda 2.在环境变量中添加cl.exe 3.测试pycuda是否正常运行 import pycuda.driver as drv import pycuda.tools,pycuda
-
pytorch 优化器(optim)不同参数组,不同学习率设置的操作
optim 的基本使用 for do: 1. 计算loss 2. 清空梯度 3. 反传梯度 4. 更新参数 optim的完整流程 cifiron = nn.MSELoss() optimiter = torch.optim.SGD(net.parameters(),lr=0.01,momentum=0.9) for i in range(iters): out = net(inputs) loss = cifiron(out,label) optimiter.zero_grad() # 清空之前
-
浅谈pytorch中的nn.Sequential(*net[3: 5])是啥意思
看到代码里面有这个 1 class ResNeXt101(nn.Module): 2 def __init__(self): 3 super(ResNeXt101, self).__init__() 4 net = resnext101() # print(os.getcwd(), net) 5 net = list(net.children()) # net.children()得到resneXt 的表层网络 # for i, value in enumerate(net): # print(
-
Pytorch实现图像识别之数字识别(附详细注释)
使用了两个卷积层加上两个全连接层实现 本来打算从头手撕的,但是调试太耗时间了,改天有时间在从头写一份 详细过程看代码注释,参考了下一个博主的文章,但是链接没注意关了找不到了,博主看到了联系下我,我加上 代码相关的问题可以评论私聊,也可以翻看博客里的文章,部分有详细解释 Python实现代码: import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transf
-
如何利用Pytorch计算三角函数
一.加载库 首先加载torch库,进入python后加载库使用import导入 [import 库名] 二.sin值计算方法 pytorch中的sin计算都是基于tensor的,所以无论单个值还是多个值同时计算sin值,都需要首先将输入量转换为tensor 使用指令: [torch.sin(tensor)] 实例中,使用了计算单个和多个sin值时的情况 三.cos值计算方法 pytorch中的cos计算都是基于tensor的,所以无论单个值还是多个值同时计算cos值,都需要首先将输入量转换为te
-
pytorch visdom安装开启及使用方法
安装 conda activate ps pip install visdom 激活ps的环境,在指定的ps环境中安装visdom 开启 python -m visdom.server 浏览器输入红框内的网址 使用 1. 简单示例:一条线 from visdom import Visdom # 创建一个实例 viz=Visdom() # 创建一个直线,再把最新数据添加到直线上 # y x二维两个轴,win 创建一个小窗口,不指定就默认为大窗口,opts其他信息比如名称 viz.line([1,2
-
PyTorch CUDA环境配置及安装的步骤(图文教程)
Pytorch版本介绍 torch:1.6 CUDA:10.2 cuDNN:8.1.0 ✨安装 NVIDIA 显卡驱动程序 一般 电脑出厂/装完系统 会自动安装显卡驱动 如果有 可直接进行下一步 下载链接 http://www.nvidia.cn/Download/index.aspx?lang=cn 选择和自己显卡相匹配的显卡驱动 下载安装 ✨确认项目所需torch版本 # pip install -r requirements.txt # base ---------------------
-
Python深度学习之使用Pytorch搭建ShuffleNetv2
一.model.py 1.1 Channel Shuffle def channel_shuffle(x: Tensor, groups: int) -> Tensor: batch_size, num_channels, height, width = x.size() channels_per_group = num_channels // groups # reshape # [batch_size, num_channels, height, width] -> [batch_size
-
PyTorch 如何将CIFAR100数据按类标归类保存
few-shot learning的采样 Few-shot learning 基于任务对模型进行训练,在N-way-K-shot中,一个任务中的meta-training中含有N类,每一类抽取K个样本构成support set, query set则是在刚才抽取的N类剩余的样本中sample一定数量的样本(可以是均匀采样,也可以是不均匀采样). 对数据按类标归类 针对上述情况,我们需要使用不同类别放置在不同文件夹的数据集.但有时,数据并没有按类放置,这时就需要对数据进行处理. 下面以CIFAR1