详解Java中KMP算法的图解与实现
目录
- 图解
- 代码实现
图解
kmp算法跟之前讲的bm算法思想有一定的相似性。之前提到过,bm算法中有个好后缀的概念,而在kmp中有个好前缀的概念,什么是好前缀,我们先来看下面这个例子。

观察上面这个例子,已经匹配的abcde称为好前缀,a与之后的bcde都不匹配,所以没有必要再比一次,直接滑动到e之后即可。
那如果好前缀中有互相匹配的字符呢?

观察上面这个例子,这个时候如果我们直接滑到好前缀之后,则会过度滑动,错失匹配子串。那我们如何根据好前缀来进行合理滑动?
其实就是看当前的好前缀的前缀和后缀是否有匹配的,找到最长匹配长度,直接滑动。鉴于不止一次找最长匹配长度,我们完全可以先初始化一个数组,保存在当前好前缀情况下,最长匹配长度是多少,这时候我们的next数组就出来了。
我们定义一个next数组,表示在当前好前缀下,好前缀的前缀和后缀的最长匹配子串长度,这个最长匹配长度表示这个子串之前已经匹配过匹配了,不需要再次进行匹配,直接从子串的下一个字符开始匹配。
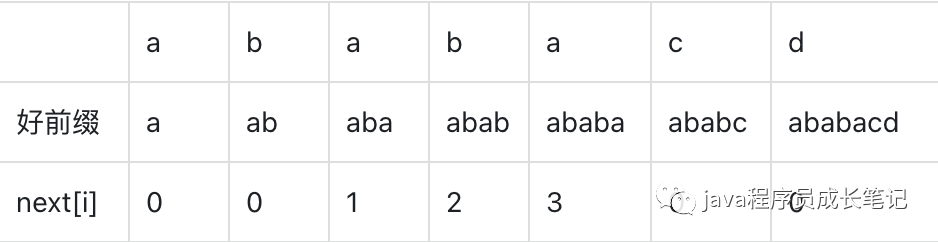
我们是否每次算next[i]时都需要每一个字符进行匹配,是否可以根据next[i - 1]进行推导以便减少不必要的比较。
带着这个思路我们来看看下面的步骤:
假设next[i - 1] = k - 1;
如果modelStr[k] = modelStr[i] 则next[i]=k

如果modelStr[k] != modelStr[i],我们是否可以直接认定next[i] = next[i - 1]?

通过上面这个例子,我们可以很清晰的看到,next[i]!=next[i-1],那当modelStr[k]!=modelStr[i]时候,我们已知next[0],next[1]…next[i-1],如何推倒出next[i]呢?
假设modelStr[x…i]是前缀后缀能匹配的最长后缀子串,那么最长匹配前缀子串为modelStr[0…i-x]

我们在求这个最长匹配串的时候,他的前面的次长匹配串(不包含当前i的),也就是modelStr[x…i-1]在之前应该是已经求解出来了的,因此我们只需要找到这个某一个已经求解的匹配串,假设前缀子串为modelStr[0…i-x-1],后缀子串为modelStr[x…i-1],且modelStr[i-x] == modelStr[i],这个前缀后缀子串即为次前缀子串,加上当前字符即为最长匹配前缀后缀子串。
代码实现
首先在kmp算法中最主要的next数组,这个数组标志着截止到当前下标的最长前缀后缀匹配子串字符个数,kmp算法里面,如果某个前缀是好前缀,即与模式串前缀匹配,我们就可以利用一定的技巧不止向前滑动一个字符,具体看前面的讲解。我们提前不知道哪些是好前缀,并且匹配过程不止一次,因此我们在最开始调用一个初始化方法,初始化next数组。
1.如果上一个字符的最长前缀子串的下一个字符==当前字符,上一个字符的最长前缀子串直接加上当前字符即可
2.如果不等于,需要找到之前存在的最长前缀子串的下一个字符等于当前子串的,然后设置当前字符子串的最长前缀后缀子串
int[] next ;
/**
* 初始化next数组
* @param modelStr
*/
public void init(char[] modelStr) {
//首先计算next数组
//遍历modelStr,遍历到的字符与之前字符组成一个串
next = new int[modelStr.length];
int start = 0;
while (start < modelStr.length) {
next[start] = this.recursion(start, modelStr);
++ start;
}
}
/**
*
* @param i 当前遍历到的字符
* @return
*/
private int recursion(int i, char[] modelStr) {
//next记录的是个数,不是下标
if (0 == i) {
return 0;
}
int last = next[i -1];
//没有匹配的,直接判断第一个是否匹配
if (0 == last) {
if (modelStr[last] == modelStr[i]) {
return 1;
}
return 0;
}
//如果last不为0,有值,可以作为最长匹配的前缀
if (modelStr[last] == modelStr[i]) {
return next[i - 1] + 1;
}
//当next[i-1]对应的子串的下一个值与modelStr不匹配时,需要找到当前要找的最长匹配子串的次长子串
//依据就是次长子串对应的子串的下一个字符==modelStr[i];
int tempIndex = i;
while (tempIndex > 0) {
last = next[tempIndex - 1];
//找到第一个下一个字符是当前字符的匹配子串
if (modelStr[last] == modelStr[i]) {
return last + 1;
}
-- tempIndex;
}
return 0;
}
然后开始利用next数组进行匹配,从第一个字符开始匹配进行匹配,找到第一个不匹配的字符,这时候之前的都是匹配的,接下来先判断是否已经是完全匹配,是直接返回,不是,判断是否第一个就不匹配,是直接往后面匹配。如果有好前缀,这时候就利用到了next数组,通过next数组知道当前可以从哪个开始匹配,之前的都不用进行匹配。
public int kmp(char[] mainStr, char[] modelStr) {
//开始进行匹配
int i = 0, j = 0;
while (i + modelStr.length <= mainStr.length) {
while (j < modelStr.length) {
//找到第一个不匹配的位置
if (modelStr[j] != mainStr[i]) {
break;
}
++ i;
++ j;
}
if (j == modelStr.length) {
//证明完全匹配
return i - j;
}
//走到这里找到的是第一个不匹配的位置
if (j == 0) {
++ i;
continue;
}
//从好前缀后一个匹配
j = next[j - 1];
}
return -1;
}
到此这篇关于详解Java中KMP算法的图解与实现的文章就介绍到这了,更多相关Java KMP算法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
如何通过Java代码实现KMP算法
这篇文章主要介绍了如何通过Java代码实现KMP算法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此人们称它为克努特--莫里斯--普拉特操作(简称KMP算法).KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的.具体实现就是实现一个next()函数, 函数本身包含了模式串的局部匹配信息.时间复
-

Java数据结构彻底理解关于KMP算法
大家好,前面的有一篇文章讲了子序列和全排列问题,今天我们再来看一个比较有难度的问题.那就是大名鼎鼎的KMP算法. 本期文章源码:GitHub源码 简介 KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特-莫里斯-普拉特操作(简称KMP算法).KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的.具体实现就是通过一个next()函数实现,函数本身包含了模式串的局部匹配信息.KMP算法
-
Java 数据结构与算法系列精讲之KMP算法
概述 从今天开始, 小白我将带大家开启 Java 数据结构 & 算法的新篇章. KMP 算法 KMP (Knuth-Morris-Pratt), 是一种改进的字符串匹配算法. KMP 算法解决了暴力匹配需要高频回退的问题, KMP 算法在匹配上若干字符后, 字符串位置不需要回退, 从而大大提高效率. 如图: 举个例子 (字符串 "abcabcdef" 匹配字符串 "abcdef"): 次数 暴力匹配 KMP 算法 说明 1 abcabcdef abcdef
-
java暴力匹配及KMP算法解决字符串匹配问题示例详解
目录 要解决的问题? 一.暴力匹配算法 一个图例介绍KMP算法 二.KMP算法 算法介绍 一个图例介绍KMP算法 代码实现 要解决的问题? 一.暴力匹配算法 一个图例介绍KMP算法 String str1 = "BBC ABCDAB ABCDABCDABDE"; String str2 = "ABCDABD"; 1. S[0]为B,P[0]为A,不匹配,执行第②条指令:"如果失配(即S[i]! = P[j]),令i = i - (j - 1),
-
JAVA实现KMP算法理论和示例代码
一.理论准备KMP算法为什么比传统的字符串匹配算法快?KMP算法是通过分析模式串,预先计算每个位置发生不匹配的时候,可以省去重新匹配的的字符个数.整理出来发到一个next数组, 然后进行比较,这样可以避免字串的回溯,模式串中部分结果还可以复用,减少了循环次数,提高匹配效率.通俗的说就是KMP算法主要利用模式串某些字符与模式串开头位置的字符一样避免这些位置的重复比较的.例如 主串: abcabcabcabed ,模式串:abcabed.当比较到模式串'e'字符时不同的时候完全没有必要从模式串开始位
-
java 中模式匹配算法-KMP算法实例详解
java 中模式匹配算法-KMP算法实例详解 朴素模式匹配算法的最大问题就是太低效了.于是三位前辈发表了一种KMP算法,其中三个字母分别是这三个人名的首字母大写. 简单的说,KMP算法的对于主串的当前位置不回溯.也就是说,如果主串某次比较时,当前下标为i,i之前的字符和子串对应的字符匹配,那么不要再像朴素算法那样将主串的下标回溯,比如主串为"abcababcabcabcabcabc",子串为"abcabx".第一次匹配的时候,主串1,2,3,4,5字符都和子串相应的
-
java 实现KMP算法
KMP算法是一种神奇的字符串匹配算法,在对 超长字符串 进行模板匹配的时候比暴力匹配法的效率会高不少.接下来我们从思路入手理解KMP算法. 在对字符串进行匹配的时候我们最容易想到的就是一个个匹配,类似下面这种: 换成Java代码就是: public static boolean bfSearch(String pattern,String txt){ if (txt.length() < pattern.length()) return false; for (int i = 0; i < t
-
详解Java中KMP算法的图解与实现
目录 图解 代码实现 图解 kmp算法跟之前讲的bm算法思想有一定的相似性.之前提到过,bm算法中有个好后缀的概念,而在kmp中有个好前缀的概念,什么是好前缀,我们先来看下面这个例子. 观察上面这个例子,已经匹配的abcde称为好前缀,a与之后的bcde都不匹配,所以没有必要再比一次,直接滑动到e之后即可. 那如果好前缀中有互相匹配的字符呢? 观察上面这个例子,这个时候如果我们直接滑到好前缀之后,则会过度滑动,错失匹配子串.那我们如何根据好前缀来进行合理滑动? 其实就是看当前的好前缀的前缀和后缀
-
详解Java中AC自动机的原理与实现
目录 简介 工作过程 数据结构 初始化 构建字典树 构建失败指针 匹配 执行结果 简介 AC自动机是一个多模式匹配算法,在模式匹配领域被广泛应用,举一个经典的例子,违禁词查找并替换为***.AC自动机其实是Trie树和KMP 算法的结合,首先将多模式串建立一个Tire树,然后结合KMP算法前缀与后缀匹配可以减少不必要比较的思想达到高效找到字符串中出现的匹配串. 如果不知道什么是Tire树,可以先查看:详解Java中字典树(Trie树)的图解与实现 如果不知道KMP算法,可以先查看:详解Java中
-
详解Java中Dijkstra(迪杰斯特拉)算法的图解与实现
目录 简介 工作过程 总体思路 实现 小根堆 Dijsktra 测试 简介 Dijkstra(迪杰斯特拉)算法是典型的单源最短路径算法,用于计算一个节点到其他所有节点的最短路径.主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止.Dijkstra算法是很有代表性的最短路径算法,在很多专业课程中都作为基本内容有详细的介绍,如数据结构,图论,运筹学等等.注意该算法要求图中不存在负权边.对应问题:在无向图G=(V,E)中,假设每条边E(i)的长度W(i),求由顶点V0到各节点的最短路径. 工作过
-
详解Java中字典树(Trie树)的图解与实现
目录 简介 工作过程 数据结构 初始化 构建字典树 应用 匹配有效单词 关键词提示 总结 简介 Trie又称为前缀树或字典树,是一种有序树,它是一种专门用来处理串匹配的数据结构,用来解决一组字符中快速查找某个字符串的问题.Google搜索的关键字提示功能相信大家都不陌生,我们在输入框中进行搜索的时候,会下拉出一系列候选关键词. 上面这个关键词提示功能,底层最基本的原理就是我们今天说的数据结构:Trie树 我们先看看Tire树长什么样子,以单纯的单词匹配为例,首先它是一棵多叉树结构,根节点是一个空
-
详解Java中hashCode的作用
详解Java中hashCode的作用 以下是关于HashCode的官方文档定义: hashcode方法返回该对象的哈希码值.支持该方法是为哈希表提供一些优点,例如,java.util.Hashtable 提供的哈希表. hashCode 的常规协定是: 在 Java 应用程序执行期间,在同一对象上多次调用 hashCode 方法时,必须一致地返回相同的整数,前提是对象上 equals 比较中所用的信息没有被修改.从某一应用程序的一次执行到同一应用程序的另一次执行,该整数无需保持一致. 如果根据
-
详解Java中AbstractMap抽象类
jdk1.8.0_144 下载地址:http://www.jb51.net/softs/551512.html AbstractMap抽象类实现了一些简单且通用的方法,本身并不难.但在这个抽象类中有两个方法非常值得关注,keySet和values方法源码的实现可以说是教科书式的典范. 抽象类通常作为一种骨架实现,为各自子类实现公共的方法.上一篇我们讲解了Map接口,此篇对AbstractMap抽象类进行剖析研究. Java中Map类型的数据结构有相当多,AbstractMap作为它们的骨架实现实
-
详解小白之KMP算法及python实现
在看子串匹配问题的时候,书上的关于KMP的算法的介绍总是理解不了.看了一遍代码总是很快的忘掉,后来决定好好分解一下KMP算法,算是给自己加深印象. 在将KMP字串匹配问题的时候,我们先来回顾一下字串匹配的暴力解法: 假设字符串str为: "abcgbabcdh", 字串substr为: "abcd" 从第一个字符开始比较,显然两个字符串的第一个字符相等('a'=='a'),然后比较第二个字符也相等('b'=='b'),继续下去,我们发现第4个字符不相等了('g'!
-
详解JAVA中priorityqueue的具体使用
Java中PriorityQueue通过二叉小顶堆实现,可以用一棵完全二叉树表示.本文从Queue接口函数出发,结合生动的图解,深入浅出地分析PriorityQueue每个操作的具体过程和时间复杂度,将让读者建立对PriorityQueue建立清晰而深入的认识. 总体介绍 前面以JavaArrayDeque为例讲解了Stack和Queue,其实还有一种特殊的队列叫做PriorityQueue,即优先队列.优先队列的作用是能保证每次取出的元素都是队列中权值最小的(Java的优先队列每次取最小元素,
-
详解Java 中泛型的实现原理
泛型是 Java 开发中常用的技术,了解泛型的几种形式和实现泛型的基本原理,有助于写出更优质的代码.本文总结了 Java 泛型的三种形式以及泛型实现原理. 泛型 泛型的本质是对类型进行参数化,在代码逻辑不关注具体的数据类型时使用.例如:实现一个通用的排序算法,此时关注的是算法本身,而非排序的对象的类型. 泛型方法 如下定义了一个泛型方法, 声明了一个类型变量,它可以应用于参数,返回值,和方法内的代码逻辑. class GenericMethod{ public <T> T[] sort(T[]
-
详解Java中的hashcode
一.什么是hash Hash,一般翻译做散列.杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值.这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值.简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数. 这个说的有点官方,你就可以把它简单的理解为一个key,就像是map的key值一样,是不可重复的. 二.hash有什么用?,