Mysql数据库group by原理详解
目录
- 引言
- 1. 使用group by的简单例子
- 2. group by 原理分析
- 2.1 explain 分析
- 2.2 group by 的简单执行流程
- 3. where 和 having的区别
- 3.1 group by + where 的执行流程
- 3.2 group by + having 的执行
- 3.3 同时有where、group by 、having的执行顺序
- 3.4 where + having 区别总结
- 4. 使用 group by 注意的问题
- 4.1 group by一定要配合聚合函数使用嘛?
- 4.2 group by 后面跟的字段一定要出现在select中嘛。
- 4.3 group by导致的慢SQL问题
- 5. group by的一些优化方案
- 5.1 group by 后面的字段加索引
- 5.2 order by null 不用排序
- 5.3 尽量只使用内存临时表
- 5.4 使用SQL_BIG_RESULT优化
- 6. 一个生产慢SQL如何优化
引言
日常开发中,我们经常会使用到group by。亲爱的小伙伴,你是否知道group by的工作原理呢?group by和having有什么区别呢?group by的优化思路是怎样的呢?使用group by有哪些需要注意的问题呢?本文将跟大家一起来学习,攻克group by~
使用group by的简单例子
group by 工作原理
group by + where 和 having的区别
group by 优化思路
group by 使用注意点
一个生产慢SQL如何优化
1. 使用group by的简单例子
group by一般用于分组统计,它表达的逻辑就是根据一定的规则,进行分组。我们先从一个简单的例子,一起来复习一下哈。
假设用一张员工表,表结构如下:
CREATE TABLE `staff` ( `id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '主键id', `id_card` varchar(20) NOT NULL COMMENT '身份证号码', `name` varchar(64) NOT NULL COMMENT '姓名', `age` int(4) NOT NULL COMMENT '年龄', `city` varchar(64) NOT NULL COMMENT '城市', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8 COMMENT='员工表';
表存量的数据如下:

我们现在有这么一个需求:统计每个城市的员工数量。对应的 SQL 语句就可以这么写:
select city ,count(*) as num from staff group by city;
执行结果如下:

这条SQL语句的逻辑很清楚啦,但是它的底层执行流程是怎样的呢?
2. group by 原理分析
2.1 explain 分析
我们先用explain查看一下执行计划
explain select city ,count(*) as num from staff group by city;

- Extra 这个字段的Using temporary表示在执行分组的时候使用了临时表
- Extra 这个字段的Using filesort表示使用了排序
group by 怎么就使用到临时表和排序了呢?我们来看下这个SQL的执行流程
2.2 group by 的简单执行流程
explain select city ,count(*) as num from staff group by city;
我们一起来看下这个SQL的执行流程哈
- 创建内存临时表,表里有两个字段city和num;
- 全表扫描staff的记录,依次取出city = 'X'的记录。
- 判断临时表中是否有为 city='X'的行,没有就插入一个记录 (X,1);
- 如果临时表中有city='X'的行的行,就将x 这一行的num值加 1;
- 遍历完成后,再根据字段city做排序,得到结果集返回给客户端。
这个流程的执行图如下:
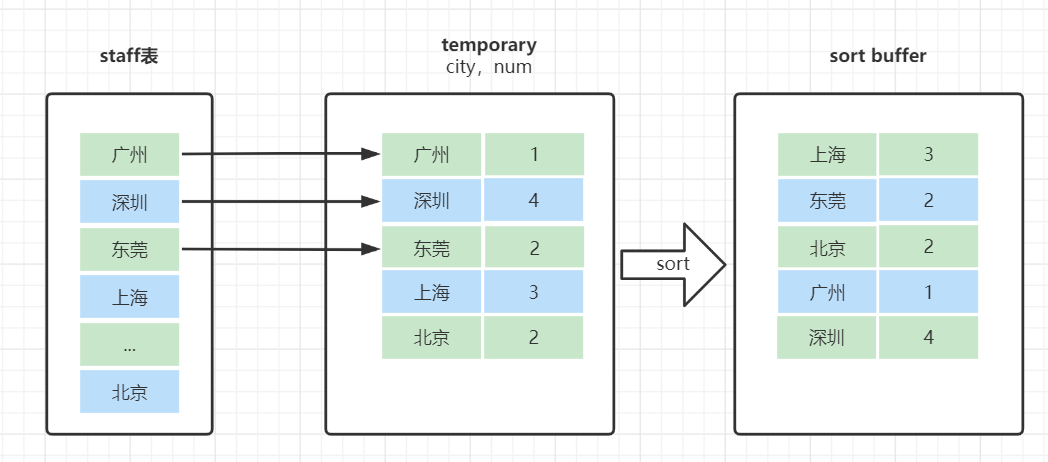
临时表的排序是怎样的呢?
就是把需要排序的字段,放到sort buffer,排完就返回。在这里注意一点哈,排序分全字段排序和rowid排序
如果是全字段排序,需要查询返回的字段,都放入sort buffer,根据排序字段排完,直接返回
如果是rowid排序,只是需要排序的字段放入sort buffer,然后多一次回表操作,再返回。
怎么确定走的是全字段排序还是rowid 排序排序呢?由一个数据库参数控制的,max_length_for_sort_data
对排序有兴趣深入了解的小伙伴,可以看我这篇文章哈。
看一遍就理解:order by详解
3. where 和 having的区别
- group by + where 的执行流程
- group by + having 的执行流程
- 同时有where、group by 、having的执行顺序
3.1 group by + where 的执行流程
有些小伙伴觉得上一小节的SQL太简单啦,如果加了where条件之后,并且where条件列加了索引呢,执行流程是怎样?
好的,我们给它加个条件,并且加个idx_age的索引,如下:
select city ,count(*) as num from staff where age> 30 group by city; //加索引 alter table staff add index idx_age (age);
再来expain分析一下:
explain select city ,count(*) as num from staff where age> 30 group by city;

从explain 执行计划结果,可以发现查询条件命中了idx_age的索引,并且使用了临时表和排序
Using index condition:
表示索引下推优化,根据索引尽可能的过滤数据,然后再返回给服务器层根据where其他条件进行过滤。这里单个索引为什么会出现索引下推呢?explain出现并不代表一定是使用了索引下推,只是代表可以使用,但是不一定用了。大家如果有想法或者有疑问,可以加我微信讨论哈。
执行流程如下:
- 创建内存临时表,表里有两个字段city和num;
- 扫描索引树idx_age,找到大于年龄大于30的主键ID
- 通过主键ID,回表找到city = 'X'
- 判断临时表中是否有为 city='X'的行,没有就插入一个记录 (X,1);
- 如果临时表中有city='X'的行的行,就将x 这一行的num值加 1;
- 继续重复2,3步骤,找到所有满足条件的数据,
最后根据字段city做排序,得到结果集返回给客户端。
3.2 group by + having 的执行
如果你要查询每个城市的员工数量,获取到员工数量不低于3的城市,having可以很好解决你的问题,SQL酱紫写:
select city ,count(*) as num from staff group by city having num >= 3;
查询结果如下:

having称为分组过滤条件,它对返回的结果集操作。
3.3 同时有where、group by 、having的执行顺序
如果一个SQL同时含有where、group by、having子句,执行顺序是怎样的呢。
比如这个SQL:
select city ,count(*) as num from staff where age> 19 group by city having num >= 3;
执行where子句查找符合年龄大于19的员工数据
group by子句对员工数据,根据城市分组。
对group by子句形成的城市组,运行聚集函数计算每一组的员工数量值;
最后用having子句选出员工数量大于等于3的城市组。
3.4 where + having 区别总结
having子句用于分组后筛选,where子句用于行条件筛选
having一般都是配合group by 和聚合函数一起出现如(count(),sum(),avg(),max(),min())
where条件子句中不能使用聚集函数,而having子句就可以。
having只能用在group by之后,where执行在group by之前
4. 使用 group by 注意的问题
使用group by 主要有这几点需要注意:
group by一定要配合聚合函数一起使用嘛?
group by的字段一定要出现在select中嘛
group by导致的慢SQL问题
4.1 group by一定要配合聚合函数使用嘛?
group by 就是分组统计的意思,一般情况都是配合聚合函数如(count(),sum(),avg(),max(),min())一起使用。
- count() 数量
- sum() 总和
- avg() 平均
- max() 最大值
- min() 最小值
如果没有配合聚合函数使用可以吗?
我用的是Mysql 5.7 ,是可以的。不会报错,并且返回的是,分组的第一行数据。
比如这个SQL:
select city,id_card,age from staff group by city;
查询结果是

大家对比看下,返回的就是每个分组的第一条数据

当然,平时大家使用的时候,group by还是配合聚合函数使用的,除非一些特殊场景,比如你想去重,当然去重用distinct也是可以的。
4.2 group by 后面跟的字段一定要出现在select中嘛。
不一定,比如以下SQL:
select max(age) from staff group by city;
执行结果如下:

分组字段city不在select 后面,并不会报错。当然,这个可能跟不同的数据库,不同的版本有关吧。大家使用的时候,可以先验证一下就好。有一句话叫做,纸上得来终觉浅,绝知此事要躬行。
4.3 group by导致的慢SQL问题
到了最重要的一个注意问题啦,group by使用不当,很容易就会产生慢SQL 问题。因为它既用到临时表,又默认用到排序。有时候还可能用到磁盘临时表。
- 如果执行过程中,会发现内存临时表大小到达了上限(控制这个上限的参数就是tmp_table_size),会把内存临时表转成磁盘临时表。
- 如果数据量很大,很可能这个查询需要的磁盘临时表,就会占用大量的磁盘空间。
这些都是导致慢SQL的x因素,我们一起来探讨优化方案哈。
5. group by的一些优化方案
从哪些方向去优化呢?
- 方向1:既然它默认会排序,我们不给它排是不是就行啦。
- 方向2:既然临时表是影响group by性能的X因素,我们是不是可以不用临时表?
我们一起来想下,执行group by语句为什么需要临时表呢?group by的语义逻辑,就是统计不同的值出现的个数。如果这个这些值一开始就是有序的,我们是不是直接往下扫描统计就好了,就不用临时表来记录并统计结果啦?
- group by 后面的字段加索引
- order by null 不用排序
- 尽量只使用内存临时表
- 使用SQL_BIG_RESULT
5.1 group by 后面的字段加索引
如何保证group by后面的字段数值一开始就是有序的呢?当然就是加索引啦。
我们回到一下这个SQL
select city ,count(*) as num from staff where age= 19 group by city;
它的执行计划

如果我们给它加个联合索引idx_age_city(age,city)
alter table staff add index idx_age_city(age,city);
再去看执行计划,发现既不用排序,也不需要临时表啦。

加合适的索引是优化group by最简单有效的优化方式。
5.2 order by null 不用排序
并不是所有场景都适合加索引的,如果碰上不适合创建索引的场景,我们如何优化呢?
如果你的需求并不需要对结果集进行排序,可以使用order by null。
select city ,count(*) as num from staff group by city order by null
执行计划如下,已经没有filesort啦

5.3 尽量只使用内存临时表
如果group by需要统计的数据不多,我们可以尽量只使用内存临时表;因为如果group by 的过程因为内存临时表放不下数据,从而用到磁盘临时表的话,是比较耗时的。因此可以适当调大tmp_table_size参数,来避免用到磁盘临时表。
5.4 使用SQL_BIG_RESULT优化
如果数据量实在太大怎么办呢?总不能无限调大tmp_table_size吧?但也不能眼睁睁看着数据先放到内存临时表,随着数据插入发现到达上限,再转成磁盘临时表吧?这样就有点不智能啦。
因此,如果预估数据量比较大,我们使用SQL_BIG_RESULT 这个提示直接用磁盘临时表。MySQl优化器发现,磁盘临时表是B+树存储,存储效率不如数组来得高。因此会直接用数组来存
示例SQl如下:
select SQL_BIG_RESULT city ,count(*) as num from staff group by city;
执行计划的Extra字段可以看到,执行没有再使用临时表,而是只有排序

执行流程如下:
- 初始化 sort_buffer,放入city字段;
- 扫描表staff,依次取出city的值,存入 sort_buffer 中;
- 扫描完成后,对 sort_buffer的city字段做排序
- 排序完成后,就得到了一个有序数组。
- 根据有序数组,统计每个值出现的次数。
6. 一个生产慢SQL如何优化
最近遇到个生产慢SQL,跟group by相关的,给大家看下怎么优化哈。
表结构如下:
CREATE TABLE `staff` ( `id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '主键id', `id_card` varchar(20) NOT NULL COMMENT '身份证号码', `name` varchar(64) NOT NULL COMMENT '姓名', `status` varchar(64) NOT NULL COMMENT 'Y-已激活 I-初始化 D-已删除 R-审核中', `age` int(4) NOT NULL COMMENT '年龄', `city` varchar(64) NOT NULL COMMENT '城市', `enterprise_no` varchar(64) NOT NULL COMMENT '企业号', `legal_cert_no` varchar(64) NOT NULL COMMENT '法人号码', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8 COMMENT='员工表';
查询的SQL是这样的:
select * from t1 where status = #{status} group by #{legal_cert_no}
我们先不去探讨这个SQL的=是否合理。如果就是这么个SQL,你会怎么优化呢?有想法的小伙伴可以留言讨论哈,也可以加我微信加群探讨。如果你觉得文章那里写得不对,也可以提出来哈,一起进步,加油呀
参考
https://www.jb51.net/article/222520.htm
以上就是Mysql数据库group by原理详解的详细内容,更多关于Mysql数据库group by的资料请关注我们其它相关文章!
相关推荐
-

python groupby函数实现分组后选取最值
现在需要将course分组,然后选择出每一组里面的最大值和最小值,并保留下来 实现下面数据结果: 直接使用groupby函数,不能直接达到此效果,需要在groupby函数上添加apply和lambda函数 代码如下: import pandas as pd data = pd.read_excel('group_apply.xlsx') data1 = data.groupby('course').apply(lambda t: t[(t['grade']==t['grade'].min())
-
python DataFrame数据分组统计groupby()函数的使用
目录 groupby()函数 1. groupby基本用法 1.1 一级分类_分组求和 1.2 二级分类_分组求和 1.3 对DataFrameGroupBy对象列名索引(对指定列统计计算) 2. 对分组数据进行迭代 2.1 对一级分类的DataFrameGroupBy对象进行遍历 2.2 对二级分类的DataFrameGroupBy对象进行遍历 3. agg()函数 3.1一般写法_对目标数据使用同一聚合函数 3.2 对不同列使用不同聚合函数 3.3 自定义函数写法 4. 通过 字典 和 Se
-
mybatis group by substr函数传参报错的解决
目录 mybatis group by substr传参报错 报异常 原因 使用group by 分组查询返回为null 解决方法 mybatis group by substr传参报错 报异常 ### Cause: java.sql.SQLSyntaxErrorException: ORA-00979: 不是 GROUP BY 表达式 SELECT SUBSTR( region_code, 1,#{ queryMap.groupCodeLength, jdbcType = INTEGE
-
pandas的排序、分组groupby及cumsum累计求和方式
目录 生成一列sum_age 对age 进行累加 生成一列sum_age_new 按照 gender和is_good 对age进行累加 根据不同的性别对年龄进行 等级 排序 对数据排序之后,分组,并累计求和 pandas分组排序功能 生成一列sum_age 对age 进行累加 df['sum_age'] = df['age'].cumsum() print(df) 生成一列sum_age_new 按照 gender和is_good 对age进行累加 df['sum_age_new'] = df.
-
聚合函数和group by的关系详解
目录 前言 聚合函数介绍 group by介绍 解释聚合函数和group by的关系 使用group by和聚合函数需要注意的地方 总结 前言 world:世界表格continent:大洲名称name:国家名称population:人口数量 聚合函数介绍 sum() 求和函数 avg() 求平均值函数 max() 求最大值函数 min() 求最小值函数 count() 求行数函数 group by介绍 group up + 字段名:规定哪个字段分组聚合在单独使用使用时,作用为分组去重 结果与di
-
MySQL数据库分组查询group by语句详解
一:分组函数的语句顺序 1 SELECT ... 2 FROM ... 3 WHERE ... 4 GROUP BY ... 5 HAVING ... 6 ORDER BY ... 二:WHERE和HAVING筛选条件的区别 数据源 位置 关键字 WHERE 原始表 ORDER BY语句之前 WHERE HAVING 分组后的结果集 ORDER BY语句之后 HAVING 三:举例说明 #1.查询每个班学生的最大年龄 SELECT MAX(age),class FROM STU_CLASS GR
-
Mysql数据库group by原理详解
目录 引言 1. 使用group by的简单例子 2. group by 原理分析 2.1 explain 分析 2.2 group by 的简单执行流程 3. where 和 having的区别 3.1 group by + where 的执行流程 3.2 group by + having 的执行 3.3 同时有where.group by .having的执行顺序 3.4 where + having 区别总结 4. 使用 group by 注意的问题 4.1 group by一定要配合聚
-
MySQL数据库中表的操作详解
目录 1.Mysql中的数据类型 2.创建数据表 3.删除表 4.插入数据 5.更新数据 6.删除数据 7.快速复制表 8.快速删除表数据 1.Mysql中的数据类型 varchar 动态字符串类型(最长255位),可以根据实际长度来动态分配空间,例如:varchar(100) char 定长字符串(最长255位),存储空间是固定的,例如:char(10) int 整数型(最长11位) long 长整型 float 单精度 double 双精度 date 短日期,只包括年月日 datetime
-
Java之jdbc连接mysql数据库的方法步骤详解
Java:jdbc连接mysql数据库 安装eclipse和mysql的步骤这里不赘述了. 1.一定要下jar包 要想实现连接数据库,要先下载mysql-connector-java-5.1.47(或者其他版本)的jar包.低版本的jar包不会出现时差问题的异常. 建议在下载界面点右边的"Looking for previous GA versions?"下载低版本的. https://www.jb51.net/article/190860.htm我看的是这个教程. 2.mysql前期
-
MySQL数据库的约束限制详解
目录 一.介绍 二.操作 添加 删除 外键联级操作 一.介绍 数据库的约束是对表中数据进行的一种限制,为了保证数据的正确性.有效性.完整性. 无论是在添加数据还是在删除数据的时候,都能提供帮助.所有的关系型数据库都支持对数据表的约束. 主键:唯一标识一条记录,不能重复,不允许为空.主要用来保证数据的完整性. 外键: 表的外键是另一表的主键,外键可以有重复,可以为控制.主要用来和其他表建立联系. 二.操作 添加 添加主键: // 一般设置id为主键 CREATE TABLE student( id
-
mysql中的mvcc 原理详解
目录 简介 前言 一.mysql 数据写入磁盘流程 二.redo log 1.redolog 的整体流程 2.为什么需要 redo log 三.undo log 1.undo log 特点 2.undo log 类型 3.undo log 生成过程 4.undo log 回滚过程 5.undo log的删除 四.mvcc 1.什么是MVCC 2.MVCC组成 3.快照读与当前读 快照读 当前读 五.mvcc操作演示 1.READ COMMITTED 隔离级别 2.REPEATABLE READ
-
nodejs连接mysql数据库及基本知识点详解
本文实例讲述了nodejs连接mysql数据库及基本知识点.分享给大家供大家参考,具体如下: 一.几个常用的全局变量 1.__filename获取当前文件的路径 2.__dirname获取当前文件的目录 3.process.cwd()获取当前工程的目录 二.文件的引入与导出 1.使用require引入文件 2.使用module.exports导出文件中指定的变量.方法.对象 三.node项目的搭建目录结构 demo package.json 当前项目所依赖的包或者模块 router 存
-
基于mysql数据库的密码问题详解
今儿在做实验用到mysql数据库时,用户密码忘记了,让我也是找了半天:现在给大家介绍下我自己的方法:用到了mysql自身的函数来测试的. 复制代码 代码如下: mysql> select user,password,host from user;+------+------------------+-----------+| user | password | host |+------+------------------+-----------+| root | 7
-
如何利用C++实现mysql数据库的连接池详解
目录 为什么是mysql? 为什么要搞资源池? mysql资源池实现的案例源码 头文件:MysqlPool.h 实现文件:MysqlPool.cpp 测试函数 总结 为什么是mysql? 现在几乎所有的后台应用都要用到数据库,什么关系型的.非关系型的:正当关系的,不正当关系的:主流的和非主流的, 大到Oracle,小到sqlite,以及包括现在逐渐流行的基于物联网的时序数据库,比如涛思的TDengine,咱们中国人自己的开源时序数据库,性能杠杠滴. 凡此总总,即使没用过,也听说过,但大部分人或企
-
mysql数据库查询基础命令详解
目录 1.启动数据库命令行客户端 2.查询数据库 3.进入数据库 3.查询所在数据库中所有表信息 4.查询数据库某张表结构 5.简单select查询语句(单张表) 5.1查询单张表所有数据 5.2 LIMIT限制查询结果返回数据项 5.3查询指定列数 5.4 WHERE带条件精准查询 5.5 LIKE使用通配符模糊查询 5.6 ORDER BY查询结果排序 1.启动数据库命令行客户端 #linux命令,注意区分大小写 mysql 2.查询数据库 #执行结果:返回所有数据库列表 SHOW DATA
-
MySQL复制优点、原理详解
复制是将主数据库的DDL和DML操作通过二进制日志传到从库上,然后再从库重做,从而使得从库和主库保持数据的同步.MySQL可以从一台主库同时向多台从库进行复制,从库同时也可以作为其他从库的主库,实现链式复制. MySQL复制的优点: 主库故障,可以快速切换至从库提供服务: 在从库执行查询操作,降低主库的访问压力: 在从库执行备份,避免备份期间对主库影响: MySQL复制原理 1.MySQL主库在事务提交时会把数据变更作为事件Events记录在Binlog中,主库上的sync_binlog参数控制