python sklearn包——混淆矩阵、分类报告等自动生成方式
preface:做着最近的任务,对数据处理,做些简单的提特征,用机器学习算法跑下程序得出结果,看看哪些特征的组合较好,这一系列流程必然要用到很多函数,故将自己常用函数记录上。应该说这些函数基本上都会用到,像是数据预处理,处理完了后特征提取、降维、训练预测、通过混淆矩阵看分类效果,得出报告。
1.输入
从数据集开始,提取特征转化为有标签的数据集,转为向量。拆分成训练集和测试集,这里不多讲,在上一篇博客中谈到用StratifiedKFold()函数即可。在训练集中有data和target开始。
2.处理
def my_preprocessing(train_data):
from sklearn import preprocessing
X_normalized = preprocessing.normalize(train_data ,norm = "l2",axis=0)#使用l2范式,对特征列进行正则
return X_normalized
def my_feature_selection(data, target):
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
data_new = SelectKBest(chi2, k= 50).fit_transform(data,target)
return data_new
def my_PCA(data):#data without target, just train data, withou train target.
from sklearn import decomposition
pca_sklearn = decomposition.PCA()
pca_sklearn.fit(data)
main_var = pca_sklearn.explained_variance_
print sum(main_var)*0.9
import matplotlib.pyplot as plt
n = 15
plt.plot(main_var[:n])
plt.show()
def clf_train(data,target):
from sklearn import svm
#from sklearn.linear_model import LogisticRegression
clf = svm.SVC(C=100,kernel="rbf",gamma=0.001)
clf.fit(data,target)
#clf_LR = LogisticRegression()
#clf_LR.fit(x_train, y_train)
#y_pred_LR = clf_LR.predict(x_test)
return clf
def my_confusion_matrix(y_true, y_pred):
from sklearn.metrics import confusion_matrix
labels = list(set(y_true))
conf_mat = confusion_matrix(y_true, y_pred, labels = labels)
print "confusion_matrix(left labels: y_true, up labels: y_pred):"
print "labels\t",
for i in range(len(labels)):
print labels[i],"\t",
print
for i in range(len(conf_mat)):
print i,"\t",
for j in range(len(conf_mat[i])):
print conf_mat[i][j],'\t',
print
print
def my_classification_report(y_true, y_pred):
from sklearn.metrics import classification_report
print "classification_report(left: labels):"
print classification_report(y_true, y_pred)
my_preprocess()函数:
主要使用sklearn的preprocessing函数中的normalize()函数,默认参数为l2范式,对特征列进行正则处理。即每一个样例,处理标签,每行的平方和为1.
my_feature_selection()函数:
使用sklearn的feature_selection函数中SelectKBest()函数和chi2()函数,若是用词袋提取了很多维的稀疏特征,有必要使用卡方选取前k个有效的特征。
my_PCA()函数:
主要用来观察前多少个特征是主要特征,并且画图。看看前多少个特征占据主要部分。
clf_train()函数:
可用多种机器学习算法,如SVM, LR, RF, GBDT等等很多,其中像SVM需要调参数的,有专门调试参数的函数如StratifiedKFold()(见前几篇博客)。以达到最优。
my_confusion_matrix()函数:
主要是针对预测出来的结果,和原来的结果对比,算出混淆矩阵,不必自己计算。其对每个类别的混淆矩阵都计算出来了,并且labels参数默认是排序了的。
my_classification_report()函数:
主要通过sklearn.metrics函数中的classification_report()函数,针对每个类别给出详细的准确率、召回率和F-值这三个参数和宏平均值,用来评价算法好坏。另外ROC曲线的话,需要是对二分类才可以。多类别似乎不行。
主要参考sklearn官网
补充拓展:[sklearn] 混淆矩阵——多分类预测结果统计
调用的函数:confusion_matrix(typeTrue, typePred)
typeTrue:实际类别,list类型
typePred:预测类别,list类型
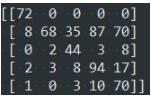
结果如下面的截图:
第i行:实际为第i类,预测到各个类的样本数
第j列:预测为第j类,实际为各个类的样本数
true↓ predict→
以上这篇python sklearn包——混淆矩阵、分类报告等自动生成方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

详解使用python绘制混淆矩阵(confusion_matrix)
Summary 涉及到分类问题,我们经常需要通过可视化混淆矩阵来分析实验结果进而得出调参思路,本文介绍如何利用python绘制混淆矩阵(confusion_matrix),本文只提供代码,给出必要注释. Code # -*-coding:utf-8-*- from sklearn.metrics import confusion_matrix import matplotlib.pyplot as plt import numpy as np #labels表示你不同类别的代号,比如这里的de
-
python sklearn包——混淆矩阵、分类报告等自动生成方式
preface:做着最近的任务,对数据处理,做些简单的提特征,用机器学习算法跑下程序得出结果,看看哪些特征的组合较好,这一系列流程必然要用到很多函数,故将自己常用函数记录上.应该说这些函数基本上都会用到,像是数据预处理,处理完了后特征提取.降维.训练预测.通过混淆矩阵看分类效果,得出报告. 1.输入 从数据集开始,提取特征转化为有标签的数据集,转为向量.拆分成训练集和测试集,这里不多讲,在上一篇博客中谈到用StratifiedKFold()函数即可.在训练集中有data和target开始. 2.
-
使用Python和scikit-learn创建混淆矩阵的示例详解
目录 一.混淆矩阵概述 1.示例1 2.示例2 二.使用Scikit-learn 创建混淆矩阵 1.相应软件包 2.生成示例数据集 3.训练一个SVM 4.生成混淆矩阵 5.可视化边界 一.混淆矩阵概述 在训练了有监督的机器学习模型(例如分类器)之后,您想知道它的工作情况. 这通常是通过将一小部分称为测试集的数据分开来完成的,该数据用作模型以前从未见过的数据. 如果它在此数据集上表现良好,那么该模型很可能在其他数据上也表现良好 - 当然,如果它是从与您的测试集相同的分布中采样的. 现在,当您测试
-
Python实现两种多分类混淆矩阵
目录 1.什么是混淆矩阵 2.分类模型评价指标 3.两种多分类混淆矩阵 3.1直接打印出每一个类别的分类准确率. 3.2打印具体的分类结果的数值 4.总结 1.什么是混淆矩阵 深度学习中,混淆矩阵是ROC曲线绘制的基础,同时它也是衡量分类型模型准确度中最基本,最直观,计算最简单的方法.它可以直观地了解分类模型在每一类样本里面表现,常作为模型评估的一部分.它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class). 首先要明确几个概念: T或者F:该样本 是否被正确分类
-
Python sklearn库实现PCA教程(以鸢尾花分类为例)
PCA简介 主成分分析(Principal Component Analysis,PCA)是最常用的一种降维方法,通常用于高维数据集的探索与可视化,还可以用作数据压缩和预处理等.矩阵的主成分就是其协方差矩阵对应的特征向量,按照对应的特征值大小进行排序,最大的特征值就是第一主成分,其次是第二主成分,以此类推. 基本步骤: 具体实现 我们通过Python的sklearn库来实现鸢尾花数据进行降维,数据本身是4维的降维后变成2维,可以在平面中画出样本点的分布.样本数据结构如下图: 其中样本总数为150
-
利用python中的matplotlib打印混淆矩阵实例
前面说过混淆矩阵是我们在处理分类问题时,很重要的指标,那么如何更好的把混淆矩阵给打印出来呢,直接做表或者是前端可视化,小编曾经就尝试过用前端(D5)做出来,然后截图,显得不那么好看.. 代码: import itertools import matplotlib.pyplot as plt import numpy as np def plot_confusion_matrix(cm, classes, normalize=False, title='Confusion matrix', cma
-
python机器学习混淆矩阵及confusion matrix函数使用
目录 1.混淆矩阵 2.confusion_matrix函数的使用 实现例子: 运行结果: 关于混淆矩阵的概念,可参考此篇博文混淆矩阵 1.混淆矩阵 混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型作出的分类判断两个标准进行汇总.这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class) 下图是混淆矩阵的一个例子 其中灰色部分是真实分类和预测分类结果相一致的,绿色部分是真实分类和预测分类不一致的,即
-
Python利用Seaborn绘制多标签的混淆矩阵
Seaborn - 绘制多标签的混淆矩阵.召回.精准.F1 导入seaborn\matplotlib\scipy\sklearn等包: import seaborn as sns from matplotlib import pyplot as plt from scipy.special import softmax from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_sco
-
python利用sklearn包编写决策树源代码
本文实例为大家分享了python编写决策树源代码,供大家参考,具体内容如下 因为最近实习的需要,所以用python里的sklearn包重新写了一次决策树. 工具:sklearn,将dot文件转化为pdf格式(是为了将形成的决策树可视化)graphviz-2.38,下载解压之后将其中的bin文件的目录添加进环境变量 源代码如下: from sklearn.feature_extraction import DictVectorizer import csv from sklearn import
-
python sklearn常用分类算法模型的调用
本文实例为大家分享了python sklearn分类算法模型调用的具体代码,供大家参考,具体内容如下 实现对'NB', 'KNN', 'LR', 'RF', 'DT', 'SVM','SVMCV', 'GBDT'模型的简单调用. # coding=gbk import time from sklearn import metrics import pickle as pickle import pandas as pd # Multinomial Naive Bayes Classifier d