python数据挖掘Apriori算法实现关联分析
目录
- 摘要:
- 关联分析
- Apriori原理
- 算法实现
- 挖掘关联规则
- 利用Apriori算法解决实际问题
- 发现毒蘑菇的相似特征
- 总结:
摘要:
主要是讲解一些数据挖掘中频繁模式挖掘的Apriori算法原理应用实践
当我们买东西的时候,我们会发现物品展示方式是不同,购物以后优惠券以及用户忠诚度也是不同的,但是这些来源都是大量数据的分析,为了从顾客身上获得尽可能多的利润,所以需要用各种技术来达到目的。
通过查看哪些商品一起购物可以帮助商店了解客户的购买行为。这种从大规模数据集中寻找物品间的隐含关系被称为关联分析或者关联规则学习。寻找物品的不同组合用蛮力算法的话效率十分底下,所以需要用智能的方法在时间范围内寻找频繁项集。
关联分析
关联规则学习是在大规模数据集中寻找有趣关系的任务。这些关系可以有两种形式:频繁项集或者关联规则。频繁项是经常出线一起物品集合,而关联规则暗示两种物品之间存在很强的关系。
{葡萄酒,尿布,豆奶}就是频繁项集,而尿布->葡萄酒就是关联规则。
商家可以更好的理解顾客。
而频繁的定义是什么?就是支持度和可信度
支持度是:数据集中包含这个项的比例。{豆奶} 支持度4/5 {豆奶,尿布}支持度为3/5
可信度:是针对关联规则定义的。{尿布]->{葡萄酒} 为 支持度({A,B})/支持度({A})。根据这两种衡量方法,但是当物品成千上万的时候如何计算这种组合清单呢?
Apriori原理
比如四种商品,我们考虑商品的组合问题:
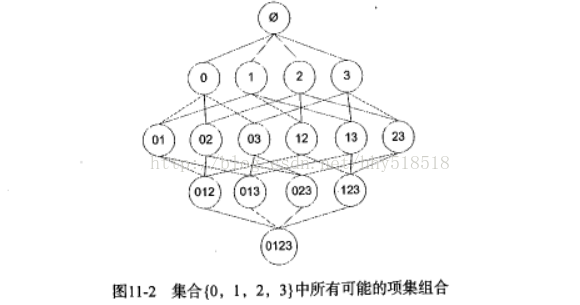
我们目标是寻找一起购买的商品集合。我们使用集合的支持度来度量出现的频率。随着物品数目的增加我们比如有N种商品那么就有2^N-1种项集的组合。为了降低计算时间,发现了一种Apriori原理。
Apriori原理:如果某个项集是频繁的,那么它所有的子集也是频繁的。
推论:如果一个项集是非频繁的,那么所i有超集也是非频繁的。
我们用图来表示就是:
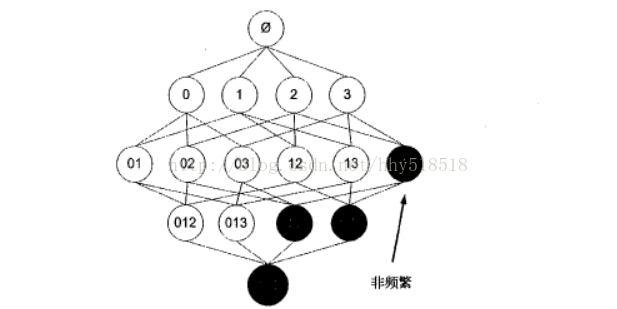
阴影{2,3}是非频繁的,那么{0,2,3},{1,2,3},{0,1,2,3}也是非频繁的。一旦计算出{2,3}的支持度,知道是非频繁的了。就不用计算{0,2,3],{1,2,3},{0,1,2,3}避免了指数增长。
算法实现
Apriori算法是发现频繁项集的一种方法,对于两个输出参数分别是最小支持度和数据集。首先生成所有单个物品的项目列表,然后查看那个项目集满足最小支持度。接下把不满足的去掉。将剩下的合并成为2个两素项集。重复继续去掉不满足最小支持度的项集。
对于数据集的每条交易记录tran
对于每个候选can:
- 检查can是否是tran子集
- 增加计数
对每个候选can:
- 如果支持度不小于最小保留
返回所有频繁项集
代码如下:
我们先实现两个函数。一个是最开始生成C1候选集的函数。另外一个是从候选集中选出满足支持度的频繁集
def createC1(dataset):
C1=[]
for transaction in dataset:
for item in transaction:
if not [item] in C1:#如果不在项集中
C1.append([item])
C1.sort()
#可以作为key值
return map(frozenset,C1)#每个元素是一个frozenset
#满足要求的构成L1,然后L1组合成为C2。进一步过滤成为L2
#frozenset可以作为key值
def scanD(D,Ck,minSupport):
#先在记录中查看所有候选集的次数
ssCnt = {}
for td in D:
for can in Ck:
if can.issubset(td):#如果是那个集合的子集
if not ssCnt.has_key(can):ssCnt[can]=1
else:ssCnt[can]+=1
numCount = len(D)#记录的总数
#记录每个项集的支持度
supportData={}
retList=[]
for key in ssCnt.iterkeys():
support = float(ssCnt[key]*1.0/numCount)
if support>=minSupport:
retList.insert(0,key)#加入满足条件的项集合的序列
supportData[key] = support
return retList,supportData
测试这两个函数如下:
x = apriori.loadDataSet() C1 = apriori.createC1(x)#frozenset每个元素 print C1 #构建事物集 D = map(set,x)#每个元素是集合 L1,supportData0 = apriori.scanD(D,C1,0.5) print L1
得到如下结果:
[frozenset([1]), frozenset([2]), frozenset([3]), frozenset([4]), frozenset([5])][frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])]
而整体算法如下:
当集合项个数大于0时候
- 构建一个K个项组成的候选列表
- 检查是否每个项集是频繁的
- 保留频繁的并且构建K+1项的候选项列表
#前面K-1x项目相同的时候可以生成Lk
def aprioriGen(Lk,k):
#前面k-1项目相同就可以合成
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i+1,lenLk):
L1 = list(Lk[i])[:k-2]#可以考虑1个元素的时候是0直接合并
L2 = list(Lk[j])[:k-2]
L1.sort()
L2.sort()
if L1==L2:
retList.append(Lk[i]|Lk[j])
return retList
def apriori(dataset,minSupport=0.5):
C1 = createC1(dataset)
D = map(set,dataset)
L1,supportData = scanD(D,C1,minSupport)
L = [L1]
k = 2#项集为2
#频繁n-1项目总数为
while(len(L[k-2])>0):#因为项集存的位置是0
Ck = aprioriGen(L[k-2],k)
Lk,supK = scanD(D,Ck,minSupport)
supportData.update(supK)#加入字典更新
L.append(Lk)#L+1
k+=1#当空集的时候退出
return L,supportData
测试如下:
dataSet = apriori.loadDataSet() L,supportData = apriori.apriori(dataSet,minSupport=0.7) print L
我们可以获得如下的频繁项集
[[frozenset([3]), frozenset([2]), frozenset([5])], [frozenset([2, 5])], []]
挖掘关联规则
要找到关联规则。首先需要从频繁项集开始。我们知道集合中元素是不重复的,但是我们想基于这些元素获得其他内容。某个元素或者某个元素的集合可以推导另外一个元素。
关联规则也可以想频繁项集一样量化。频繁项集是需要满足最小支持度的要求。
对于关联规则我们就可以用可信度来衡量。一条规则的可信度为P->H定义为support{P|h}/support(P)其实也就是P条件下H的概率满足最小可信度就是关联规则
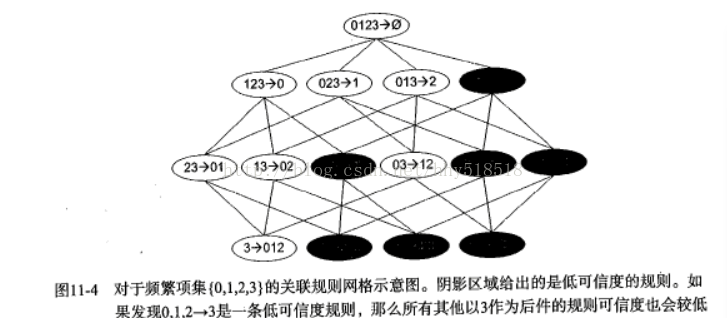
如果某条规则不满足最小可信度的要求。假设{0,1,2}->{3}不满足最小可信度的要求。
那么任何{0,1,2}的子集也不会满足最小可信度的要求。可以利用这个规则来 减少需要测试的规则数目。利用Apriori算法,进行首先从一个频繁项集合开始,创建一个规则列表。
规则右部包含一个元素,然后对这些规则测试。接下来合并所有剩余 规则来创建一个新的规则列表,其中规则的右部包含两个元素。这种方法称为分级法。
#规则生成函数
def generateRules(L,supportData,minConf=0.7):
bigRuleList=[]
for i in range(1,len(L)):#只获取两个或者更多的频繁项集合
for freqSet in L[i]:
H1 = [frozenset([item]) for item in freqSet]#将每个元素拆出来这个是右边被推出的项集
if (i>1):
rulesFromConseq()
else:
calcConf(freqSet,H1,supportData,bigRuleList,minConf)
return bigRuleList
#计算可信度
def calcConf(freqSet,H,supportData,brl,minConf=0.7):
prunedH = []
for conseq in H:
conf = supportData[freqSet]/supportData[freqSet-conseq]#获得条件概率(freq-conseq) -> conseq
if conf>=minConf:
print freqSet-conseq,'--->',conseq,'conf:',conf
brl.append((freqSet-conseq,conseq,conf))#加入这个元祖
prunedH.append(conseq)#为后面准备。因为若不满足规则右边该元素基础下添加也不会满足
return prunedH
#最初的规则生成更多的规则
def rulesFromConseq(freqSet,H,supportData,brl,minConf=0.7):
m = len(H[0])
if (len(freqSet)>(m+1)):#一直到该频繁项集能包含的右边推出等于项的个数-1为止例如{1,2,3,4}当{1}-{2,3,4}以后此时H[0]长度为3
Hmp1 = aprioriGen(H,m+1)#右边推出过程类似生成过程
Hmp1 = calcConf(freqSet,Hmp1,supportData,brl,minConf)#过滤过程返回被推出的右边的项集的集合
if (len(Hmp1)>1):#若有新规则生成继续递归处理
rulesFromConseq(freqSet,Hmp1,supportData,brl,minConf)
测试如下:
#生成所有频繁项集合 dataSet = apriori.loadDataSet() L,supportData = apriori.apriori(dataSet,minSupport=0.5) #生成规则 rules = apriori.generateRules(L,supportData,minConf=0.5)
calcConf中输出的结果如下:
frozenset([3]) ---> frozenset([1]) conf: 0.666666666667 frozenset([1]) ---> frozenset([3]) conf: 1.0 frozenset([5]) ---> frozenset([2]) conf: 1.0 frozenset([2]) ---> frozenset([5]) conf: 1.0 frozenset([3]) ---> frozenset([2]) conf: 0.666666666667 frozenset([2]) ---> frozenset([3]) conf: 0.666666666667 frozenset([5]) ---> frozenset([3]) conf: 0.666666666667 frozenset([3]) ---> frozenset([5]) conf: 0.666666666667 frozenset([5]) ---> frozenset([2, 3]) conf: 0.666666666667 frozenset([3]) ---> frozenset([2, 5]) conf: 0.666666666667 frozenset([2]) ---> frozenset([3, 5]) conf: 0.666666666667
利用Apriori算法解决实际问题
发现国会投票的模式
加州大学的机器学习数据集合有一个1984年起的国会投票记录的数据集: 这个数据集合比较老。可以尝试一些新的数据。其中一个组织是投票工程。提供了一个公共的API。
下面是如何收集数据的过程 而数据获取过程比较繁琐。以及键值对映射可以看《机器学习实战》这本书。
我们主要针对已经获取的txt文本来进行挖掘
构建投票记录的数据集:
我们希望最后的数据集合格式是每一行代表美国国会的一个成员,每一列是投票的对象。
from votesmart import votesmartvotesmart.apikey = 'a7fa40adec6f4a77178799fae4441030'#votesmart.apikey = 'get your api key first'
现在假设将议案的标题以及ID号保存为recent100bills.txt文件,可以通过getBill来获取每条议案的内容。
如果要获取每条议案的投票信息用getBillActionVotes() 上面都是该API提供的功能。我们主要是针对数据的预处理阶段。我们需要将BillId转换成actionID
#只保留包含投票数据的actionId
def getActionIds():
fr = open('recent20bills.txt')
actionIdList=[];billTitleList=[]
for line in fr.readlines():
billNum = int(line.split('\t')[0])
try:
billDetail = votesmart.votes.getBill(billNum)#获取议案对象
for action in billDetail.actions:
if action.level=='House' and \
(action.stage=='Passage' or \
action.stage=='Amendment Vote'):
actionId = int(action.actionId)
actionIdList.append(actionId)
billTitleList.append(line.strip().split('\t')[1])
except:
print "problem gettin bill %d"%billNum
sleep(1)
return actionIdList,billTitleList
我们获得的是类似Bill:12939 has actionId:34089这样的信息。我们需要频繁模式挖掘的话,需要将上面信息转换成项集或者交易数据库的东西。一条交易记录只有一个项出线还是没出现的信息,并不包含出现的次数。
美国有两个主要政党:共和和民主。我们可以将这个特征编码为0和1.然后对投票.
#基于投票数据的事物列表填充函数
def getTransList(actionIdList,billTitleList):
itemMeaning = ['Republican','Democratic']
for billTitle in billTitleList:
itemMeaning.append('%s -- Nay'%billTitle)
itemMeaning.append('%s -- Yea' % billTitle)
#创建事务字典
transDict = {}
voteCount = 2# 0,1是所属党派。2开始是被第几次投票
for actionId in actionIdList:
sleep(3)
print 'getting votes for actionId: %d' %actionId
try:
voteList = votesmart.votes.getBillActionVotes(actionId)
for vote in voteList:
if not transDict.has_key(vote.candidateName):
transDict[vote.candidateName] = []
if vote.officeParties =='Democratic':
transDict[vote.candidateName].append(1)
elif vote.officeParties=='Republican':
transDict[vote.candidateName].append(0)
if vote.action=='Nay':
transDict[vote.candidateName].append(voteCount)
elif vote.action=='Yea':
transDict[vote.candidateName].append(voteCount+1)
except:
print "problem getting actionId:%d" %actionId
voteCount+=2
return transDict,itemMeaning
其实就是获取的事物集。每一条事物集是[0/1,哪条具体规则]
就是将所有必要信息离散化编号然后统计整个投票过程
最后得到类似的结果:
Prohibiting Federal Funding of National Public Radio -- Yea
-------->
Republican
Repealing the Health Care Bill -- Yea
confidence: 0.995614
发现毒蘑菇的相似特征
有时候不是想要寻找所有的频繁项集合,只是队某个特征元素项集感兴趣。我们寻找毒蘑菇的公共特征,利用这些特征就能避免迟到有毒的蘑菇。
UCI数据集合重有蘑菇的23种特征的数据集,每一个特征是标称数据。而我们需要将样本转换成特征的集合,枚举每个特征所有可能的举止,如果某个样本 包含特征,那么特征对应的整数应该被包含在数据集中 1 3 9 13 23 25 34 36 38 40 52 54 59 63 67 76 85 86 90 93 98 107 113 每一个样本都是这样的特征集合。
如果第一个特征有毒就是2,如果能食用就是1,下一个特征是形状有6可能值,用整数3-8表示
相当于把需要的特征维度都进行排列离散化。最终只有1个大维特征
mushDatSet = [line.split() for line in open('mushroom.dat').readlines()]
L,suppData = apriori.apriori(mushDatSet,minSupport=0.3)
#寻找毒的公共特征
for item in L[1]:
if item.intersection('2'):print item
frozenset(['2', '59']) frozenset(['39', '2']) frozenset(['2', '67']) frozenset(['2', '34']) frozenset(['2', '23']) frozenset(['2', '86']) frozenset(['76', '2']) frozenset(['90', '2']) frozenset(['2', '53']) frozenset(['93', '2']) frozenset(['63', '2']) frozenset(['2', '28']) frozenset(['2', '85']) frozenset(['2', '36'])
那么可以给我们的提示就是如果有特征编号是这些的就不要吃这种蘑菇了
总结:
关联分析是发现大数据集合元素间关系的工具集。可以用在不同的物品上,主要是在样本处理上需要将样本转换成特征集合。也就是将所有维的特征统一编码。
以上就是python数据挖掘Apriori算法实现关联分析的详细内容,更多关于Apriori算法关联分析的资料请关注我们其它相关文章!
相关推荐
-
python使用Apriori算法进行关联性解析
从大规模数据集中寻找物品间的隐含关系被称作关联分析或关联规则学习.过程分为两步:1.提取频繁项集.2.从频繁项集中抽取出关联规则. 频繁项集是指经常出现在一块的物品的集合. 关联规则是暗示两种物品之间可能存在很强的关系. 一个项集的支持度被定义为数据集中包含该项集的记录所占的比例,用来表示项集的频繁程度.支持度定义在项集上. 可信度或置信度是针对一条诸如{尿布}->{葡萄酒}的关联规则来定义的.这条规则的可信度被定义为"支持度({尿布,葡萄酒})/支持度({尿布})". 寻找频繁
-

python中Apriori算法实现讲解
本文主要给大家讲解了Apriori算法的基础知识以及Apriori算法python中的实现过程,以下是所有内容: 1. Apriori算法简介 Apriori算法是挖掘布尔关联规则频繁项集的算法.Apriori算法利用频繁项集性质的先验知识,通过逐层搜索的迭代方法,即将K-项集用于探察(k+1)项集,来穷尽数据集中的所有频繁项集.先找到频繁项集1-项集集合L1, 然后用L1找到频繁2-项集集合L2,接着用L2找L3,知道找不到频繁K-项集,找到每个Lk需要一次数据库扫描.注意:频繁项集的所有非空
-
数据挖掘之Apriori算法详解和Python实现代码分享
关联规则挖掘(Association rule mining)是数据挖掘中最活跃的研究方法之一,可以用来发现事情之间的联系,最早是为了发现超市交易数据库中不同的商品之间的关系.(啤酒与尿布) 基本概念 1.支持度的定义:support(X-->Y) = |X交Y|/N=集合X与集合Y中的项在一条记录中同时出现的次数/数据记录的个数.例如:support({啤酒}-->{尿布}) = 啤酒和尿布同时出现的次数/数据记录数 = 3/5=60%. 2.自信度的定义:confidence(X-->
-
基于Python代码实现Apriori 关联规则算法
目录 一.关联规则概述 二.应用场景举例 1.股票涨跌预测 2.视频.音乐.图书等推荐 3.打车路线预测(考虑时空) 4.风控策略自动化挖掘 三.3个最重要的概念 1.支持度 2.置信度 3.提升度 4. 频繁项集 四.Python算法介绍 五.挖掘实例 一.关联规则概述 1993年,Agrawal等人在首先提出关联规则概念,迄今已经差不多30年了,在各种算法层出不穷的今天,这算得上是老古董了,比很多人的年纪还大,往往是数据挖掘的入门算法,但深入研究的不多,尤其在风控领域,有着极其重要的应用潜力
-
python 实现关联规则算法Apriori的示例
首先导入包含apriori算法的mlxtend库, pip install mlxtend 调用apriori进行关联规则分析,具体代码如下,其中数据集选取本博客 "机器学习算法--关联规则" 中的例子,可进行参考,设置最小支持度(min_support)为0.4,最小置信度(min_threshold)为0.1, 最小提升度(lift)为1.0,对数据集进行关联规则分析, from mlxtend.preprocessing import TransactionEncoder fro
-
python数据挖掘Apriori算法实现关联分析
目录 摘要: 关联分析 Apriori原理 算法实现 挖掘关联规则 利用Apriori算法解决实际问题 发现毒蘑菇的相似特征 总结: 摘要: 主要是讲解一些数据挖掘中频繁模式挖掘的Apriori算法原理应用实践 当我们买东西的时候,我们会发现物品展示方式是不同,购物以后优惠券以及用户忠诚度也是不同的,但是这些来源都是大量数据的分析,为了从顾客身上获得尽可能多的利润,所以需要用各种技术来达到目的. 通过查看哪些商品一起购物可以帮助商店了解客户的购买行为.这种从大规模数据集中寻找物品间的隐含关系被称
-
浅谈Python实现Apriori算法介绍
导读: 随着大数据概念的火热,啤酒与尿布的故事广为人知.我们如何发现买啤酒的人往往也会买尿布这一规律?数据挖掘中的用于挖掘频繁项集和关联规则的Apriori算法可以告诉我们.本文首先对Apriori算法进行简介,而后进一步介绍相关的基本概念,之后详细的介绍Apriori算法的具体策略和步骤,最后给出Python实现代码. 1.Apriori算法简介 Apriori算法是经典的挖掘频繁项集和关联规则的数据挖掘算法.A priori在拉丁语中指"来自以前".当定义问题时,通常会使用先验知识
-
python实现AHP算法的方法实例(层次分析法)
一.层次分析法原理 层次分析法(Analytic Hierarchy Process,AHP)由美国运筹学家托马斯·塞蒂(T. L. Saaty)于20世纪70年代中期提出,用于确定评价模型中各评价因子/准则的权重,进一步选择最优方案.该方法仍具有较强的主观性,判断/比较矩阵的构造在一定程度上是拍脑门决定的,一致性检验只是检验拍脑门有没有自相矛盾得太离谱. 相关的理论参考可见:wiki百科 二.代码实现 需要借助Python的numpy矩阵运算包,代码最后用了一个b1矩阵进行了调试,相关代码如下
-
python 数据挖掘算法的过程详解
目录 1.首先简述数据挖掘的过程 第一步:数据选择 第二步:数据预处理 第三步:特征值数据转换 第四步:模型训练 第五步:测试模型+效果评估 第六步:模型使用 第七步:解释与评价 2.主要的算法模型讲解——基于sklearn 3.sklearn自带方法joblib来进行保存训练好的模型 1.首先简述数据挖掘的过程 第一步:数据选择 可以通过业务原始数据.公开的数据集.也可通过爬虫的方式获取. 第二步: 数据预处理 数据极可能有噪音,不完整等缺陷,需要对数据进行数据标准化,方法有min-max 标
-
Python实现灰色关联分析与结果可视化的详细代码
目录 代码实现 下载数据 实现灰色关联分析 结果可视化 参考文章 之前在比赛的时候需要用Python实现灰色关联分析,从网上搜了下只有实现两个列之间的,于是我把它改写成了直接想Pandas中的计算工具直接计算person系数那样的形式,可以对整个矩阵进行运算,并给出了可视化效果,效果请见实现 灰色关联分析法 对于两个系统之间的因素,其随时间或不同对象而变化的关联性大小的量度,称为关联度.在系统发展过程中,若两个因素变化的趋势具有一致性,即同步变化程度较高,即可谓二者关联程度较高:反之,则较低.因
-
Python数据结构与算法之图结构(Graph)实例分析
本文实例讲述了Python数据结构与算法之图结构(Graph).分享给大家供大家参考,具体如下: 图结构(Graph)--算法学中最强大的框架之一.树结构只是图的一种特殊情况. 如果我们可将自己的工作诠释成一个图问题的话,那么该问题至少已经接近解决方案了.而我们我们的问题实例可以用树结构(tree)来诠释,那么我们基本上已经拥有了一个真正有效的解决方案了. 邻接表及加权邻接字典 对于图结构的实现来说,最直观的方式之一就是使用邻接列表.基本上就是针对每个节点设置一个邻接列表.下面我们来实现一个最简