Apache Kafka 分区重分配的实现原理解析
目录
- 一、前言
- 二、工具的使用
- 三、元数据管理及协调器
- 3.1 ZooKeeper
- 3.2 Kafka Controller
- 四、分区重分配流程分析
- 4.1 kafka-reassign-partitions 客户端
- 4.2 controller 维护分区的元数据信息
- 4.3 broker 端数据跨路径迁移
- 五、总结
本文作者为中国移动云能力中心大数据团队软件开发工程师孙大鹏,本文结合 2.0.0 版本的 Kafka 源码,详细介绍了 Kafka 分区副本重分配的流程和逻辑,供大家参考。
一、前言
Kafka 是由 Apache 软件基金会开发的一个开源流处理平台,旨在提供一个统一的、高吞吐、低延迟的实时数据处理平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。
在 Kafka 中,用 topic 来对消息进行分类,每个进入到 Kafka 的信息都会被放到一个 topic 下,同时每个 topic 中的消息又可以分为若干 partition 以此来提高消息的处理效率。存储消息数据的主机服务器被命名为 broker。通常为了保证数据的可靠性,数据是以多副本的形式保存在不同 broker 的不同磁盘上的。对于每一个 topic 的每一个 partition,如果多个副本之间完成了数据同步,保证了数据的一致性,则此时的多个副本所在的 broker 的集合称为 Isr。同一时间,某个 topic 的某个 partition 的多个副本中仅有一个对外提供服务,此时对外提供服务的 broker 被认定为该 partition 的 leader,客户端的请求都集中到 leader 上。
对于 2 副本 3 分区的 topic 其描述信息及存储状态如下所示:
test的描述信息: Topic:test PartitionCount:3 ReplicationFactor:2 Configs:min.insync.replic as=1 Topic: test Partition: 0 Leader: 0 Replicas: 0,1 Isr: 0,1 Topic: test Partition: 1 Leader: 2 Replicas: 2,0 Isr: 2,0 Topic: test Partition: 2 Leader: 1 Replicas: 1,2 Isr: 1,2

test的副本分布
健康状态的 Kafka 集群,对于每个 topic 的每个 partition,其 Isr 都应该等于预期的副本集合(后面均已 Replicas 表示),但在实际场景中,不可避免的存在磁盘/主机故障,或者 由于某些原因需要将部分 broker 节点下线的情况,此时就需要将故障/要下线的 broker 从 Replicas 中移除。对此 Kafka 提供了 kafka-reassign-partitions 工具来进行手动的分区副本迁移。
二、工具的使用
在 Kafka 的根路径下,通过执行如下命令,来完成分区副本的重分配:
./bin/kafka‐reassign‐partitions.sh ‐‐zookeeper localhost:2181/kafka ‐‐reassignment‐json‐file reassign‐topic.json ‐‐execute
其中:reassign‐topic.json 文件指定了分区副本的分布情况,示例如下:
{
"version": 1,
"partitions": [
{
"topic": "test",
"partition": 2,
"replicas": [
2,
1
],
"log_dirs": [
"any",
"any"
]
}
}
文件中指明了将 topic=test,partition=2 的分区的两副本分别移动到 brokerId=2 和 brokerId=1 的节点的任意磁盘路径上。
下面将结合 2.0.0 版本的 Kafka 源码简单的介绍下 Kafka 分区副本重分配的流程和逻辑。
三、元数据管理及协调器
在开始之前先简单介绍下在 Kafka 分区副本重分配中涉及到的两个概念:ZooKeeper 和 Kafka Controller。
3.1 ZooKeeper
Kafka 的元数据,是存储在 ZooKeeper 中的。Apache ZooKeeper 是一个提供高可靠性的分布式协调服务框架。它使用的数据模型类似于文件系统的树形结构,根目录也是以“/”开始。该结构上的每个节点被称为 znode,用来保存一些元数据协调信息。同时 ZooKeeper 赋予客户端监控 znode 变更的能力,即所谓的 Watch 通知功能。一旦 znode 节点被创建、删除,子节点数量发生变化,或是 znode 所存的数据本身变更, ZooKeeper 会通过节点变更监听器 (ChangeHandler) 的方式显式通知客户端以便客户端 触发对应的处理操作。
3.2 Kafka Controller
Kafka Controller 是 Apache Kafka 的核心组件,它的主要作用是在 Apache ZooKeeper 的帮助下管理和协调整个 Kafka 集群。集群中任意一台 Broker 都能充当控制器的角色,但是,在运行过程中,只能有一个 Broker 成为控制器,行使其管理和协调的职责。
四、分区重分配流程分析
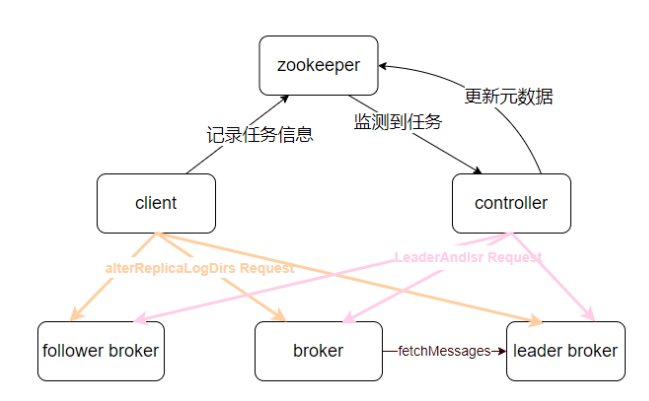
Kafka 的分区重分配就是在 client、broker 和 controller 的协同运行下完成的。即:
1. 客户端发起分区重分配任务,在 ZooKeeper 中创建/admin/reassign_partitions 节点,然 后向涉及的 broker 发送 alterReplicaLogDirs 请求
2. controller 监测到 ZooKeeper 中/admin/reassign_partitions 的变化,触发 Kafka 分区元 数据的变更维护操作
3. broker 接收到客户端发送的 alterReplicaLogDirs 请求,根据具体任务内容在服务端实际完成分区副本移动
流程总结如下图所示:
下面将针对这三部分分别展开介绍:
4.1 kafka-reassign-partitions 客户端
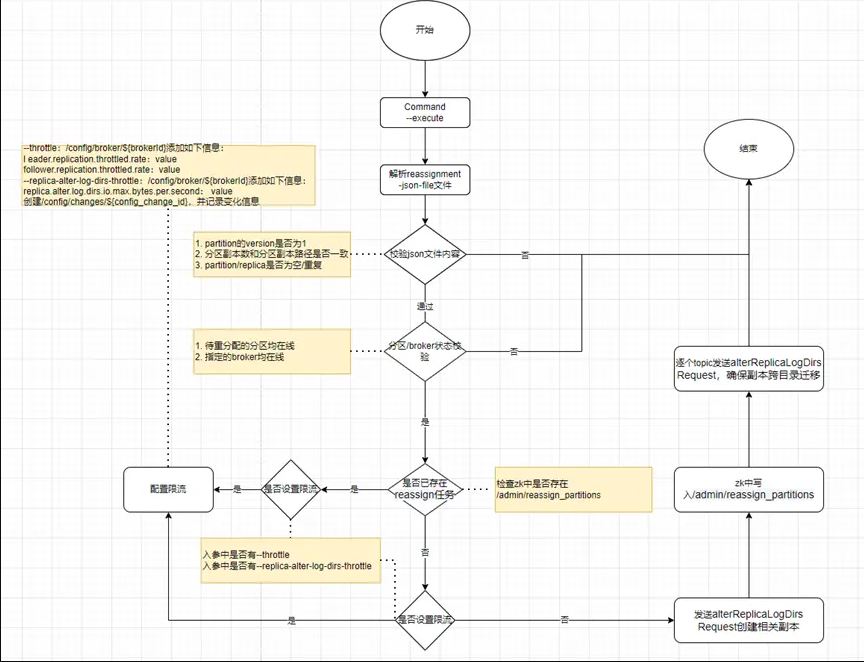
分区重分配任务是由客户端发起的,其入口主类为 ReassignPartitionsCommand.scala 中,调用 executeAssignment 方法。客户端的 executeAssignment 方法主要完成了如下操作:
1.解析 json 文件并进行相关校验
•读取 json 文件内容,校验“partitions”的“version”,仅为 1 时,继续执行副本重分 配
•校验分区副本数和副本数据路径数是否一致
•校验 partition/replica 是否为空/重复
2.检查待重分配的分区在集群中是否存在(根据 zk 中的/brokers/topics/${topic})
3.检查确认所有目标 broker 均在线(zk 中/brokers/ids 的子 znode 列表)
4.检查是否已存在分区副本重分配任务,如果已存在相关任务,则退出
5.将分区重分配任务记录到 zk 中,即在 zk 中创建/admin/reassign_partitions,以便 controller 可以发现并协调 broker 进行相关操作
6.根据解析的 json 内容,逐个 topic 向相关的 broker 发送 alterReplicaLogDirs 请求
客户端的处理逻辑可总结为如下流程图:
4.2 controller 维护分区的元数据信息
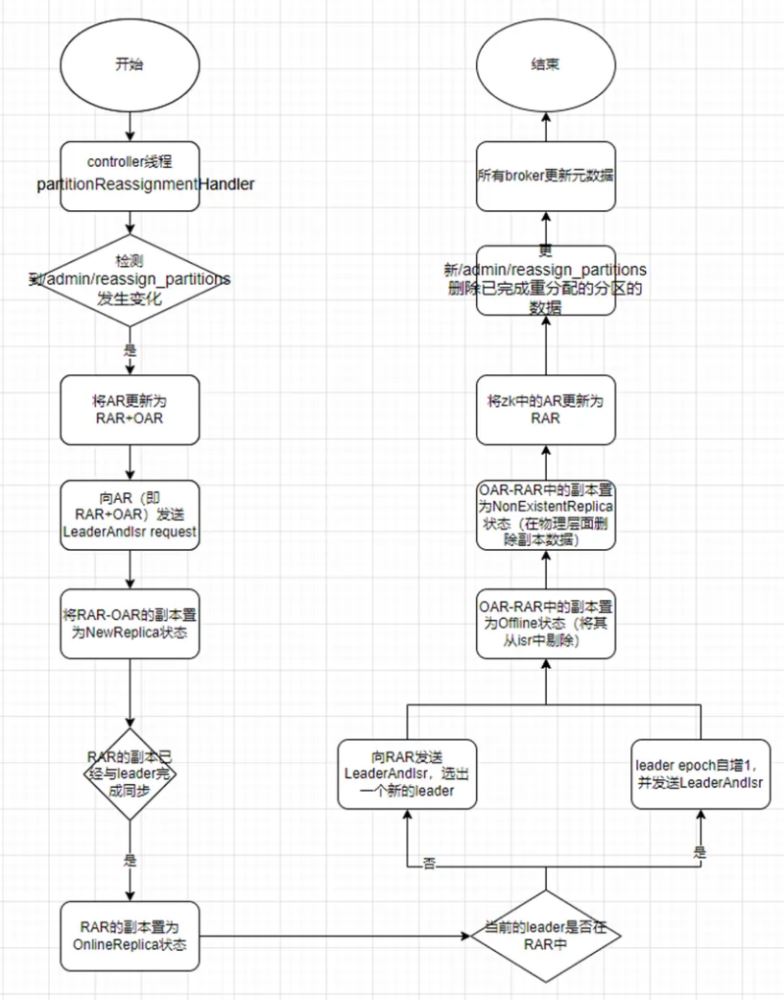
在 controller 启动时会创建 partitionReassignmentHandler,kafkaController 主线程回调 onControllerFailover 时,检测到/admin/reassign_partitions 发生变化时,触发分区副本重分配操作,在 maybeTriggerPartitionReassignment 中通过调用 onPartitionReassignment 真正执行分区副本重分配。在 onPartitionReassignment 中定 义了三个概念:
•RAR:指定的分区副本放置策略
•OAR:原始的分区副本放置策略
•AR:当前的分区副本放置策略
onPartitionReassignment 的执行过程可以总结为如下步骤:
检查指定的分区副本是否处在 isr 中,如果不在则执行以下前 3 步,否则直接执行第 4 步
1.在 zk 中将 AR 更新为 RAR+OAR (/broker/topics/${topicName})
2.向所有副本(RAR+OAR)中发送 LeaderAndIsr 请求
3.将 RAR-OAR 的副本状态置为 NewReplica,等待 NewReplica 中的数据与 leader 中的数据 完成同步
4.等待直到所有 RAR 中的副本完成与 leader 的同步
5.将所有 RAR 的副本置为 OnlineReplica 状态
6.将 RAR 作为 AR
7.如果当前的 leader 不在 RAR 中,发送 LeaderAndIsr Request 从 RAR 中选出一个新的 leader;如果当前 leader 在 RAR 中,检查 leader 状态,如果 leader 健康则更新 LeaderEpoch,否则重新选择 leader
8.将 OAR-RAR 的副本置为 Offline 状态
9.将 OAR-RAR 的副本置为 NonExistentReplica 状态(真实删除对应的分区副本)
10.将 zk 中的 AR 置为 RAR(/brokers/topics/${topicName}数据格式:{"version":1,"partitions":{"0":[${brokerId}]}})
11.更新 zk 中/admin/reassign_partitions 的值,将完成迁移的分区删除
12.同步所有 broker,更新元数据信息
逻辑流程图如下:
4.3 broker 端数据跨路径迁移
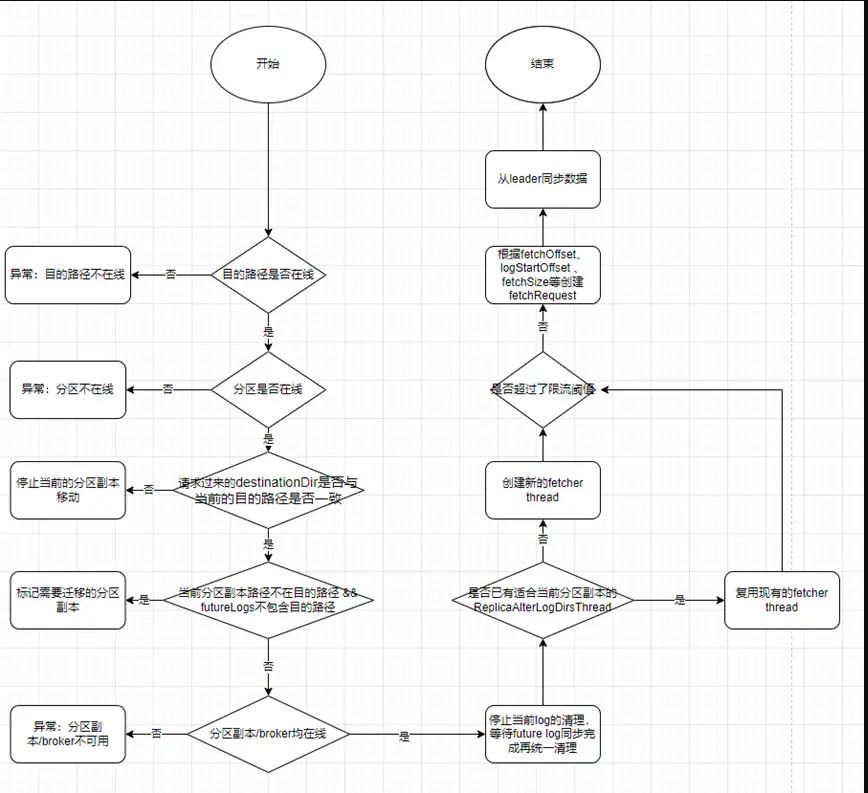
底层数据跨路径迁移,是由 broker 端完成的,broker 接收到客户端发来的 ALTER_REPLICA_LOG_DIRS 请求后,调用 alterReplicaLogDirs 方法,相关流程如下:
1.确保目的路径/待移动分区在线
2.如果当前分区副本的 log 路径不存在给定的目的路径并且 futureLogs(用于跨路径数据迁移的中间过程)也不包含目的路径,则在内存中记录当前分区副本和目的 logDir,即标记那些需要进行迁移的分区副本路径
3.对于需要移动的分区副本,目的 broker 的路径中创建 future Log
4.停止当前 Log 的清理工作,等待 future Log 同步完再清理
5.创建 ReplicaAlterLogDirsThread,逐个 topic 逐个 partition 获取 fetchOffset、 logStartOffset 、fetchSize 等数据构造 Fetch 请求
6.通过 ReplicaManager.fetchMessages 从分区副本 leader 获取数据,完成数据同步
更详细的处理流程如下图所示:
五、总结
Kafka 分区重分配,通过 kafka-reassign-partitions 启动任务,将任务记录在元数据管理器 ZooKeeper 中,Kafka controller 通过对 ZooKeeper 的监测,发现相关任务通过和 broker 的交互按序处理相关的迁移任务,同时 controller 实时维护 ZooKeeper 中的元数据信息并进行相关变化的记录,保证在重分配过程中,不影响 topic 分区的正常使用,在任务完成后,再由 controller 负责 ZooKeeper 中重分配任务标记的清理,以便客户端验证重分配任务的结果。
到此这篇关于Apache Kafka 分区重分配的实现原理解析的文章就介绍到这了,更多相关Apache Kafka 分区重分配内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

kafka手动调整分区副本数的操作步骤
目录 前言 前置准备 操作步骤 增加副本 前言 在生产环境中,akfka集群下的每台服务器的配置和性能可能不一样,但Kafka集群只会根据配置规则创建对应的分区副本,这样一来可能就会导致个别服务器存储压力较大. 在这种情况下,就需要手动调整分区副本的存储.我们不妨看看下面的这张图就明白了 上图的传达的意思是: broker0和broker1所在的服务器配置较高,存储容量较大,但是broker2和broker3所在的机器配置稍差存储容量较小,一开始创建出主题之后,集群只会按照默认的配置规则,将le
-
使用kafka如何选择分区数及kafka性能测试
kafka选择分区数及kafka性能测试 1.简言 如何选择合适的分区,这是我们经常面临的问题,不过针对这个问题,在网上并没有搜到固定的答案.因此,今天在这里主要通过性能测试的工具来告诉如何选择相对应的kafka分区. 2.性能测试工具 kafka本身提供了比较的性能测试工具,我们可以使用它来测试适用于我们机器的kafka分区. ① 生产者性能测试 分别创建三个topic,副本数设置为1. bin/kafka-topics.sh --zookeeper zk --create --rep
-
Java kafka如何实现自定义分区类和拦截器
生产者发送到对应的分区有以下几种方式: (1)指定了patition,则直接使用:(可以查阅对应的java api, 有多种参数) (2)未指定patition但指定key,通过对key的value进行hash出一个patition: (3)patition和key都未指定,使用轮询选出一个patition. 但是kafka提供了,自定义分区算法的功能,由业务手动实现分布: 1.实现一个自定义分区类,CustomPartitioner实现Partitioner import org.apache
-
详解kafka中的消息分区分配算法
目录 背景 RangeAssignor 定义 源码分析 场景 RoundRobinAssignor 定义 源码分析 场景 StickyAssignor 定义 场景 背景 kafka有分区机制,一个主题topic在创建的时候,会设置分区.如果只有一个分区,那所有的消费者都订阅的是这一个分区消息:如果有多个分区的话,那消费者之间又是如何分配的呢? 分配算法 RangeAssignor 定义 Kafka默认采⽤RangeAssignor的分配算法. RangeAssignor策略的原理是按照消费者总数
-
解决kafka消息堆积及分区不均匀的问题
目录 kafka消息堆积及分区不均匀的解决 1.先在kafka消息中创建 2.添加配置文件application.properties 3.创建kafka工厂 4.展示kafka消费者 kafka出现若干分区不消费的现象 定位过程 验证 解决方法 kafka消息堆积及分区不均匀的解决 我在环境中发现代码里面的kafka有所延迟,查看kafka消息发现堆积严重,经过检查发现是kafka消息分区不均匀造成的,消费速度过慢.这里由自己在虚拟机上演示相关问题,给大家提供相应问题的参考思路. 这篇文章有点
-
Apache Kafka 分区重分配的实现原理解析
目录 一.前言 二.工具的使用 三.元数据管理及协调器 3.1 ZooKeeper 3.2 Kafka Controller 四.分区重分配流程分析 4.1 kafka-reassign-partitions 客户端 4.2 controller 维护分区的元数据信息 4.3 broker 端数据跨路径迁移 五.总结 本文作者为中国移动云能力中心大数据团队软件开发工程师孙大鹏,本文结合 2.0.0 版本的 Kafka 源码,详细介绍了 Kafka 分区副本重分配的流程和逻辑,供大家参考. 一.前
-
spring boot jar的启动原理解析
1.前言 近来有空对公司的open api平台进行了些优化,然后在打出jar包的时候,突然想到以前都是对spring boot使用很熟练,但是从来都不知道spring boot打出的jar的启动原理,然后这回将jar解开了看了下,与想象中确实大不一样,以下就是对解压出来的jar的完整分析. 2.jar的结构 spring boot的应用程序就不贴出来了,一个较简单的demo打出的结构都是类似,另外我采用的spring boot的版本为1.4.1.RELEASE网上有另外一篇文章对spring
-
Spring Boot 文件上传原理解析
首先我们要知道什么是Spring Boot,这里简单说一下,Spring Boot可以看作是一个框架中的框架--->集成了各种框架,像security.jpa.data.cloud等等,它无须关心配置可以快速启动开发,有兴趣可以了解下自动化配置实现原理,本质上是 spring 4.0的条件化配置实现,深抛下注解,就会看到了. 说Spring Boot 文件上传原理 其实就是Spring MVC,因为这部分工作是Spring MVC做的而不是Spring Boot,那么,SpringMVC又是怎么
-
在Spring Boot应用程序中使用Apache Kafka的方法步骤详解
第1步:生成我们的项目: Spring Initializr来生成我们的项目.我们的项目将提供Spring MVC / Web支持和Apache Kafka支持. 第2步:发布/读取Kafka主题中的消息: <b>public</b> <b>class</b> User { <b>private</b> String name; <b>private</b> <b>int</b> age
-
SpringCloud配置刷新原理解析
我们知道在SpringCloud中,当配置变更时,我们通过访问http://xxxx/refresh,可以在不启动服务的情况下获取最新的配置,那么它是如何做到的呢,当我们更改数据库配置并刷新后,如何能获取最新的数据源对象呢?下面我们看SpringCloud如何做到的. 一.环境变化 1.1.关于ContextRefresher 当我们访问/refresh时,会被RefreshEndpoint类所处理.我们来看源代码: /* * Copyright 2013-2014 the original a
-
Spring整合Dubbo框架过程及原理解析
这篇文章主要介绍了Spring整合Dubbo框架过程及原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Dubbo作为一个RPC框架,其最核心的功能就是要实现跨网络的远程调用.演示过程创建两个小工程,一个作为服务的提供者,一个作为服务的消费者.通过Dubbo来实现服务消费者远程调用服务提供者的方法. dubbo 的使用需要一个注册中心,这里以Zookeeper为例来演示 1.Dubbo架构 Dubbo架构图(Dubbo官方提供)如下: 节
-
SpringCloud Eureka自我保护机制原理解析
这篇文章主要介绍了SpringCloud Eureka自我保护机制原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1. 自我保护机制演示 eureka在频繁修改微服务名称的时候,可以会出现如下现象: 2. 什么是自我保护模式? 默认情况下,如果EurekaServer在一定时间内没有接收到某个微服务实例的心跳,EurekaServer将会注销该实例(默认90秒).但是当网络分区故障发生时,微服务与EurekaServer之间无法正常通信
-
Google和Facebook不使用Docker的原理解析
写作本文的起因是我想让修改后的分布式 PyTorch 程序能更快的在 Facebook 的集群上启动.探索过程很有趣,也展示了工业机器学习需要的知识体系. 2007 年我刚毕业后在 Google 工作过三年.当时觉得分布式操作系统 Borg 真好用. 从 2010 年离开 Google 之后就一直盼着它开源,直到 Kubernetes 的出现. Kubernetes 调度的计算单元是 containers(准确的翻译是"集装箱",而不是意思泛泛的"容器",看看 Do
-
大厂禁止SpringBoot在项目使用Tomcat容器原理解析
目录 前言 SpringBoot中的Tomcat容器 SpringBoot设置Undertow Tomcat与Undertow的优劣对比 最后 前言 在SpringBoot框架中,我们使用最多的是Tomcat,这是SpringBoot默认的容器技术,而且是内嵌式的Tomcat.同时,SpringBoot也支持Undertow容器,我们可以很方便的用Undertow替换Tomcat,而Undertow的性能和内存使用方面都优于Tomcat,那我们如何使用Undertow技术呢?本文将为大家细细讲解
-
Tomcat Catalina为什么不new出来原理解析
一.Catalina为什么不new出来? 掌握了Java的类加载器和双亲委派机制,现在我们就可以回答正题上来了,Tomcat的类加载器是怎么设计的? 1.Web容器的特性 Web容器有其自身的特殊性,所以在类加载器这块是不能完全使用JVM的类加载器的双亲委派机制的.在Web容器中我们应该要满足如下的特性: 隔离性: 部署在同一个Web容器上的两个Web应用程序所使用的Java类库可以实现相互隔离.设想一下,两个Web应用,一个使用了Spring3.0,另一个使用了新的的5.0,应用服务器使用一个