Python 调用有道翻译接口实现翻译
最近为了熟悉一下 js 用有道翻译练了一下手,写一篇博客记录一下,也希望能对大家有所启迪,不过这些网站更新太快,可能大家尝试的时候会有所不同。
首先来看一下网页 post 过去的数据

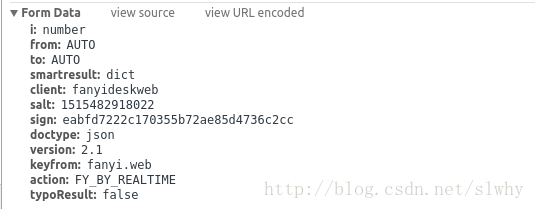
大家不难发现,我们翻译的内容是放在 post 的 data 中的,这些参数,除了 salt 和 sign 要么就是不会变化,要么就是一眼能看出来意义的;那么这个 salt 和 sign 是什么呢?salt 根据 ta 数据的特征,我们应该会想到,这应该是一个时间戳,而 sign 又是什么呢?我们一起来看一下
找到这个 js 文件,最上面这个 send 文件
将里面的 js 代码拷贝出来,格式化一下,搜索 sign
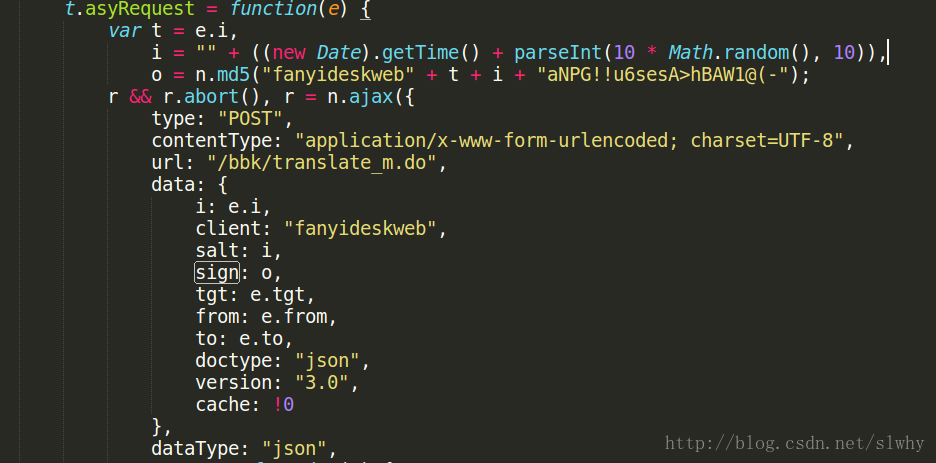
我们发现,salt 确实是一个时间戳,但 sign 呢?,这里对 sign 的计算稍微多啰嗦几句,如图:

大家发现 sign 的值,也就是 o 一共是对四个参数进行求 md5 码,两个是定值,一个是前面求到的时间戳,还有一个是什么呢?这个地方我也找了挺久的(还是不懂 js 的痛啊,哭。。。)剩下的参数,就是图片中所谓的 t
var t = e.i
然后在 data 中,大家还能发现这么一句:
i:e.i
这个 i 我们对应到 ta 发送的 data 中,不就是我们要翻译的字符串吗?哈哈哈,被我发现了吧!
发现这个就好办了,我们找出其中参数之间的关系,用Python实现 ta

但当我们构造好 data 兴高采烈地将数据 post 过去的时候,会发现出现报错了

为什么呢?难道是我们的 data 构造的有问题吗?不清楚,先尝试一下,咱们吧浏览器中的 data 拷贝进来运行一下,发现还是出错了;那么说明错误不是出在 data 上面了,那究竟是那里出了问题呢?难道 ta 还有其他的校验方式;别着急继续分析,我们再观察一下,post 请求,发现这个请求是带了 cookie的,于是我们猜测,是不是 cookie 的原因呢? 还是不清楚,我们尝试一下,将 data 对应的 cookie 加上,再运行一下。发现这次通过了,我们的猜测没错,确实是 cookie 的原因,那么这个 cookie 又是怎么来的呢?
Cookie

多尝试几次,大家会发现,不同的请求内容,前面两个是不会发生改变的,而第三个,结合我们之前的经验,是不是很像一个时间戳;既然有猜测,咱们就又来尝试一下,自己构造一个 Cookie post 过去,万事大吉,哈哈哈哈。
最后附上我的代码
#/usr/bin/python
# encoding:utf-8
# __Author__ = Slwhy
import requests
import time
import random
import hashlib
#i = "" + ((new Date).getTime() + parseInt(10 * Math.random(), 10))
i = str(int(time.time()*1000)+random.randint(1,10))
#o = n.md5("fanyideskweb" + t + i + "aNPG!!u6sesA>hBAW1@(-");
t = raw_input("please input the word you want to translate:")
u = 'fanyideskweb'
l = 'aNPG!!u6sesA>hBAW1@(-'
src = u + t + i + l # u 与 l 是固定字符串,t是你要翻译的字符串,i是之前的时间戳
m2 = hashlib.md5()
m2.update(src)
str_sent = m2.hexdigest()
'''
i:number
from:AUTO
to:AUTO
smartresult:dict
client:fanyideskweb
salt:1515462554510
sign:32ea4a33c063d174a069959a5df1a115
doctype:json
version:2.1
keyfrom:fanyi.web
action:FY_BY_REALTIME
typoResult:false
'''
head = {
'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Content-Length':'200',
'Connection':'keep-alive',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Host':'fanyi.youdao.com',
'Origin':'http://fanyi.youdao.com',
'Referer':'http://fanyi.youdao.com/',
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36',
'X-Requested-With':'XMLHttpRequest',
# 'Cookie': 'YOUDAO_MOBILE_ACCESS_TYPE=1; OUTFOX_SEARCH_USER_ID=833904829@10.169.0.84; OUTFOX_SEARCH_USER_ID_NCOO=1846816080.1245883; fanyi-ad-id=39535; fanyi-ad-closed=1; JSESSIONID=aaaYuYbMKHEJQ7Hanizdw; ___rl__test__cookies=1515471316884'
}
head['Cookie'] = 'OUTFOX_SEARCH_USER_ID=833904829@10.169.0.84; OUTFOX_SEARCH_USER_ID_NCOO=1846816080.1245883; ___rl__test__cookies='+str(time.time()*1000)
# '___rl__test__cookies=1515471316884'
data = {
'i': t,
'from':'AUTO',
'to':'AUTO',
'smartresult':'dict',
'client':'fanyideskweb',
'salt':i,
'sign':str_sent,
'doctype':'json',
'version':'2.1',
'keyfrom':'fanyi.web',
'action':'FY_BY_REALTIME',
'typoResult':'false'
}
s = requests.session()
# print data
url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
p = s.post(url,data= data,headers = head)
print p.text
到此这篇关于Python 调用有道翻译接口实现翻译的文章就介绍到这了,更多相关Python 有道翻译内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

如何基于Python制作有道翻译小工具
这篇文章主要介绍了如何基于Python制作有道翻译小工具,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 该工具主要是利用了爬虫,爬取web有道翻译的内容. 然后利用简易GUI来可视化结果. 首先我们进入有道词典的首页,并点击翻译结果的审查元素 之后request响应网页,并分析网页,定位到翻译结果. 使用tkinter来制作一个建议的GUI 期间遇到的一个问题则是如何刷新翻译的结果,否则的话会在text里一直累加翻译结果. 于是,在mainlo
-
Python3.6实现带有简单界面的有道翻译小程序
本人使用的是Python3.6(32bit),在win10上运行的 代码如下: from tkinter import * import urllib.request import urllib.parse import json #实现翻译功能的函数 def translate(content): url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&ses
-
python利用有道翻译实现"语言翻译器"的功能实例
实例如下: import urllib.request import urllib.parse import json while True: content = input('请输入需要翻译的内容(退出输入Q):') if content == 'Q': break else: url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom
-
用python3 urllib破解有道翻译反爬虫机制详解
前言 最近在学习python 爬虫方面的知识,网上有一博客专栏专门写爬虫方面的,看到用urllib请求有道翻译接口获取翻译结果.发现接口变化很大,用md5加了密,于是自己开始破解.加上网上的其他文章找源码方式并不是通用的,所有重新写一篇记录下. 爬取条件 要实现爬取的目标,首先要知道它的地址,请求参数,请求头,响应结果. 进行抓包分析 打开有道翻译的链接:http://fanyi.youdao.com/.然后在按f12 点击Network项.这时候就来到了网络监听窗口,在这个页面中发送的所有网络
-
Python通过调用有道翻译api实现翻译功能示例
本文实例讲述了Python通过调用有道翻译api实现翻译功能.分享给大家供大家参考,具体如下: 通过调用有道翻译的api,实现中译英.其他语言译中文 Python代码: # coding=utf-8 import urllib import urllib2 import json import time import hashlib class YouDaoFanyi: def __init__(self, appKey, appSecret): self.url = 'https://open
-
Python爬虫实现简单的爬取有道翻译功能示例
本文实例讲述了Python爬虫实现简单的爬取有道翻译功能.分享给大家供大家参考,具体如下: # -*- coding:utf-8 -*- #!python3 import urllib.request import urllib.parse import json while True : content = input("请输入需要翻译的内容:(按q退出)") if content == 'q' : break url = 'http://fanyi.youdao.com/trans
-
详解Python3网络爬虫(二):利用urllib.urlopen向有道翻译发送数据获得翻译结果
上一篇内容,已经学会了使用简单的语句对网页进行抓取.接下来,详细看下urlopen的两个重要参数url和data,学习如何发送数据data 一.urlopen的url参数 Agent url不仅可以是一个字符串,例如:http://www.baidu.com.url也可以是一个Request对象,这就需要我们先定义一个Request对象,然后将这个Request对象作为urlopen的参数使用,方法如下: # -*- coding: UTF-8 -*- from urllib import re
-
python 调用有道api接口的方法
初学python ,研究了几天,写了一个python 调用 有道api接口程序 效果看下图: 申明:代码仅供和我一样的初学者学习交流 有道api申请地址http://fanyi.youdao.com/openapi?path=data-mode 申请很简单的 ps:审核不用花时间的,请勿滥用!! #-*- coding: UTF-8 -*- import urllib import urllib2 import requests import json import sys reload(sys
-
Python 调用有道翻译接口实现翻译
最近为了熟悉一下 js 用有道翻译练了一下手,写一篇博客记录一下,也希望能对大家有所启迪,不过这些网站更新太快,可能大家尝试的时候会有所不同. 首先来看一下网页 post 过去的数据 大家不难发现,我们翻译的内容是放在 post 的 data 中的,这些参数,除了 salt 和 sign 要么就是不会变化,要么就是一眼能看出来意义的:那么这个 salt 和 sign 是什么呢?salt 根据 ta 数据的特征,我们应该会想到,这应该是一个时间戳,而 sign 又是什么呢?我们一起来看一下 找到这
-
Python调用微信公众平台接口操作示例
本文实例讲述了Python调用微信公众平台接口操作.分享给大家供大家参考,具体如下: 这里使用的是Django,其他类似 # coding=utf-8 from django.http import HttpResponse import hashlib, time, re from xml.etree import ElementTree as ET def weixin(request): token = "your token here" params = request.GET
-
python 简单的调用有道翻译
代码 import json import requests # 翻译函数,word 需要翻译的内容 def translate(word): # 有道词典 api url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null' # 传输的参数,其中 i 为需要翻译的内容 key = { 'type': "AUTO&qu
-
python 调用Google翻译接口的方法
一.网页分析 打开谷歌翻译链接:https://translate.google.com/ 按F12,点击network.在左侧输入"who are you" 可以看到,请求的链接为: https://translate.google.com/_/TranslateWebserverUi/data/batchexecute?rpcids=MkEWBc&f.sid=-2609060161424095358&bl=boq_translate-webserver_202012
-
python调用有道智云API实现文件批量翻译
最近工作过程中,需要对一批文件进行汉译英的翻译,对单个文档手工复制.粘贴的翻译方式过于繁琐,考虑到工作的重复性和本人追求提高效率.少动手(懒),想通过调用已有的接口的方法,自己实现一个批量翻译工具,一劳永逸.在网上找了几款翻译API,通过对比翻译的结果和学习成本,选择了有道智云的服务,自己开发了一个批量翻译的小软件.详细记录一下使用和开发过程,后面的小伙伴们有相关需求,可以参考. 批量文档翻译工具的使用 我这里开发批量文档翻译工具使用python作为开发工具,功能如下: 1)通过文件夹
-
python 实现有道翻译功能
初期操作 打开有道翻译界面-F12-Network-在翻译框中输入'hello'-在Network下面发现名为'translate_o?smartresult......'返回翻译之后的数据 分析参数 把所有的Request Headers.params都写上尝试爬虫,可以得到结果. 然后Request Headers中Headers.Host.Origin.Referer三项留下,Cookie一项经尝试只有 OUTFOX_SEARCH_USER_ID=-1927650476@223.97.