Python爬虫实战之虎牙视频爬取附源码
目录
- 知识点
- 开发环境
- 分析目标url
- 开始代码
- 最开始还是线导入所需模块
- 数据请求
- 获取视频标题以及url地址
- 获取视频id
- 保存数据
- 调用函数
- 运行代码,得到数据
知识点
- 爬虫基本流程
- re正则表达式简单使用
- requests
- json数据解析方法
- 视频数据保存
开发环境
- Python 3.8
- Pycharm
爬虫基本思路流程: (重点) [无论任何网站 任何数据内容 都是按照这个流程去分析]
1.确定需求 (爬取的内容是什么东西?)
- 都通过开发者工具进行抓包分析
- 分析视频播放url地址 是可以从哪里获取到
- 如果我们想要的数据内容 是 音频数据/视频数据 (media)
- 虽然说知道视频播放地址, 但是我们还需要知道这个播放地址 可以从什么地方获取
2.发送请求, 用python代码模拟浏览器对于目标地址发送请求
3.获取数据, 获取服务器给我们返回的数据内容
4.解析数据, 提取我们想要数据内容, 视频标题/视频url地址
5.保存数据
【付费VIP完整版】只要看了就能学会的教程,80集Python基础入门视频教学
分析目标url
先打开一个视频,查看id
打开开发者工具,查找

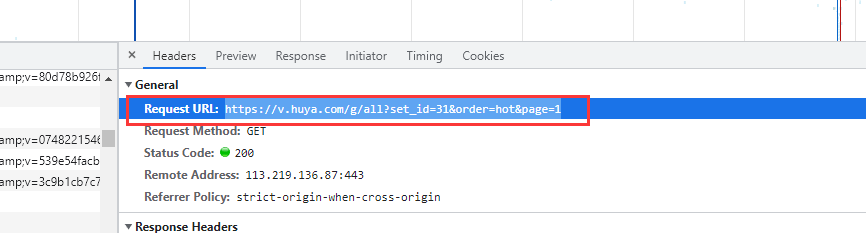
拿到目标url
开始代码
最开始还是线导入所需模块
import requests # 数据请求模块 pip install requests (第三方模块) import pprint # 格式化输出模块 内置模块 不需要安装 import re # 正则表达式 import json
数据请求
def get_response(html_url):
# 用python代码模拟浏览器
# headers 把python代码进行伪装
# user-agent 浏览器的基本标识
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
# 用代码直接获取的 一般大多数都是直接 cookie
response = requests.get(url=html_url, headers=headers)
return response
获取视频标题以及url地址
def get_video_info(video_id):
html_url = f'https://liveapi.huya.com/moment/getMomentContent?videoId={video_id}&uid=&_=1634127164373'
response = get_response(html_url)
title = response.json()['data']['moment']['title'] # 视频标题
video_url = response.json()['data']['moment']['videoInfo']['definitions'][0]['url']
video_info = [title, video_url]
return video_info
获取视频id
def get_video_id(html_url):
html_data = get_response(html_url).text
result = re.findall('<script> window.HNF_GLOBAL_INIT = (.*?) </script>', html_data)[0]
# 需要把获取的字符串数据, 转成json字典数据
json_data = json.loads(result)['videoData']['videoDataList']['value']
# json_data 列表 里面元素是字典
# print(json_data)
video_ids = [i['vid'] for i in json_data] # 列表推导式
# lis = []
# for i in json_data:
# lis.append(i['vid'])
# print(video_ids)
# print(type(json_data))
return video_ids
# 目光所至 我皆可爬
def main(html):
video_ids = get_video_id(html_url=html)
for video_id in video_ids:
video_info = get_video_info(video_id)
save(video_info[0], video_info[1])
保存数据
def save(title, video_url):
# 保存数据, 也是还需要对于播放地址发送请求的
# response.content 获取响应的二进制数据
video_content = get_response(html_url=video_url).content
new_title = re.sub(r'[\/:*?"<>|]', '_', title)
# 'video\\' + title + '.mp4' 文件夹路径以及文件名字 mode 保存方式 wb二进制保存方式
with open('video\\' + new_title + '.mp4', mode='wb') as f:
f.write(video_content)
print('保存成功: ', title)
调用函数
if __name__ == '__main__':
# get_video_info('589462235')
video_info = get_video_info('589462235')
save(video_info[0], video_info[1])
for page in range(1, 6):
print(f'正在爬取第{page}页的数据内容')
# python基础入门课程 第一节课 讲解的知识点 字符串格式化方法
url = f'https://v.huya.com/g/all?set_id=31&order=hot&page={page}'
main(url)
运行代码,得到数据

到此这篇关于Python爬虫实战之虎牙视频爬取附源码的文章就介绍到这了,更多相关Python 爬取虎牙视频内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python爬虫看看虎牙女主播中谁最“顶”步骤详解
网页链接:https://www.huya.com/g/4079 这里的主要步骤其实还是和我们之前分析的一样,如下图所示: 这里再简单带大家看一下就行,重点是我们的第二部分. 既然网页结构我们已经分析完了,那么我还是选择用之前的xpath来爬取我们所需要的资源. # 获取所有的主播信息 def getDatas(html): datalist=[] parse=parsel.Selector(html) lis=parse.xpath('//li[@class="game-live-item&q
-
Python趣味编程实现手绘风视频示例
在正文开始之前,先看一下最初效果,下面是单张图片转换前后对比 图一 图二 图三 为了增加趣味性,后面将这段代码应用到一个视频中,加上一个背景音乐,新鲜的 "手绘风视频" 出炉 Python 手绘风视频制作! "手绘风"实现步骤 讲解之前,需要了解手绘图像的三个主要特点: 图片需为灰度图,是单通道的: 边缘部分线条较重涂抹为黑色,相同或相近像素值转换后趋于白色: 在光源效果的加持下,灰度变化可模拟人类视觉的远近效果 读取图片,转化为数组 因为后面要用到像素计算,为了方
-
Python+selenium 自动化快手短视频发布的实现过程
第一章:效果展示 ① 效果展示 ② 素材展示 一个为视频,另一个为像素大小不小于视频的封面. 第二章:实现过程 ① 调用已启用的浏览器 通过调用已启用的浏览器,可以实现直接跳过每次的登录过程. from selenium import webdriver options = webdriver.ChromeOptions() options.add_experimental_option("debuggerAddress", "127.0.0.1:5003") dr
-
Python selenium抓取虎牙短视频代码实例
今天闲着没事,用selenium抓取视频保存到本地,只爬取了第一页,只要小于等于5分钟的视频... 为什么不用requests,没有为什么,就因为有些网站正则和xpath都提取不出来想要的东西,要么就是接口出来的数据加密,要么就因为真正的视频url规律难找! selenium几行代码轻轻松松就搞定! 安装selenium库,设置无界面模式 代码如下: from selenium import webdriver from selenium.webdriver.chrome.options imp
-
Python爬虫小练习之爬取并分析腾讯视频m3u8格式
目录 普通爬虫正常流程: 环境介绍 分析网站 开始代码 导入模块 数据请求 提取数据 遍历 保存数据 运行代码 普通爬虫正常流程: 数据来源分析 发送请求 获取数据 解析数据 保存数据 环境介绍 python 3.8 pycharm 2021专业版 [付费VIP完整版]只要看了就能学会的教程,80集Python基础入门视频教学 点这里即可免费在线观看 分析网站 先打开开发者工具,然后搜索m3u8,会返回给你很多的ts的文件,像这种ts文件,就是视频的片段 我们可以复制url地址,在新的浏览页打开
-
Python爬虫实战之虎牙视频爬取附源码
目录 知识点 开发环境 分析目标url 开始代码 最开始还是线导入所需模块 数据请求 获取视频标题以及url地址 获取视频id 保存数据 调用函数 运行代码,得到数据 知识点 爬虫基本流程 re正则表达式简单使用 requests json数据解析方法 视频数据保存 开发环境 Python 3.8 Pycharm 爬虫基本思路流程: (重点) [无论任何网站 任何数据内容 都是按照这个流程去分析] 1.确定需求 (爬取的内容是什么东西?) 都通过开发者工具进行抓包分析 分析视频播放url地址 是
-
Python爬虫实战之使用Scrapy爬取豆瓣图片
使用Scrapy爬取豆瓣某影星的所有个人图片 以莫妮卡·贝鲁奇为例 1.首先我们在命令行进入到我们要创建的目录,输入 scrapy startproject banciyuan 创建scrapy项目 创建的项目结构如下 2.为了方便使用pycharm执行scrapy项目,新建main.py from scrapy import cmdline cmdline.execute("scrapy crawl banciyuan".split()) 再edit configuration 然后
-
Python爬虫实战之用selenium爬取某旅游网站
一.selenium实战 这里我们只会用到很少的selenium语法,我这里就不补充别的用法了,以实战为目的 二.打开艺龙网 可以直接点击这里进入:艺龙网 这里是主页 三.精确目标 我们的目标是,鹤壁市,所以我们应该先点击搜索框,然后把北京删掉,替换成鹤壁市,那么怎么通过selenium实现呢? 打开pycharm,新建一个叫做艺龙网的py文件,先导包: from selenium import webdriver import time # 导包 driver = webdriver.Chro
-
python爬虫 正则表达式使用技巧及爬取个人博客的实例讲解
这篇博客是自己<数据挖掘与分析>课程讲到正则表达式爬虫的相关内容,主要简单介绍Python正则表达式爬虫,同时讲述常见的正则表达式分析方法,最后通过实例爬取作者的个人博客网站.希望这篇基础文章对您有所帮助,如果文章中存在错误或不足之处,还请海涵.真的太忙了,太长时间没有写博客了,抱歉~ 一.正则表达式 正则表达式(Regular Expression,简称Regex或RE)又称为正规表示法或常规表示法,常常用来检索.替换那些符合某个模式的文本,它首先设定好了一些特殊的字及字符组合,通过组合的&
-
Python爬虫实现的根据分类爬取豆瓣电影信息功能示例
本文实例讲述了Python爬虫实现的根据分类爬取豆瓣电影信息功能.分享给大家供大家参考,具体如下: 代码的入口: if __name__ == '__main__': main() #! /usr/bin/python3 # -*- coding:utf-8 -*- # author:Sirius.Zhao import json from urllib.parse import quote from urllib.request import urlopen from urllib.reque
-
Python爬虫入门教程01之爬取豆瓣Top电影
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 基本开发环境 Python 3.6 Pycharm 相关模块的使用 requests parsel csv 安装Python并添加到环境变量,pip安装需要的相关模块即可. 爬虫基本思路 一.明确需求 爬取豆瓣Top250排行电影信息 电影名字 导演.主演 年份.国家.类型 评分.评价人数 电影简介 二.发送请求 Python中的大量开源的模块使得编码变的特别简单,我们写爬虫第一个要了解的模
-
python爬虫之利用Selenium+Requests爬取拉勾网
一.前言 利用selenium+requests访问页面爬取拉勾网招聘信息 二.分析url 观察页面可知,页面数据属于动态加载 所以现在我们通过抓包工具,获取数据包 观察其url和参数 url="https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false" 参数: city=%E5%8C%97%E4%BA%AC ==>城市 first=true ==>无用 pn=
-
python gui开发——制作抖音无水印视频下载工具(附源码)
hello,大家好啊,失踪人口回归了 [捂脸]!本次使用tkinter撰写一篇 抖音无水印视频下载,目的很纯粹,就是为了设置 微信状态视频.本篇博文中,我会写下我的代码撰写思路以及想写设计流程,代码放在了第四节,工具打包好放在了 蓝奏云,慢慢看,后面有链接. 一.准备工作 本次要用到以下依赖库:re json os random tkinter threading requests pillow 其中后两个需要安装后使用 二.预览 0.复制抖音分享短链接 1.启动 2.运行 3.结果 (小姐姐挺
-
python基于tkinter制作无损音乐下载工具(附源码)
继续写GUI,本次依然使用Tkinter设计一款图形界面,使用Tkinter做一款音乐下载软件,听起来听平常的,但是我这款软件能够下载 无损音乐下载软件,听起来不错吧,Let`s go! 一.准备工作 python Tkinter 二.预览 1.搜索 2.下载 3.结果 无损音乐就这样下载完了. 三.详细设计 这里仅展示我设计的整体思路. 四.源代码 4.1 Music_Search-v1.0.py from tkinter import * from tkinter import ttk fr
-
Python写一个简单上课点名系统(附源码)
目录 一.准备工作 1.Tkinter 2.PIL 二.预览 1.启动 2.开始点名-顺序点名 3.开始点名-随机点名 4.手动加载人名单 5.开始点名-顺序点名-Pyqt5版本 三.思路 1.整体实现思路 2.点名实现思路 四.源代码 五.总结 一.准备工作 1.Tkinter Tkinter 是 python 内置的 TK GUI 工具集.TK 是 Tcl 语言的原生 GUI 库.作为 python 的图形设计工具,它所使用的 Tcl 语言环境已经完全嵌入到了 python 解释器中. 我们