Tree 组件搜索过滤功能实现干货
目录
- 1 Tree 组件搜索过滤功能简介
- 2 组件交互逻辑分析
- 2.1 对于匹配节点的标识如何呈现?
- 2.2 用户如何调用 tree 组件的搜索过滤功能?
- 2.3 对于匹配的节点其父节点及兄弟节点如何获取及处理?
- 3 实现原理和步骤
- 3.1 第一步:需要熟悉 tree 组件整个代码及逻辑组织方式
- 3.2 第二步:需要熟悉 tree 组件整个nodes数据结构是怎样的
- 3.3 第三步: 处理匹配节点及其父节点的展开属性
- 3.4 第四步: 如果是过滤功能时,需要将未匹配到的节点进行隐藏
- 3.5 第五步:处理匹配节点的高亮显示
- 3.6 第六步:
- 4 使用searchTree对Tree进行搜索过滤
- 5 遇到的难点问题
- 5.1 搜索的核心在于对匹配节点的所有父节点的访问以及处理
- 5.2 处理父级节点时进行优化,防止内层遍历重复处理已经访问过的父级节点,带来性能提升
- 5.3 对于过滤功能,还需处理节点的显示隐藏
- 6 小结
1 Tree 组件搜索过滤功能简介
本文源于 Vue DevUI 开源组件库实践。
树节点的搜索功能主要是为了方便用户能够快速查找到自己需要的节点。过滤功能不仅要满足搜索的特性,同时还需要隐藏掉与匹配节点同层级的其它未能匹配的节点。
搜索功能主要包括以下功能:
- 与搜索过滤字段匹配的节点需要进行标识,和普通节点进行区分
- 子节点匹配时,其所有父节点需要展开,方便用户查看层级关系
- 对于大数据量,采用虚拟滚动时,搜索过滤完成后滚动条需滚动至第一个匹配节点的位置
搜索会将匹配到的节点高亮:

过滤除了将匹配到的节点高亮之外,还会将不匹配的节点筛除掉:

2 组件交互逻辑分析
2.1 对于匹配节点的标识如何呈现?
通过将节点与搜索字段相匹配的 label 部分文字进行高亮加粗的方式进行标记。易于用户一眼就能够找到搜索到的节点。
2.2 用户如何调用 tree 组件的搜索过滤功能?
通过添加searchTree方法,用户通过ref的方式进行调用。并通过option参数配置区分搜索、过滤。
2.3 对于匹配的节点其父节点及兄弟节点如何获取及处理?
对于节点的获取及处理是搜索过滤功能的核心。尤其在大数据量的情况下,带来的性能消耗如何优化,将在实现原理中详情阐述。
3 实现原理和步骤
3.1 第一步:需要熟悉 tree 组件整个代码及逻辑组织方式
tree组件的文件结构:
tree ├── index.ts ├── src | ├── components | | ├── tree-node.tsx | | ├── ... | ├── composables | | ├── use-check.ts | | ├── use-core.ts | | ├── use-disable.ts | | ├── use-merge-nodes.ts | | ├── use-operate.ts | | ├── use-select.ts | | ├── use-toggle.ts | | ├── ... | ├── tree.scss | ├── tree.tsx └── __tests__ └── tree.spec.ts
可以看出,vue3.0中 composition-api 带来的便利。逻辑层之间的分离,方便代码组织及后续问题的定位。能够让开发者只专心于自己的特性,非常有利于后期维护。
添加文件use-search-filter.ts, 文件中定义searchTree方法。
import { Ref, ref } from 'vue';
import { trim } from 'lodash';
import { IInnerTreeNode, IUseCore, IUseSearchFilter, SearchFilterOption } from './use-tree-types';
export default function () {
return function useSearchFilter(data: Ref<IInnerTreeNode[]>, core: IUseCore): IUseSearchFilter {
const searchTree = (target: string, option: SearchFilterOption): void => {
// 搜索主逻辑
};
return {
virtualListRef,
searchTree,
};
}
}
SearchFilterOption的接口定义,matchKey 与 pattern的配置增添了搜索的匹配方式多样性。
export interface SearchFilterOption {
isFilter: boolean; // 是否是过滤节点
matchKey?: string; // node节点中匹配搜索过滤的字段名
pattern?: RegExp; // 搜索过滤时匹配的正则表达式
}
在tree.tsx主文件中添加文件use-search-fliter.ts的引用, 并将searchTree方法暴露给第三方调用者。
import useSearchFilter from './composables/use-search-filter';
setup(props: TreeProps, context: SetupContext) {
const userPlugins = [useSelect(), useOperate(), useMergeNodes(), useSearchFilter()];
const treeFactory = useTree(data.value, userPlugins, context);
expose({
treeFactory,
});
}
3.2 第二步:需要熟悉 tree 组件整个nodes数据结构是怎样的
nodes数据结构直接决定如何访问及处理匹配节点的父节点及兄弟节点
在use-core.ts文件中可以看出, 整个数据结构采用的是扁平结构,并不是传统的树结构,所有的节点包含在一个一维的数组中。
const treeData = ref<IInnerTreeNode[]>(generateInnerTree(tree));
// 内部数据结构使用扁平结构
export interface IInnerTreeNode extends ITreeNode {
level: number;
idType?: 'random';
parentId?: string;
isLeaf?: boolean;
parentChildNodeCount?: number;
currentIndex?: number;
loading?: boolean; // 节点是否显示加载中
childNodeCount?: number; // 该节点的子节点的数量
// 搜索过滤
isMatched?: boolean; // 搜索过滤时是否匹配该节点
childrenMatched?: boolean; // 搜索过滤时是否有子节点存在匹配
isHide?: boolean; // 过滤后是否不显示该节点
matchedText?: string; // 节点匹配的文字(需要高亮显示)
}
3.3 第三步: 处理匹配节点及其父节点的展开属性
节点中添加以下属性,用于标识匹配关系
isMatched?: boolean; // 搜索过滤时是否匹配该节点 childrenMatched?: boolean; // 搜索过滤时是否有子节点存在匹配 matchedText?: string; // 节点匹配的文字(需要高亮显示)
通过 dealMatchedData 方法来处理所有节点关于搜索属性的设置。
它主要做了以下事情:
- 将用户传入的搜索字段进行大小写转换
- 循环所有节点,先处理自身节点是否与搜索字段匹配,匹配就设置
selfMatched = true。首先判断用户是否通过自定义字段进行搜索 (matchKey参数),如果有,设置匹配属性为node中自定义属性,否则为默认label属性;然后判断是否进行正则匹配 (pattern参数),如果有,就进行正则匹配,否则为默认的忽略大小写的模糊匹配。 - 如果自身节点匹配时, 设置节点
matchedText属性值,用于高亮标识。 - 判断自身节点有无
parentId,无此属性值时,为根节点,无须处理父节点。有此属性时,需要进行内层循环处理父节点的搜索属性。利用set保存节点的parentId, 依次向前查找,找到parent节点,判读是否该parent节点被处理过,如果没有,设置父节点的childrenMatched和expanded属性为true,再将parent节点的parentId属性加入set中,while循环重复这个操作,直到遇到第一个已经处理过的父节点或者直到根节点停止循环。 - 整个双层循环将所有节点处理完毕。
dealMatchedData核心代码如下:
const dealMatchedData = (target: string, matchKey: string | undefined, pattern: RegExp | undefined) => {
const trimmedTarget = trim(target).toLocaleLowerCase();
for (let i = 0; i < data.value.length; i++) {
const key = matchKey ? data.value[i][matchKey] : data.value[i].label;
const selfMatched = pattern ? pattern.test(key) : key.toLocaleLowerCase().includes(trimmedTarget);
data.value[i].isMatched = selfMatched;
// 需要向前找父节点,处理父节点的childrenMatched、expand参数(子节点匹配到时,父节点需要展开)
if (selfMatched) {
data.value[i].matchedText = matchKey ? data.value[i].label : trimmedTarget;
if (!data.value[i].parentId) {
// 没有parentId表示时根节点,不需要再向前遍历
continue;
}
let L = i - 1;
const set = new Set();
set.add(data.value[i].parentId);
// 没有parentId时,表示此节点的纵向parent已访问完毕
// 没有父节点被处理过,表示时第一次向上处理当前纵向父节点
while (L >= 0 && data.value[L].parentId && !hasDealParentNode(L, i, set)) {
if (set.has(data.value[L].id)) {
data.value[L].childrenMatched = true;
data.value[L].expanded = true;
set.add(data.value[L].parentId);
}
L--;
}
// 循环结束时需要额外处理根节点一层
if (L >= 0 && !data.value[L].parentId && set.has(data.value[L].id)) {
data.value[L].childrenMatched = true;
data.value[L].expanded = true;
}
}
}
};
const hasDealParentNode = (pre: number, cur: number, parentIdSet: Set<unknown>) => {
// 当访问到同一层级前已经有匹配时前一个已经处理过父节点了,不需要继续访问
// 当访问到第一父节点的childrenMatched为true的时,不再需要向上寻找,防止重复访问
return (
(data.value[pre].parentId === data.value[cur].parentId && data.value[pre].isMatched) ||
(parentIdSet.has(data.value[pre].id) && data.value[pre].childrenMatched)
);
};
3.4 第四步: 如果是过滤功能时,需要将未匹配到的节点进行隐藏
节点中添加以下属性,用于标识节点是否隐藏。
isHide?: boolean; // 过滤后是否不显示该节点
同3.3中核心处理逻辑大同小异,通过双层循环, 节点的 isMatched 和 childrenMatched 以及父节点的 isMatched 设置自身节点是否显示。
核心代码如下:
const dealNodeHideProperty = () => {
data.value.forEach((item, index) => {
if (item.isMatched || item.childrenMatched) {
item.isHide = false;
} else {
// 需要判断是否有父节点有匹配
if (!item.parentId) {
item.isHide = true;
return;
}
let L = index - 1;
const set = new Set();
set.add(data.value[index].parentId);
while (L >= 0 && data.value[L].parentId && !hasParentNodeMatched(L, index, set)) {
if (set.has(data.value[L].id)) {
set.add(data.value[L].parentId);
}
L--;
}
if (!data.value[L].parentId && !data.value[L].isMatched) {
// 没有parentId, 说明已经访问到当前节点所在的根节点
item.isHide = true;
} else {
item.isHide = false;
}
}
});
};
const hasParentNodeMatched = (pre: number, cur: number, parentIdSet: Set<unknown>) => {
return parentIdSet.has(data.value[pre].id) && data.value[pre].isMatched;
};
3.5 第五步:处理匹配节点的高亮显示
如果该节点被匹配,将节点的label处理成[preMatchedText, matchedText, postMatchedText]格式的数组。 matchedText添加 span标签包裹,通过CSS样式显示高亮效果。
const matchedContents = computed(() => {
const matchItem = data.value?.matchedText || '';
const label = data.value?.label || '';
const reg = (str: string) => str.replace(/[-[\]{}()*+?.,\\^$|#\s]/g, '\\$&');
const regExp = new RegExp('(' + reg(matchItem) + ')', 'gi');
return label.split(regExp);
});
<span class={nodeTitleClass.value}>
{ !data.value?.matchedText && data.value?.label }
{
data.value?.matchedText
&& matchedContents.value.map((item: string, index: number) => (
index % 2 === 0
? item
: <span class={highlightCls}>{item}</span>
))
}
</span>
3.6 第六步:
tree组件采用虚拟列表时,需将滚动条滚动至第一个匹配的节点,方便用户查看
先得到目前整个树显示出来的节点,找到第一个匹配的节点下标。调用虚拟列表组件的 scrollTo 方法滚动至该匹配节点。
const getFirstMatchIndex = (): number => {
let index = 0;
const showTreeData = getExpendedTree().value;
while (index <= showTreeData.length - 1 && !showTreeData[index].isMatched) {
index++;
}
return index >= showTreeData.length ? 0 : index;
};
const scrollIndex = getFirstMatchIndex();
virtualListRef.value.scrollTo(scrollIndex);
通过 scrollTo 方法定位至第一个匹配项效果图:
原始树结构显示图:

过滤功能:
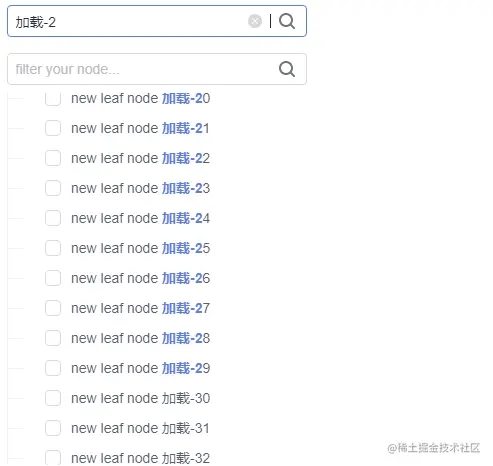
4 使用searchTree对Tree进行搜索过滤
到这里 Tree 组件的搜索过滤功能就开发完了,我们来使用下吧。
<script setup lang="ts">
import { ref } from 'vue';
const treeRef = ref();
const data = ref([
{
label: 'parent node 1',
},
{
label: 'parent node 2',
children: [
{
label: 'child node 2-1',
children: [
{
label: 'child node 2-1-1',
},
{
label: 'child node 2-1-2',
},
],
},
{
label: 'child node 2-2',
children: [
{
label: 'child node 2-2-1',
},
{
label: 'child node 2-2-2',
},
],
},
],
},
]);
const onSearch = (keyword) => {
// 只需要调用 Tree 组件实例的 searchTree 方法即可实现搜索过滤
treeRef.value.treeFactory.searchTree(keyword);
};
</script>
<template>
<d-search @search="onSearch"></d-search>
<d-tree ref="treeRef" :data="data"></d-tree>
</template>
是不是非常简单?
searchTree 方法一共有两个参数:
keyword 搜索关键字
options 配置选项
- isFilter 是否需要过滤
- matchKey node节点中匹配搜索过滤的字段名
- pattern 搜索过滤时匹配的正则表达式
5 遇到的难点问题
5.1 搜索的核心在于对匹配节点的所有父节点的访问以及处理
整棵树数据结构就是一个一维数组,向上需要将匹配节点所有的父节点全部展开, 向下需要知道有没有子节点存在匹配。传统tree组件的数据结构是树形结构,通过递归的方式完成节点的访问及处理。对于扁平的数据结构应该如何处理?
- 方案一:扁平数据结构 --> 树形结构 --> 递归处理 --> 扁平数据结构 (NO)
- 方案二: node添加parent属性,保存该节点父级节点内容 --> 遍历节点处理自身节点及parent节点 (No)
- 方案三: 同过双层循环,第一层循环处理当前节点,第二层循环处理父节点 (Yes)
方案一:通过数据结构的转换处理,不仅丢掉了扁平数据结构的优势,还增加了数据格式转换的成本,并带来了更多的性能消耗。
方案二:parent属性添加其实就是一种树形结构的模仿,增加内存消耗,保存很多无用重复数据。循环访问节点时也存在节点的重复访问。节点越靠后,重复访问越严重,无用的性能消耗。
方案三: 利用扁平数据结构的优势,节点是有顺序的。即:树节点的显示顺序就是节点在数组中的顺序,父节点一定是在子节点之前。父节点访问处理只需要遍历该节点之前的节点,通过 childrenMatched属性标识该父节点有子节点存在匹配。 不用添加parent字段存取所有的父节点信息,不用通过数据转换,再递归寻找处理节点。
5.2 处理父级节点时进行优化,防止内层遍历重复处理已经访问过的父级节点,带来性能提升
外层循环,如果该节点没有匹配搜索字段,将不进行内层循环,直接跳过。 详见3.3中的代码
通过对内层循环终止条件的优化,防止重复访问同一个父节点
let L = index - 1;
const set = new Set();
set.add(data.value[index].parentId);
while (L >= 0 && data.value[L].parentId && !hasParentNodeMatched(L, index, set)) {
if (set.has(data.value[L].id)) {
set.add(data.value[L].parentId);
}
L--;
}
const hasDealParentNode = (pre: number, cur: number, parentIdSet: Set<unknown>) => {
// 当访问到同一层级前已经有匹配时前一个已经处理过父节点了,不需要继续访问
// 当访问到第一父节点的childrenMatched为true的时,不再需要向上寻找,防止重复访问
return (
(data.value[pre].parentId === data.value[cur].parentId && data.value[pre].isMatched) ||
(parentIdSet.has(data.value[pre].id) && data.value[pre].childrenMatched)
);
};
5.3 对于过滤功能,还需处理节点的显示隐藏
同样通过双层循环、以及处理匹配数据时增加的isMatched 、 childrenMatched属性来共同决定节点的isHide属性,详见3.4中的代码、
通过对内层循环终止条件的优化,与设置 childrenMatched时的判断有所区别。
const hasParentNodeMatched = (pre: number, cur: number, parentIdSet: Set<unknown>) => {
return parentIdSet.has(data.value[pre].id) && data.value[pre].isMatched;
};
6 小结
虽然是一个组件下一个小特性的开发,但是从特性的交互分析开始,一步步到最终的功能实现,整个过程还是收获满满。
平时开发中很少能够从方案设计到功能实现有一个整体的规划,往往都是先上手代码,在开发过程中才发现方案选取不合理,就会走很多弯路。
所以,刚开始的特性分析和方案设计就显得尤为重要。 分析 --> 设计 --> 方案探讨 --> 方案确定 --> 功能实现 --> 逻辑优化。每个过程都能锻炼提升自己的能力。
以上就是Tree 组件搜索过滤功能实现干货的详细内容,更多关于Tree 组件搜索过滤的资料请关注我们其它相关文章!
相关推荐
-
vue实现搜索过滤效果
本文实例为大家分享了vue实现搜索过滤效果的具体代码,供大家参考,具体内容如下 html: <table id="tfhover_1" class="tftable_1" border="1"> <tr> <th>名称</th> <th>链接状态</th> <th>IP</th> <th>特例类型</th> <th>
-
Vue2.0实现1.0的搜索过滤器功能实例代码
Vue2.0删除了很多1.0的比较实用的过滤器,如filterBy,orderBy.官方文档给了通过计算属性实现1.0搜索过滤器功能,自己又加入了大小写通用检索功能,比较简单,学一下. <body> <div class="app"> <input type="text" v-model="name"> <ul> <li v-for="user in newUsers" &
-
easyui combogrid实现本地模糊搜索过滤多列
这几天在项目中前台使用到了easyui 的 combogrid插件为用户提供点选数据项的功能.由于数据项的内容可能有很多,所以仅仅是点选还不够,需要能够对用户的输入进行过滤,即根据用户的输入将某一列与用户输入匹配的数据项筛选保留下来. 实现这一功能需要以下几个步骤: 1.声明一个combogrid <div class="fitem"> <label>盘条基本信息编号:</label> <input class="easyui-com
-

Tree 组件搜索过滤功能实现干货
目录 1 Tree 组件搜索过滤功能简介 2 组件交互逻辑分析 2.1 对于匹配节点的标识如何呈现? 2.2 用户如何调用 tree 组件的搜索过滤功能? 2.3 对于匹配的节点其父节点及兄弟节点如何获取及处理? 3 实现原理和步骤 3.1 第一步:需要熟悉 tree 组件整个代码及逻辑组织方式 3.2 第二步:需要熟悉 tree 组件整个nodes数据结构是怎样的 3.3 第三步: 处理匹配节点及其父节点的展开属性 3.4 第四步: 如果是过滤功能时,需要将未匹配到的节点进行隐藏 3.5 第五
-
react echarts tree树图搜索展开功能示例详解
目录 前言 最终效果 版本信息 核心功能: 关键思路: 附上代码 数据data.js 功能: TreeUtils 总结: 前言 umi+antd-admin 框架中使用类组件+antd结合echarts完成树图数据展示和搜索展开功能 最终效果 版本信息 "antd": "3.24.2", "umi": "^2.7.7", "echarts": "^4.4.0", "echart
-
Element-ui tree组件自定义节点使用方法代码详解
工作上使用到element-ui tree 组件,主要功能是要实现节点拖拽和置顶,通过自定义内容方法(render-content)渲染树代码如下~ <template> <div class="sortDiv"> <el-tree :data="sortData" draggable node-key="id" ref="sortTree" default-expand-all :expand-
-
layui.tree组件的使用以及搜索节点功能的实现
由于项目树形节点比较多需要增加节点搜索功能,所以研究了一下加上社区伙伴的支持,目前功能可以简单实现但细节还需要修改,添加上了组件的基本使用方法和属性,现在分享出来~ HTML: <div class="layui-btn-container"> <button class="layui-btn layui-btn-sm" type="button" lay-demo="getChecked">获取选中节
-
vue中使用elementui实现树组件tree右键增删改功能
功能描述: 1.右击节点可进行增删改 2.可对节点数据进行模糊查询 3.右击第一级节点可以进行同级节点增加 4.双击节点或点击修改节点 都可以对节点获取焦点并进行修改,回车修改成功 5.可对节点进行拖拽,实现节点移动功能 效果图: 完整代码: <template> <div class="lalala tree-container"> <el-input placeholder="输入关键字进行过滤" v-model="fil
-
基于element-ui封装可搜索的懒加载tree组件的实现
引言 最近开发项目时遇到一个需求就是采用tree的方式展示以万为单位的数据,因为数据量大第一反应就是采用"懒加载"的方式实现,为了方便用户在庞大的数据量中快速定位到某个节点搜索功能也是必不可少的:因为采用"懒加载"数据,搜索当然也是远程搜索了:确定了需求当然第一时间就去网上找有没有小伙伴已经实现了相关组件,最后....,还是自己实现一个吧(由于公司采用的element-ui所以基于el-tree进行改造):[这只是自己实现的一种思路,希望大家多多指正] 1.懒加载树
-
antd为Tree组件标题附加操作按钮功能
目录 一.前言 二.实现方案 三.总结 一.前言 使用antd的tree组件实现下面这样的模块树,点击标题请求其下列表的数据,点击标题旁边的操作图标则执行对应的增删改功能: 二.实现方案 1.封装一个设置树标题的方法,通过开关改变state来控制图标按钮是否可见: 处理树数据(name.children) const setTree = (module_data: any) => { return module_data.map((item: any) => { let _json = {
-
Angular搜索 过滤 批量删除 添加 表单验证功能集锦(实例代码)
废话不多说了,直接给大家贴代码,具体代码如下所示: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <style> *{ margin: 0; padding: 0; } .sspan{ background: #28a54c; color: #fff; margi
-
jQuery EasyUI tree增加搜索功能的实现方法
扩展jQuery EasyUI tree搜索树节点的方法,使其支持节点名称的模糊匹配,将不匹配的节点隐藏. /** * 1)扩展jquery easyui tree的节点检索方法.使用方法如下: * $("#treeId").tree("search", searchText); * 其中,treeId为easyui tree的根UL元素的ID,searchText为检索的文本. * 如果searchText为空或"",将恢复展示所有节点为正常状
-
使用Vue3+Vant组件实现App搜索历史记录功能(示例代码)
最近在开发一款新的app项目,我自己也是第一次接触app开发,经过团队的一段时间研究调查,决定使用Vue3+Vant前端组件的模式进行开发,vue2开发我们已经用过几个项目了,所以决定这一次尝试使用Vue3来进行前段开发. 我刚开始负责搜索功能的开发,有历史搜索记录的需求,一开始我认为这是记录的存储信息也会放在一个数据库表里面,但经过一番调查,发现并不是这样,而是要存储在本地.但是网上的方法也并没有完全解决问题,经过一番尝试,终于给搞好了,话不多说,直接上效果图. 初始化不显示历史搜索记录 回车