二叉树的概念案例详解
二叉树简介
关于树的介绍,请参考:https://blog.csdn.net/weixin_43790276/article/details/104033482
一、二叉树简介
二叉树是每个节点最多有两个子树的树结构,是一种特殊的树,如下图,就是一棵二叉树。

二叉树是由n(n>=0)个节点组成的数据集合。当 n=0 时,二叉树中没有节点,称为空二叉树。当 n=1 时,二叉树只有根节点一个节点。当 n>1 时,二叉树的每个节点都最多只能有两个子树,递归地构建成一棵完整的二叉树。
二叉树的两个子树被称为左子树(left subtree)和右子树(right subtree)。在二叉树中,如果节点没有子树,则左子树和右子树都为空,如果节点只有一个子树,要根据子树的左右来区分子树是左子树还是右子树,如果节点有两个子树,则左子树和右子树都有。
如果,树中存在一个节点,该节点的子树超过两个,则该树不是二叉树,如下图中,节点C有三个子树,所以这不是一棵二叉树。

二、几种特殊的二叉树
只要树中所有节点的子树都不超过两个(0个,1个,2个),这就是一棵普通的二叉树。在二叉树中,有一些比较特殊,除了满足二叉树的结构外,还满足一些特殊的规则,主要有如下几种。
1. 完全二叉树:假设一棵二叉树的深度为d(d>1),除了第d层外,其它各层的节点数目均已达最大值,且第d层所有节点从左向右连续地紧密排列,这样的二叉树被称为完全二叉树。
完全二叉树的叶节点只能出现在最下层和次下层,最下层的叶节点靠左紧密地排列,次下层如果存在叶节点,叶节点紧密地靠右排列。
如下图,树的深度为4,除了第4层,节点数达到了最大(“挂满了”),第4层的节点都是紧密地靠左排列(中间没有空位),所以这是一棵完全二叉树。
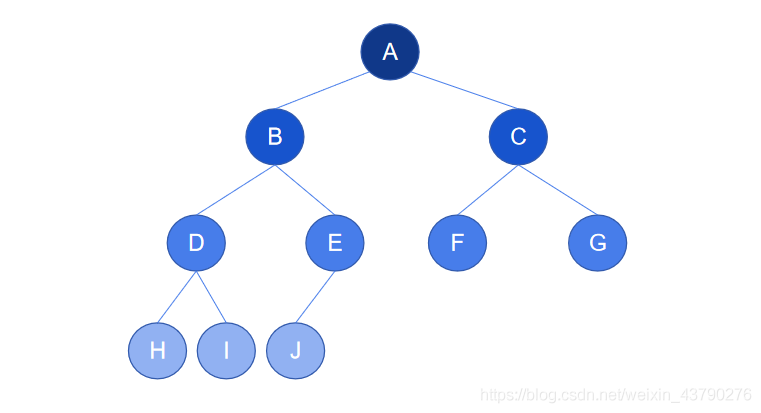
如下图,树的深度也为4,除了第4层,节点数也达到了最大,但是第4层的节点不是紧靠左侧排列的(节点E没有子节点,空了两个位置),所以这不是一棵完全二叉树,只是一棵普通的二叉树。

2. 满二叉树:所有叶节点都在最底层的完全二叉树称为满二叉树。满二叉树是完全二叉树中的特殊情况,除了满足完全二叉树的特征,还满足所有叶节点都在最底层。满二叉树是相同深度的二叉树中叶节点最多的树。
如下图,这首先是一棵完全二叉树,其次,所有的叶节点都在最底层,所以这是一棵满二叉树。其实,满二叉树也可以这么定义,二叉树有节点的所有层,节点数目均已达最大值,则这是一棵满二叉树。

3. 平衡二叉树(AVL树):如果二叉树的所有节点的两棵子树的高度差不大于1,则二叉树被称为平衡二叉树。
如上图中的满二叉树,任何节点的两棵子树高度差都是0(高度都相等,高度差不大于1),所以这是一棵平衡二叉树。
如下图中的二叉树,对于根节点A,左子树是以节点B为根的子树,高度为4,右子树是以节点C为根的子树,高为2,A的左子树与右子树的高度差为2(高度差大于1),所以这不是一棵平衡二叉树。
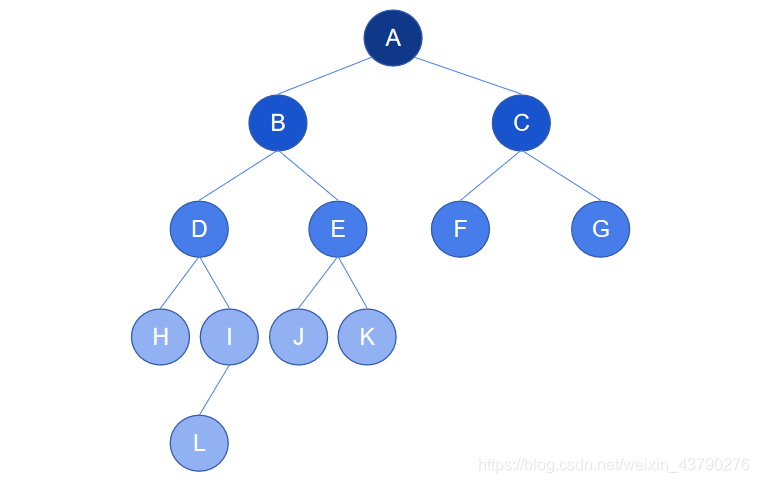
AVL树得名于它的发明者G. M. Adelson-Velsky和E. M. Landis,是两人姓的缩写。AVL树中任何节点的两个子树的高度差不大于1,通过高度来判断是否平衡,所以也被称为高度平衡树。
4. 排序二叉树(二叉查找树,Binary Search Tree):又称为二叉搜索树、有序二叉树。
排序二叉树需要具有如下的性质:
4.1 如果二叉树的左子树不为空,则左子树上所有节点的值均小于它的根节点的值。
4.2 如果二叉树的右子树不为空,则右子树上所有节点的值均大于它的根节点的值。
4.3 如果独立地看,左子树、右子树也分别为排序二叉树,用递归的思想,直到树的叶节点。
如下图,根节点8的左子树中,所有节点的值都小于根节点,右子树中,所有节点的值都大于根节点,并且左子树和右子树都是排序二叉树,所以这是一棵排序二叉树。

5. 斜树:除了叶节点,所有节点都只有左子树的二叉树称为左斜树。除了叶节点,所有节点都只有右子树的二叉树称为右斜树。他们统称为斜树,判断二叉树是否为斜树,主要是看树的结构,对节点的值没有要求。
如下图,左边的树中,除了叶节点D,所有节点都只有左子树,这是一棵左斜树,同理,右边的树是一棵右斜树。

三、二叉树的特点和性质
通过对二叉树的介绍和对几种特殊二叉树的了解,可知二叉树有以下特点:
1. 每个节点最多有两颗子树,所以二叉树中节点的度不大于2,二叉树的度也不会大于2。
2. 左子树和右子树的次序不能颠倒。
3. 即使某节点只有一棵子树,也要根据左右来区分它是左子树还是右子树。
此外,二叉树还具有如下性质:
1. 在二叉树的第i层,至多有 2^(i-1) 个节点(i>0) 。
这里说的是至多的情况,满二叉树的每一层节点都“挂满”了,所以可以用下图中的满二叉树来验证,第1层的节点数为2^(1-1)=1个,... 第4层的节点个数最多为 2^(4-1)=8个。
2. 深度为i的二叉树至多有 2^i - 1 个节点(k>0) 。
这里也是说至多的情况,所以也用满二叉树来验证,深度为4时,二叉树的节点数最多为 2^4 - 1=16-1=15个。

3. 对于任意一棵二叉树,如果其叶节点数为M,度为2的节点总数为N,则 M=N+1 。
为了不失一般性,下图中的树是一棵普通的二叉树,叶节点为 F,H,I,J,K,L ,共6个,度为2的节点为 A,B,C,D,G ,共5个。

4. 具有n个节点的满二叉树的深度必为 log2(n+1) 。这个性质是上面第2点的逆运算。
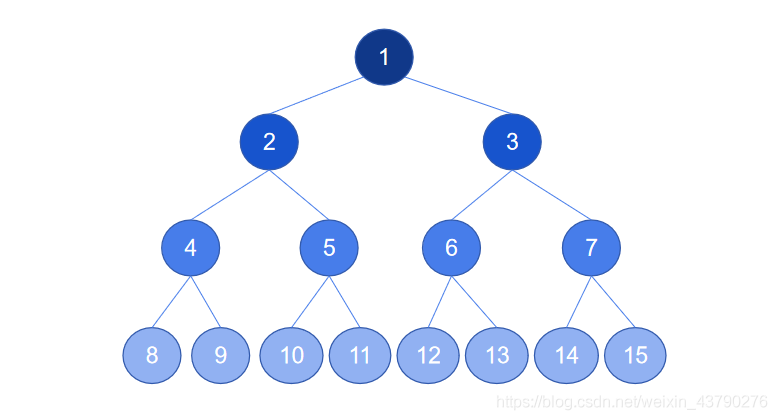
5. 对于一棵完全二叉树,若从上至下、从左至右编号,则编号为 i 的节点,(叶节点除外)其左子节点的编号必为2i,(叶节点除外)其右子节点的编号必为 2i+1,(根节点除外)其父节点的编号必为i/2(取整除)。
如下图,这是一棵完全二叉树,已经按规则编好号了,可以任意取一个节点进行验证,都是符合此性质的。
到此这篇关于二叉树的概念案例详解的文章就介绍到这了,更多相关二叉树的概念内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
java二叉树的遍历方式详解
目录 一.前序遍历(递归和非递归) 二.中序遍历(递归和非递归) 三.后序遍历(递归和非递归) 四.层序遍历 总结 一.前序遍历(递归和非递归) 前序遍历就是先遍历根再遍历左之后是右 根左右 递归实现: public List<Integer> preorderTraversal(TreeNode root) { List <Integer> list=new ArrayList<>(); pre(root,list); return list; } public vo
-
C++实现LeetCode(199.二叉树的右侧视图)
[LeetCode] 199.Binary Tree Right Side View 二叉树的右侧视图 Given a binary tree, imagine yourself standing on the right side of it, return the values of the nodes you can see ordered from top to bottom. For example: Given the following binary tree, 1
-
JAVA二叉树的基本操作
目录 记录二叉树的基本操作DEMO 1.创建一个二叉树类 2.然后创建二叉树的节点 记录二叉树的基本操作DEMO 1.创建一个二叉树类 这里约束了泛型只能为实现了Comparable这个接口的类型. /** * @author JackHui * @version BinaryTree.java, 2020年03月05日 12:45 */ public class BinaryTree<T extends Comparable> { //树根 BinaryTreeNode root; publ
-

如何使用C语言实现平衡二叉树数据结构算法
目录 前言 一.平衡二叉树实现原理 二.平衡二叉树实现算法 三.全部代码 前言 对于一个二叉排序树而言 它们的结构都是根据了二叉树的特性从最左子树开始在回到该结点上继续往右结点走 通过该方式进行递归操作,并且该二叉排序树的结构也是从小到大依次显示 那么我们假设a[10]={ 3,2,1,4,5,6,7,10,9,8 };我们需要查找改列表中的某一个结点的值 那么我们通过二叉排序树的展示,会展示成如图: 可以发现,如果我们想通过二叉排序树这个深度为8的树来查找某个数 我们需要走到最后,这是最坏的打
-
全网最精细详解二叉树,2万字带你进入算法领域
目录 一.前言 二.二叉树缺点 三.遍历与结点删除 1.四种基本的遍历思想 2.自定义二叉树 3.代码实现 四.先看一个问题 五.线索化二叉树 六.线索化二叉树代码实例 1.线索化二叉树 2.测试 3.控制台输出 七.遍历线索化二叉树 1.代码实例 2.控制台输出 八.大顶堆和小顶堆图解说明 1.堆排序基本介绍 2.大顶堆举例说明 3.小顶堆距离说明 4.一般升序采用大顶堆,降序采用小顶堆 九.堆排序思路和步骤解析 1.将无序二叉树调整为大顶堆 2.将堆顶元素与末尾元素进行交换 3.重新调整结构
-
C++二叉树的直径与合并详解
目录 二叉树的直径 给定一棵二叉树,你需要计算它的直径长度.一棵二叉树的直径长度是任意两个结点路径长度中的最大值.这条路径可能穿过也可能不穿过根结点. 思路 合并二叉树 给定两个二叉树,想象当你将它们中的一个覆盖到另一个上时,两个二叉树的一些节点便会重叠.你需要将他们合并为一个新的二叉树.合并的规则是如果两个节点重叠,那么将他们的值相加作为节点合并后的新值,否则不为 NULL 的节点将直接作为新二叉树的节点. 思路 1.确定递归函数的参数和返回值: 2.确定终止条件: 3.确定单层递归的逻辑:
-
二叉树的概念案例详解
二叉树简介 关于树的介绍,请参考:https://blog.csdn.net/weixin_43790276/article/details/104033482 一.二叉树简介 二叉树是每个节点最多有两个子树的树结构,是一种特殊的树,如下图,就是一棵二叉树. 二叉树是由n(n>=0)个节点组成的数据集合.当 n=0 时,二叉树中没有节点,称为空二叉树.当 n=1 时,二叉树只有根节点一个节点.当 n>1 时,二叉树的每个节点都最多只能有两个子树,递归地构建成一棵完整的二叉树. 二叉树的两个子树
-
Python 二叉树的概念案例详解
二叉树简介 关于树的介绍,请参考:https://www.jb51.net/article/222488.htm 一.二叉树简介 二叉树是每个节点最多有两个子树的树结构,是一种特殊的树,如下图,就是一棵二叉树. 二叉树是由n(n>=0)个节点组成的数据集合.当 n=0 时,二叉树中没有节点,称为空二叉树.当 n=1 时,二叉树只有根节点一个节点.当 n>1 时,二叉树的每个节点都最多只能有两个子树,递归地构建成一棵完整的二叉树. 二叉树的两个子树被称为左子树(left subtree)和右子树
-
webpack-dev-server核心概念案例详解
webpack-dev-server 核心概念 Webpack 的 ContentBase vs publicPath vs output.path webpack-dev-server 会使用当前的路径作为请求的资源路径(所谓 当前的路径 就是运行 webpack-dev-server 这个命令的路径,如果对 webpack-dev-server 进行了包装,比如 wcf,那么当前路径指的就是运行 wcf命令的路径,一般是项目的根路径),但是读者可以通过指定 content-base 来修改这
-
C语言指针数组案例详解
指针与数组是 C 语言中很重要的两个概念,它们之间有着密切的关系,利用这种 关系,可以增强处理数组的灵活性,加快运行速度,本文着重讨论指针与数组之 间的联系及在编程中的应用. 1.指针与数组的关系 当一个指针变量被初始化成数组名时,就说该指针变量指向了数组.如: char str[20], *ptr; ptr=str; ptr 被置为数组 str 的第一个元素的地址,因为数组名就是该数组的首地址, 也是数组第一个元素的地址.此时可以认为指针 ptr 就是数组 str(反之不成立), 这样原来对数
-
JavaWeb之会话技术案例详解
会话技术 1. 会话:一次会话中包含多次请求和响应. 一次会话:浏览器第一次给服务器资源发送请求,会话建立,直到有一方断开为止 2. 功能:在一次会话的范围内的多次请求间,共享数据 3. 方式: 1. 客户端会话技术:Cookie 2. 服务器端会话技术:Session Cookie: 1. 概念:客户端会话技术,将数据保存到客户端 2. 快速入门: 1. 创建Cookie对象,绑定数据
-
Java ConcurrentHashMap用法案例详解
一.概念 哈希算法(hash algorithm):是一种将任意内容的输入转换成相同长度输出的加密方式,其输出被称为哈希值. 哈希表(hash table):根据设定的哈希函数H(key)和处理冲突方法将一组关键字映象到一个有限的地址区间上,并以关键字在地址区间中的象作为记录在表中的存储位置,这种表称为哈希表或散列,所得存储位置称为哈希地址或散列地址. 二.HashMap与HashTable 1,线程不安全的HashMap 因为多线程环境下,使用HashMap进行put操作会引起死循环,导致CP
-
Java JNDI案例详解
JNDI的理解 JNDI是 Java 命名与文件夹接口(Java Naming and Directory Interface),在J2EE规范中是重要的规范之中的一个,不少专家觉得,没有透彻理解JNDI的意义和作用,就没有真正掌握J2EE特别是EJB的知识. 那么,JNDI究竟起什么作用?//带着问题看文章是最有效的 要了解JNDI的作用,我们能够从"假设不用JNDI我们如何做?用了JNDI后我们又将如何做?"这个问题来探讨. 没有JNDI的做法: 程序猿开发时,知道要开发訪
-
Java DFA算法案例详解
1.背景 项目中需要对敏感词做一个过滤,首先有几个方案可以选择: 直接将敏感词组织成String后,利用indexOf方法来查询. 传统的敏感词入库后SQL查询. 利用Lucene建立分词索引来查询. 利用DFA算法来进行. 首先,项目收集到的敏感词有几千条,使用a方案肯定不行.其次,为了方便以后的扩展性尽量减少对数据库的依赖,所以放弃b方案.然后Lucene本身作为本地索引,敏感词增加后需要触发更新索引,并且这里本着轻量原则不想引入更多的库,所以放弃c方案.于是我们选定d方案为研究目标. 2.
-
Java Map.entry案例详解
Map.entrySet() 这个方法返回的是一个Set<Map.Entry<K,V>>,Map.Entry 是Map中的一个接口,他的用途是表示一个映射项(里面有Key和Value),而Set<Map.Entry<K,V>>表示一个映射项的Set.Map.Entry里有相应的getKey和getValue方法,即JavaBean,让我们能够从一个项中取出Key和Value. 下面是遍历Map的四种方法: public static void main
-
Java ResourceBundle案例详解
JAVA中ResourceBundle使用详解 这个类主要用来解决国际化和本地化问题.国际化和本地化可不是两个概念,两者都是一起出现的.可以说,国际化的目的就是为了实现本地化.比如对于"取消",中文中我们使用"取消"来表示,而英文中我们使用"cancel".若我们的程序是面向国际的(这也是软件发展的一个趋势),那么使用的人群必然是多语言环境的,实现国际化就非常有必要.而ResourceBundle可以帮助我们轻松完成这个任务:当程序需要一个特定于