细数nn.BCELoss与nn.CrossEntropyLoss的区别
以前我浏览博客的时候记得别人说过,BCELoss与CrossEntropyLoss都是用于分类问题。可以知道,BCELoss是Binary CrossEntropyLoss的缩写,BCELoss CrossEntropyLoss的一个特例,只用于二分类问题,而CrossEntropyLoss可以用于二分类,也可以用于多分类。
不过我重新查阅了一下资料,发现同样是处理二分类问题,BCELoss与CrossEntropyLoss是不同的。下面我详细讲一下哪里不同。
1、使用nn.BCELoss需要在该层前面加上Sigmoid函数。
公式如下:
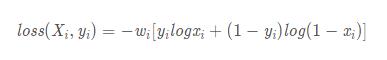
2、使用nn.CrossEntropyLoss会自动加上Sofrmax层。
公式如下:
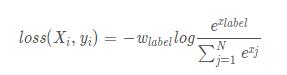
可以看出,这两个计算损失的函数使用的激活函数不同,故而最后的计算公式不同。
补充拓展:pytorch的BCELoss和cross entropy
BCELoss:
torch.nn.BCELoss:
Input: (N, *)(N,∗) where *∗ means, any number of additional dimensions Target: (N, *)(N,∗), same shape as the input Output: scalar. If reduction is 'none', then (N, *)(N,∗), same shape as input.
这里的输入和target 目标必须形状一致,并且都是浮点数,二分类中一般用sigmoid的把输出挑出一个数:
>>> m = nn.Sigmoid() >>> loss = nn.BCELoss() >>> input = torch.randn(3, requires_grad=True) >>> target = torch.empty(3).random_(2) >>> output = loss(m(input), target) >>> output.backward()
CrossEntropyLoss:
input(N,C) #n 是batch c是类别 target(N)
输入和target 形状是不同的crossEntropy 是自己会做softmax
>>> loss = nn.CrossEntropyLoss() >>> input = torch.randn(3, 5, requires_grad=True) >>> target = torch.empty(3, dtype=torch.long).random_(5) >>> output = loss(input, target) >>> output.backward()
以上这篇细数nn.BCELoss与nn.CrossEntropyLoss的区别就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pytorch中交叉熵损失(nn.CrossEntropyLoss())的计算过程详解
公式 首先需要了解CrossEntropyLoss的计算过程,交叉熵的函数是这样的: 其中,其中yi表示真实的分类结果.这里只给出公式,关于CrossEntropyLoss的其他详细细节请参照其他博文. 测试代码(一维) import torch import torch.nn as nn import math criterion = nn.CrossEntropyLoss() output = torch.randn(1, 5, requires_grad=True) label = tor
-
细数nn.BCELoss与nn.CrossEntropyLoss的区别
以前我浏览博客的时候记得别人说过,BCELoss与CrossEntropyLoss都是用于分类问题.可以知道,BCELoss是Binary CrossEntropyLoss的缩写,BCELoss CrossEntropyLoss的一个特例,只用于二分类问题,而CrossEntropyLoss可以用于二分类,也可以用于多分类. 不过我重新查阅了一下资料,发现同样是处理二分类问题,BCELoss与CrossEntropyLoss是不同的.下面我详细讲一下哪里不同. 1.使用nn.BCELoss需要在
-
对Pytorch中nn.ModuleList 和 nn.Sequential详解
简而言之就是,nn.Sequential类似于Keras中的贯序模型,它是Module的子类,在构建数个网络层之后会自动调用forward()方法,从而有网络模型生成.而nn.ModuleList仅仅类似于pytho中的list类型,只是将一系列层装入列表,并没有实现forward()方法,因此也不会有网络模型产生的副作用. 需要注意的是,nn.ModuleList接受的必须是subModule类型,例如: nn.ModuleList( [nn.ModuleList([Conv(inp_dim
-
对tensorflow中tf.nn.conv1d和layers.conv1d的区别详解
在用tensorflow做一维的卷积神经网络的时候会遇到tf.nn.conv1d和layers.conv1d这两个函数,但是这两个函数有什么区别呢,通过计算得到一些规律. 1.关于tf.nn.conv1d的解释,以下是Tensor Flow中关于tf.nn.conv1d的API注解: Computes a 1-D convolution given 3-D input and filter tensors. Given an input tensor of shape [batch, in_wi
-
细数JavaScript 一个等号,两个等号,三个等号的区别
一个等号 =:表示赋值 : 两个等号 ==:先转换类型再比较 : 三个等号 ===:先判断类型,如果不是同一类型直接false. 以上就是小编为大家带来的细数JavaScript 一个等号,两个等号,三个等号的区别全部内容了,希望大家多多支持我们~
-
细数MySQL中SQL语句的分类
1:数据定义语言(DDL) 用于创建.修改.和删除数据库内的数据结构,如:1:创建和删除数据库(CREATE DATABASE || DROP DATABASE):2:创建.修改.重命名.删除表(CREATE TABLE || ALTER TABLE|| RENAME TABLE||DROP TABLE):3:创建和删除索引(CREATEINDEX || DROP INDEX) 2:数据查询语言(DQL) 从数据库中的一个或多个表中查询数据(SELECT) 3:数据操作语
-
细数Ajax请求中的async:false和async:true的差异
实例如下: function test(){ var temp="00"; $.ajax({ async: false, type : "GET", url : 'userL_checkPhone.do', complete: function(msg){ alert('complete'); }, success : function(data) { alert('success'); temp=data; temp="aa"; } }); a
-
细数java中Long与Integer比较容易犯的错误总结
今天使用findbugs扫描项目后发现很多高危漏洞,其中非常常见的一个是比较两个Long或Integer时直接使用的==来比较. 其实这样是错误的. 因为Long与Ineger都是包装类型,是对象. 而不是普通类型long与int , 所以它们在比较时必须都应该用equals,或者先使用longValue()或intValue()方法来得到他们的基本类型的值然后使用==比较也是可以的. 但是有一种特殊情况, 其实Long与Integer都将 -128~127 这些对象缓存了. 可以看看Long类
-
细数Java接口的概念、分类及与抽象类的区别
Java接口(Interface),是一系列方法的声明,是一些方法特征的集合,一个接口只有方法的特征没有方法的实现,因此这些方法可以在不同的地方被不同的类实现,而这些实现可以具有不同的行为(功能). 一.接口含义: 1.Java接口,Java语言中存在的结构,有特定的语法和结构: 2.一个类所具有的方法的特征集合,是一种逻辑上的抽象. 前者叫做"Java接口",后者叫做"接口". Java接口本身没有任何实现,因为Java接口不涉及表象,而只描述public行为,所
-
PyTorch之nn.ReLU与F.ReLU的区别介绍
我就废话不多说了,大家还是直接看代码吧~ import torch.nn as nn import torch.nn.functional as F import torch.nn as nn class AlexNet_1(nn.Module): def __init__(self, num_classes=n): super(AlexNet, self).__init__() self.features = nn.Sequential( nn.Conv2d(3, 64, kernel_siz
-

Java由浅入深细数数组的操作
目录 1.JVM的内存分布 2.引用类型变量的特点 3.一维数组的使用 3.1定义和初始化 3.2数组的访问 3.3打印数组所有的元素 3.4数组的拷贝 3.5作为参数和返回值 本篇介绍一维数组以及相关操作,二维数组放在下一篇 1.JVM的内存分布 Java的代码是运行在JVM上的,为了方便管理,对所使用的内存按照功能的不同进行了划分,这不是本篇重点,只做简单的介绍: Java虚拟栈:局部变量在这里开辟空间 Java本地方法栈:运行一些由C/C++编写的程序 堆:对象在这里存储,且开辟后的空间使