基于 Python实现云服务器的CDN域名远程鉴权配置
目录
- 实战场景
- 开启远程鉴权
- Python 端权限验证
- 验证逻辑
实战场景
在项目实战中,会碰到一种特定的运维场景,对CDN访问进行限制,一般手段是开启 referer 防盗链,开启 IP黑白名单,开启UA黑白名单,本篇博客为大家展示的是通过我们自己的服务器,然后实现远程鉴权,进行更加细致的权限判定。

实现目标:
- 请求CDN资源调用我们的鉴权服务器
- 鉴权服务器获取请求信息,并保存到日志中
- 分别返回鉴权成功,鉴权失败
开启远程鉴权
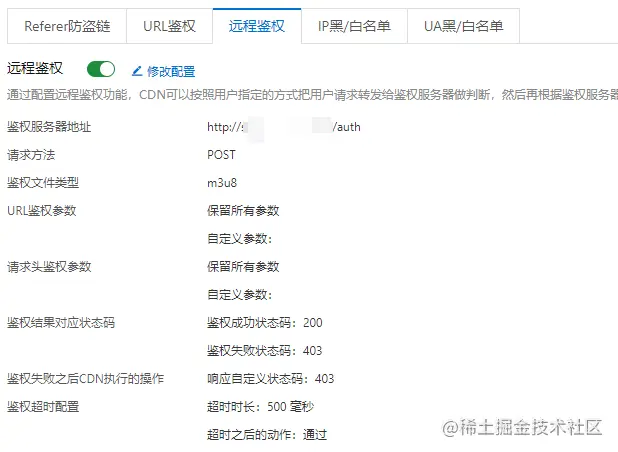
在远程鉴权页面打开【开关】之后,出现如下配置界面,这里相关细节描述如下:
鉴权服务器地址:我们自己的服务器,地址可访问,可以是域名也可以是IP地址;请求方法:支持 GET,POST,HEAD 三种请求;鉴权文件类型:多个文件类型用|分隔,例如mp4|flv;保留参数设置:控制用户请求 URL 中需要鉴权的参数,用|分隔;自定义参数:可以自定义参数,可以使用CDN控制台预设的变量,多个参数用|分隔,例如token=$arg_token|vendor=ali_cdn;保留请求头设置:控制用户请求头中需要鉴权的参数,可以保留所有参数,也可以保留指定参数;添加自定义参数:给请求头添加自定义参数;鉴权状态码:成功200,失败 403;鉴权超时时长:单位为毫秒,最长时长可以设置为3000;

参考上述说明配置完毕,得到如下界面,本案例中仅限制了 m3u8 类型的文件,后续我们根据实际情况进行修改。
开启该配置之后,再次访问静态资源,就会出现 403 Forbidden
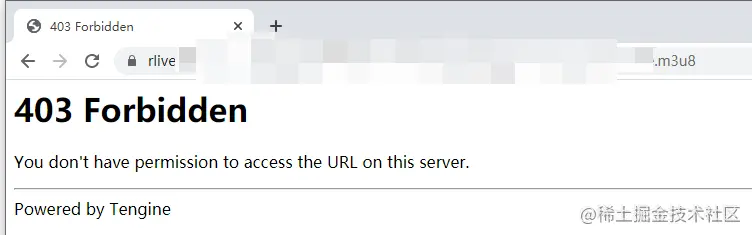
这里需要注意,由于测试的是 m3u8 文件,所以访问该文件的时候,如果没有被禁止,会自动下载。
Python 端权限验证
以下代码基于 Flask 编写,主要将POST请求数据和Header请求头保存到文件中。 日志文件,我们使用 logging 模块写入到 new.log 文件中。
# 导入Flask类
from flask import Flask
from flask import request
from flask import render_template
import logging
import requests
import time
import random
import base64
logging.basicConfig(level=logging.DEBUG,
filename='./new.log',
filemode='a',
format='%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s')
# 实例化,可视为固定格式
app = Flask(__name__)
@app.route('/auth', methods=['GET', 'POST','HEAD'])
def auth():
if request.method == 'GET':
args = request.args
return "hello"
if request.method == 'HEAD':
print("HEAD请求")
arges = request.form
print("参数")
logging.info(arges)
print(request)
print("请求头")
headers = request.headers
print(headers)
logging.info(headers)
print("请求数据")
logging.info(request.data)
return "login success", 200 # 403
if request.method == "POST":
print("POST请求")
arges = request.form
print(request)
headers = request.headers
print("参数")
logging.info(arges)
print("请求头")
logging.info(headers)
print("请求数据")
logging.info(request.data)
return "login success", 200 # 403
if __name__ == '__main__':
# app.run(host, port, debug, options)
# 默认值:host="127.0.0.1", port=5000, debug=False
app.run(host="0.0.0.0", port=5000)
此时,当你再次访问CDN资源时,会自动回调你的服务器进行鉴权操作,上述代码请求成功之后,返回状态码为 200,接下来CDN资源可以访问,如果返回403,表示被禁用。
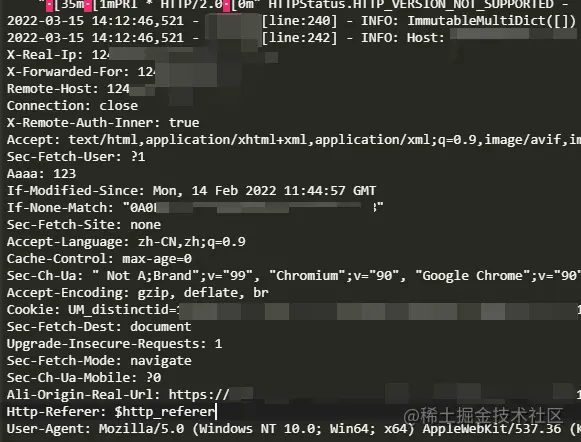
验证逻辑
服务端验证可以基于 referer + ua + ip 进行验证,为了保证效率,可以使用 redis 缓存数据库进行配置。
到此这篇关于基于 Python实现云服务器的CDN域名远程鉴权配置的文章就介绍到这了,更多相关CDN 鉴权配置内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
利用Python中的pandas库对cdn日志进行分析详解
前言 最近工作工作中遇到一个需求,是要根据CDN日志过滤一些数据,例如流量.状态码统计,TOP IP.URL.UA.Referer等.以前都是用 bash shell 实现的,但是当日志量较大,日志文件数G.行数达数千万亿级时,通过 shell 处理有些力不从心,处理时间过长.于是研究了下Python pandas这个数据处理库的使用.一千万行日志,处理完成在40s左右. 代码 #!/usr/bin/python # -*- coding: utf-8 -*- # sudo pip instal
-
EarthLiveSharp中cloudinary的CDN图片缓存自动清理python脚本
恰巧发现有个叫"EarthLiveSharp",可用将日本向日葵8号卫星的地球实时图片设为屏保.向日葵8号卫星的地球实时图片官网为:http://himawari8.nict.go.jp/,EarthLiveSharp的项目地址是:https://github.com/bitdust/EarthLiveSharp. 为了减轻向日葵8号的服务器负担,同时也是提高地球实时图片的获取成功率,需要使用cloudinary来做CDN.注册配置都在软件里有说明. 目前EarthLiveSharp暂
-

基于 Python实现云服务器的CDN域名远程鉴权配置
目录 实战场景 开启远程鉴权 Python 端权限验证 验证逻辑 实战场景 在项目实战中,会碰到一种特定的运维场景,对CDN访问进行限制,一般手段是开启 referer 防盗链,开启 IP黑白名单,开启UA黑白名单,本篇博客为大家展示的是通过我们自己的服务器,然后实现远程鉴权,进行更加细致的权限判定. 实现目标: 请求CDN资源调用我们的鉴权服务器 鉴权服务器获取请求信息,并保存到日志中 分别返回鉴权成功,鉴权失败 开启远程鉴权 在远程鉴权页面打开[开关]之后,出现如下配置界面,这里相关细节描述
-
基于腾讯云服务器部署微信小程序后台服务(Python+Django)
一 前言 微信小程序,相信大家早已熟知,它是一种无需下载安装即可使用的轻型应用,具有跨平台和接近 Native App 性能体验的优势.从开发模式上说,它是前后端分离的,微信小程序负责实现前端应用,后端服务可以使用任何你说熟知的开发语言,如 PHP . NodeJs . Java . C# . Python 等,因而,微信小程序的开发文档主要是围绕 WXML . WXSS 等前端框架.组件或样式布局进行讲解,几乎看不到后端技术的身影.本文主要介绍如何在腾讯云服务器上部署 Python+Djang
-
基于Python词云分析政府工作报告关键词
前言 十三届全国人大三次会议作了政府工作报告.这份政府工作报告仅有10500字左右,据悉是改革开放40年以来最短的一次.受到疫情影响,今年的两会会议适当缩短,政府工作报告也大幅压缩,体现了"实干为要"的理念.那么,这份政府工作报告突出强调了哪些关键词呢?我们其实可以基于Python技术进行词频分析和词云制作! import matplotlib.pyplot as plt#绘图库 import jieba from wordcloud import WordCloud # 读入文本数据
-
详解Python操作RabbitMQ服务器消息队列的远程结果返回
先说一下笔者这里的测试环境:Ubuntu14.04 + Python 2.7.4 RabbitMQ服务器 sudo apt-get install rabbitmq-server Python使用RabbitMQ需要Pika库 sudo pip install pika 远程结果返回 消息发送端发送消息出去后没有结果返回.如果只是单纯发送消息,当然没有问题了,但是在实际中,常常会需要接收端将收到的消息进行处理之后,返回给发送端. 处理方法描述:发送端在发送信息前,产生一个接收消息的临时队列,该队
-
SpringBoot项目部署到阿里云服务器的实现步骤
目录 一.申请阿里云服务器 二.Xshell 的安装使用 三.云服务器上jdk的安装 四.linux云服务器安装mysql 五.部署SpringBoot项目 SpringBoot项目部署到阿里云linux服务器全流程 文章里所有需要的软件.jdk.mysql.xshell等下载地址: Xshell 5 下载地址:https://www.jb51.net/softs/56322.html jdk下载地址:https://www.jb51.net/softs/698365.html tomcat下载
-
阿里云ECS云服务器(linux系统)安装mysql后远程连接不了(踩坑)
昨天买了一年的阿里云服务器,系统是linux Centos7的,满怀憧憬的装了个mysql,接下来的一天让我差点怀疑人生... 怎么装mysql就不多说了,反正我装了三遍,每次在阿里云上都能本地连接数据库 用navcat远程连阿里云的数据库死活连接不上.始终报:2003 - Can't connect to MySQL SERVER ON ********* (10060) 装了三次你就知道我有多绝望了,因为第一次linux下安装mysql,每次都认为可能是安装出了问题, 百度都被我翻烂了...
-
云服务器使用宝塔搭建Python环境,运行django程序
目录 安装宝塔 配置 Python 运行环境 安装 Python 配置 django 环境 安装模块 nginx 反向代理 本篇博客主要内容为 介绍 阿里云服务器(CentOS) 搭建 Django 程序. 在正式开始之前,你需要有一台服务器. 安装宝塔 宝塔官网:https://www.bt.cn/ 如果使用的是 CentOS 系统,使用下述命令安装即可. yum install -y wget && wget -O install.sh http://download.bt.cn/in
-
基于python实现cdn日志文件导入mysql进行分析
目录 一.本文需求背景 二.需求落地如下 三.自定义查询 一.本文需求背景 周六日出现CDN大量请求,现需要分析其请求频次与来源,查询是否存在被攻击问题. 本文以阿里云CDN日志作为辅助查询数据,其它云平台大同小异. 系统提供的离线日志如下所示: 二.需求落地如下 日志实例如下所示: [9/Jun/2015:01:58:09 +0800] 10.10.10.10 - 1542 "-" "GET http://www.aliyun.com/index.html" 20
-
在云服务器上基于docker安装jenkins的实现步骤
目录 基于docker安装jenkins 设置jenkins的反向代理 jenkins是老牌的CI/CD工具.下面记录一下在云服务器上的安装过程. 基于docker安装jenkins 下面记录了如何在云服务器上安装jenkins. 新建一个jenkins_docker文件夹,在文件夹里新建一个data文件夹.并给data文件夹读写权限. chmod -R a+w data/ 新建一个docker-compose.yml文件.添加下面的内容: version: "3.1" service
-
python+selenium定时爬取丁香园的新型冠状病毒数据并制作出类似的地图(部署到云服务器)
前言 硬要说这篇文章怎么来的,那得先从那几个吃野味的人开始说起-- 前天睡醒:假期还有几天:昨天睡醒:假期还有十几天:今天睡醒:假期还有一个月-- 每天过着几乎和每个假期一样的宅男生活,唯一不同的是玩手机已不再是看剧.看电影.打游戏了,而是每天都在关注着这次新冠肺炎疫情的新闻消息,真得希望这场战"疫"快点结束,让我们过上像以前一样的生活.武汉加油!中国加油!! 本次爬取的网站是丁香园点击跳转,相信大家平时都是看这个的吧. 一.准备 python3.7 selenium:自动化测试框架,