Keras搭建孪生神经网络Siamese network比较图片相似性
目录
- 什么是孪生神经网络
- 孪生神经网络的实现思路
- 一、预测部分
- 1、主干网络介绍
- 2、比较网络
- 二、训练部分
- 1、数据集的格式
- 2、Loss计算
- 训练自己的孪生神经网络
- 1、训练本文所使用的Omniglot例子
- 2、训练自己相似性比较的模型
什么是孪生神经网络
最近学习了一下如何比较两张图片的相似性,用到了孪生神经网络,一起来学习一下。
简单来说,孪生神经网络(Siamese network)就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的,如下图所示。

所谓权值共享就是当神经网络有两个输入的时候,这两个输入使用的神经网络的权值是共享的(可以理解为使用了同一个神经网络)。
很多时候,我们需要去评判两张图片的相似性,比如比较两张人脸的相似性,我们可以很自然的想到去提取这个图片的特征再进行比较,自然而然的,我们又可以想到利用神经网络进行特征提取。
如果使用两个神经网络分别对图片进行特征提取,提取到的特征很有可能不在一个域中,此时我们可以考虑使用一个神经网络进行特征提取再进行比较。
这个时候我们就可以理解孪生神经网络为什么要进行权值共享了。
孪生神经网络有两个输入(Input1 and Input2),利用神经网络将输入映射到新的空间,形成输入在新的空间中的表示。通过Loss的计算,评价两个输入的相似度。
代码下载
孪生神经网络的实现思路
一、预测部分
1、主干网络介绍
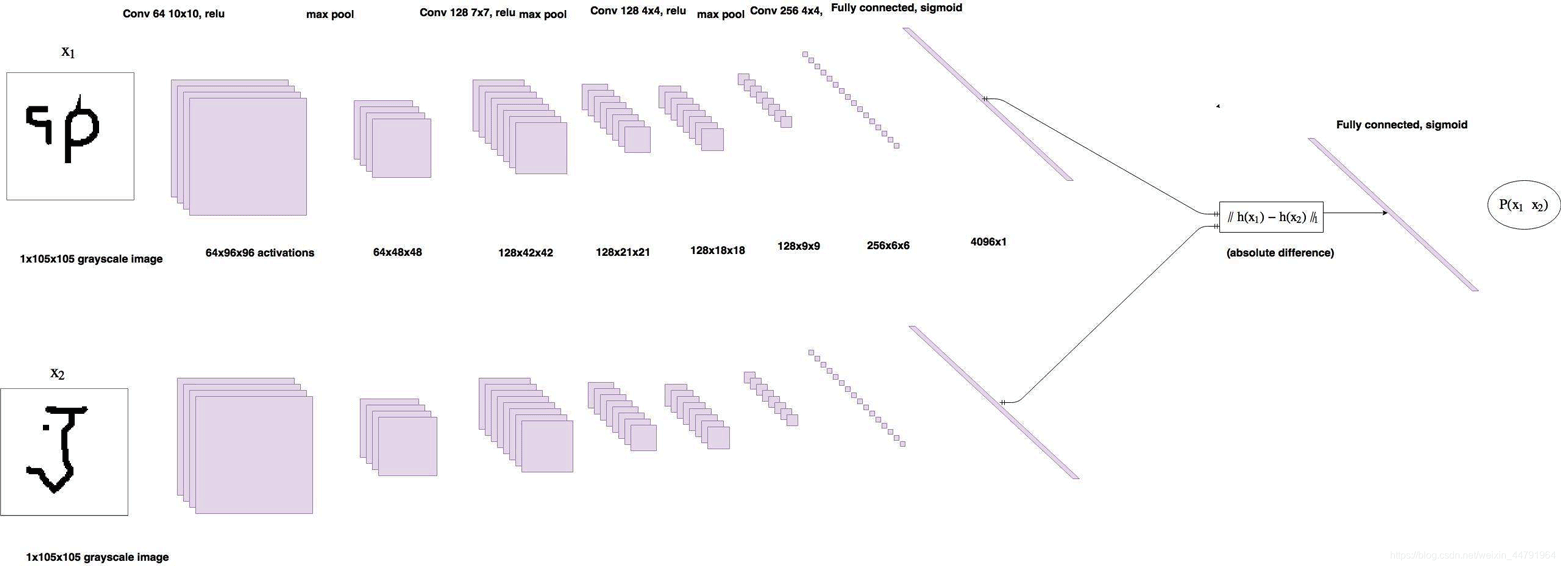
孪生神经网络的主干特征提取网络的功能是进行特征提取,各种神经网络都可以适用,本文使用的神经网络是VGG16。关于VGG的介绍大家可以看我的另外一篇博客
https://www.jb51.net/article/246968.htm

这是一个VGG被用到烂的图,但确实很好的反应了VGG的结构:
1、一张原始图片被resize到指定大小,本文使用105x105。
2、conv1包括两次[3,3]卷积网络,一次2X2最大池化,输出的特征层为64通道。
3、conv2包括两次[3,3]卷积网络,一次2X2最大池化,输出的特征层为128通道。
4、conv3包括三次[3,3]卷积网络,一次2X2最大池化,输出的特征层为256通道。
5、conv4包括三次[3,3]卷积网络,一次2X2最大池化,输出的特征层为512通道。
6、conv5包括三次[3,3]卷积网络,一次2X2最大池化,输出的特征层为512通道。
实现代码为:
import keras
from keras.layers import Input,Dense,Conv2D
from keras.layers import MaxPooling2D,Flatten
from keras.models import Model
import os
import numpy as np
from PIL import Image
from keras.optimizers import SGD
class VGG16:
def __init__(self):
self.block1_conv1 = Conv2D(64,(3,3),activation = 'relu',padding = 'same',name = 'block1_conv1')
self.block1_conv2 = Conv2D(64,(3,3),activation = 'relu',padding = 'same', name = 'block1_conv2')
self.block1_pool = MaxPooling2D((2,2), strides = (2,2), name = 'block1_pool')
self.block2_conv1 = Conv2D(128,(3,3),activation = 'relu',padding = 'same',name = 'block2_conv1')
self.block2_conv2 = Conv2D(128,(3,3),activation = 'relu',padding = 'same',name = 'block2_conv2')
self.block2_pool = MaxPooling2D((2,2),strides = (2,2),name = 'block2_pool')
self.block3_conv1 = Conv2D(256,(3,3),activation = 'relu',padding = 'same',name = 'block3_conv1')
self.block3_conv2 = Conv2D(256,(3,3),activation = 'relu',padding = 'same',name = 'block3_conv2')
self.block3_conv3 = Conv2D(256,(3,3),activation = 'relu',padding = 'same',name = 'block3_conv3')
self.block3_pool = MaxPooling2D((2,2),strides = (2,2),name = 'block3_pool')
self.block4_conv1 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block4_conv1')
self.block4_conv2 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block4_conv2')
self.block4_conv3 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block4_conv3')
self.block4_pool = MaxPooling2D((2,2),strides = (2,2),name = 'block4_pool')
# 第五个卷积部分
self.block5_conv1 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block5_conv1')
self.block5_conv2 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block5_conv2')
self.block5_conv3 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block5_conv3')
self.block5_pool = MaxPooling2D((2,2),strides = (2,2),name = 'block5_pool')
self.flatten = Flatten(name = 'flatten')
def call(self, inputs):
x = inputs
x = self.block1_conv1(x)
x = self.block1_conv2(x)
x = self.block1_pool(x)
x = self.block2_conv1(x)
x = self.block2_conv2(x)
x = self.block2_pool(x)
x = self.block3_conv1(x)
x = self.block3_conv2(x)
x = self.block3_conv3(x)
x = self.block3_pool(x)
x = self.block4_conv1(x)
x = self.block4_conv2(x)
x = self.block4_conv3(x)
x = self.block4_pool(x)
x = self.block5_conv1(x)
x = self.block5_conv2(x)
x = self.block5_conv3(x)
x = self.block5_pool(x)
outputs = self.flatten(x)
return outputs
2、比较网络
在获得主干特征提取网络之后,我们可以获取到一个多维特征,我们可以使用flatten的方式将其平铺到一维上,这个时候我们就可以获得两个输入的一维向量了
将这两个一维向量进行相减,再进行绝对值求和,相当于求取了两个特征向量插值的L1范数。也就相当于求取了两个一维向量的距离。
然后对这个距离再进行两次全连接,第二次全连接到一个神经元上,对这个神经元的结果取sigmoid,使其值在0-1之间,代表两个输入图片的相似程度。
实现代码如下:
import keras
from keras.layers import Input,Dense,Conv2D
from keras.layers import MaxPooling2D,Flatten,Lambda
from keras.models import Model
import keras.backend as K
import os
import numpy as np
from PIL import Image
from keras.optimizers import SGD
from nets.vgg import VGG16
def siamese(input_shape):
vgg_model = VGG16()
input_image_1 = Input(shape=input_shape)
input_image_2 = Input(shape=input_shape)
encoded_image_1 = vgg_model.call(input_image_1)
encoded_image_2 = vgg_model.call(input_image_2)
l1_distance_layer = Lambda(
lambda tensors: K.abs(tensors[0] - tensors[1]))
l1_distance = l1_distance_layer([encoded_image_1, encoded_image_2])
out = Dense(512,activation='relu')(l1_distance)
out = Dense(1,activation='sigmoid')(out)
model = Model([input_image_1,input_image_2],out)
return model
二、训练部分
1、数据集的格式
本文所使用的数据集为Omniglot数据集。
其包含来自 50不同字母(语言)的1623 个不同手写字符。
每一个字符都是由 20个不同的人通过亚马逊的 Mechanical Turk 在线绘制的。
相当于每一个字符有20张图片,然后存在1623个不同的手写字符,我们需要利用神经网络进行学习,去区分这1623个不同的手写字符,比较输入进来的字符的相似性。
本博客中数据存放格式有三级:
- image_background - Alphabet_of_the_Magi - character01 - 0709_01.png - 0709_02.png - …… - character02 - character03 - …… - Anglo-Saxon_Futhorc - ……
最后一级的文件夹用于分辨不同的字体,同一个文件夹里面的图片属于同一文字。在不同文件夹里面存放的图片属于不同文字。


上两个图为.\images_background\Alphabet_of_the_Magi\character01里的两幅图。它们两个属于同一个字。

上一个图为.\images_background\Alphabet_of_the_Magi\character02里的一幅图。它和上面另两幅图不属于同一个字。
2、Loss计算
对于孪生神经网络而言,其具有两个输入。
当两个输入指向同一个类型的图片时,此时标签为1。
当两个输入指向不同类型的图片时,此时标签为0。
然后将网络的输出结果和真实标签进行交叉熵运算,就可以作为最终的loss了。
本文所使用的Loss为binary_crossentropy。
当我们输入如下两个字体的时候,我们希望网络的输出为1。
我们会将预测结果和1求交叉熵。
当我们输入如下两个字体的时候,我们希望网络的输出为0。
我们会将预测结果和0求交叉熵。
训练自己的孪生神经网络
1、训练本文所使用的Omniglot例子

下载数据集,放在根目录下的dataset文件夹下。

运行train.py开始训练。

2、训练自己相似性比较的模型
如果大家想要训练自己的数据集,可以将数据集按照如下格式进行摆放。

每一个chapter里面放同类型的图片。
之后将train.py当中的train_own_data设置成True,即可开始训练。

以上就是Keras搭建孪生神经网络Siamese network比较图片相似性的详细内容,更多关于Keras孪生神经网络比较图片的资料请关注我们其它相关文章!
相关推荐
-
keras的siamese(孪生网络)实现案例
代码位于keras的官方样例,并做了微量修改和大量学习?. 最终效果: import keras import numpy as np import matplotlib.pyplot as plt import random from keras.callbacks import TensorBoard from keras.datasets import mnist from keras.models import Model from keras.layers import Input,
-
使用Keras画神经网络准确性图教程
1.在搭建网络开始时,会调用到 keras.models的Sequential()方法,返回一个model参数表示模型 2.model参数里面有个fit()方法,用于把训练集传进网络.fit()返回一个参数,该参数包含训练集和验证集的准确性acc和错误值loss,用这些数据画成图表即可. 如: history=model.fit(x_train, y_train, batch_size=32, epochs=5, validation_split=0.25) #获取数据 #########画图
-
使用keras实现孪生网络中的权值共享教程
首先声明,这里的权值共享指的不是CNN原理中的共享权值,而是如何在构建类似于Siamese Network这样的多分支网络,且分支结构相同时,如何使用keras使分支的权重共享. Functional API 为达到上述的目的,建议使用keras中的Functional API,当然Sequential 类型的模型也可以使用,本篇博客将主要以Functional API为例讲述. keras的多分支权值共享功能实现,官方文档介绍 上面是官方的链接,本篇博客也是基于上述官方文档,实现的此功能.(插
-
Python实现Keras搭建神经网络训练分类模型教程
我就废话不多说了,大家还是直接看代码吧~ 注释讲解版: # Classifier example import numpy as np # for reproducibility np.random.seed(1337) # from keras.datasets import mnist from keras.utils import np_utils from keras.models import Sequential from keras.layers import Dense, Act
-

Keras神经网络efficientnet模型搭建yolov3目标检测平台
目录 什么是EfficientNet模型 源码下载 EfficientNet模型的实现思路 1.EfficientNet模型的特点 2.EfficientNet网络的结构 EfficientNet的代码构建 1.模型代码的构建 2.Yolov3上的应用 什么是EfficientNet模型 2019年,谷歌新出EfficientNet,在其它网络的基础上,大幅度的缩小了参数的同时提高了预测准确度,简直太强了,我这样的强者也要跟着做下去 EfficientNet,网络如其名,这个网络非常的有效率,怎
-
Keras搭建孪生神经网络Siamese network比较图片相似性
目录 什么是孪生神经网络 孪生神经网络的实现思路 一.预测部分 1.主干网络介绍 2.比较网络 二.训练部分 1.数据集的格式 2.Loss计算 训练自己的孪生神经网络 1.训练本文所使用的Omniglot例子 2.训练自己相似性比较的模型 什么是孪生神经网络 最近学习了一下如何比较两张图片的相似性,用到了孪生神经网络,一起来学习一下. 简单来说,孪生神经网络(Siamese network)就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的,如下图所示. 所谓权值共享就是当神经网
-
python神经网络Keras搭建RFBnet目标检测平台
目录 什么是RFBnet目标检测算法 RFBnet实现思路 一.预测部分 1.主干网络介绍 2.从特征获取预测结果 3.预测结果的解码 4.在原图上进行绘制 二.训练部分 1.真实框的处理 2.利用处理完的真实框与对应图片的预测结果计算loss 训练自己的RFB模型 一.数据集的准备 二.数据集的处理 三.开始网络训练 四.训练结果预测 什么是RFBnet目标检测算法 RFBnet是SSD的一种加强版,主要是利用了膨胀卷积这一方法增大了感受野,相比于普通的ssd,RFBnet也是一种加强吧 RF
-
R语言基于Keras的MLP神经网络及环境搭建
目录 Intro 环境搭建 本机电脑配置 安装TensorFlow以及Keras 安装R以及Rstudio 基于R语言的深度学习MLP 在Rstudio中安装Tensorflow和Keras MNIST数据集的预处理 深度学习MLP模型 总结和学习笔记 Intro R语言是我使用的第一种计算机语言,也是目前的主流数据分析语言之一,常常被人与python相比较.在EDA,制图和机器学习方面R语言拥有很多的的package可供选择.但深度学习方面由于缺少学习库以及合适的框架而被python赶超.但K
-
Keras搭建自编码器操作
简介: 传统机器学习任务任务很大程度上依赖于好的特征工程,但是特征工程往往耗时耗力,在视频.语音和视频中提取到有效特征就更难了,工程师必须在这些领域有非常深入的理解,并且需要使用专业算法提取这些数据的特征.深度学习则可以解决人工难以提取有效特征的问题,大大缓解机器学习模型对特征工程的依赖. 深度学习在早期一度被认为是一种无监督的特征学习过程,模仿人脑对特征逐层抽象的过程.这其中两点很重要:一是无监督学习:二是逐层训练.例如在图像识别问题中,假定我们有许多汽车图片,要如何利用计算机进行识别任务呢?
-
Keras搭建Efficientdet目标检测平台的实现思路
学习前言 一起来看看Efficientdet的keras实现吧,顺便训练一下自己的数据. 什么是Efficientdet目标检测算法 最近,谷歌大脑 Mingxing Tan.Ruoming Pang 和 Quoc V. Le 提出新架构 EfficientDet,结合 EfficientNet(同样来自该团队)和新提出的 BiFPN,实现新的 SOTA 结果. 源码下载 https://github.com/bubbliiiing/efficientdet-keras 喜欢的可以点个star噢
-
Keras搭建分类网络平台VGG16 MobileNet ResNet50
目录 分类网络的常见形式 分类网络介绍 1.VGG16网络介绍 2.MobilenetV1网络介绍 3.ResNet50网络介绍 分类网络的训练 1.LOSS介绍 2.利用分类网络进行训练 才发现做了这么多的博客和视频,居然从来没有系统地做过分类网络,做一个科学的分类网络,对身体好. 源码下载 https://github.com/bubbliiiing/classification-keras 分类网络的常见形式 常见的分类网络都可以分为两部分,一部分是特征提取部分,另一部分是分类部分. 特征
-
Keras搭建Mask R-CNN实例分割平台实现源码
目录 什么是Mask R-CNN Mask R-CNN实现思路 一.预测部分 1.主干网络介绍 2.特征金字塔FPN的构建 3.获得Proposal建议框 4.Proposal建议框的解码 5.对Proposal建议框加以利用(Roi Align) 6.预测框的解码 7.mask语义分割信息的获取 二.训练部分 1.建议框网络的训练 2.Classiffier模型的训练 3.mask模型的训练 训练自己的Mask-RCNN模型 1.数据集准备 2.参数修改 3.模型训练 什么是Mask R-CN
-
Keras搭建M2Det目标检测平台示例
目录 什么是M2det目标检测算法 M2det实现思路 一.预测部分 1.主干网络介绍 2.FFM1特征初步融合 3.细化U型模块TUM 4.FFM2特征加强融合 5.注意力机制模块SFAM 6.从特征获取预测结果 7.预测结果的解码 8.在原图上进行绘制 二.训练部分 1.真实框的处理 2.利用处理完的真实框与对应图片的预测结果计算loss 训练自己的M2Det模型 一.数据集的准备 二.数据集的处理 三.开始网络训练 四.训练结果预测 什么是M2det目标检测算法 一起来看看M2det的ke