关于python time库整理汇总
目录
- 1.Time库的作用
- 2. Time库的使用
- 时间获取函数
- 时间格式化:将时间以合理的方式展示出来
- 以以字符串的形式构造一个时间
- 程序计时应用:测量起止动作所经历时间的过程
- 3.实例:文本进度条
- 实例1:每次进度换行:
- 实例2:每次进度不换行,只是不断地进行刷新:用后打印的字符覆盖之前的字符
- 拓展:文本进度条的不同设计函数:

1.Time库的作用
time库是Python中处理时间的标准库- 提供获取系统时间并格式化输出功能
- 提供系统级精确计时功能,用于程序性能分析
2. Time库的使用
先明确几个概念:
- 时间戳:格林威治时间1970年01月01日00分00秒(北京时间1970年01月01日08时00分00秒)起至现在的总秒数,是个数字。
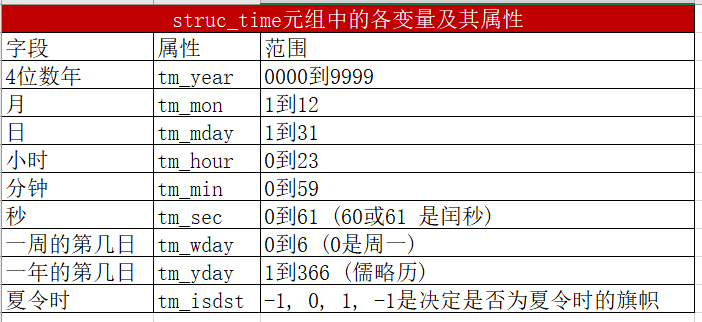
Python中获取时间的常用方法是,先得到时间戳,再将其转换成想要的时间格式。- 元组struct_time:日期、时间是包含许多变量的,所以在Python中定义了一个元组
struct_time将所有这些变量组合在一起,包括:年、月、日、小时、分钟、秒等。
时间获取函数


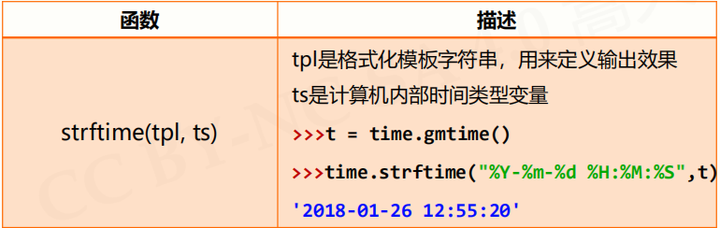
时间格式化:将时间以合理的方式展示出来
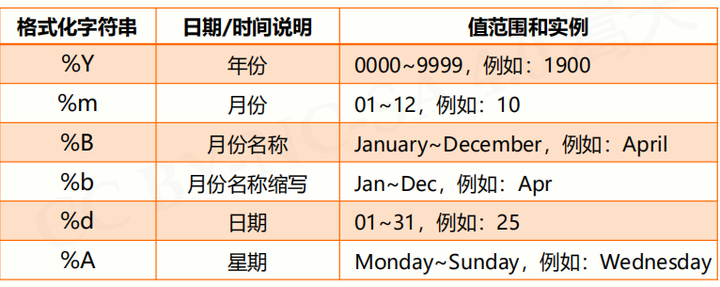
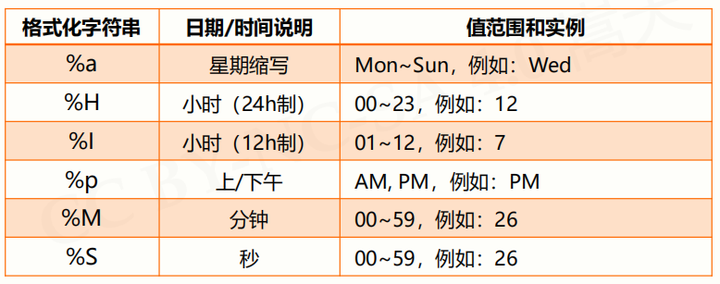
以以字符串的形式构造一个时间
问题:我们是否可以以字符串的形式构造一个时间,如”2018-01-26 12:55:20”,然后将其变成一个时间变量呢?
答案是可以的,通过展示模板定义的参数逐一解析字符串中对应的每一个值,它可能会形成一个时间变量。转化成一个计算机内部可以操作的一个时间。
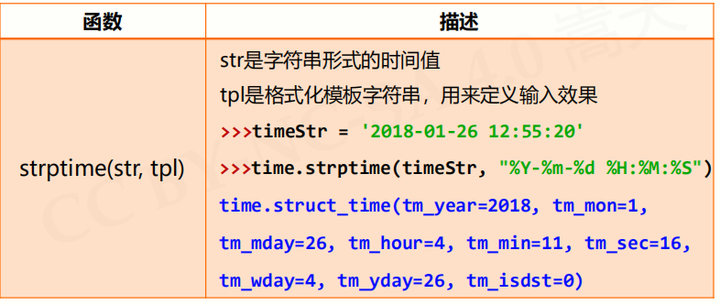
程序计时应用:测量起止动作所经历时间的过程
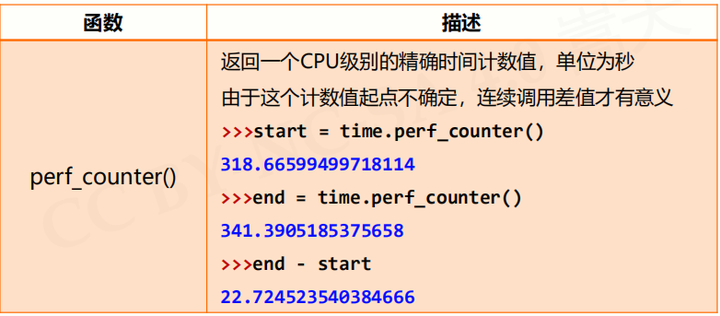

疑问:perf_counter()函数是用来做程序计时,但是time()函数不是也可以吗?
解答:
time()精度上相对没有那么高,而且受系统的影响,适合表示日期时间或者大程序程序的计时。
perf_counter()适合小一点的程序测试,会计算sleep()时间。
3.实例:文本进度条
实例1:每次进度换行:
print()函数默认输出一个字符后换到下一行,所以不用进行其他操作
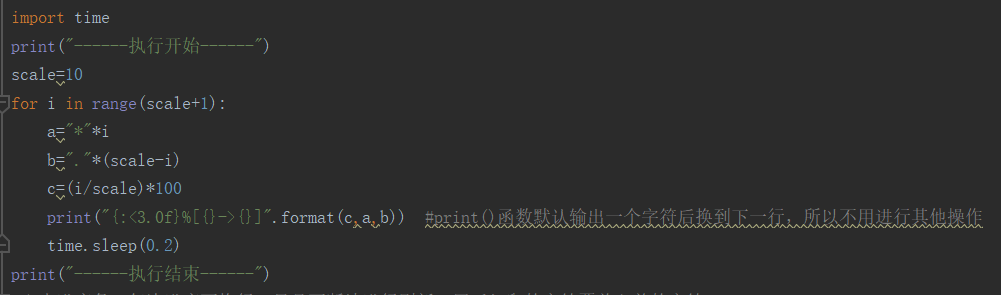
输出结果>>

实例2:每次进度不换行,只是不断地进行刷新:用后打印的字符覆盖之前的字符
- 为了实现单行动态刷新,就需要要求我们的程序在输出某一个字符的字符串的时候,不能够换行到下一行。因为换到下一行后,之前的信息不能够被修改
- 转义符 \r(光标移动到本行首)
- 有关转义符的使用当时困扰了我很久,比如应该放在哪个位置,所以单独放在了一个文档里专门介绍啦~~
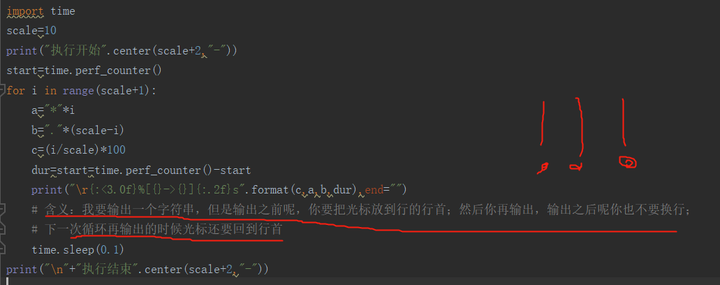
输出结果>>

拓展:文本进度条的不同设计函数:
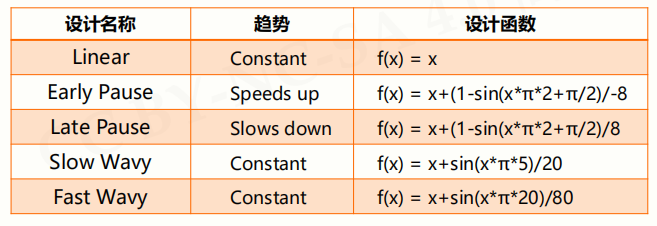
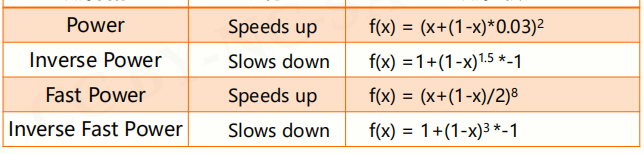
到此这篇关于关于python time库整理汇总的文章就介绍到这了,更多相关python time库整理内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!

相关推荐
-

Python time.time()方法
目录 描述 返回值 实例 备注 总结 描述 Python time time()返回当前时间的时间戳(1970纪元后经过的浮点秒数). 突然想看时间了,打开cmd发现脑中空荡,Java和Python的Time类全忘了,我留下了无助的眼泪o(╥﹏╥)o. 语法 time()方法语法: time.time() 返回值 返回当前时间的时间戳(1970纪元后经过的浮点秒数). 实例 以下实例展示了 time() 函数的使用方法: #!/usr/bin/python import time print "
-
python标准库之time模块的语法与简单使用
目录 表示时间的方式 1. 调用语法: 2. time概述 3. 时间获取 4. 时间格式化(将时间以合理的方式展示出来) 5. 程序计时应用 6. 示例 总结 表示时间的方式 时间戳表示法: 即以整型或浮点型表示的是一个以秒为单位的时间间隔.这个时间的基础值是从1970年的1月1号零点开始算起. 格式化的时间字符串: 即以格式化字符串的格式输出时间形式. 元组格式表示法: 即一种Python的数据结构表示.这个元组有9个整型内容(不能少),分别表示不同的时间含义. 索引(Index) 属性(A
-
一篇文章带你了解python标准库--datetime模块
目录 1. datetime模块介绍 1.1 datetime模块包含的类 1.2 datetime模块中包含的常量 2. datetime实例的方法 3. 日期格式化符号 总结 1. datetime模块介绍 1.1 datetime模块包含的类 1.2 datetime模块中包含的常量 2. datetime实例的方法 案例代码 import locale from datetime import datetime,date,time locale.setlocale(locale.LC_C
-
一篇文章带你了解python标准库--time模块
目录 1. 调用语法: 2. time概述 3. 时间获取 4. 时间格式化(将时间以合理的方式展示出来) 5. 程序计时应用 6. 示例 总结 Time库是python中处理时间的标准库 1. 调用语法: import time time.<b>() 计算机时间的表达,提供获取系统时间并格式化输出功能 提供提供系统精确即使功能,用于程序性能分析 2. time概述 time库包括三类函数 时间获取: time() ctime() gmtime() 时间格式化: strftime() strp
-
Python time库的时间时钟处理
前言 time库运行访问多种类型的时钟,这些时钟用于不同的场景.本篇,将详细讲解time库的应用知识. 获取各种时钟 既然time库提供了多种类型的时钟.下面我们直接来获取这些时钟,对比其具体的用途.具体代码如下: import time print(time.monotonic()) print(time.monotonic_ns()) print(time.perf_counter()) print(time.perf_counter_ns()) print(time.process_tim
-
python语言time库和datetime库基本使用详解
今天是边复习边创作博客的第三天,我今年大二,我们专业开的有这门课程,因为喜欢所以更加认真学习,本以为没人看呢,看了后台浏览量让我更加认真创作,这篇博客花了2个半小时的时间,结合自己所学,所思,所想写作,目的是为了方便喜欢Python的小白学习,也是一种自我鞭策吧! python语言使用内置time库和datetime库来处理日期时间 相关术语的解释 UTC time Coordinated Universal Time,世界协调时,又称 格林尼治天文时间.世界标准时间.与UTC time对应的是
-
浅谈Python3中datetime不同时区转换介绍与踩坑
最近的项目需要根据用户所属时区制定一些特定策略,学习.应用了若干python3的时区转换相关知识,这里整理一部分记录下来. 下面涉及的几个概念及知识点: GMT时间:Greenwich Mean Time, 格林尼治平均时间 UTC时间:Universal Time Coordinated 世界协调时,可以认为是更精准的GMT时间,但两者误差极小,在1s以内,一般可视为等同 LMT:Local Mean Time, 当地标准时间 Python中的北京时间:Python的标准timezone中信息
-
python常见模块之OS模块和time模块
一.OS模块概述 Python OS模块包含普遍的操作系统功能.如果你希望你的程序能够与平台无关的话,这个模块是尤为重要的. 二.常用方法 三.OS模块的练习 1. 在当前目录新建目录img, 里面包含多个文件, 文件名各不相同(X4G5.png) 2. 将当前img目录所有以.png结尾的后缀名改为.jpg def gen_code(len=4): # 随机生成4位验证码 li = random.sample(string.ascii_letters+string.digits,len) re
-
关于python time库整理汇总
目录 1.Time库的作用 2. Time库的使用 时间获取函数 时间格式化:将时间以合理的方式展示出来 以以字符串的形式构造一个时间 程序计时应用:测量起止动作所经历时间的过程 3.实例:文本进度条 实例1:每次进度换行: 实例2:每次进度不换行,只是不断地进行刷新:用后打印的字符覆盖之前的字符 拓展:文本进度条的不同设计函数: 1.Time库的作用 time库是Python中处理时间的标准库 提供获取系统时间并格式化输出功能 提供系统级精确计时功能,用于程序性能分析 2. Time库的使用
-
Python特殊方法整理汇总
运算符无关特殊方法 运算符相关特殊方法 到此这篇关于Python特殊方法整理汇总的文章就介绍到这了,更多相关Python特殊方法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
-
python机器学习库常用汇总
汇总整理一套Python网页爬虫,文本处理,科学计算,机器学习和数据挖掘的兵器谱. 1. Python网页爬虫工具集 一个真实的项目,一定是从获取数据开始的.无论文本处理,机器学习和数据挖掘,都需要数据,除了通过一些渠道购买或者下载的专业数据外,常常需要大家自己动手爬数据,这个时候,爬虫就显得格外重要了,幸好,Python提供了一批很不错的网页爬虫工具框架,既能爬取数据,也能获取和清洗数据,也就从这里开始了: 1.1 Scrapy 鼎鼎大名的Scrapy,相信不少同学都有耳闻,课程图谱中的很多课
-
python文件操作整理汇总
总是记不住API.昨晚写的时候用到了这些,但是没记住,于是就索性整理一下吧: python中对文件.文件夹(文件操作函数)的操作需要涉及到os模块和shutil模块. 得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd() 返回指定目录下的所有文件和目录名:os.listdir() 函数用来删除一个文件:os.remove() 删除多个目录:os.removedirs(r"c:\python") 检验给出的路径是否是一个文件:os.path.isfile()
-
Python 机器学习库 NumPy入门教程
NumPy是一个Python语言的软件包,它非常适合于科学计算.在我们使用Python语言进行机器学习编程的时候,这是一个非常常用的基础库. 本文是对它的一个入门教程. 介绍 NumPy是一个用于科技计算的基础软件包,它是Python语言实现的.它包含了: 强大的N维数组结构 精密复杂的函数 可集成到C/C++和Fortran代码的工具 线性代数,傅里叶变换以及随机数能力 除了科学计算的用途以外,NumPy也可被用作高效的通用数据的多维容器.由于它适用于任意类型的数据,这使得NumPy可以无缝和
-
超详细的Python安装第三方库常用方法汇总
目录 前言 安装方法 1. 通过pychram安装 2. pip安装大法 3. 下载whl文件到本地离线安装 3.1 补充 4.其他方法 4.1 Python官方的Pypi菜单 4.2 国内镜像源解决pip安装过慢的问题 小结 总结 前言 在pyhton的学习中,相信大家通常都会碰到第三方库的安装问题,这个问题对于很多初学者而言头疼不已.这里我做一些简单的总结,如何正确高效地安装第三方库,少走弯路(毕竟都是我亲自踩过的坑,所以特地来总结一下,方便以后回顾和总结)! 安装方法 1. 通过pychr
-
Python标准库itertools的使用方法
Python标准库itertools模块介绍 itertools是python内置的模块,使用简单且功能强大,这里尝试汇总整理下,并提供简单应用示例:如果还不能满足你的要求,欢迎加入补充. 使用Python标准库itertools只需简单一句导入:import itertools chain() 与其名称意义一样,给它一个列表如 lists/tuples/iterables,链接在一起:返回iterables对象. letters = ['a', 'b', 'c', 'd', 'e', 'f']
-
常用python爬虫库介绍与简要说明
这个列表包含与网页抓取和数据处理的Python库 python网络库 通用 urllib -网络库(stdlib). requests -网络库. grab – 网络库(基于pycurl). pycurl – 网络库(绑定libcurl). urllib3 – Python HTTP库,安全连接池.支持文件post.可用性高. httplib2 – 网络库. RoboBrowser – 一个简单的.极具Python风格的Python库,无需独立的浏览器即可浏览网页. MechanicalSoup
-
Python wxPython库消息对话框MessageDialog用法示例
本文实例讲述了Python wxPython库消息对话框MessageDialog用法.分享给大家供大家参考,具体如下: 消息对话框即我们平时说的Messagebox,看看它的原型,下面是wxWidgets中的原型定义,C++风格,与python风格的区别就是wx前缀与后面名称直接相连,例如wxMessageDialog,在wxpython中使用时就是wx.MessageDialog wxMessageDialog(wxWindow* parent, const wxString& messag
-
Python应用库大全总结
学Python,想必大家都是从爬虫开始的吧.毕竟网上类似的资源很丰富,开源项目也非常多. Python学习网络爬虫主要分3个大的版块:抓取,分析,存储 当我们在浏览器中输入一个url后回车,后台会发生什么? 简单来说这段过程发生了以下四个步骤: 查找域名对应的IP地址. 向IP对应的服务器发送请求. 服务器响应请求,发回网页内容. 浏览器解析网页内容. 网络爬虫要做的,简单来说,就是实现浏览器的功能.通过指定url,直接返回给用户所需要的数据,而不需要一步步人工去操纵浏览器获取. 抓取这一步,你