python神经网络使用tensorflow构建长短时记忆LSTM
目录
- LSTM简介
- 1、RNN的梯度消失问题
- 2、LSTM的结构
- tensorflow中LSTM的相关函数
- tf.contrib.rnn.BasicLSTMCell
- tf.nn.dynamic_rnn
- 全部代码
LSTM简介
1、RNN的梯度消失问题
在过去的时间里我们学习了RNN循环神经网络,其结构示意图是这样的:
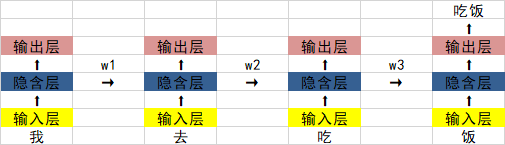
其存在的最大问题是,当w1、w2、w3这些值小于0时,如果一句话够长,那么其在神经网络进行反向传播与前向传播时,存在梯度消失的问题。
0.925=0.07,如果一句话有20到30个字,那么第一个字的隐含层输出传递到最后,将会变为原来的0.07倍,相比于最后一个字的影响,大大降低。
其具体情况是这样的:
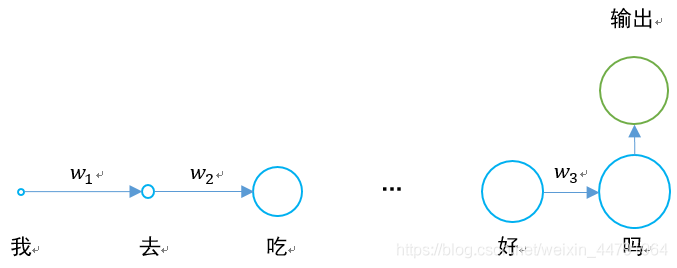
长短时记忆网络就是为了解决梯度消失的问题出现的。
2、LSTM的结构
原始RNN的隐藏层只有一个状态h,从头传递到尾,它对于短期的输入非常敏感。
如果我们再增加一个状态c,让它来保存长期的状态,问题就可以解决了。
对于RNN和LSTM而言,其两个step单元的对比如下。
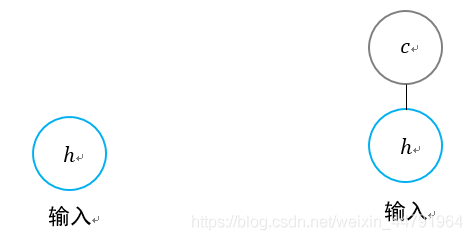
我们把LSTM的结构按照时间维度展开:
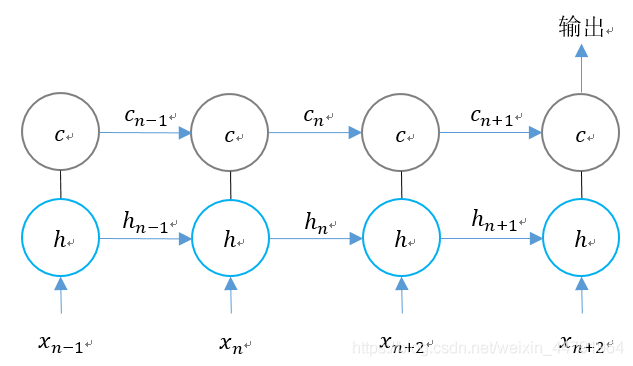
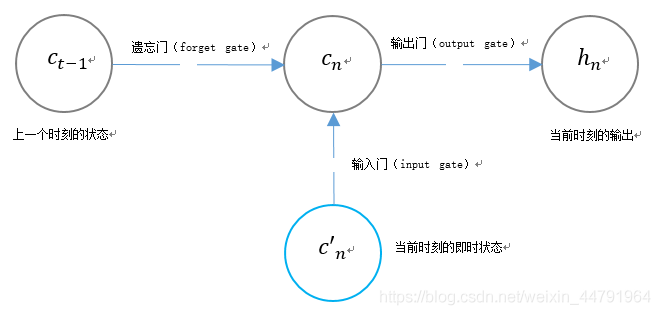
我们可以看出,在n时刻,LSTM的输入有三个:
1、当前时刻网络的输入值;
2、上一时刻LSTM的输出值;
3、上一时刻的单元状态。
LSTM的输出有两个:
1、当前时刻LSTM输出值;
2、当前时刻的单元状态。
3、LSTM独特的门结构
LSTM用两个门来控制单元状态cn的内容:
1、遗忘门(forget gate),它决定了上一时刻的单元状态cn-1有多少保留到当前时刻;
2、输入门(input gate),它决定了当前时刻网络的输入c’n有多少保存到单元状态。
LSTM用一个门来控制当前输出值hn的内容:
输出门(output gate),它决定了当前时刻单元状态cn有多少输出。
tensorflow中LSTM的相关函数
tf.contrib.rnn.BasicLSTMCell
tf.contrib.rnn.BasicLSTMCell(
num_units,
forget_bias=1.0,
state_is_tuple=True,
activation=None,
reuse=None,
name=None,
dtype=None
)
num_units:RNN单元中的神经元数量,即输出神经元数量。
forget_bias:偏置增加了忘记门。从CudnnLSTM训练的检查点(checkpoin)恢复时,必须手动设置为0.0。
state_is_tuple:如果为True,则接受和返回的状态是c_state和m_state的2-tuple;如果为False,则他们沿着列轴连接。False即将弃用。
activation:激活函数。
reuse:描述是否在现有范围中重用变量。如果不为True,并且现有范围已经具有给定变量,则会引发错误。
name:层的名称。
dtype:该层的数据类型。
在使用时,可以定义为:
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
在定义完成后,可以进行状态初始化:
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
tf.nn.dynamic_rnn
tf.nn.dynamic_rnn(
cell,
inputs,
sequence_length=None,
initial_state=None,
dtype=None,
parallel_iterations=None,
swap_memory=False,
time_major=False,
scope=None
)
- cell:上文所定义的lstm_cell。
- inputs:RNN输入。如果time_major==false(默认),则必须是如下shape的tensor:[batch_size,max_time,…]或此类元素的嵌套元组。如果time_major==true,则必须是如下形状的tensor:[max_time,batch_size,…]或此类元素的嵌套元组。
- sequence_length:Int32/Int64矢量大小。用于在超过批处理元素的序列长度时复制通过状态和零输出。因此,它更多的是为了性能而不是正确性。
- initial_state:上文所定义的_init_state。
- dtype:数据类型。
- parallel_iterations:并行运行的迭代次数。那些不具有任何时间依赖性并且可以并行运行的操作将是。这个参数用时间来交换空间。值>>1使用更多的内存,但花费的时间更少,而较小的值使用更少的内存,但计算需要更长的时间。
- time_major:输入和输出tensor的形状格式。如果为真,这些张量的形状必须是[max_time,batch_size,depth]。如果为假,这些张量的形状必须是[batch_size,max_time,depth]。使用time_major=true会更有效率,因为它可以避免在RNN计算的开始和结束时进行换位。但是,大多数TensorFlow数据都是批处理主数据,因此默认情况下,此函数为False。
- scope:创建的子图的可变作用域;默认为“RNN”。
在LSTM的最后,需要用该函数得出结果。
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn( lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
返回的是一个元组 (outputs, state):
outputs:LSTM的最后一层的输出,是一个tensor。如果为time_major== False,则它的shape为[batch_size,max_time,cell.output_size]。如果为time_major== True,则它的shape为[max_time,batch_size,cell.output_size]。
states:states是一个tensor。state是最终的状态,也就是序列中最后一个cell输出的状态。一般情况下states的形状为 [batch_size, cell.output_size],但当输入的cell为BasicLSTMCell时,states的形状为[2,batch_size, cell.output_size ],其中2也对应着LSTM中的cell state和hidden state。
整个LSTM的定义过程为:
def add_input_layer(self,):
#X最开始的形状为(256 batch,28 steps,28 inputs)
#转化为(256 batch*28 steps,128 hidden)
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='to_2D')
#获取Ws和Bs
Ws_in = self._weight_variable([self.input_size, self.cell_size])
bs_in = self._bias_variable([self.cell_size])
#转化为(256 batch*28 steps,256 hidden)
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
# (batch * n_steps, cell_size) ==> (batch, n_steps, cell_size)
# (256*28,256)->(256,28,256)
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='to_3D')
def add_cell(self):
#神经元个数
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
#每一次传入的batch的大小
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
#不是主列
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
def add_output_layer(self):
#设置Ws,Bs
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size])
# shape = (batch,output_size)
# (256,10)
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(self.cell_final_state[-1], Ws_out) + bs_out
全部代码
该例子为手写体识别例子,将手写体的28行分别作为每一个step的输入,输入维度均为28列。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
mnist = input_data.read_data_sets("MNIST_data",one_hot = "true")
BATCH_SIZE = 256 # 每一个batch的数据数量
TIME_STEPS = 28 # 图像共28行,分为28个step进行传输
INPUT_SIZE = 28 # 图像共28列
OUTPUT_SIZE = 10 # 共10个输出
CELL_SIZE = 256 # RNN 的 hidden unit size,隐含层神经元的个数
LR = 1e-3 # learning rate,学习率
def get_batch(): #获取训练的batch
batch_xs,batch_ys = mnist.train.next_batch(BATCH_SIZE)
batch_xs = batch_xs.reshape([BATCH_SIZE,TIME_STEPS,INPUT_SIZE])
return [batch_xs,batch_ys]
class LSTMRNN(object): #构建LSTM的类
def __init__(self, n_steps, input_size, output_size, cell_size, batch_size):
self.n_steps = n_steps
self.input_size = input_size
self.output_size = output_size
self.cell_size = cell_size
self.batch_size = batch_size
#输入输出
with tf.name_scope('inputs'):
self.xs = tf.placeholder(tf.float32, [None, n_steps, input_size], name='xs')
self.ys = tf.placeholder(tf.float32, [None, output_size], name='ys')
#直接加层
with tf.variable_scope('in_hidden'):
self.add_input_layer()
#增加LSTM的cell
with tf.variable_scope('LSTM_cell'):
self.add_cell()
#直接加层
with tf.variable_scope('out_hidden'):
self.add_output_layer()
#计算损失值
with tf.name_scope('cost'):
self.compute_cost()
#训练
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(LR).minimize(self.cost)
#正确率计算
self.correct_pre = tf.equal(tf.argmax(self.ys,1),tf.argmax(self.pred,1))
self.accuracy = tf.reduce_mean(tf.cast(self.correct_pre,tf.float32))
def add_input_layer(self,):
#X最开始的形状为(256 batch,28 steps,28 inputs)
#转化为(256 batch*28 steps,128 hidden)
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='to_2D')
#获取Ws和Bs
Ws_in = self._weight_variable([self.input_size, self.cell_size])
bs_in = self._bias_variable([self.cell_size])
#转化为(256 batch*28 steps,256 hidden)
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
# (batch * n_steps, cell_size) ==> (batch, n_steps, cell_size)
# (256*28,256)->(256,28,256)
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='to_3D')
def add_cell(self):
#神经元个数
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
#每一次传入的batch的大小
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
#不是主列
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
def add_output_layer(self):
#设置Ws,Bs
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size])
# shape = (batch,output_size)
# (256,10)
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(self.cell_final_state[-1], Ws_out) + bs_out
def compute_cost(self):
self.cost = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits = self.pred,labels = self.ys)
)
def _weight_variable(self, shape, name='weights'):
initializer = np.random.normal(0.0,1.0 ,size=shape)
return tf.Variable(initializer, name=name,dtype = tf.float32)
def _bias_variable(self, shape, name='biases'):
initializer = np.ones(shape=shape)*0.1
return tf.Variable(initializer, name=name,dtype = tf.float32)
if __name__ == '__main__':
#搭建 LSTMRNN 模型
model = LSTMRNN(TIME_STEPS, INPUT_SIZE, OUTPUT_SIZE, CELL_SIZE, BATCH_SIZE)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
#训练10000次
for i in range(10000):
xs, ys = get_batch() #提取 batch data
if i == 0:
#初始化data
feed_dict = {
model.xs: xs,
model.ys: ys,
}
else:
feed_dict = {
model.xs: xs,
model.ys: ys,
model.cell_init_state: state #保持 state 的连续性
}
#训练
_, cost, state, pred = sess.run(
[model.train_op, model.cost, model.cell_final_state, model.pred],
feed_dict=feed_dict)
#打印精确度结果
if i % 20 == 0:
print(sess.run(model.accuracy,feed_dict = {
model.xs: xs,
model.ys: ys,
model.cell_init_state: state #保持 state 的连续性
}))
以上就是python神经网络使用tensorflow构建长短时记忆LSTM的详细内容,更多关于tensorflow长短时记忆网络LSTM的资料请关注我们其它相关文章!
相关推荐
-
Python通过TensorFlow卷积神经网络实现猫狗识别
这份数据集来源于Kaggle,数据集有12500只猫和12500只狗.在这里简单介绍下整体思路 处理数据 设计神经网络 进行训练测试 1. 数据处理 将图片数据处理为 tf 能够识别的数据格式,并将数据设计批次. 第一步get_files() 方法读取图片,然后根据图片名,添加猫狗 label,然后再将 image和label 放到 数组中,打乱顺序返回 将第一步处理好的图片 和label 数组 转化为 tensorflow 能够识别的格式,然后将图片裁剪和补充进行标准化处理,分批次返回. 新建
-
tensorflow之自定义神经网络层实例
如下所示: import tensorflow as tf tfe = tf.contrib.eager tf.enable_eager_execution() 大多数情况下,在为机器学习模型编写代码时,您希望在比单个操作和单个变量操作更高的抽象级别上操作. 1.关于图层的一些有用操作 许多机器学习模型可以表达为相对简单的图层的组合和堆叠,TensorFlow提供了一组许多常用图层,以及您从头开始或作为组合创建自己的应用程序特定图层的简单方法.TensorFlow在tf.keras包中包含完整的
-
TensorFlow keras卷积神经网络 添加L2正则化方式
我就废话不多说了,大家还是直接看代码吧! model = keras.models.Sequential([ #卷积层1 keras.layers.Conv2D(32,kernel_size=5,strides=1,padding="same",data_format="channels_last",activation=tf.nn.relu,kernel_regularizer=keras.regularizers.l2(0.01)), #池化层1 keras.l
-

TensorFlow卷积神经网络之使用训练好的模型识别猫狗图片
本文是Python通过TensorFlow卷积神经网络实现猫狗识别的姊妹篇,是加载上一篇训练好的模型,进行猫狗识别 本文逻辑: 我从网上下载了十几张猫和狗的图片,用于检验我们训练好的模型. 处理我们下载的图片 加载模型 将图片输入模型进行检验 代码如下: #coding=utf-8 import tensorflow as tf from PIL import Image import matplotlib.pyplot as plt import input_data import numpy
-
tensorflow2.0实现复杂神经网络(多输入多输出nn,Resnet)
常见的'融合'操作 复杂神经网络模型的实现离不开"融合"操作.常见融合操作如下: (1)求和,求差 # 求和 layers.Add(inputs) # 求差 layers.Subtract(inputs) inputs: 一个输入张量的列表(列表大小至少为 2),列表的shape必须一样才能进行求和(求差)操作. 例子: input1 = keras.layers.Input(shape=(16,)) x1 = keras.layers.Dense(8, activation='rel
-
python 使用Tensorflow训练BP神经网络实现鸢尾花分类
Hello,兄弟们,开始搞深度学习了,今天出第一篇博客,小白一枚,如果发现错误请及时指正,万分感谢. 使用软件 Python 3.8,Tensorflow2.0 问题描述 鸢尾花主要分为狗尾草鸢尾(0).杂色鸢尾(1).弗吉尼亚鸢尾(2). 人们发现通过计算鸢尾花的花萼长.花萼宽.花瓣长.花瓣宽可以将鸢尾花分类. 所以只要给出足够多的鸢尾花花萼.花瓣数据,以及对应种类,使用合适的神经网络训练,就可以实现鸢尾花分类. 搭建神经网络 输入数据是花萼长.花萼宽.花瓣长.花瓣宽,是n行四列的矩阵. 而输
-
python神经网络使用tensorflow构建长短时记忆LSTM
目录 LSTM简介 1.RNN的梯度消失问题 2.LSTM的结构 tensorflow中LSTM的相关函数 tf.contrib.rnn.BasicLSTMCell tf.nn.dynamic_rnn 全部代码 LSTM简介 1.RNN的梯度消失问题 在过去的时间里我们学习了RNN循环神经网络,其结构示意图是这样的: 其存在的最大问题是,当w1.w2.w3这些值小于0时,如果一句话够长,那么其在神经网络进行反向传播与前向传播时,存在梯度消失的问题. 0.925=0.07,如果一句话有20到30个
-
python神经网络使用Keras构建RNN训练
目录 Keras中构建RNN的重要函数 1.SimpleRNN 2.model.train_on_batch Keras中构建RNN的重要函数 1.SimpleRNN SimpleRNN用于在Keras中构建普通的简单RNN层,在使用前需要import. from keras.layers import SimpleRNN 在实际使用时,需要用到几个参数. model.add( SimpleRNN( batch_input_shape = (BATCH_SIZE,TIME_STEPS,INPUT
-
python神经网络使用tensorflow实现自编码Autoencoder
目录 学习前言 antoencoder简介 1.为什么要降维 2.antoencoder的原理 3.python中encode的实现 全部代码 学习前言 当你发现数据的维度太多怎么办!没关系,我们给它降维!当你发现不会降维怎么办!没关系,来这里看看怎么autoencode antoencoder简介 1.为什么要降维 随着社会的发展,可以利用人工智能解决的越来越多,人工智能所需要处理的问题也越来越复杂,作为神经网络的输入量,维度也越来越大,也就出现了当前所面临的“维度灾难”与“信息丰富.知识贫乏
-
python人工智能tensorflow构建循环神经网络RNN
目录 学习前言 RNN简介 tensorflow中RNN的相关函数 tf.nn.rnn_cell.BasicLSTMCell tf.nn.dynamic_rnn 全部代码 学习前言 在前一段时间已经完成了卷积神经网络的复习,现在要对循环神经网络的结构进行更深层次的明确. RNN简介 RNN 是当前发展非常火热的神经网络中的一种,它擅长对序列数据进行处理. 什么是序列数据呢?举个例子. 现在假设有四个字,“我” “去” “吃” “饭”.我们可以对它们进行任意的排列组合. “我去吃饭”,表示的就是我
-
python人工智能tensorflow构建卷积神经网络CNN
目录 简介 隐含层介绍 1.卷积层 2.池化层 3.全连接层 具体实现代码 卷积层.池化层与全连接层实现代码 全部代码 学习神经网络已经有一段时间,从普通的BP神经网络到LSTM长短期记忆网络都有一定的了解,但是从未系统的把整个神经网络的结构记录下来,我相信这些小记录可以帮助我更加深刻的理解神经网络. 简介 卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),
-
python神经网络TensorFlow简介常用基本操作教程
目录 要将深度学习更快且更便捷地应用于新的问题中,选择一款深度学习工具是必不可少的步骤. TensorFlow是谷歌于2015年11月9日正式开源的计算框架.TensorFlow计算框架可以很好地支持深度学习的各种算法. TensorFlow很好地兼容了学术研究和工业生产的不同需求. 一方面,TensorFlow的灵活性使得研究人员能够利用它快速实现新的模型设计: 另一方面,TensorFlow强大的分布式支持,对工业界在海量数据集上进行的模型训练也至关重要.作为谷歌开源的深度学习框架,Tens
-
tensorflow构建BP神经网络的方法
之前的一篇博客专门介绍了神经网络的搭建,是在python环境下基于numpy搭建的,之前的numpy版两层神经网络,不能支持增加神经网络的层数.最近看了一个介绍tensorflow的视频,介绍了关于tensorflow的构建神经网络的方法,特此记录. tensorflow的构建封装的更加完善,可以任意加入中间层,只要注意好维度即可,不过numpy版的神经网络代码经过适当地改动也可以做到这一点,这里最重要的思想就是层的模型的分离. import tensorflow as tf import nu
-
Python深度学习TensorFlow神经网络基础概括
目录 一.基础理论 1.TensorFlow 2.TensorFlow过程 1.构建图阶段 2.执行图阶段(会话) 二.TensorFlow实例(执行加法) 1.构造静态图 1-1.创建数据(张量) 1-2.创建操作(节点) 2.会话(执行) API: 普通执行 fetches(多参数执行) feed_dict(参数补充) 总代码 一.基础理论 1.TensorFlow tensor:张量(数据) flow:流动 Tensor-Flow:数据流 2.TensorFlow过程 TensorFlow
-
Python神经网络TensorFlow基于CNN卷积识别手写数字
目录 基础理论 一.训练CNN卷积神经网络 1.载入数据 2.改变数据维度 3.归一化 4.独热编码 5.搭建CNN卷积神经网络 5-1.第一层:第一个卷积层 5-2.第二层:第二个卷积层 5-3.扁平化 5-4.第三层:第一个全连接层 5-5.第四层:第二个全连接层(输出层) 6.编译 7.训练 8.保存模型 代码 二.识别自己的手写数字(图像) 1.载入数据 2.载入训练好的模型 3.载入自己写的数字图片并设置大小 4.转灰度图 5.转黑底白字.数据归一化 6.转四维数据 7.预测 8.显示
-
python神经网络Keras构建CNN网络训练
目录 Keras中构建CNN的重要函数 1.Conv2D 2.MaxPooling2D 3.Flatten 全部代码 利用Keras构建完普通BP神经网络后,还要会构建CNN Keras中构建CNN的重要函数 1.Conv2D Conv2D用于在CNN中构建卷积层,在使用它之前需要在库函数处import它. from keras.layers import Conv2D 在实际使用时,需要用到几个参数. Conv2D( nb_filter = 32, nb_row = 5, nb_col = 5